Configurer les paramètres d’Apache Spark
Un cluster HDInsight Spark comprend une installation de la bibliothèque Apache Spark. Chaque cluster HDInsight inclut des paramètres de configuration par défaut pour tous ses services installés, y compris Spark. L’un des principaux aspects de la gestion d’un cluster Apache Hadoop HDInsight est le monitoring de la charge de travail, notamment des travaux Spark. Pour exécuter les travaux Spark dans les meilleures conditions, tenez compte de la configuration physique du cluster au moment de déterminer sa configuration logique.
Le cluster Apache Spark HDInsight par défaut comporte les nœuds suivants : trois nœuds Apache ZooKeeper, deux nœuds principaux et un ou plusieurs nœuds Worker :
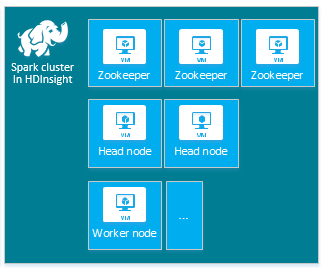
Le nombre et la taille des machines virtuelles pour les nœuds du cluster HDInsight peuvent avoir une incidence sur la configuration Spark. Les valeurs de configuration HDInsight autres que les valeurs par défaut nécessitent souvent des valeurs de configuration Spark spécifiques. Quand vous créez un cluster HDInsight Spark, des tailles de machine virtuelle vous sont suggérées pour chacun des composants. Les tailles de machine virtuelle Linux à mémoire optimisée pour Azure sont D12 v2 ou supérieur.
Versions d’Apache Spark
Utilisez la version de Spark la mieux adaptée à votre cluster. Le service HDInsight inclut plusieurs versions de Spark et de HDInsight. Chaque version de Spark comprend un ensemble de paramètres de cluster par défaut.
Lorsque vous créez un cluster, différentes versions de Spark sont disponibles. Pour connaître la liste complète, consultez Composants et versions de HDInsight.
Notes
La version par défaut d’Apache Spark dans le service HDInsight peut changer sans préavis. Si vous êtes dépendant d’une version, Microsoft vous recommande de spécifier cette version quand vous créez des clusters à l’aide du SDK .NET, d’Azure PowerShell et d’Azure Classic CLI.
Apache Spark a trois emplacements de configuration système :
- Les propriétés de Spark contrôlent la plupart des paramètres d’application et peuvent être définies à l’aide d’un objet
SparkConfou par le biais des propriétés système Java. - Les variables d’environnement permettent de définir les paramètres par machine, tels que l’adresse IP, par le biais du script
conf/spark-env.shsur chaque nœud. - Vous pouvez configurer la journalisation par le biais de
log4j.properties.
Quand vous sélectionnez une version particulière de Spark, votre cluster comprend les paramètres de configuration par défaut. Vous pouvez modifier la configuration par défaut de Spark à l’aide d’un fichier de configuration Spark personnalisé. Voici un exemple.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
L’exemple ci-dessus remplace plusieurs valeurs par défaut de cinq paramètres de configuration Spark. Ces valeurs sont le codec de compression, la taille minimale de fractionnement MapReduce Apache Hadoop et la taille des blocs Parquet, ainsi que la valeur par défaut de la partition Spark SQL et de la taille des fichiers ouverts. Ces modifications de configuration sont choisies parce que les données et travaux associés (dans cet exemple, des données génomiques) présentent des caractéristiques particulières dont l’efficacité est meilleure avec ces paramètres de configuration personnalisés.
Vérifier les paramètres de configuration du cluster
Vérifiez les paramètres actuels de configuration du cluster HDInsight avant d’effectuer une optimisation des performances sur le cluster. Lancez le tableau de bord HDInsight à partir du portail Azure en cliquant sur le lien Tableau de bord dans le volet du cluster Spark. Connectez-vous avec le nom d’utilisateur et le mot de passe de l’administrateur de cluster.
L’interface utilisateur web Apache Ambari s’ouvre sur un tableau de bord regroupant les principales métriques d’utilisation des ressources de cluster. Le tableau de bord Ambari montre la configuration d’Apache Spark et d’autres services installés. Il comporte un onglet Historique de la configuration permettant d’afficher des informations sur tous les services installés, y compris Spark.
Pour afficher les valeurs de configuration pour Apache Spark, sélectionnez Config History (Historique de la configuration), puis sélectionnez Spark2. Sélectionnez l’onglet Configs (Configurations), puis le lien Spark (ou Spark2, selon votre version) dans la liste des services. Une liste de valeurs de configuration pour votre cluster apparaît :
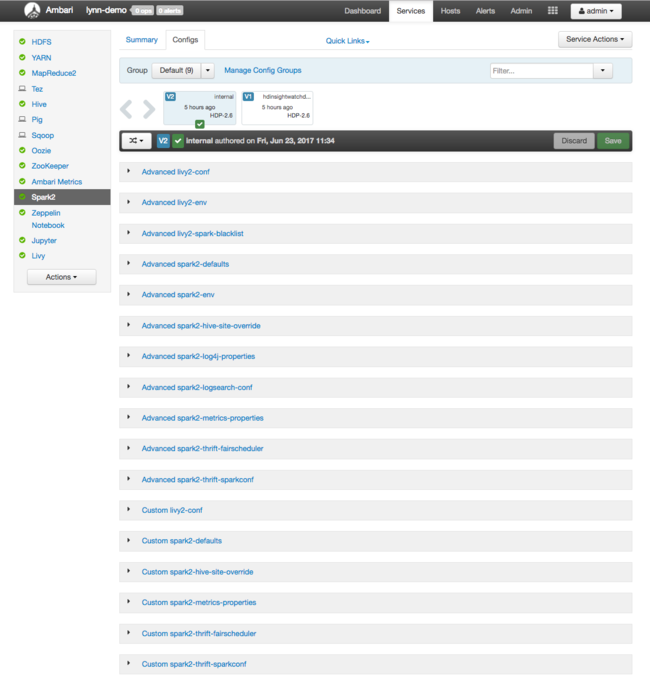
Pour afficher et modifier des valeurs de configuration de Spark spécifiques, sélectionnez un lien dont le titre contient « spark ». Les configurations de Spark incluent des valeurs de configuration personnalisées et avancées dans les catégories suivantes :
- Custom Spark2-defaults (Valeurs Spark2-defaults personnalisées)
- Custom Spark2-metrics-properties (Valeurs Spark2-metrics-properties personnalisées)
- Advanced Spark2-defaults (Valeurs Spark2-defaults avancées)
- Advanced Spark2-env (Valeurs Spark2-env avancées)
- Advanced spark2-hive-site-override (Valeurs spark2-hive-site-override avancées)
Si vous créez un ensemble de valeurs de configuration autre que l’ensemble par défaut, votre historique des mises à jour est visible. Cet historique de configuration peut être utile pour déterminer la configuration (autre que la configuration par défaut) dont les performances sont optimales.
Notes
Pour afficher, mais pas changer, les paramètres de configuration de cluster Spark courants, sélectionnez l’onglet Environment (Environnement) dans l’interface de niveau supérieur Spark Job UI (Interface utilisateur des travaux Spark).
Configuration des Exécuteurs Spark
Le diagramme suivant montre les objets Spark clés : le programme de pilote et son contexte Spark associé, ainsi que le gestionnaire de cluster et ses n nœuds Worker. Chaque nœud Worker inclut un Exécuteur, un cache et n instances de tâches.

Les travaux Spark utilisent des ressources Worker, notamment de la mémoire ; il est donc courant d’ajuster les valeurs de configuration de Spark pour les Exécuteurs des nœuds Worker.
Trois paramètres clés souvent ajustés pour paramétrer les configurations de Spark afin d’améliorer les exigences de l’application sont spark.executor.instances, spark.executor.cores et spark.executor.memory. Un exécuteur est un processus lancé pour une application Spark. Un Exécuteur s’exécute sur le nœud Worker et est responsable des tâches de l’application. Le nombre et la taille des nœuds Worker déterminent le nombre et la taille des exécuteurs. Ces valeurs sont stockées dans spark-defaults.conf sur les nœuds principaux du cluster. Vous pouvez les modifier dans un cluster en cours d’exécution en sélectionnant Valeurs spark-defaults personnalisées dans l’interface utilisateur web Ambari. Une fois que vous avez apporté des modifications, vous êtes invité par l’interface utilisateur à redémarrer tous les services concernés.
Notes
Ces trois paramètres de configuration peuvent être configurés au niveau du cluster (pour toutes les applications qui s’exécutent sur le cluster) et également spécifiés pour chaque application.
L’interface utilisateur d’application Spark représente une autre source d’informations sur les ressources utilisées par les exécuteurs Spark. Dans l’interface utilisateur, Exécuteurs présente les vues récapitulatives et détaillées de la configuration et des ressources consommées. Déterminez s’il faut modifier les valeurs des exécuteurs pour l’ensemble du cluster ou pour une série particulière d’exécutions de travaux.

Vous pouvez sinon utiliser l’API REST Ambari pour vérifier programmatiquement les paramètres de configuration du cluster HDInsight et Spark. Pour plus d’informations, voir Informations de référence sur l’API Apache Ambari sur GitHub.
En fonction de votre charge de travail Spark, vous pouvez déterminer qu’une configuration Spark autre que la configuration par défaut fournit une optimisation des exécutions des travaux Spark. Effectuez des tests d’évaluation avec des exemples de charges de travail afin de valider les configurations de cluster différentes des configurations par défaut. Certains des paramètres courants que vous pouvez envisager d’ajuster sont les suivants :
| Paramètre | Description |
|---|---|
| --num-executors | Définit le nombre d’exécuteurs. |
| --executor-cores | Définit le nombre de cœurs de chaque exécuteur. Nous vous recommandons d’utiliser des Exécuteurs de taille moyenne, car d’autres processus consomment également une partie de la mémoire disponible. |
| --executor-memory | Contrôle la taille de la mémoire (taille de segment) de chaque exécuteur sur Apache Hadoop YARN ; laissez de la mémoire pour la surcharge d’exécution. |
Voici un exemple de deux nœuds Worker avec des valeurs de configuration différentes :

La liste suivante affiche les paramètres de mémoire clés des exécuteurs Spark.
| Paramètre | Description |
|---|---|
| spark.executor.memory | Définit la quantité totale de mémoire disponible pour un exécuteur. |
| spark.storage.memoryFraction | (par défaut, environ 60 %) Définit la quantité de mémoire disponible pour le stockage de RDD persistants. |
| spark.shuffle.memoryFraction | (par défaut, environ 20 %) Définit la quantité de mémoire réservée pour la lecture aléatoire. |
| spark.storage.unrollFraction et spark.storage.safetyFraction | (au total, environ 30 % de la mémoire totale) Ces valeurs, utilisées en interne par Spark, ne doivent pas être modifiées. |
YARN contrôle la somme maximale de mémoire utilisée par les conteneurs sur chaque nœud Spark. Le diagramme suivant montre les relations par nœud entre les objets de configuration YARN et les objets Spark.

Changer les paramètres d’une application exécutée dans Jupyter Notebook
Les clusters Spark dans HDInsight incluent un certain nombre de composants par défaut. Chacun de ces composants inclut des valeurs de configuration par défaut qui peuvent être remplacées en fonction des besoins.
| Composant | Description |
|---|---|
| Spark Core | Spark Core, Spark SQL, API de streaming Spark, GraphX et Apache Spark MLlib. |
| Anaconda | Un gestionnaire de package Python. |
| Apache Livy | API REST Apache Spark, utilisée pour envoyer des travaux à distance à un cluster Spark HDInsight. |
| Notebooks Jupyter et notebooks Apache Zeppelin | Interface utilisateur interactive sur navigateur permettant d’interagir avec le cluster Spark. |
| Pilote ODBC | Connecte les clusters Spark dans HDInsight à des outils décisionnels comme Microsoft Power BI et Tableau. |
Pour les applications exécutées dans Jupyter Notebook, utilisez la commande %%configure afin d’apporter des modifications à la configuration depuis le notebook. Ces modifications de configuration sont appliquées aux travaux Spark exécutés à partir de votre instance de bloc-notes. Effectuez ces modifications au début de l’application, avant d’exécuter la première cellule de code. La configuration modifiée est appliquée à la session Livy au moment de sa création.
Notes
Pour changer la configuration ultérieurement dans l’application, utilisez le paramètre -f (forcer). Néanmoins, toute la progression de l’application est alors perdue.
Le code ci-dessous montre comment changer la configuration d’une application exécutée dans Jupyter Notebook.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Conclusion
Surveillez les paramètres de configuration de base de sorte que vos travaux Spark s’exécutent de manière prévisible et performante. Ces paramètres permettent de déterminer la meilleure configuration de cluster Spark pour vos charges de travail particulières. Vous devez également superviser l’exécution des travaux Spark longs ou gourmands en ressources. Les difficultés les plus courantes concernent la sollicitation de la mémoire résultant de configurations inappropriées (par exemple, des exécuteurs de taille incorrecte) ainsi que les opérations et les tâches de longue durée, qui entraînent des opérations cartésiennes.