Utiliser des blocs-notes Apache Zeppelin avec un cluster Apache Spark sur HDInsight
Les clusters HDInsight Spark incluent des blocs-notes Apache Zeppelin. Utilisez les notebooks pour exécuter des travaux Apache Spark. Dans cet article, vous allez apprendre à utiliser le bloc-notes Zeppelin sur un cluster HDInsight.
Prérequis
- Un cluster Apache Spark sur HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight.
- Le schéma d'URI de votre principal espace de stockage de clusters. Il peut s’agir de
wasb://pour Stockage Blob Azure, deabfs://pour Azure Data Lake Storage Gen2 ou deadl://pour Azure Data Lake Storage Gen1. Si le transfert sécurisé est activé pour le stockage Blob, l’URI serawasbs://. Pour plus d’informations, voir Exiger un transfert sécurisé dans Stockage Azure.
Lancer un bloc-notes Apache Zeppelin
Dans la section Vue d'ensemble du cluster Spark, accédez à Tableaux de bord du cluster et sélectionnez Bloc-notes Zeppelin. Entrez les informations d'identification de l'administrateur du cluster.
Notes
Vous pouvez également atteindre le bloc-notes Zeppelin pour votre cluster en ouvrant l'URL suivante dans votre navigateur. Remplacez CLUSTERNAME par le nom de votre cluster.
https://CLUSTERNAME.azurehdinsight.net/zeppelinCréer un nouveau bloc-notes. Dans le volet d'en-tête, accédez à Bloc-notes>Créer une note.

Entrez un nom pour le bloc-notes, puis sélectionnez Créer une note.
Vérifiez que l'en-tête du bloc-notes indique un état connecté. Il est indiqué par un point vert dans le coin supérieur droit.

Chargez un exemple de données dans une table temporaire. Lorsque vous créez un cluster Spark dans HDInsight, l'exemple de fichier de données
hvac.csvest copié sur le compte de stockage associé, sous\HdiSamples\SensorSampleData\hvac.Collez l’extrait suivant dans le paragraphe vide créé par défaut dans le nouveau bloc-notes.
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Appuyez sur MAJ + ENTRÉE ou sélectionnez le bouton Lire pour que le paragraphe exécute l’extrait de code. L’état indiqué dans le coin supérieur droit du paragraphe doit progresser de READY, PENDING, RUNNING à FINISHED. Le résultat s’affiche au bas du même paragraphe. La capture d’écran ressemble à l’image suivante :
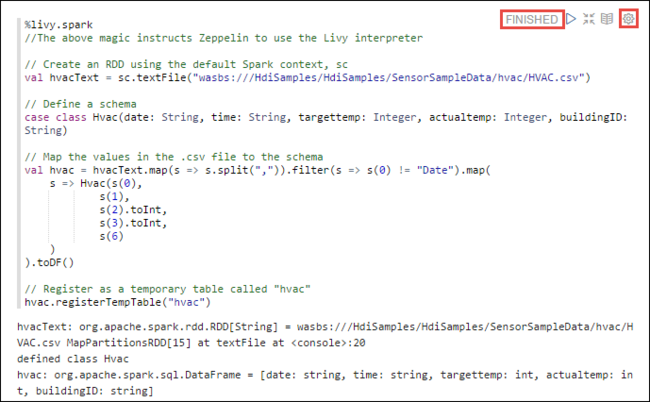
Vous pouvez également indiquer un titre pour chaque paragraphe. Dans le coin droit du paragraphe, sélectionnez l'icône Paramètres (pignon), puis sélectionnez Afficher le titre.
Notes
L’interpréteur %spark2 n’est pas pris en charge dans les bloc-notes Zeppelin sur toutes les versions HDInsight et l’interpréteur %sh ne sera pas pris en charge à partir de HDInsight 4.0 et versions ultérieures.
Vous pouvez maintenant exécuter des instructions Spark SQL dans la table
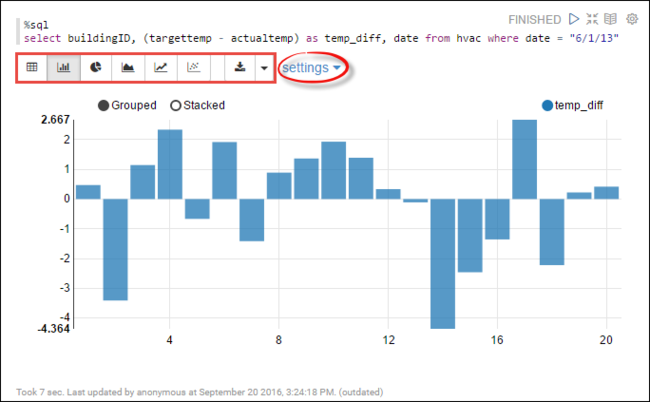
hvac. Collez la requête suivante dans un nouveau paragraphe. La requête récupère l’ID de bâtiment. Elle récupère également la différence entre les températures cible et réelle pour chaque bâtiment à une date donnée. Appuyez sur MAJ + ENTRÉE.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"L’instruction %sql du début demande au bloc-notes d’utiliser l’interpréteur Livy Scala.
Sélectionnez l'icône Graphique à barres pour modifier l'affichage. Les paramètres, apparaissent une fois que vous avez sélectionné Graphique à barres, ce qui vous permet de choisir des Clés et des Valeurs. La capture d’écran qui suit présente le résultat.
Vous pouvez également exécuter des instructions Spark SQL à l’aide de variables dans la requête. L'extrait suivant montre comment définir la variable
Tempdans la requête avec les valeurs d'interrogation possibles. Lors de la première exécution de la requête, une liste déroulante est automatiquement renseignée avec les valeurs que vous avez spécifiées pour la variable.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Collez cet extrait dans un nouveau paragraphe, puis appuyez sur MAJ + ENTRÉE. Sélectionnez ensuite 65 dans la liste déroulante Temp.
Sélectionnez l'icône Graphique à barres pour modifier l'affichage. Sélectionnez ensuite paramètres et apportez les modifications suivantes :
Groupes : Ajoutez targettemp.
Valeurs : 1. Supprimez date. 2. Ajoutez temp_diff. 3. Remplacez l'agrégateur SUM par AVG.
La capture d’écran qui suit présente le résultat.

Comment utiliser des packages externes avec le bloc-notes ?
Un bloc-notes Zeppelin dans un cluster Apache Spark sur HDInsight peut utiliser des packages externes bénéficiant de la contribution de la communauté, qui ne sont pas inclus dans le cluster. Recherchez le référentiel Maven pour obtenir la liste complète des packages disponibles. Vous pouvez également obtenir une liste des packages disponibles à partir d’autres sources. Par exemple, une liste complète des packages bénéficiant de la contribution de la communauté est disponible sur le site Spark Packages(Packages Spark).
Dans cet article, vous allez apprendre à utiliser le package spark-csv avec le notebook Jupyter.
Ouvrez les paramètres de l’interpréteur. Dans le coin supérieur droit, sélectionnez le nom de l'utilisateur connecté, puis Interpréteur.

Accédez à livy2, puis sélectionnez modifier.

Accédez à la clé
livy.spark.jars.packageset définissez sa valeur au formatgroup:id:version. Par conséquent, si vous souhaitez utiliser le package spark-csv, vous devez définir la valeur de la clé surcom.databricks:spark-csv_2.10:1.4.0.
Sélectionnez Enregistrer, puis OK pour redémarrer l’interpréteur Livy.
si vous souhaitez savoir comment atteindre la valeur de la clé entrée ci-dessus, lisez ce qui suit.
a. Recherchez le package dans le référentiel Maven. Dans cet article, nous avons utilisé spark-csv.
b. À partir du référentiel, rassemblez les valeurs pour GroupId, ArtifactId et Version.
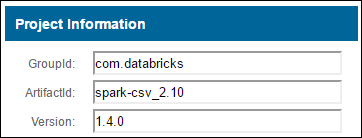
c. Concaténez les trois valeurs séparées par deux-points ( : ).
com.databricks:spark-csv_2.10:1.4.0
Où les blocs-notes Zeppelin sont-ils enregistrés ?
Les blocs-notes Zeppelin sont enregistrés dans les nœuds principaux du cluster. Par conséquent, si vous supprimez le cluster, les blocs-notes seront aussi supprimés. Si vous souhaitez conserver vos blocs-notes pour une utilisation ultérieure sur les autres clusters, vous devez les exporter après avoir terminé l’exécution des tâches. Pour exporter un bloc-notes, sélectionnez l'icône Exporter comme illustré sur l'image ci-dessous.

Cette action enregistre le bloc-notes en tant que fichier JSON dans votre emplacement de téléchargement.
Remarque
Dans HDI 4.0, le chemin d’accès au répertoire du notebook zeppelin est
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/par exemple /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
Dans HDI 5.0 et au-delà, ce chemin d’accès est différent
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/par exemple /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
Le nom de fichier stocké est différent dans HDI 5.0. Il est stocké en tant que
<notebook_name>_<sessionid>.zplnpar exemple testzeppelin_2JJK53XQA.zpln
Dans HDI 4.0, le nom de fichier n’est que note.json stocké dans le répertoire session_id.
par exemple /2JMC9BZ8X/note.json
HDI Zeppelin enregistre toujours le notebook dans le chemin d’accès
/usr/hdp/<version>/zeppelin/notebook/sur le disque local hn0.Si vous souhaitez que le notebook soit disponible même après la suppression du cluster, vous pouvez essayer d’utiliser le stockage de fichiers Azure (à l’aide du protocole SMB) et le lier au chemin local. Pour plus de détails, consultez Monter un partage de fichiers SMB Azure sur Linux
Après le montage, vous pouvez modifier la configuration zeppelin.notebook.dir vers le chemin monté dans l’interface utilisateur ambari.
- Le partage de fichiers SMB en tant que stockage GitNotebookRepo n’est pas recommandé pour zeppelin version 0.10.1
Utiliser Shiro pour configurer l’accès aux interpréteurs Zeppelin dans les clusters Pack Sécurité Entreprise (ESP)
Comme indiqué ci-dessus, l’interpréteur %sh n’est plus pris en charge à partir de HDInsight 4.0. En outre, puisque l’interpréteur %sh introduit des problèmes de sécurité potentiels, tels que l’accès à des keytabs à l’aide de commandes shell, il a également été supprimé des clusters ESP de HDInsight 3.6. Cela signifie que l’interpréteur %sh n’est pas disponible lorsque vous cliquez sur Créer une note ni dans l’interface utilisateur par défaut de l’interpréteur.
Les utilisateurs privilégiés de domaine peuvent utiliser le fichier Shiro.ini pour contrôler l’accès à l’interface utilisateur de l’interpréteur. Seuls ces utilisateurs peuvent créer des interpréteurs %sh et définir des autorisations sur chaque nouvel interpréteur %sh. Pour contrôler l’accès à l’aide du fichier shiro.ini, procédez comme suit :
Définissez un nouveau rôle à l’aide d’un nom de groupe de domaine existant. Dans l’exemple suivant,
adminGroupNameest un groupe d’utilisateurs privilégiés dans AAD. N’utilisez pas de caractères spéciaux ni d’espaces blancs dans le nom de groupe. Les caractères situés après=accordent les autorisations pour ce rôle.*signifie que le groupe dispose de toutes les autorisations.[roles] adminGroupName = *Ajoutez le nouveau rôle pour l’accès aux interpréteurs Zeppelin. Dans l’exemple suivant, tous les utilisateurs de
adminGroupNameont accès aux interpréteurs Zeppelin et peuvent créer des interpréteurs. Vous pouvez placer plusieurs rôles entre les crochets du paramètreroles[], séparés par des virgules. Ensuite, les utilisateurs disposant des autorisations nécessaires peuvent accéder aux interpréteurs Zeppelin.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Exemple shiro.ini pour plusieurs groupes de domaines :
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Gestion des sessions Livy
Le premier paragraphe de code de votre bloc-notes Zeppelin crée une session livy dans votre cluster. Cette session est partagée entre tous les blocs-notes Zeppelin que vous créez par la suite. Si la session livy est supprimée pour une raison quelconque, les travaux ne sont pas exécutés à partir du bloc-notes Zeppelin.
Dans ce cas, vous devez suivre les étapes suivantes avant de commencer à exécuter des tâches à partir d’un bloc-notes Zeppelin.
Redémarrez l’interpréteur Livy à partir du bloc-notes Zeppelin. Pour ce faire, ouvrez les paramètres de l'interpréteur en sélectionnant le nom de l'utilisateur connecté dans le coin supérieur droit, puis sélectionnez Interpréteur.
Accédez à livy2, puis sélectionnez redémarrer.
Exécutez une cellule de code à partir d’un bloc-notes Zeppelin existant. Ce code crée une session Livy dans le cluster HDInsight.
Informations générales
Valider le service
Pour valider le service à partir d’Ambari, accédez à https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary où CLUSTERNAME est le nom de votre cluster.
Pour valider le service à partir d’une ligne de commande, utilisez le protocole SSH pour accéder au nœud principal. Basculez l’utilisateur sur Zeppelin à l’aide de la commande sudo su zeppelin. Commandes relatives à l’état :
| Commande | Description |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
État du service. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Version du service. |
ps -aux | grep zeppelin |
Identifier le PID. |
Emplacements des journaux
| Service | Path |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Journaux d’activité du serveur | /var/log/zeppelin |
Interpréteur de configuration, Shiro, site.xml, log4j |
/usr/hdp/current/zeppelin-server/conf or /etc/zeppelin/conf |
| Répertoire PID | /var/run/zeppelin |
Activer l’enregistrement du débogage
Accédez à
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary, où CLUSTERNAME est le nom de votre cluster.Accédez à CONFIGS>Advanced zeppelin-log4j-properties>log4j_properties_content.
Remplacez
log4j.appender.dailyfile.Threshold = INFOparlog4j.appender.dailyfile.Threshold = DEBUG.Ajoutez
log4j.logger.org.apache.zeppelin.realm=DEBUG.Enregistrez les modifications et redémarrez le service.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour