Surveiller Cloud Connector avec Operations Management Suite (OMS)
Important
Cloud Connector Edition sera mis hors service le 31 juillet 2021 avec Skype Entreprise Online. Une fois que votre organization a été mis à niveau vers Teams, découvrez comment connecter votre réseau téléphonique local à Teams à l’aide du routage direct.
Lisez cet article pour découvrir comment surveiller votre déploiement Cloud Connector version 2.1 et ultérieure à l’aide de Microsoft Operations Management Suite (OMS).
Vous pouvez désormais surveiller votre déploiement Cloud Connector version 2.1 et ultérieure à l’aide d’Operations Management Suite (OMS), une solution de gestion informatique cloud Microsoft. OMS Log Analytics vous permet de surveiller et d’analyser la disponibilité et les performances des ressources, y compris les machines physiques et virtuelles. Pour plus d’informations sur OMS et Log Analytics, consultez Qu’est-ce qu’Operations Management Suite (OMS) ?
Cet article contient les sections suivantes :
Conditions préalables
Configurer Cloud Connector pour utiliser OMS
Configurer OMS
Analyser les alertes dans votre référentiel Log Analytics
Ensemble de surveillance recommandé
Conditions préalables
Avant de pouvoir utiliser OMS pour surveiller votre déploiement Cloud Connector, vous aurez besoin des éléments suivants :
Un compte Azure et un espace de travail OMS. Si vous n’avez pas encore de compte Azure, vous devez en créer un pour utiliser OMS Log Analytics. Pour plus d’informations sur la création d’un compte Azure et la configuration d’un espace de travail OMS, consultez Prise en main d’un espace de travail Log Analytics.
Cloud Connector version 2.1 ou ultérieure
Une nouvelle recherche dans les journaux Log Analytics est requise pour la surveillance de Cloud Connector. Pour plus d’informations, consultez Mettre à niveau votre espace de travail Azure Log Analytics vers une nouvelle recherche dans les journaux.
Configurer Cloud Connector pour utiliser OMS
Vous devez configurer votre environnement local Cloud Connector pour utiliser OMS. Pour ce faire, vous avez besoin de l’ID et de la clé de votre espace de travail OMS, que vous pouvez trouver à l’aide du portail OMS comme suit : Paramètres -->Sources connectées --> Serveurs Windows :
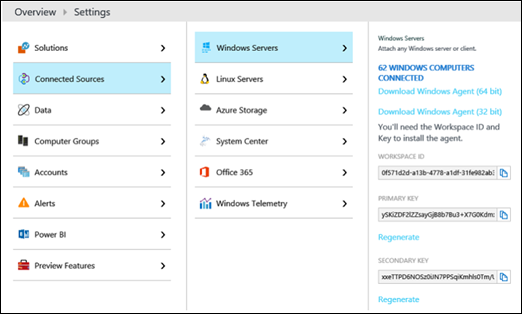
La façon dont vous configurez Cloud Connector pour utiliser OMS dépend de votre scénario :
Si vous installez un nouveau cloud Connector Appliance ou si vous souhaitez redéployer un Appliance, procédez comme suit avant d’exécuter Install-CcAppliance :
Dans la section CloudConnector.ini fichier [Commun], définissez le paramètre OMSEnabled sur True.
Chaque fois que Cloud Connector est déployé ou mis à niveau, il tente d’installer automatiquement l’agent OMS sur les machines virtuelles. Activez cette fonctionnalité pour que l’agent OMS puisse survivre à la mise à jour automatique de Cloud Connector.
Pour configurer l’ID et la clé OMS, exécutez Set-CcCredential -AccountType OMSWorkspace.
Si vous installez un agent OMS sur un Appliance Cloud Connector existant, procédez comme suit :
Dans la section CloudConnector.ini fichier [Commun], définissez OMSEnabled=true.
Exécutez Import-CcConfiguration.
Exécutez Install-CcOMSAgent.
Remarque
Si les informations d’identification OMSWorkspace n’ont jamais été définies, vous êtes invité à entrer les informations d’identification lorsque vous exécutez install-CcOMSAgent.
Si vous souhaitez mettre à jour l’ID ou la clé de l’espace de travail OMS dans un Appliance Cloud Connector qui a déjà installé un agent OMS :
Pour configurer l’ID et la clé OMS, exécutez Set-CcCredential -AccountType OMSWorkspace.
Pour appliquer les mises à jour, exécutez Install-CcOMSAgent.
Pour tous les scénarios, vérifiez que les agents sont connectés comme suit :
Dans le portail OMS, accédez à Paramètres -> Sources connectées -> Serveurs Windows. Vous voyez une liste des machines connectées.
Configurer OMS
Ensuite, vous devez spécifier votre configuration OMS à l’aide du portail OMS. Plus précisément, vous devez :
Spécifiez des informations sur les journaux des événements et les compteurs de performances.
Créer des alertes.
Spécifier des informations sur les journaux des événements et les compteurs de performances
Dans le portail OMS, vous devez spécifier des informations sur les journaux des événements et les compteurs de performances comme suit :
Accédez à Paramètres-Données-Journaux>> des événements Windows et ajoutez les journaux des événements pour :
Lync Server
Application
Remarque
Vous devez entrer manuellement Lync Server dans la zone de texte. Elle n’apparaît pas en tant qu’option dans la liste déroulante.
Pour plus d’informations, consultez Sources de données du journal des événements Windows dans Log Analytics
Accédez à Paramètres-Données> -> Compteurs de performances Windows et ajoutez des compteurs de performances pour :
Compteurs au niveau du système d’exploitation. Vous pouvez ajouter des compteurs au niveau du système d’exploitation, tels que l’utilisation du processeur, l’utilisation de la mémoire, l’utilisation du réseau, ou vous pouvez utiliser des solutions existantes telles que capacité et performances, Analyseur de performances réseau sans ajouter explicitement de compteurs. Quelle que soit la façon dont vous décidez de les surveiller, Microsoft vous recommande de surveiller ces compteurs de système d’exploitation.
Skype Entreprise compteurs. Il existe de nombreux compteurs fournis par Skype Entreprise. Vous pouvez trouver ces compteurs en vous connectant à n’importe quel serveur de médiation et en ouvrant le Analyseur de performances. Ces compteurs commencent par « LS : ». Microsoft vous recommande de commencer avec les compteurs de capacité suivants au minimum et d’en ajouter d’autres qui sont intéressants :
Nombre total d’appels actifs :
LS :MediationServer - Appels entrants(_Total)- Actuel
LS :MediationServer - Appels sortants(_Total)- Actuel
Nombre total d’appels de contournement de média actifs :
LS :MediationServer - Appels entrants(_Total)- Appels de contournement multimédia actifs
LS :MediationServer - Appels sortants (_Total)- Appels de contournement multimédia actifs
Remarque
Vous devez entrer manuellement les compteurs de performances dans la zone de texte. Elles n’apparaissent pas en tant qu’options dans la liste déroulante.
Pour plus d’informations, consultez Sources de données de performances Windows et Linux dans Log Analytics
Créer des alertes
Il existe deux types d’alertes dans OMS : les alertes de nombre de résultats et les alertes de mesure de métrique. Pour plus d’informations sur la création d’alertes, consultez Utilisation des règles d’alerte dans Log Analytics.
Vous devez prendre en compte les points suivants lors de la création d’alertes :
Assurez-vous que l’alerte est une alerte Nombre de résultats, qui est la sélection par défaut.
Les requêtes de démonstration nécessitent que « Nombre de résultats » soit défini sur « Supérieur à 0 ».
Il est recommandé de définir la fenêtre de temps et la fréquence de l’alerte sur 5 minutes.
Il est recommandé de ne pas activer « Supprimer les alertes » pour les alertes de démonstration.
Pour les scénarios d’alerte classiques, Microsoft recommande de créer une paire d’alertes : une alerte d’erreur et une alerte de réinitialisation. Pour l’alerte d’erreur, sélectionnez niveau de gravité Critique ; pour l’alerte de réinitialisation, sélectionnez niveau de gravité Information.
Les sections suivantes décrivent comment créer des exemples d’alertes.
Créez une paire d’alertes : « RTCMEDSRV n’est PAS en cours d’exécution dans les serveurs de médiation » et « RTCMEDSRV est de nouveau en cours d’exécution dans les serveurs de médiation »
Pour créer cette paire d’alertes :
La requête pour l’alerte d’erreur est la suivante :
Event | where Computer contains "MediationServer" | where EventLog == "Lync Server" and (EventID == 25002 or EventID == 25003) | summarize arg_max(TimeGenerated, EventID) by Computer | where EventID == 25003La requête utilise le filtre d’ordinateur où Ordinateur contient « MediationServer ». Le filtre sélectionne uniquement l’ordinateur dont le nom contient la chaîne « MediationServer ».
Vous devez remplacer le filtre par votre propre filtre d’ordinateur ou le supprimer. Vous pouvez créer des filtres de chaîne complexes sans expressions régulières. Vous pouvez également choisir d’utiliser des expressions régulières. En outre, vous pouvez créer un groupe d’ordinateurs en enregistrant une requête de recherche et en utilisant ce groupe comme filtre d’ordinateur dans votre requête d’alerte. Pour plus d’informations, consultez Groupes d’ordinateurs dans les recherches de journaux Log Analytics.
Pour chaque ordinateur, la requête d’erreur obtient le dernier journal des événements pour le démarrage et l’arrêt du service RTCMEDSRV. Il retourne un journal si le dernier événement est l’événement d’arrêt du service ; elle ne retourne rien si le dernier événement est l’événement de démarrage du service. En bref, la requête retourne une liste des serveurs dont RTCMEDSRV est arrêté dans la fenêtre de temps.
La requête pour l’alerte de réinitialisation est la suivante :
Event | where Computer contains "MediationServer" | where EventLog == "Lync Server" and (EventID == 25002 or EventID == 25003) | summarize arg_max(TimeGenerated, EventID) by Computer | where EventID == 2500La requête de réinitialisation effectue exactement la chose inverse de la requête d’erreur. Pour chaque ordinateur, il en retourne un si le dernier événement est l’événement de début de service ; elle ne retourne rien si le dernier événement est l’événement d’arrêt de service.
Créez une paire d’alertes : « Trop d’appels simultanés dans les serveurs de médiation » et « Les appels simultanés reviennent à une charge normale »
Pour créer cette alerte :
La requête pour l’alerte d’erreur est la suivante :
Perf | where Computer contains "MediationServer" | where (ObjectName == "LS:MediationServer - Outbound Calls" or ObjectName == "LS:MediationServer - Inbound Calls") | summarize arg_max(TimeGenerated, CounterValue) by ObjectName, Computer | summarize TotalCalls = sum(CounterValue) by Computer| where TotalCalls >= 500Pour chaque ordinateur, la requête obtient les derniers compteurs pour les appels entrants et sortants, et additionne ces deux valeurs. Elle retourne un journal si la valeur de somme dépasse 500 ; si ce n’est pas le cas, elle ne retournera rien. En bref, la requête retournerait une liste de serveurs dont les appels simultanés sont trop nombreux dans la fenêtre de temps.
La requête pour l’alerte de réinitialisation est la suivante :
Perf | where Computer contains "MediationServer" | where (ObjectName == "LS:MediationServer - Outbound Calls" or ObjectName == "LS:MediationServer - Inbound Calls") | summarize arg_max(TimeGenerated, CounterValue) by ObjectName, Computer | summarize TotalCalls = sum(CounterValue) by Computer| where TotalCalls < 500La requête de réinitialisation effectue exactement la chose inverse de la requête d’erreur. Pour chaque ordinateur, la requête obtient les derniers compteurs pour les appels entrants et sortants, et additionne ces deux valeurs. Elle retourne un journal si la valeur de somme est inférieure à 500 ; il ne retournera rien sinon.
Créer une alerte : alerte « Utilisation > du processeur 90 ou RTCMEDIARELAY arrêtée dans les serveurs »
Pour créer cette alerte, la requête est la suivante :
search *| where Computer contains "MediationServer" | where (Type == "Perf" or Type == "Event") | where ((ObjectName == "Processor" and CounterName == "% Processor Time") or EventLog == "Lync Server") | where (CounterValue > 90 or EventID == 22003)
La requête obtient tous les compteurs d’utilisation du processeur et l’événement d’arrêt de service de tous les ordinateurs et retourne un journal si l’utilisation du processeur dépasse 90 % ou si le service est arrêté.
Analyser les alertes dans votre référentiel Log Analytics
Pour analyser les alertes dans votre dépôt, utilisez la solution Gestion des alertes. Pour plus d’informations, consultez Solution de gestion des alertes dans Operations Management Suite (OMS)
Jeu de surveillance minimal recommandé
Pour identifier les problèmes liés aux journaux des événements et aux compteurs de performances :
Journaux des événements. Pour tout problème, il doit y avoir une paire d’événements, avec un ensemble d’événements pour indiquer un problème, tandis que l’autre indique que tout va bien. Pour une période donnée, il s’agit du dernier événement enregistré qui indiquera si quelque chose est anormal pour cette période.
Compteurs de performances. Il doit y avoir un seuil pour les compteurs surveillés.
Le tableau suivant répertorie les services que Microsoft recommande de surveiller en répertoriant les ID d’événement d’arrêt et de démarrage :
| Nom du service |
Rôle serveur cible |
ID d’événement d’arrêt |
ID d’événement de démarrage |
|---|---|---|---|
| RTCMEDSRV |
serveur de médiation |
25003 |
25002 |
| RTCSRV |
serveur Edge |
12289 |
12288 |
| RTCMRAUTH |
serveur Edge |
19003 |
19002 |
| RTCMEDIARELAY |
serveur Edge |
22003 |
22002 |
Le tableau suivant répertorie les problèmes réseau que Microsoft recommande de surveiller :
| Nom du moniteur |
Rôle serveur cible |
Expression d’ID d’événement de réussite |
Expression d’ID d’événement d’erreur |
Exemple d’échec |
|---|---|---|---|---|
| Échec de connectivité du serveur de médiation à la passerelle |
serveur de médiation |
25062 | 25002 |
|
| Échec de la saisie semi-automatique de l’appel du serveur de médiation vers la passerelle |
serveur de médiation |
25064 | 25002 |
|
| Problèmes réseau critiques |
serveur Edge |
14353 | 12288 |
L’exemple suivant répertorie les compteurs de capacité d’appel qui doivent être surveillés. Ces nombres doivent être inférieurs à 500 pour l’édition standard de Cloud Connector ; moins de 50 pour l’édition minimale de Cloud Connector.
LS :MediationServer - Appels entrants(_Total)- Actuel
LS :MediationServer - Appels sortants(_Total)- Actuel
LS :MediationServer - Appels entrants(_Total)- Appels de contournement multimédia actifs
LS :MediationServer - Appels sortants (_Total)- Appels de contournement multimédia actifs
Voir aussi
Pour plus d’informations sur l’utilisation d’OMS, consultez les rubriques suivantes :