Analyser des journaux d’activité de site web en utilisant une bibliothèque Python personnalisée avec un cluster Apache Spark sur HDInsight
Ce bloc-notes montre comment analyser les données de journal à l'aide d'une bibliothèque personnalisée avec Apache Spark sur HDInsight. La bibliothèque personnalisée que nous utilisons est une bibliothèque Python appelée iislogparser.py.
Conditions préalables requises
Un cluster Apache Spark sur HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight.
Enregistrer des données brutes en tant que RDD
Dans cette section, nous allons utiliser le notebook Jupyter associé à un cluster Apache Spark dans HDInsight pour exécuter des travaux qui traitent les exemples de données brutes et les enregistrent dans une table Hive. L’exemple de données est un fichier .csv (hvac.csv), qui est disponible par défaut sur tous les clusters.
Une fois vos données enregistrées dans une table Apache Hive, vous allez vous connecter, dans la prochaine section, à la table Hive à l’aide d’outils de Business Intelligence tels que Power BI et Tableau.
Dans un navigateur web, accédez à
https://CLUSTERNAME.azurehdinsight.net/jupyter, oùCLUSTERNAMEest le nom de votre cluster.Créer un nouveau bloc-notes. Sélectionnez Nouveau, puis PySpark.
 Notebook" border="true":::
Notebook" border="true":::Un nouveau bloc-notes est créé et ouvert sous le nom Untitled.pynb. Sélectionnez le nom du bloc-notes en haut, puis entrez un nom convivial.
Comme vous avez créé un notebook à l’aide du noyau PySpark, il est inutile de créer des contextes explicitement. Les contextes Spark et Hive sont automatiquement créés pour vous lorsque vous exécutez la première cellule de code. Vous pouvez commencer par importer les types requis pour ce scénario. Collez l’extrait de code suivant dans une cellule vide, puis appuyez sur Maj+ Entrée.
from pyspark.sql import Row from pyspark.sql.types import *Créez un RDD à l’aide de l’exemple de données de journal déjà disponible sur le cluster. Vous pouvez accéder aux données dans le compte de stockage par défaut associé au cluster à l’emplacement
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log. Exécutez le code suivant :logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')Récupérez un exemple de jeu de journal pour vérifier que l'étape précédente a été correctement effectuée.
logs.take(5)Le résultat doit ressembler au texte qui suit :
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
Analysez les données de journal à l'aide d'une bibliothèque Python personnalisée
Dans la sortie ci-dessus, les premières lignes comprennent les informations d'en-tête et chaque ligne restante correspond au schéma décrit dans l'en-tête. L’analyse de tels journaux d’activité peut s’avérer complexe. Par conséquent, nous utilisons une bibliothèque Python personnalisée (iislogparser.py) qui facilite beaucoup l’analyse de tels journaux d’activité. Par défaut, cette bibliothèque est incluse avec votre cluster Spark sur HDInsight dans
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py.Toutefois, cette bibliothèque n’est pas dans le
PYTHONPATH. Par conséquent, vous ne pouvez pas l’utiliser à l’aide d’une instruction d’importation telle queimport iislogparser. Pour utiliser cette bibliothèque, nous devons la distribuer à tous les nœuds de travail. Exécutez l'extrait de code suivant.sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparserfournit une fonctionparse_log_linequi retourneNonesi une ligne de journal est une ligne d'en-tête et retourne une instance de la classeLogLinesi elle rencontre une ligne de journal. Utilisez la classeLogLinepour extraire uniquement les lignes de journal du RDD :def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()Récupérez quelques lignes de journal extraites pour vérifier que l'étape a été correctement effectuée.
logLines.take(2)Le résultat doit être similaire au texte qui suit :
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]La classe
LogLine, quant à elle, dispose de méthodes utiles, telles queis_error(), qui retourne si une entrée de journal présente un code d’erreur. Elle permet de calculer le nombre d’erreurs dans les lignes de journal extraites, puis de journaliser toutes les erreurs dans un fichier différent.errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')La sortie doit indiquer
There are 30 errors and 646 log entries.Matplotlib permet également de construire une visualisation des données. Par exemple, si vous souhaitez isoler la cause des requêtes qui s'exécutent pendant une longue période, il se peut que vous souhaitiez trouver les fichiers qui mettent le plus de temps à répondre en moyenne. L’extrait de code ci-dessous récupère les 25 ressources qui mettent le plus de temps à répondre à une requête.
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])Un résultat similaire à ce qui suit s’affiche normalement :
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]Vous pouvez également présenter ces informations sous forme de diagramme. La première étape pour créer un tracé consiste à créer un tableau temporaire AverageTime. Le tableau regroupe les journaux d’activité par heure pour voir si des pics de latence inhabituels sont survenus à un moment donné.
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')Vous pouvez ensuite exécuter la requête SQL suivante pour obtenir tous les enregistrements du tableau AverageTime .
%%sql -o averagetime SELECT * FROM AverageTimeLa méthode
%%sqlsuivie par-o averagetimegarantit que le résultat de la requête est conservé localement sur le serveur Jupyter (généralement le nœud principal du cluster). Le résultat est conservé sous forme d’un tableau de données Pandas avec le nom spécifié averagetime.Un résultat similaire à l’image suivante s’affiche normalement :
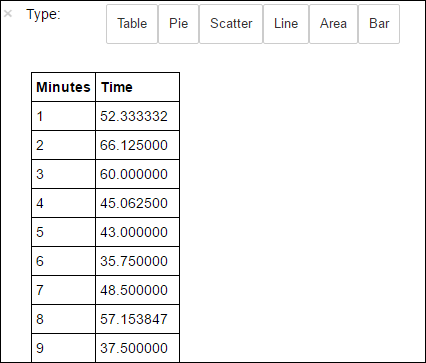 yter sql query output" border="true":::
yter sql query output" border="true":::Pour plus d’informations sur
%%sqlMagic, consultez Paramètres pris en charge avec %%SQL Magic.Vous pouvez désormais utiliser Matplotlib, une bibliothèque permettant de construire une visualisation des données, pour créer un tracé. Étant donné que le tracé doit être créé à partir du tableau de données averagetime conservé localement, l’extrait de code doit commencer par la méthode magique
%%local. Cela garantit l’exécution locale du code sur le serveur Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')Un résultat similaire à l’image suivante s’affiche normalement :
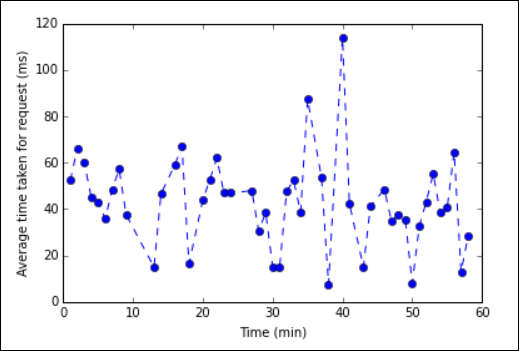 eb log analysis plot" border="true":::
eb log analysis plot" border="true":::Une fois l’exécution de l’application terminée, fermez le bloc-notes pour libérer les ressources. Pour ce faire, dans le menu Fichier du bloc-notes, sélectionnez Fermer et arrêter. Cette action permet d’arrêter et de fermer le notebook.
Étapes suivantes
Explorez les articles suivants :
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour