Mise à l’échelle dans Service Fabric
Azure Service Fabric facilite la création d’applications évolutives en gérant les services, les partitions et les réplicas sur les nœuds d’un cluster. L’exécution de nombreuses charges de travail sur un même appareil permet une utilisation maximale des ressources, mais permet également de choisir la façon dont vous mettez à l’échelle vos charges de travail. Cette vidéo Channel 9 décrit comment vous pouvez générer des applications de microservices scalables :
Dans Service Fabric, la mise à l’échelle s’effectue de plusieurs manières :
- En créant ou en supprimant des instances de services sans état
- En créant ou en supprimant de nouveaux services nommés
- En créant ou en supprimant de nouvelles instances d’application nommées
- En utilisant des services partitionnés
- Mise à l’échelle par l’ajout ou la suppression de nœuds dans un cluster
- En utilisant des métriques Cluster Resource Manager
En créant ou en supprimant des instances de services sans état
L’une des méthodes les plus simples pour effectuer une mise à l’échelle dans Service Fabric est d’utiliser des services sans état. Lorsque vous créez un service sans état, vous avez la possibilité de définir un InstanceCount. InstanceCount définit le nombre de copies du code de ce service qui doivent être créées lorsque le service démarre. Supposons, par exemple, que le cluster comprenne 100 nœuds. Supposons également qu’un service soit créé avec un InstanceCount défini sur 10. Pendant l’exécution, ces 10 copies du code peuvent devenir toutes trop occupées (ou ne pas être suffisamment occupées). La mise à l’échelle de cette charge de travail consisterait à modifier le nombre d’instances. Par exemple, une partie du code de surveillance ou de gestion peut remplacer le nombre actuel d’instances par 50 ou 5, selon que la charge de travail a besoin d’effectuer un scale-in ou un scale-out en fonction de la charge.
C# :
StatelessServiceUpdateDescription updateDescription = new StatelessServiceUpdateDescription();
updateDescription.InstanceCount = 50;
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
PowerShell :
Update-ServiceFabricService -Stateless -ServiceName $serviceName -InstanceCount 50
Utilisation du nombre d’instances dynamiques
Service Fabric permet de modifier automatiquement le nombre d’instances, en particulier pour les services sans état. En effet, le service est mis à l’échelle dynamiquement à l’aide du nombre de nœuds disponibles. Pour utiliser ce comportement, définissez le nombre d’instances sur -1. InstanceCount = -1 est une instruction qui indique à Service Fabric d’exécuter ce service sans état sur chaque nœud. Si le nombre de nœuds change, Service Fabric modifie automatiquement le nombre d’instances à rechercher, garantissant ainsi que le service s’exécute sur tous les nœuds valides.
C# :
StatelessServiceDescription serviceDescription = new StatelessServiceDescription();
//Set other service properties necessary for creation....
serviceDescription.InstanceCount = -1;
await fc.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell :
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless -PartitionSchemeSingleton -InstanceCount "-1"
En créant ou en supprimant de nouveaux services nommés
Une instance de service nommée est une instance spécifique d’un type de service (consultez Cycle de vie d’une application Service Fabric) située dans une instance d’application nommée du cluster.
De nouvelles instances de services nommées peuvent être créées (ou supprimées) si les services sont trop ou trop peu occupés. Ainsi, les demandes sont réparties entre plusieurs instances de services, ce qui permet généralement de diminuer la charge sur les services existants. Lorsque vous créez des services, Service Fabric Cluster Resource Manager les distribue dans le cluster. Les décisions exactes sont régies par les métriques du cluster et d’autres règles de sélection élective. Les services peuvent être créés de différentes façons. Cependant, les méthodes les plus courantes consistent à utiliser des actions d’administration en appelant New-ServiceFabricService, ou à appeler CreateServiceAsync par programmation. CreateServiceAsync peut même être appelé à partir d’autres services exécutés dans le cluster.
La création dynamique de services peut être utilisée dans toutes sortes de scénarios et constitue un modèle commun. Prenons par exemple un service avec état représentant un workflow particulier. Les appels représentant le travail vont apparaître dans ce service, et ce dernier va exécuter les étapes du workflow et enregistrer sa progression.
Comment mettre à l’échelle ce service ? Le service peut avoir plusieurs locataires, accepter les appels et déclencher les étapes de nombreuses instances différentes d’un même workflow, le tout simultanément. Toutefois, cela peut rendre le code plus complexe, car il doit maintenant se soucier de nombreuses instances différentes issues d’un même workflow, mais chacune associée à des phases et à des clients différents. En outre, la gestion de plusieurs workflows à la fois ne permet pas de résoudre le problème de mise à l’échelle. Cela est dû au fait qu’à un moment donné, ce service va consommer trop de ressources pour une même machine. De nombreux services qui n’ont pas été conçus pour ce modèle connaissent également des difficultés en raison de certains goulots d’étranglement inhérents ou d’un ralentissement de leur code. Ces types de problèmes empêchent le service de fonctionner lorsque le nombre de workflows simultanés qu’il suit augmente.
L’une des solutions consiste à créer une instance de ce service pour chaque instance du workflow que vous souhaitez suivre. Il s’agit d’un excellent modèle qui fonctionne aussi bien pour les services avec état que sans état. Pour que ce modèle fonctionne, il est nécessaire d’avoir un autre service qui joue le rôle de gestionnaire de charge de travail. Le rôle de ce service est de recevoir les demandes et de les acheminer vers d’autres services. Le gestionnaire peut créer dynamiquement une instance du service de charge de travail lorsqu’il reçoit le message, puis passer les demandes à ces services. Le service de gestionnaire peut également recevoir des rappels lorsqu’un service de workflow donné a terminé son travail. Lorsque le gestionnaire reçoit ces rappels, il peut supprimer l’instance du service de workflow ou la conserver si d’autres appels sont attendus.
Les versions avancées de ce type de gestionnaire peuvent même créer des pools avec les services qu’il gère. Avec le pool, les nouvelles demandes n’ont pas à attendre que le service soit disponible. En effet, le gestionnaire peut choisir dans le pool un service de workflow qui n’est pas occupé, ou acheminer la demande de manière aléatoire. L’utilisation d’un pool de services accélère la gestion des nouvelles demandes, car il est alors moins probable que la demande doive attendre qu’un nouveau service soit disponible. La création de services est rapide, mais elle n’est ni gratuite ni instantanée. Le pool permet de réduire la durée d’attente de la demande avant qu’elle puisse être traitée. Ce gestionnaire et ce modèle de pool sont souvent utilisés lorsque le temps de réponse est important. Un autre modèle de gestionnaire courant consiste à mettre en file d’attente la demande, à créer le service en arrière-plan, puis à transmettre la demande. Vous pouvez également créer et supprimer des services en fonction de la quantité de travail actuellement en attente pour le service.
En créant ou en supprimant de nouvelles instances d’application nommées
La création et la suppression d’instances d’application entières sont similaires au modèle qui consiste à créer et à supprimer des services. Pour ce modèle, un gestionnaire de service prend la décision en fonction des demandes qu’il voit et des informations qu’il reçoit des autres services du cluster.
Dans quels cas faut-il créer une instance d’application nommée au lieu de créer des instances de services nommées dans une application existante ? Voici quelques cas :
- La nouvelle instance d’application est celle d’un client dont le code doit être exécuté sous une identité particulière ou certains paramètres de sécurité.
- Service Fabric permet de définir différents packages de code à exécuter sous des identités particulières. Pour lancer le même package de code sous des identités différentes, les activations doivent se produire dans des instances d’application différentes. Prenons le cas où vous avez déployé des charges de travail d’un client existant. Ces charges sont peut-être exécutées sous une identité particulière pour que vous puissiez surveiller et contrôler leur accès aux autres ressources, telles que les bases de données distantes ou d’autres systèmes. Dans ce cas, lorsqu’un nouveau client s’inscrit, vous ne souhaiterez probablement pas activer son code dans le même contexte (espace de processus). Vous pourriez le faire, mais dans ce cas, votre code de service aurait plus de mal à agir dans le contexte d’une identité particulière. Vous devez généralement disposer de plus de sécurité, d’isolation et de code de gestion d’identité. Au lieu d’utiliser différentes instances de service nommées au sein d’une même instance d’application, et donc d’un même espace de processus, vous pouvez utiliser différentes instances d’application Service Fabric nommées. Il est donc plus facile de définir différents contextes d’identité.
- La nouvelle instance d’application sert également à la configuration.
- Par défaut, toutes les instances de service nommées d’un type de service particulier au sein d’une instance d’application sont exécutées dans le même processus d’un nœud donné. Cela signifie que, même si vous pouvez configurer chaque instance de service différemment, cela se révèlera complexe. Les services doivent avoir un jeton qui leur permet de rechercher leur configuration dans un package de configuration. En général, il s’agit du nom du service. Cette méthode fonctionne bien, mais elle associe la configuration au nom de chaque instance de service nommée au sein de cette instance d’application. Cela peut être difficile à gérer et créer de la confusion, car la configuration est normalement un artefact au moment de la conception avec des valeurs spécifiques à l’instance d’application. La création d’autres services implique davantage de mises à niveau d’applications afin de modifier les informations des packages de configuration ou d’en déployer de nouveaux pour que les nouveaux services puissent consulter leurs informations. Il est souvent plus facile de créer une toute nouvelle instance d’application nommée. Ensuite, vous pouvez utiliser les paramètres d’application pour définir la configuration nécessaire aux services. Ainsi, tous les services qui sont créés dans cette instance d’application nommée peuvent hériter de ces paramètres de configuration. Par exemple, au lieu d’avoir un seul fichier config avec les paramètres et les personnalisations de chaque client, tels que les secrets ou les limites de ressources par client, vous auriez une instance d’application différente pour chaque client dans laquelle les paramètres seraient remplacés.
- La nouvelle application sert de limite de mise à niveau.
- Dans Service Fabric, plusieurs instances d’application nommées servent de limites pour la mise à niveau. La mise à niveau d’une instance d’application nommée n’affecte pas le code exécuté par une autre instance d’application nommée. Les différentes applications vont exécuter différentes versions du même code sur les mêmes nœuds. Dans ce cas, vous pouvez avoir besoin de prendre une décision quant à la mise à l’échelle, car vous pouvez choisir si le nouveau code doit subir les mêmes mises à niveau qu’un autre service. Disons, par exemple, qu’un appel arrive au gestionnaire de service qui est chargé de mettre à l’échelle des charges de travail d’un client en créant et en supprimant des services de manière dynamique. Dans ce cas, toutefois, l’appel est émis pour une charge de travail associée à un nouveau client. La plupart des clients aiment être isolés les uns des autres, pas seulement pour les raisons de sécurité et de configuration énoncées précédemment, mais, parce que cela leur permet de choisir les versions logicielles à exécuter et le moment de la mise à niveau. Vous pouvez également créer une nouvelle instance d’application et y créer le service en vue de partitionner le nombre de services qui doivent être concernés par la mise à niveau. La séparation des instances d’application permet une plus grande granularité lors des mises à niveau d’application, et permet également d’effectuer des test A/B et des déploiements Blue/Green.
- L’instance d’application existante est pleine.
- Dans Service Fabric, la capacité de l’application est un concept qui vous permet de contrôler la quantité de ressources disponibles pour certaines instances d’application. Par exemple, vous pouvez décider qu’un service donné nécessite la création d’une autre instance pour être mis à l’échelle. Toutefois, cette instance d’application n’a plus de capacité pour une certaine métrique. Si une charge de travail ou un client spécifique nécessitent encore davantage de ressources, vous pouvez augmenter la capacité existante de cette application ou créer une nouvelle application.
Mise à l'échelle au niveau de la partition
Service Fabric prend en charge le partitionnement. Le partitionnement divise un service en plusieurs sections logiques et physiques, indépendantes les unes des autres. Cela se révèle utile pour les services avec état, car aucun jeu de réplicas n’a à traiter tous les appels ni à manipuler tous les états à la fois. L'article Vue d'ensemble du partitionnement fournit des informations sur les types de schémas de partitionnement pris en charge. Les réplicas de chaque partition sont répartis entre les nœuds d’un cluster, distribuant ainsi la charge du service et garantissant que ni le service dans son ensemble ni aucune des partitions ne comprennent un point de défaillance unique.
Imaginez un service qui utilise un schéma de partitionnement par plage avec une clé basse de 0, une clé haute de 99 et 4 partitions. Dans un cluster à trois nœuds, le service peut être disposé avec quatre réplicas partageant les ressources sur chaque nœud, comme illustré ici :
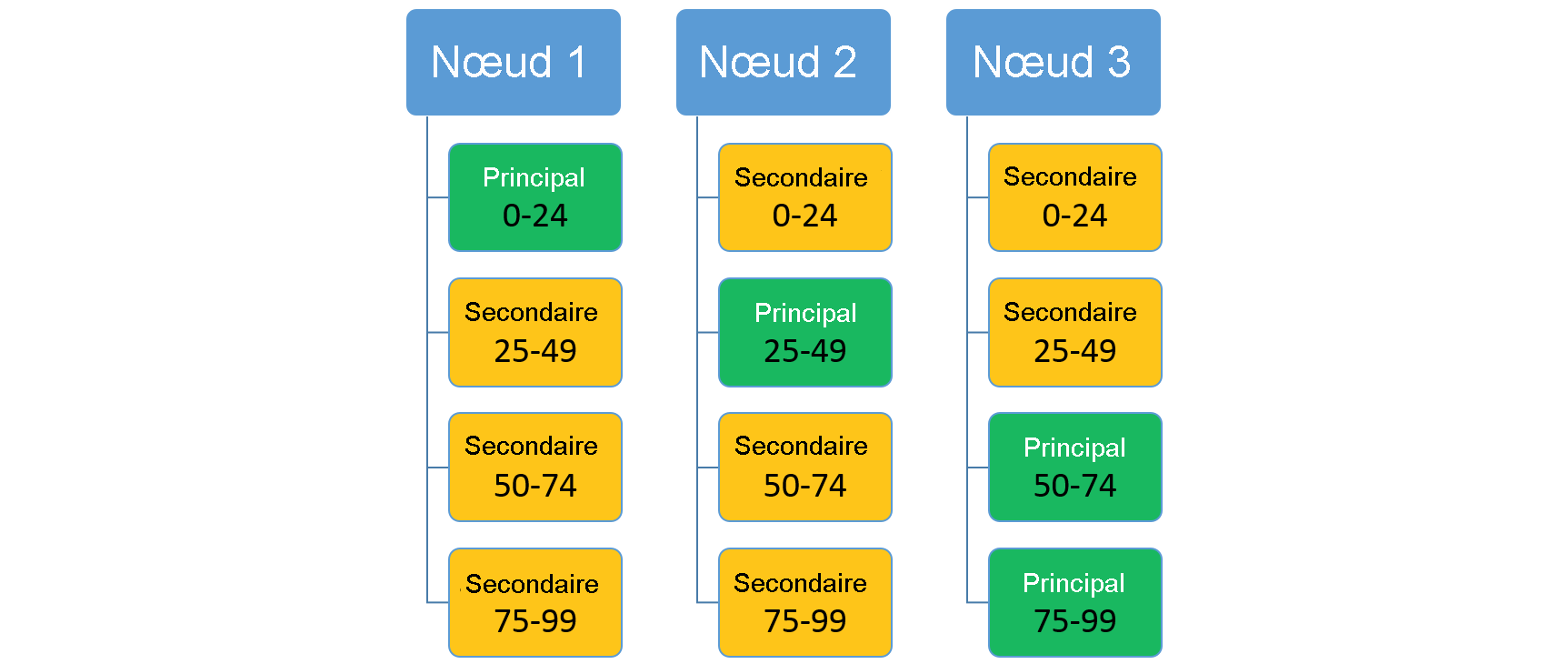
Si vous augmentez le nombre de nœuds, Service Fabric va déplacer certains des réplicas existants vers ces nouveaux nœuds. Supposons, par exemple, que le nombre de nœuds passe à quatre et que les réplicas soient redistribués. Trois réplicas sont maintenant exécutés sur chacun des nœuds, qui appartiennent chacun à des partitions différentes. Cela permet une meilleure utilisation des ressources, étant donné que le nouveau nœud n’est pas passif. En règle générale, cela améliore également les performances, car davantage de ressources sont disponibles pour chacun des services.

Mise à l’échelle à l’aide de Service Fabric Cluster Resource Manager et des métriques
Les métriques correspondent à la façon dont les services expriment leur consommation de ressources à Service Fabric. L’utilisation des métriques permet à Cluster Resource Manager de réorganiser et d’optimiser la disposition du cluster. Par exemple, il peut y avoir suffisamment de ressources dans le cluster, mais elles peuvent ne pas être allouées aux services qui sont actuellement utilisés. L’utilisation des métriques permet à Cluster Resource Manager de réorganiser le cluster de manière à garantir que les services ont accès aux ressources disponibles.
Mise à l’échelle par l’ajout ou la suppression de nœuds dans un cluster
Une autre option de mise à l’échelle avec Service Fabric consiste à modifier la taille du cluster. Modifier la taille du cluster signifie ajouter ou supprimer des nœuds d’un ou plusieurs types dans le cluster. Supposons, par exemple, que tous les nœuds du cluster soient actifs. Cela signifie que quasiment toutes les ressources du cluster sont consommées. Dans ce cas, l’ajout de nœuds supplémentaires au cluster est le meilleur moyen d’effectuer la mise à l’échelle. Une fois que les nouveaux nœuds ont rejoint le cluster, Service Fabric Cluster Resource Manager déplace les services vers ces nœuds, ce qui diminue la charge totale sur les nœuds existants. Pour les services sans état avec « instance count = -1 », des instances de service supplémentaires sont créées automatiquement. Cela permet à certains appels d’être déplacés des nœuds existants vers les nouveaux nœuds.
Pour plus d’informations, consultez Mise à l’échelle de cluster.
Choix d’une plateforme
En raison des différences d’implémentation entre les systèmes d’exploitation, le choix d’utiliser Service Fabric sous Windows ou Linux peut être un élément essentiel de la mise à l’échelle de votre application. L’une des barrières potentielles est l’exécution de la journalisation intermédiaire. Service Fabric sous Windows utilise un pilote noyau pour un journal par machine, partagé entre les réplicas de service dynamique. Ce journal pèse environ 8 Go. Linux, d’autre part, utilise un journal de mises en lots de 256 Mo pour chaque réplica, ce qui le rend moins intéressant pour les applications qui veulent maximiser le nombre de réplicas de service légers fonctionnant sur un nœud donné. Ces différences dans les besoins de stockage temporaire pourraient potentiellement informer la plateforme souhaitée sur le déploiement du cluster Service Fabric.
Exemple complet
Reprenons toutes les idées que nous avons évoquées et prenons un exemple. Supposons que vous essayiez de créer un service qui agit comme un carnet d’adresses, avec les noms et les coordonnées de personnes.
Avant même de commencer, vous avez un certain nombre de questions concernant la mise à l’échelle : Combien d’utilisateurs allez-vous avoir ? Combien de contacts chaque utilisateur va-t-il stocker ? Tenter de comprendre toutes ces questions lorsque vous mettez en place votre service pour la première fois n’est pas chose facile. Supposons que vous souhaitiez utiliser un seul service statique avec un certain nombre de partitions. Si vous ne choisissez pas le bon nombre de partitions, vous pourriez rencontrer des problèmes de mise à l’échelle plus tard. Même si vous choisissez le nombre de partitions adéquat, il est possible que vous n’ayez pas toutes les informations dont vous avez besoin. Par exemple, avant de commencer, vous devez également décider de la taille du cluster, c’est-à-dire du nombre de nœuds qu’il doit contenir et de la taille de chacun d’eux. Il est généralement difficile de savoir à l’avance le nombre de ressources qu’un service va consommer pendant sa durée de vie. Il peut également être difficile de prédire le modèle de trafic que le service va connaître. Par exemple, il est possible que les personnes ne puissent ajouter et supprimer leurs contacts qu’en début de matinée ou qu’elles puissent le faire à tout moment de la journée. En fonction de cela, vous devrez peut-être effectuer un scale-out ou un scale-in dynamiquement. Vous pouvez certes apprendre à prédire si vous aurez besoin d’effectuer un scale-out ou un scale-in, mais une chose est sûre, vous allez devoir vous adapter aux changements de consommation de votre service. Cela peut impliquer la modification de la taille du cluster afin de fournir davantage de ressources lorsque la réorganisation de l’utilisation des ressources existantes ne suffit pas.
Mais pourquoi essayer de choisir un seul schéma de partition pour tous les utilisateurs ? Pourquoi vous limiter à un seul service et à un seul cluster statique ? En effet, la situation réelle est généralement plus dynamique.
Lorsque vous créez des services devant subir une mise à l’échelle, envisagez le modèle dynamique ci-dessous. Vous aurez peut-être à l’adapter à votre situation :
- Plutôt que d’essayer de choisir un schéma de partitionnement global à l’avance, créez un « service gestionnaire ».
- Le travail de ce service gestionnaire est d’examiner les informations relatives aux clients lorsqu’ils se connectent à votre service. En fonction de ces informations, le service gestionnaire crée une instance de votre service de stockage de contacts réel, juste pour ce client. Si une configuration, une isolation ou une mise à niveau particulières sont nécessaires, vous pouvez également décider de rendre disponible une instance d’application pour ce client.
Ce modèle de création dynamique présente de nombreux avantages :
- Vous n’avez pas à deviner le nombre de partitions adéquat pour tous les utilisateurs ni à créer un service unique qui doive être mis à l’échelle indéfiniment.
- Les utilisateurs ne sont pas obligés d’avoir le même nombre de partitions, de réplicas, de contraintes de sélection élective, de métriques, de charges par défaut, de noms de service, de paramètres DNS ou d’autres propriétés spécifiées au niveau du service ou de l’application.
- Vous bénéficiez d’une segmentation des données supplémentaire. Chaque client dispose de sa propre copie du service.
- Chaque service client peut être configuré différemment et avoir accès à plus ou moins de ressources, avec plus ou moins de partitions ou de réplicas, en fonction de l’échelle attendue.
- Par exemple, supposons que le client ait choisi le niveau tarifaire « Gold ». Il peut ainsi disposer de davantage de réplicas et de partitions, et donc de davantage de ressources dédiées à ses services via les métriques et les fonctionnalités d’application.
- Ou supposons qu’il indique que le nombre de contacts dont il a besoin est « limité ». Ce client ne va alors disposer que de quelques partitions, voire être ajouté à un pool de services partagé avec d’autres clients.
- Chaque service client peut être configuré différemment et avoir accès à plus ou moins de ressources, avec plus ou moins de partitions ou de réplicas, en fonction de l’échelle attendue.
- Vous n’exécutez pas un ensemble d’instances de service ou de réplicas en attendant que les clients veuillent bien se connecter.
- Si un client quitte le service, la suppression des informations de votre service est aussi simple que de laisser le service de gestionnaire supprimer le service ou l’application qu’il a créés.
Étapes suivantes
Pour plus d’informations sur les concepts propres à Service Fabric, consultez les articles suivants :
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour