Qu’est-ce qu’Azure HDInsight ?
Azure HDInsight est un service cloud d’analyse managé, complet et open source pour les entreprises. Avec HDInsight, vous pouvez utiliser les infrastructures open source telles que Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka et bien plus, dans votre environnement Azure.
Qu’est-ce que HDInsight et la pile de technologies Hadoop ?
Azure HDInsight est une plateforme de clusters managée qui facilite l’exécution de frameworks Big Data comme Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop et d’autres dans votre environnement Azure. Il est conçu pour gérer de grands volumes de données avec une vitesse et une efficacité élevées.
Pourquoi dois-je utiliser Azure HDInsight ?
| Fonctionnalité | Description |
|---|---|
| Cloud natif | Azure HDInsight vous permet de créer des clusters optimisés pour Spark, Interactive query (LLAP), Kafka, HBase et Hadoop sur Azure. HDInsight fournit également un contrat SLA de bout en bout sur toutes vos charges de travail de production. |
| Économique et évolutif | HDInsight vous permet d’effectuer un scale-up ou un scale-down de charges de travail. Vous pouvez réduire les coûts en créant des clusters à la demande et payer seulement pour ce que vous utilisez. Vous pouvez également créer des pipelines de données pour faire fonctionner vos travaux. Le stockage et le calcul découplés améliorent les performances et la flexibilité. |
| Sécurité et conformité | HDInsight vous permet de protéger les ressources de données de votre entreprise avec un réseau virtuel Azure, un chiffrement et une intégration avec Microsoft Entra ID. HDInsight répond également aux normes de conformité du gouvernement et du secteur les plus populaires. |
| Supervision | Azure HDInsight s’intègre aux journaux d’activité Azure Monitor pour fournir une interface unique permettant de superviser tous vos clusters. |
| Disponibilité générale | HDInsight est disponible dans plus de régions que n’importe quelle autre offre d’analytique Big Data. Azure HDInsight est également disponible dans Azure Government, en Chine, et en Allemagne, ce qui vous permet de répondre aux besoins de votre entreprise dans les principaux domaines souverains. |
| Productivité | Azure HDInsight vous permet d’utiliser des outils de productivité enrichis pour Hadoop et Spark avec les environnements de développement de votre choix. Parmi ces environnements de développement figurent Visual Studio, VSCode, Eclipse et IntelliJ pour la prise en charge de Scala, Python, Java et .NET. |
| Extensibilité | Vous pouvez étendre les clusters HDInsight avec des composants installés (Hue, Presto, etc.) à l’aide d’actions de script, par l’ajout de nœuds de périphérie, ou l’intégration à d’autres applications certifiées Big Data. HDInsight permet une intégration transparente aux solutions Big Data les plus populaires à l’aide d’un déploiement en un clic. |
Que sont les données volumineuses ?
Les données volumineuses sont collectées dans des volumes toujours plus importants, à des vitesses élevées et pour une variété de formats plus grande qu’auparavant. Elles peuvent être historiques (c'est-à-dire stockées) ou en temps réel (c'est-à-dire diffusées à partir de la source). Consultez Scénarios d’utilisation d’ HDInsight pour en savoir plus sur les cas d’usage courants pour les Big Data.
Types de cluster dans HDInsight
HDInsight comprend des types de cluster spécifiques et des fonctionnalités de personnalisation de cluster, comme l’ajout de composants, d’utilitaires et de langages. HDInsight offre les types de clusters suivants :
| Type du cluster | Description | Bien démarrer |
|---|---|---|
| Apache Hadoop | infrastructure qui utilise HDFS, la gestion de ressources YARN et un modèle de programmation MapReduce simple pour traiter et analyser les lots de données en parallèle. | Créer un cluster Apache Hadoop |
| Apache Spark | infrastructure de traitement parallèle open source qui prend en charge le traitement en mémoire pour améliorer les performances des applications d’analyse du Big Data. Consultez Présentation d’Apache Spark dans HDInsight. | Créer un cluster Apache Spark |
| Apache HBase | base de données NoSQL basée sur Hadoop qui fournit un accès aléatoire et une forte cohérence pour de vastes quantités de données non structurées et semi-structurées (potentiellement, des milliards de lignes multipliées par des millions de colonnes). Consultez Qu’est-ce que HBase sur HDInsight ? | Créer un cluster Apache HBase |
| Requête interactive Apache | mise en cache pour des requêtes Hive interactives et plus rapides. Consultez l’article Utilisation d’Interactive Query dans HDInsight. | Créer un cluster Interactive Query |
| Apache Kafka | Une plateforme open source est utilisée pour créer des applications et des pipelines de données de diffusion en continu. Kafka fournit également une fonctionnalité de file d’attente de messages qui vous permet de publier des flux de données et de vous abonner à ces derniers. Consultez l’article Présentation d’Apache Kafka sur HDInsight. | Créer un cluster Apache Kafka |
Scénarios d’utilisation de HDInsight
Azure HDInsight peut être utilisé pour différents scénarios dans le cadre du traitement de données Big Data. Il peut s’agir de données historiques (des données déjà collectées et stockées) ou de données en temps réel (des données diffusées en continu directement depuis la source). Les scénarios pour le traitement de ces données peuvent être classés dans les catégories suivantes :
Traitement par lots (ETL)
Extraction, transformation et chargement (ETL) est un processus au cours duquel les données structurées ou non sont extraites à partir de sources de données hétérogènes. Elles sont ensuite converties dans un format structuré et chargées dans un magasin de données. Les données converties peuvent être utilisées pour la science des données ou l’entreposage de données.
Entrepôt de données
HDInsight permet d’exécuter des requêtes interactives sur des pétaoctets de données structurées ou non dans n’importe quel format. Vous pouvez également créer des modèles en les connectant à des outils BI.
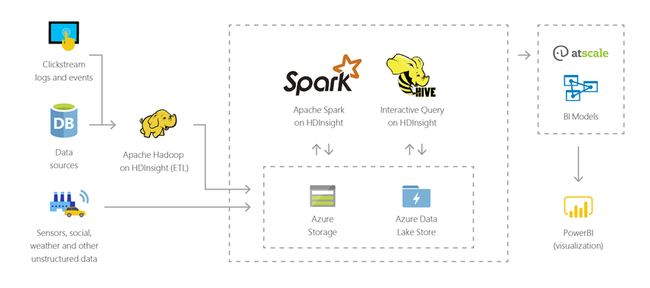
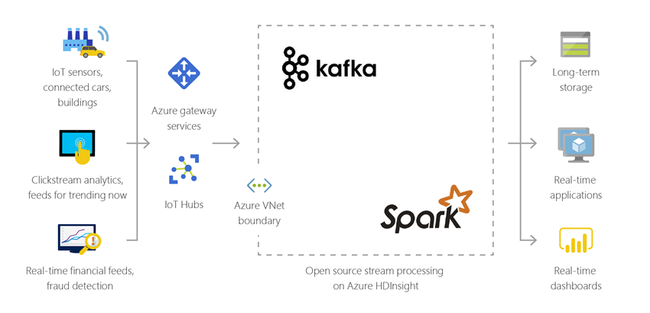
Internet des objets (IoT)
Vous pouvez utiliser HDInsight pour traiter les données de diffusion en continu reçues en temps réel depuis différentes sortes d’appareils. Pour plus d’informations, lire ce billet de blog Azure annonçant la version préliminaire publique de Apache Kafka sur HDInsight avec Azure Disques Managés.
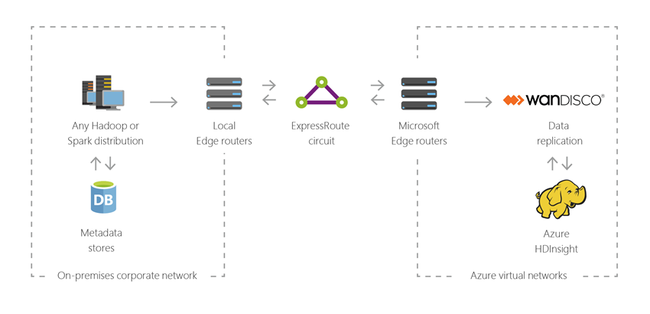
Hybride
HDInsight permet d’étendre votre infrastructure Big Data locale existante sur Azure pour appliquer les fonctionnalités d’analyse avancée du cloud.
Composants open source dans HDInsight
Azure HDInsight vous permet de créer des clusters avec des infrastructures open source telles que Spark, Hive, LLAP, Kafka, Hadoop et HBase. Par défaut, ces clusters incluent différents composants open source comme Apache Ambari, Avro, Apache Hive3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie et Apache ZooKeeper.
Langages de programmation dans HDInsight
Les clusters HDInsight (dont Spark, HBase, Kafka, Hadoop et d’autres) prennent en charge de nombreux langages de programmation. Certains langages de programmation ne sont pas installés par défaut. Pour les bibliothèques, modules ou packages non installés par défaut, utilisez une action de script pour installer le composant.
| Langage de programmation | Information |
|---|---|
| Prise en charge des langages de programmation par défaut | Par défaut, HDInsight prend en charge :
|
| Langages de machines virtuelles Java (JVM) | De nombreux langages autres que Java peuvent s’exécuter sur une machine virtuelle Java (JVM). Toutefois, si vous exécutez certains de ces langages, vous devrez peut-être installer des composants supplémentaires sur le cluster. Les langages JVM suivants sont pris en charge sur les clusters HDInsight :
|
| Langages spécifiques à Hadoop | Les clusters HDInsight prennent en charge les langages suivants, spécifiques à la pile de technologies Hadoop :
|
Outils de gestion pour HDInsight
Vous pouvez utiliser les outils de développement HDInsight, y compris IntelliJ, Eclipse, Visual Studio Code et Visual Studio, pour créer et soumettre une tâche et une requête de données HDInsight avec une intégration transparente avec Azure.
- Azure Toolkit for IntelliJ 10
- Azure Toolkit for Eclipse 6
- Outils Azure HDInsight pour VS Code 13
- Outils Azure Data Lake pour Visual Studio 9
Le décisionnel sur HDInsight
Les outils décisionnels courants permettent de récupérer des données intégrées à HDInsight, de les analyser et de générer des rapports à leur sujet via le complément Power Query ou le Pilote ODBC Microsoft Hive :
Apache Spark BI utilisant des outils de visualisation de données avec Azure HDInsight
Visualiser des données Apache Hive à l’aide de Microsoft Power BI dans Azure HDInsight
Visualiser des données Interactive Query Hive à l’aide de Power BI dans Azure HDInsight
Connecter Excel à Apache Hadoop avec Power Query (requiert Windows)
Connecter Excel à Apache Hadoop avec le Pilote ODBC Microsoft Hive (requiert Windows)
Résidence des données dans la région
Spark, Hadoop, et LLAP ne stockent pas les données client, si bien que ces services répondent automatiquement aux conditions de résidence des données dans la région spécifiées dans le Centre de gestion de la confidentialité.
En revanche, Kafka et HBase stockent des données client. Ces données sont automatiquement stockées par Kafka et HBase dans une seule région, donc ces services répondent aux conditions de résidence des données dans la région spécifiées dans le Centre de gestion de la confidentialité.
Les outils décisionnels courants permettent de récupérer des données intégrées à HDInsight, de les analyser et de générer des rapports à leur sujet par le biais du complément Power Query ou du Pilote ODBC Microsoft Hive.
Étapes suivantes
- Créer un cluster Apache Hadoop dans HDInsight
- Créer un cluster Apache Spark - Portail
- Sécurité d’entreprise dans Azure HDInsight
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour