Bonnes pratiques relatives à l’utilisation de l’API univariée Détecteur d’anomalies
Important
À partir du 20 septembre 2023, vous ne pourrez plus créer de ressources Détecteur d’anomalies. Le service Détecteur d’anomalies sera mis hors service le 1er octobre 2026.
L’API Détecteur d’anomalies est un service de détection d’anomalies sans état. La précision et les performances de ses résultats peuvent être affectées par :
- la manière dont vos données de série chronologique sont préparées ;
- les paramètres de l’API Détecteur d’anomalies qui ont été utilisés ;
- le nombre de points de données dans votre requête d’API.
Utilisez cet article pour en savoir plus sur les bonnes pratiques d’utilisation de l’API afin d’obtenir les meilleurs résultats pour vos données.
Quand utiliser la détection d'anomalies par lots (complète) ou sur les points les plus récents (derniers)
Le point de terminaison de détection par lots de l’API Détecteur d'anomalies permet de détecter des anomalies dans toutes vos données de série chronologique. Dans ce mode de détection, un modèle statistique unique est créé et appliqué à chaque point du jeu de données. Si votre série chronologique présente les caractéristiques ci-dessous, nous recommandons l’utilisation de la détection par lots pour afficher un aperçu de vos données dans un seul appel d’API.
- Une série chronologique saisonnière, avec des anomalies occasionnelles.
- Une série chronologique à tendance stable, avec des pics/creux occasionnels.
Nous ne recommandons pas l’utilisation de la détection d’anomalie par lots pour la supervision des données en temps réel ou sur des données de série chronologique ne présentant les caractéristiques ci-dessus.
La détection par lots crée un seul modèle auquel elle s’applique, la détection pour chaque point étant effectuée dans le cadre de la série entière. Si le nombre d’anomalies constatées sur les données de série chronologique a tendance à augmenter et à diminuer sans saisonnalité, certains points de changement (creux et pics dans les données) peuvent être absents du modèle. Similairement, certains points de changement moins importants que ceux mis en évidence ultérieurement dans les données ne sont pas obligatoirement considérés comme assez importants pour être incorporés au modèle.
En raison du nombre de points analysés, la détection par lots est plus lente que la détection de l’état des anomalies du dernier point lors de la surveillance des données en temps réel.
Pour l’analyse de données en temps réel, nous recommandons la seule détection de l’état des anomalies de votre dernier point de données. En appliquant en permanence la détection du dernier point, analyse des données de diffusion en continu peut être effectuée plus efficacement et précisément.
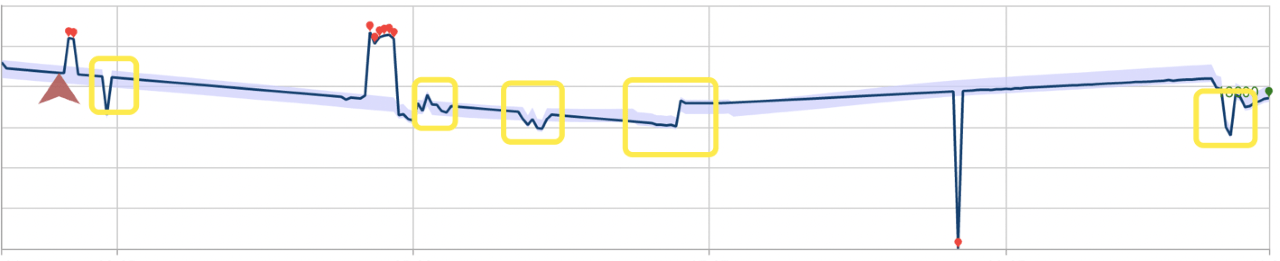
L’exemple ci-dessous décrit l’impact que ces modes de détection peuvent avoir sur les performances. La première illustration montre le résultat de la détection permanente sur le dernier point d’état pour 28 points de données préalablement examinés. Les points rouges sont des anomalies.

Voici le même jeu de données avec la détection d’anomalies par lots. Le modèle créé pour l’opération a ignoré plusieurs anomalies, indiquées par des rectangles.
Préparation des données
L’API Détecteur d’anomalies accepte la série chronologique mise en forme dans un objet de demande JSON. Une série chronologique peut être n’importe quel type de données numériques enregistrées au fil du temps dans l’ordre séquentiel. Vous pouvez envoyer des fenêtres de vos données de série chronologique au point de terminaison de l’API Détecteur d’anomalies pour améliorer les performances de l’API. Le nombre minimum de points de données que vous pouvez envoyer est de 12, et le nombre maximum est de 8 640 points. La granularité est définie comme la vitesse à laquelle vos données sont échantillonnées.
Les points de données envoyés à l’API Détecteur d’anomalies doivent avoir un horodatage UTC (temps universel coordonné) et une valeur numérique.
{
"granularity": "daily",
"series": [
{
"timestamp": "2018-03-01T00:00:00Z",
"value": 32858923
},
{
"timestamp": "2018-03-02T00:00:00Z",
"value": 29615278
},
]
}
Si vos données sont échantillonnées à un intervalle de temps non standard, vous pouvez le spécifier en ajoutant l’attribut customInterval dans votre requête. Par exemple, si votre série est échantillonnée toutes les 5 minutes, vous pouvez ajouter les éléments suivants à votre requête JSON :
{
"granularity" : "minutely",
"customInterval" : 5
}
Points de données manquants
Les données manquantes sont courantes dans les jeux de données de séries chronologiques distribués de manière homogène, en particulier ceux à granularité fine (petit intervalle d’échantillonnage, par exemple, toutes les quelques minutes). S’il manque de moins de 10 % du nombre de points prévu dans vos données, cela ne devrait pas avoir d’impact négatif sur vos résultats de détection. Envisagez de combler les lacunes dans vos données en vous basant sur leurs caractéristiques, par exemple, en les remplaçant par des points de données d’une période précédente, par une interpolation linéaire ou par une moyenne mobile.
Agréger des données distribuées
L’API Détecteur d’anomalies fonctionne le mieux sur une série chronologique distribuée de manière homogène. Si vos données sont réparties de façon aléatoire, vous devez les agréger par unité de temps, par exemple par minute, par heure ou par jour.
Détection d’anomalies sur les données avec des modèles saisonniers
Si vous savez que vos données de série chronologique ont un modèle saisonnier (qui se produit à intervalles réguliers), vous pouvez améliorer la précision et le temps de réponse de l’API.
Spécifier une period lorsque vous construisez votre demande JSON peut réduire la latence de la détection d’anomalies de jusqu'à 50 %. La period est un entier qui spécifie grossièrement combien de points de données la série chronologique utilise pour répéter un modèle. Par exemple, une série chronologique avec un point de données par jour aurait une period de 7, et une série chronologique avec un point par heure (avec le même modèle hebdomadaire) aurait une period de 7*24. Si vous ne connaissez pas les modèles de vos données, vous n’êtes pas obligé de spécifier ce paramètre.
Pour de meilleurs résultats, fournissez une valeur de points de données correspondant à quatre period, plus un point de données supplémentaire. Par exemple, des données horaires avec un modèle hebdomadaire conformément à la description ci-dessus doivent fournir 673 points de données dans le corps de la demande (7 * 24 * 4 + 1).
Données d’échantillonnage pour une analyse en temps réel
Si vos données de diffusion en continu sont échantillonnées à courts intervalles (par exemple, des secondes ou des minutes), l’envoi du nombre recommandé de points de données peut dépasser le nombre maximal (8 640 points de données) autorisé par l’API Détecteur d’anomalies. Si vos données affichent un modèle saisonnier stable, envisagez d’envoyer un échantillon de vos données de série chronologique à un intervalle de temps plus long, par exemple des heures. Cette manière d’échantillonner vos données peut également améliorer sensiblement le temps de réponse de l’API.