Tutoriel : charger des données et exécuter des requêtes sur un cluster Apache Spark dans Azure HDInsight
Dans ce tutoriel, vous allez apprendre à créer une trame de données à partir d’un fichier CSV et à exécuter des requêtes interactives SQL Spark sur un cluster Apache Spark dans Azure HDInsight. Dans Spark, une trame de données est une collection distribuée de données organisées en colonnes nommées. D’un point de vue conceptuel, une trame de données équivaut à une table d’une base de données relationnelle ou à une trame de données dans R/Python.
Dans ce tutoriel, vous allez apprendre à :
- Créer une trame de données à partir d’un fichier CSV
- Exécuter des requêtes sur la trame de données
Prérequis
Un cluster Apache Spark sur HDInsight. Consultez Créer un cluster Apache Spark.
Créer un bloc-notes Jupyter Notebook
Jupyter Notebook est un environnement de bloc-notes interactif qui prend en charge divers langages de programmation. Le Notebook vous permet d’interagir avec vos données, de combiner du code avec le texte Markdown et d’effectuer des visualisations simples.
Modifiez l'URL
https://SPARKCLUSTER.azurehdinsight.net/jupyteren remplaçantSPARKCLUSTERpar le nom de votre cluster Spark. Entrez ensuite l'URL modifiée dans un navigateur web. À l’invite (le cas échéant), entrez les informations d’identification du cluster.Dans la page web de Jupyter, Pour les clusters Spark 2.4, sélectionnez Nouveau>PySpark pour créer un notebook. Pour la version Spark 3.1, sélectionnez plutôt New>PySpark3 pour créer un notebook, car le noyau PySpark n’est plus disponible dans Spark 3.1.
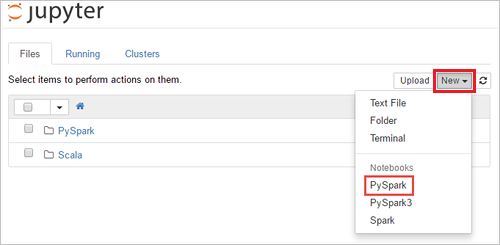
Un nouveau notebook est créé et ouvert sous le nom Untitled(
Untitled.ipynb).Notes
En utilisant le noyau PySpark ou PySpark3 pour créer un notebook, la session
sparkest automatiquement créée quand vous exécutez la première cellule de code. Vous n’avez pas besoin de créer explicitement la session.
Créer une trame de données à partir d’un fichier CSV
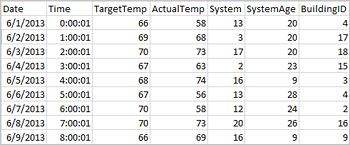
Les applications peuvent créer des dataframes directement à partir de fichiers ou de dossiers dans le stockage distant, par exemple le stockage Azure ou Azure Data Lake Storage, à partir d’une table Hive ou d’autres sources de données prises en charge par Spark, telles qu’Azure Cosmos DB, Azure SQL DB, DW, etc. La capture d’écran suivante montre un instantané du fichier HVAC.csv utilisé dans ce didacticiel. Le fichier CSV est fourni avec tous les clusters HDInsight Spark. Les données capturent les variations de température de certains bâtiments.
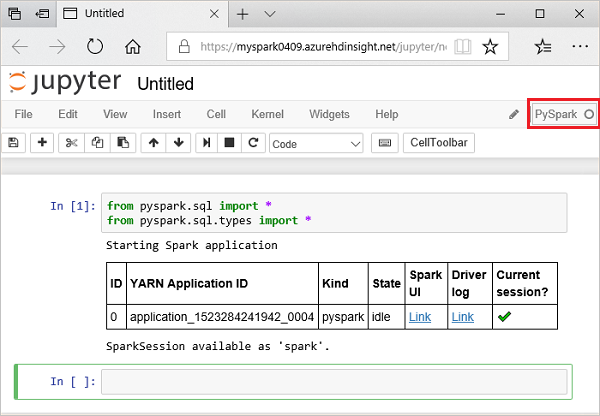
Collez l’exemple de code suivant dans une cellule vide du notebook Jupyter, puis appuyez sur MAJ + ENTRÉE pour exécuter le code. Le code importe les types requis pour ce scénario :
from pyspark.sql import * from pyspark.sql.types import *Lorsque vous exécutez une requête interactive dans Jupyter, la fenêtre du navigateur web ou la légende d’onglet affiche l’état (Occupé) ainsi que le titre du bloc-notes. Un cercle plein s’affiche également en regard du texte PySpark dans le coin supérieur droit. Une fois le travail terminé, ce cercle est remplacé par un cercle vide.
Notez l’ID de session retourné. D’après l’image ci-dessus, l’ID de session est 0. Si vous le souhaitez, vous pouvez récupérer les détails de la session en accédant à
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statements, où CLUSTERNAME est le nom de votre cluster Spark et ID est votre numéro d’ID de session.Exécutez le code suivant pour créer une trame de données et une table temporaire (hvac).
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Exécuter des requêtes sur datanami
Une fois la table créée, vous pouvez exécuter une requête interactive sur les données.
Exécutez le code suivant dans une cellule vide du bloc-notes :
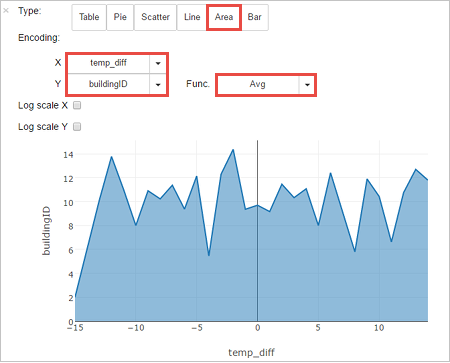
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"La sortie sous forme de tableau suivante s’affiche.
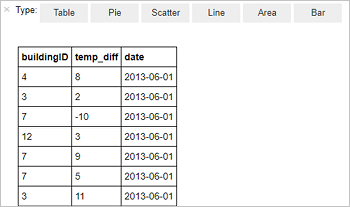
Vous pouvez également voir les résultats dans d’autres visualisations. Pour afficher un graphique en aires pour le même résultat, sélectionnez Area (Aires), puis définissez d’autres valeurs comme indiqué.
Dans la barre de menus du notebook, accédez à File (Fichier)>Save and Checkpoint(Enregistrer et créer un point de contrôle).
Si vous démarrez le didacticiel suivant maintenant, laissez le bloc-notes ouvert. Sinon, arrêtez le notebook pour libérer les ressources de cluster : dans la barre de menus, accédez à File (Fichier)>Close and Halt (Fermer et arrêter).
Nettoyer les ressources
Avec HDInsight, vos données et notebooks Jupyter sont stockés dans le stockage Azure ou dans Azure Data Lake Storage, ce qui vous permet de supprimer un cluster sans risque quand celui-ci n’est pas utilisé. Vous devez également payer pour un cluster HDInsight, même quand vous ne l’utilisez pas. Étant donné que les frais pour le cluster sont bien plus élevés que les frais de stockage, mieux vaut supprimer les clusters quand ils ne sont pas utilisés. Si vous prévoyez de suivre le tutoriel suivant immédiatement, vous souhaiterez peut-être conserver le cluster.
Ouvrez le cluster dans le portail Azure, puis sélectionnez Supprimer.
Vous pouvez également sélectionner le nom du groupe de ressources pour ouvrir la page du groupe de ressources, puis sélectionner Supprimer le groupe de ressources. En supprimant le groupe de ressources, vous supprimez le cluster HDInsight Spark et le compte de stockage par défaut.
Étapes suivantes
Dans ce didacticiel, vous avez appris à créer une trame de données à partir d'un fichier CSV et à exécuter des requêtes SQL Spark interactives sur un cluster Apache Spark dans Azure HDInsight. Passez à l’article suivant pour découvrir comment les données que vous avez inscrites dans Apache Spark peuvent être tirées (pull) et placées dans un outil analytique décisionnel tel que Power BI.