Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à : SQL Server 2019 et versions ultérieures Analysis Services Azure Analysis Services Fabric/Power BI Premium
SQL Server 2019 et versions ultérieures Analysis Services Azure Analysis Services Fabric/Power BI Premium
Les groupes de calcul peuvent réduire de manière significative le nombre de mesures redondantes en regroupant les expressions de mesure courantes en tant qu’éléments de calcul. Les groupes de calcul sont pris en charge dans les modèles tabulaires au niveau de compatibilité 1500 et supérieur.
Avantages
Les groupes de calcul résolvent un problème dans les modèles complexes où il peut y avoir une prolifération de mesures redondantes à l’aide des mêmes calculs , les plus courants avec les calculs d’intelligence temporelle. Par exemple, un analyste des ventes souhaite afficher les totaux des ventes et les commandes par mois à date (MTD), trimestre à date (QTD), année à jour (YTD), commandes année à jour pour l’année précédente (PY), et ainsi de suite. Le modélisateur de données doit créer des mesures distinctes pour chaque calcul, ce qui peut entraîner des dizaines de mesures. Pour l’utilisateur, cela peut signifier avoir à trier autant de mesures et à les appliquer individuellement à leur rapport.
Examinons d’abord comment les groupes de calcul apparaissent aux utilisateurs d’un outil de création de rapports comme Power BI. Nous allons ensuite examiner ce qui compose un groupe de calcul et comment ils sont créés dans un modèle.
Les groupes de calcul sont affichés dans les clients de création de rapports sous forme de table avec une seule colonne. La colonne n’est pas comme une colonne ou une dimension classique, elle représente plutôt un ou plusieurs calculs réutilisables, ou des éléments de calcul qui peuvent être appliqués à n’importe quelle mesure déjà ajoutée au filtre Valeurs pour une visualisation.
Dans l’animation suivante, un utilisateur analyse les données des ventes pendant les années 2012 et 2013. Avant d’appliquer un groupe de calcul, la mesure de base commune Sales calcule une somme du total des ventes pour chaque mois. L’utilisateur souhaite ensuite appliquer des calculs time intelligence pour obtenir les totaux des ventes du mois à la date, du trimestre à la date, de l’année à la date, et ainsi de suite. Sans groupes de calcul, l’utilisateur doit sélectionner des mesures d’intelligence temporelle individuelles.
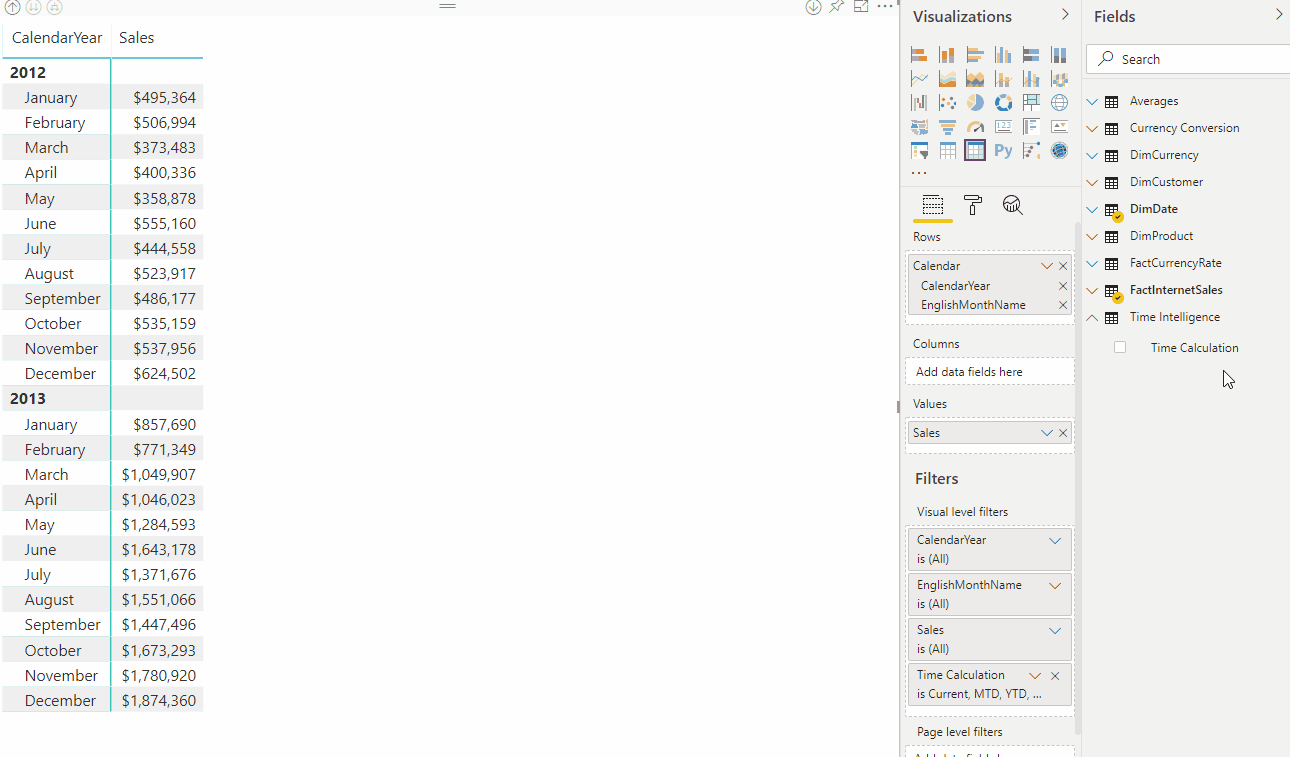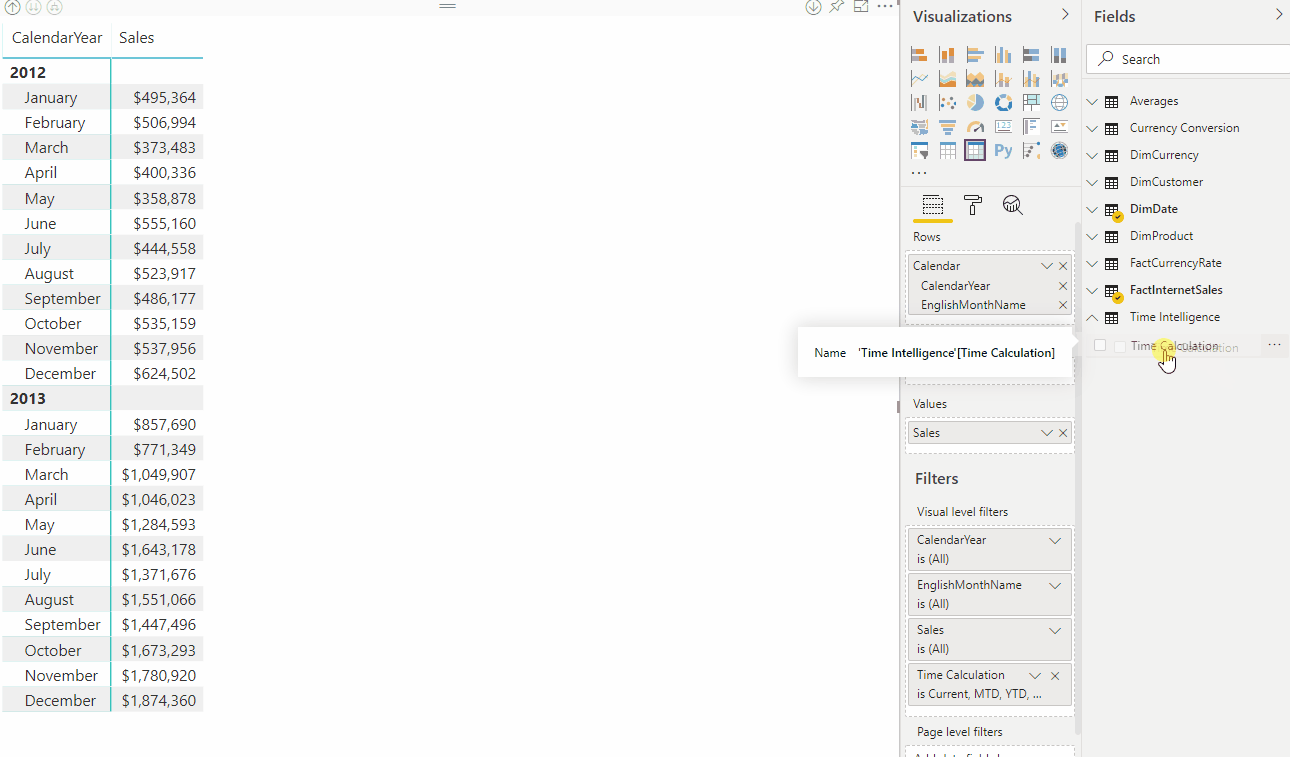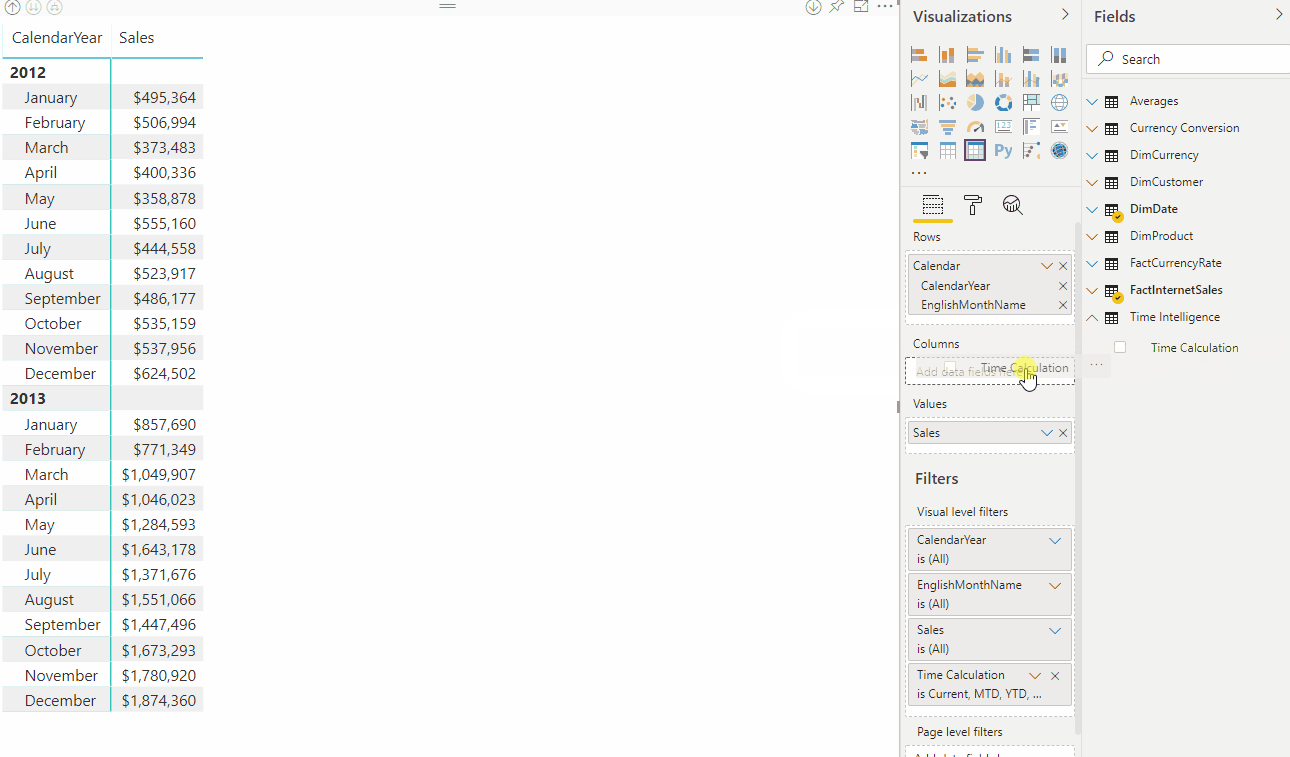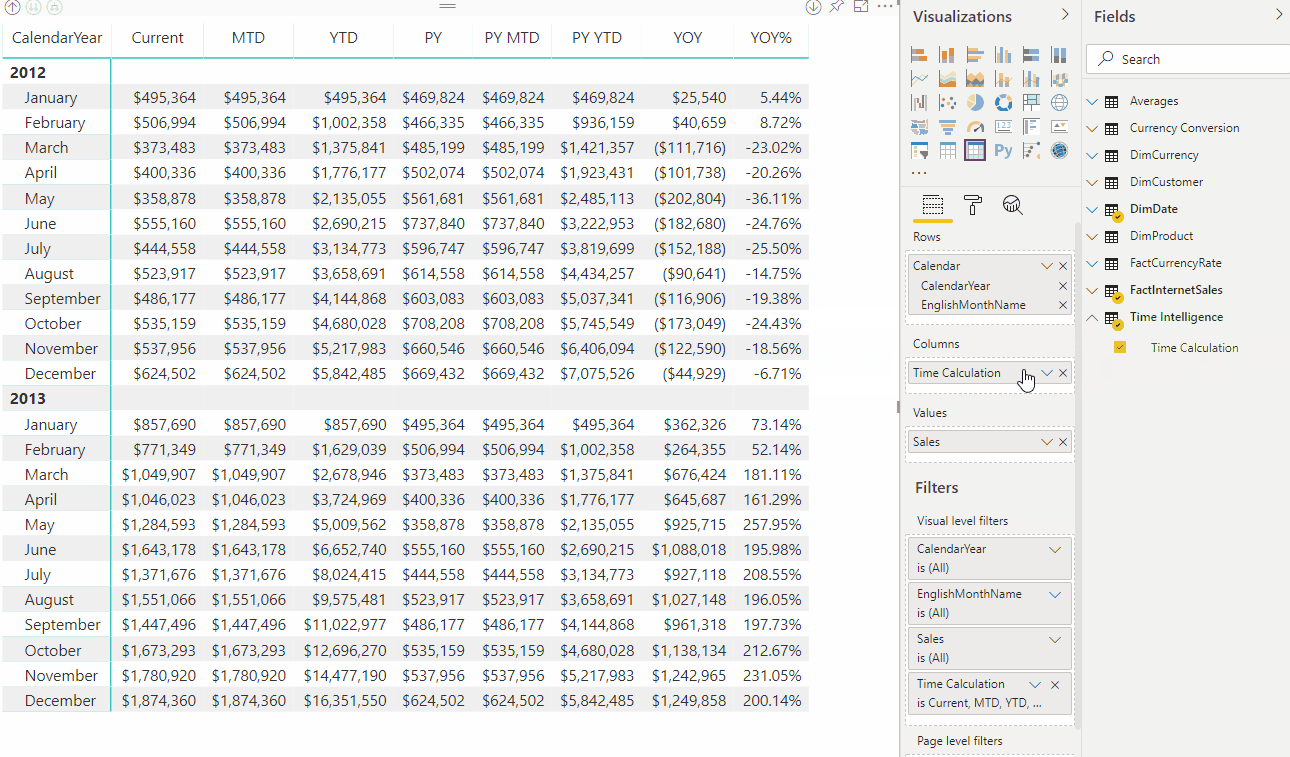
Avec un groupe de calculs, dans cet exemple nommé Time Intelligence, lorsque l’utilisateur fait glisser l’élément Calcul du temps vers la zone de filtre Colonnes , chaque élément de calcul apparaît sous la forme d’une colonne distincte. Les valeurs de chaque ligne sont calculées à partir de la mesure de base, Sales.
Les groupes de calcul fonctionnent avec des mesures DAX explicites . Dans cet exemple, Sales est une mesure explicite déjà créée dans le modèle. Les groupes de calcul ne fonctionnent pas avec les mesures DAX implicites. Par exemple, dans les mesures implicites Power BI, un utilisateur fait glisser des colonnes vers des visuels pour afficher les valeurs agrégées, sans créer de mesure explicite. À ce stade, Power BI génère DAX pour les mesures implicites écrites en tant que calculs DAX inline , ce qui signifie que les mesures implicites ne peuvent pas fonctionner avec des groupes de calcul. Une nouvelle propriété de modèle visible dans le modèle objet tabulaire (TOM) a été introduite, DiscourageImplicitMeasures. Actuellement, pour créer des groupes de calcul, cette propriété doit être définie sur true. Quand la valeur est true, Power BI Desktop en mode Live Connect désactive la création de mesures implicites.
Les groupes de calcul prennent également en charge les requêtes MDX (Multidimensional Data Expressions). Cela signifie que les utilisateurs de Microsoft Excel, qui interrogent des modèles de données tabulaires à l’aide de MDX, peuvent tirer pleinement parti des groupes de calcul dans les tableaux croisés dynamiques et les graphiques de feuille de calcul.
Fonctionnement
Maintenant que vous avez vu comment les groupes de calcul bénéficient aux utilisateurs, examinons comment l’exemple de groupe de calcul Time Intelligence illustré est créé.
Avant d’entrer dans les détails, nous allons introduire de nouvelles fonctions DAX spécifiquement pour les groupes de calcul :
SELECTEDMEASURE : utilisé par les expressions pour les éléments de calcul pour référencer la mesure actuellement en contexte. Dans cet exemple, la mesure Ventes.
SELECTEDMEASURENAME : utilisé par des expressions pour les éléments de calcul pour déterminer la mesure qui est dans le contexte par nom.
ISSELECTEDMEASURE : utilisé par des expressions des éléments de calcul pour déterminer si la mesure qui se trouve dans le contexte est spécifiée dans une liste de mesures.
SELECTEDMEASUREFORMATSTRING : utilisé par des expressions pour les éléments de calcul afin de récupérer la chaîne de format de la mesure dans le contexte.
Exemple d'intelligence temporelle
Nom de la table - Time Intelligence
Nom de colonne - Calcul de l’heure
Priorité - 20
Éléments de calcul Time Intelligence
Actuel
SELECTEDMEASURE()
MTD
CALCULATE(SELECTEDMEASURE(), DATESMTD(DimDate[Date]))
QTD
CALCULATE(SELECTEDMEASURE(), DATESQTD(DimDate[Date]))
CDA
CALCULATE(SELECTEDMEASURE(), DATESYTD(DimDate[Date]))
PY
CALCULATE(SELECTEDMEASURE(), SAMEPERIODLASTYEAR(DimDate[Date]))
PY MTD
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "MTD"
)
PY QTD
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "QTD"
)
PY YTD
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "YTD"
)
YOY
SELECTEDMEASURE() -
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation] = "PY"
)
YOY%
DIVIDE(
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="YOY"
),
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="PY"
)
)
Pour tester ce groupe de calcul, exécutez la requête DAX suivante. Remarque : MTD, YOY et YOY% sont omis dans cet exemple de requête.
Requête Time Intelligence
EVALUATE
CALCULATETABLE (
SUMMARIZECOLUMNS (
DimDate[CalendarYear],
DimDate[EnglishMonthName],
"Current", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "Current" ),
"QTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "QTD" ),
"YTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "YTD" ),
"PY", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY" ),
"PY QTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY QTD" ),
"PY YTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY YTD" )
),
DimDate[CalendarYear] IN { 2012, 2013 }
)
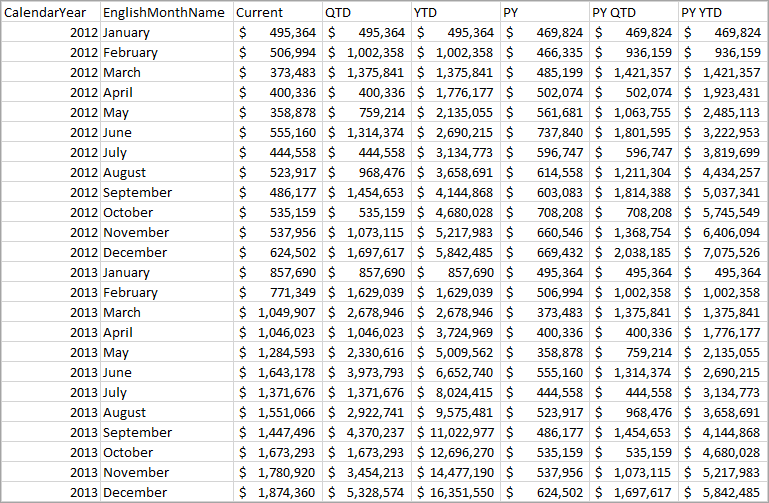
Retour de requête Time Intelligence
Le tableau de retour affiche les calculs pour chaque élément de calcul appliqué. Par exemple, voir QTD pour mars 2012 est la somme de janvier, février et mars 2012.
Chaînes de format dynamique
Les chaînes de format dynamique avec des groupes de calcul autorisent l’application conditionnelle de chaînes de format à des mesures sans les forcer à retourner des chaînes.
Les modèles tabulaires prennent en charge la mise en forme dynamique des mesures à l’aide de la fonction FORMAT de DAX. Toutefois, la fonction FORMAT présente l’inconvénient de retourner une chaîne, forçant les mesures qui seraient autrement numériques à renvoyer sous forme de chaîne. Cela peut avoir certaines limitations, comme le fait de ne pas fonctionner avec la plupart des visuels Power BI qui dépendent des valeurs numériques, tels que les graphiques.
Dans Power BI, les chaînes de format dynamique pour les mesures autorisent également l’application conditionnelle de chaînes de format à une mesure spécifique sans les forcer à retourner une chaîne et sans utiliser de groupes de calcul. Pour en savoir plus, consultez les chaînes de format dynamique pour les mesures.
Chaînes de format dynamique pour l’intelligence temporelle
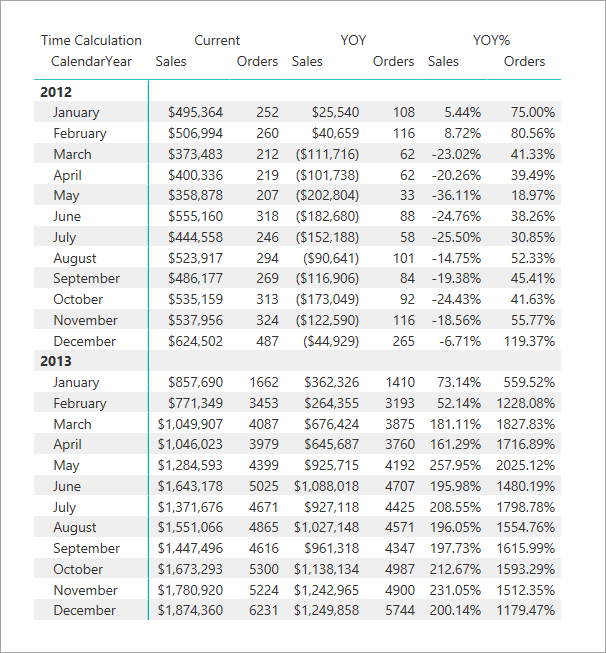
Si nous examinons l’exemple Time Intelligence ci-dessus, tous les éléments de calcul, sauf YOY% doivent utiliser le format de la mesure actuelle dans le contexte. Par exemple, YTD calculé sur la mesure de base des ventes doit être monétaire. S’il s’agissait d’un groupe de calcul pour une mesure de base Orders, le format serait numérique. YOY%, cependant, doit être un pourcentage quel que soit le format de la mesure de base.
Pour YOY%, nous pouvons remplacer la chaîne de format en définissant la propriété d’expression de chaîne de format sur 0,00%;-0.00%;0.00%. Pour en savoir plus sur les propriétés d’expression de chaîne de format, consultez MDX Cell Properties - FORMAT STRING Contents.
Dans ce visuel de matrice dans Power BI, vous voyez Sales Current/YOY et Orders Current/YOY conserver leurs chaînes de format de mesure de base respectives. Les ventes YOY% et les commandes YOY% remplacent toutefois la chaîne de format pour adopter le format pourcentage.
Chaînes de format dynamique pour la conversion monétaire
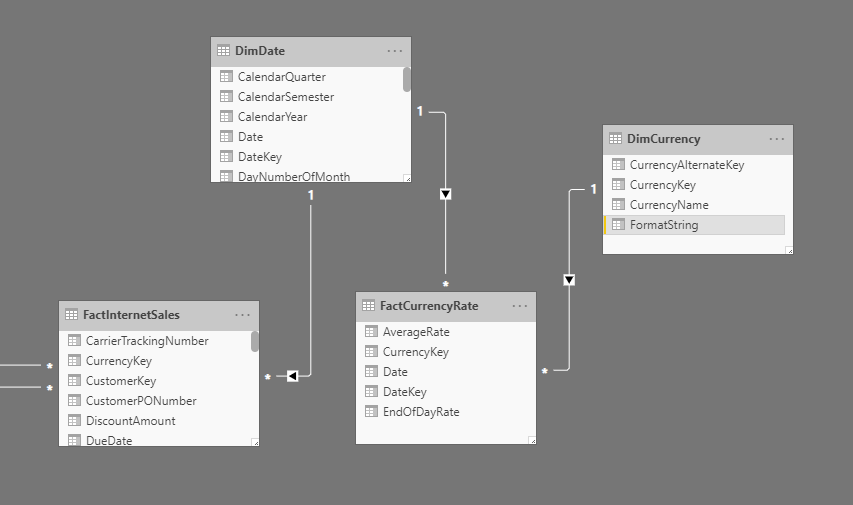
Les chaînes de format dynamique fournissent une conversion monétaire facile. Considérez le modèle de données Adventure Works suivant. Il est modélisé pour la conversion monétaire un-à-plusieurs tel que défini par les types de conversion.
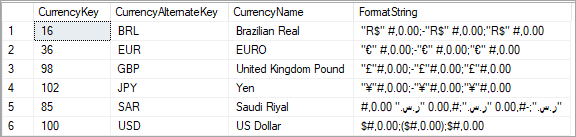
Une colonne FormatString est ajoutée à la table DimCurrency et remplie avec des chaînes de format pour les devises respectives.
Pour cet exemple, le groupe de calcul suivant est ensuite défini comme suit :
Exemple de conversion monétaire
Nom de la table - Conversion monétaire
Nom de colonne - Calcul de conversion
Priorité - 5
Éléments de calcul pour la conversion monétaire
Aucune conversion
SELECTEDMEASURE()
Devise convertie
IF(
//Check one currency in context & not US Dollar, which is the pivot currency:
SELECTEDVALUE( DimCurrency[CurrencyName], "US Dollar" ) = "US Dollar",
SELECTEDMEASURE(),
SUMX(
VALUES(DimDate[Date]),
CALCULATE( DIVIDE( SELECTEDMEASURE(), MAX(FactCurrencyRate[EndOfDayRate]) ) )
)
)
Format de l’expression de chaîne
SELECTEDVALUE(
DimCurrency[FormatString],
SELECTEDMEASUREFORMATSTRING()
)
Remarque
Les expressions de sélection pour les groupes de calcul peuvent être utilisées pour implémenter la conversion automatique des devises sur les groupes de calcul, en supprimant la nécessité d’avoir deux éléments de calcul distincts.
L’expression de chaîne de format doit retourner une chaîne scalaire. Il utilise la nouvelle fonction SELECTEDMEASUREFORMATSTRING pour revenir à la chaîne de format de mesure de base s’il existe plusieurs devises dans le contexte de filtre.
L'animation suivante montre la conversion des devises au format dynamique de la mesure Sales dans un rapport.
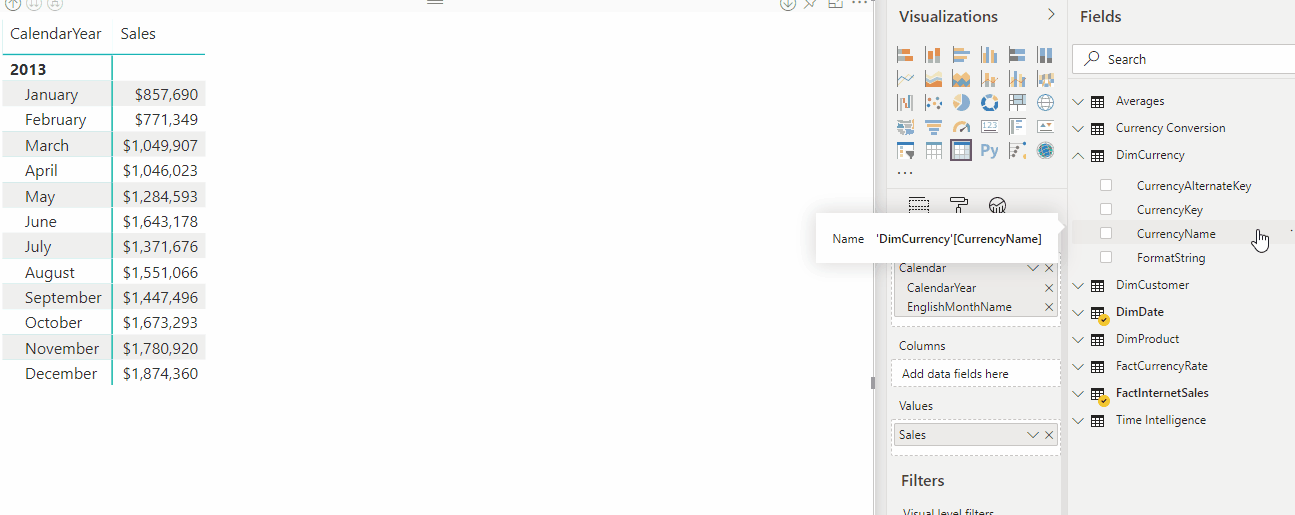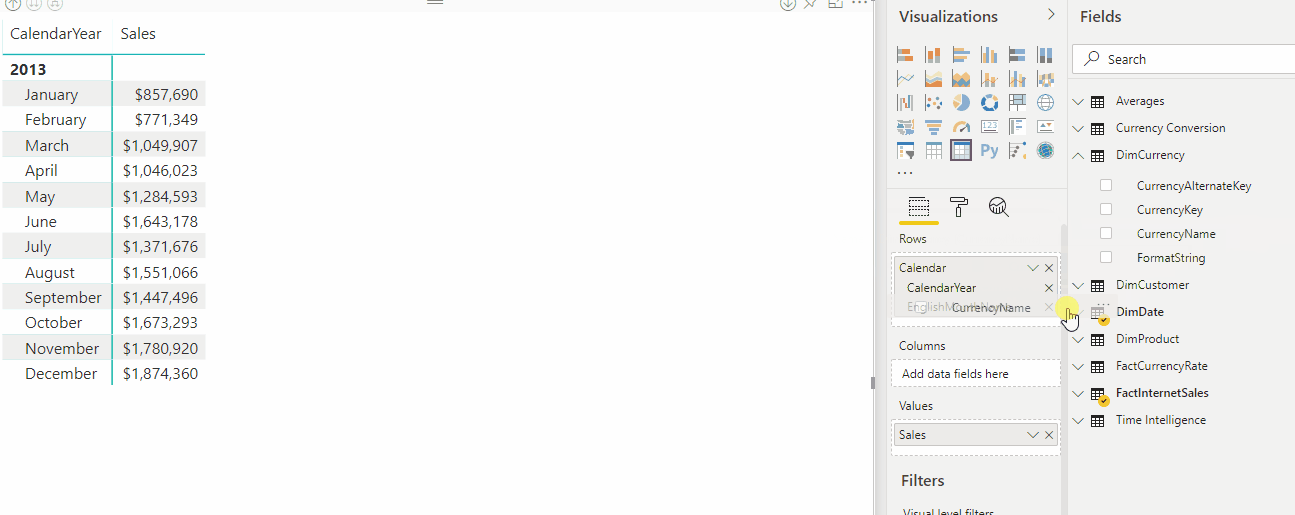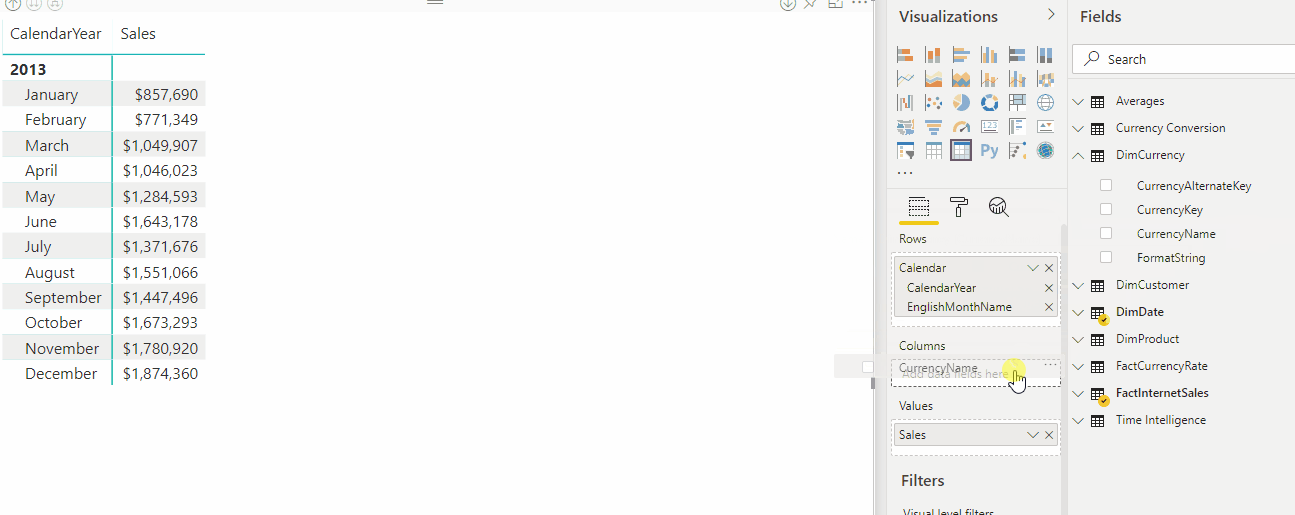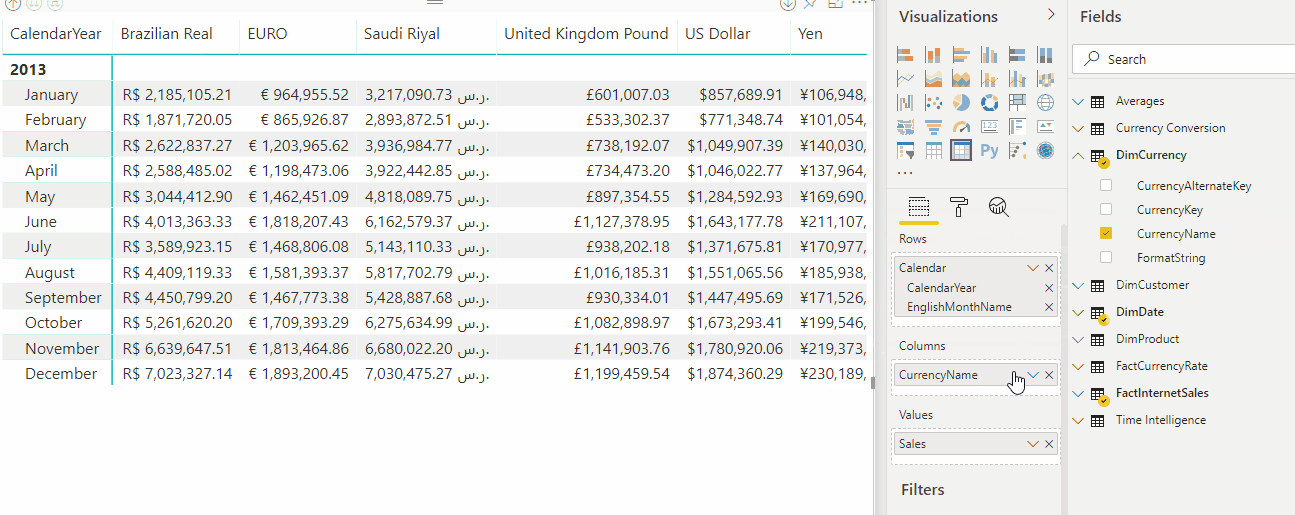
Expressions de sélection
Les expressions de sélection sont des propriétés facultatives définies pour un groupe de calcul. Il existe deux types d’expressions de sélection :
-
multipleOrEmptySelectionExpression. Cette expression de sélection est appliquée lorsque :
- plusieurs éléments de calcul ont été sélectionnés,
- un élément de calcul non existant a été sélectionné ou
- une sélection contradictoire a été effectuée.
- noSelectionExpression. Cette expression de sélection est appliquée lorsque le groupe de calcul n’est pas filtré.
Ces deux expressions de sélection ont également une expression formatStringDefinition chaîne de format dynamique.
En résumé, sur un groupe de calcul, vous pouvez définir les éléments suivants, par exemple à l’aide de TMDL :
...
table Scenarios
calculationGroup
...
multipleOrEmptySelectionExpression = <expression>
formatStringDefinition = <format string>
noSelectionExpression= <expression>
formatStringDefinition = <format string>
...
Remarque
Ces expressions, si spécifiées, sont appliquées uniquement pour les situations spécifiques mentionnées. Les sélections d’un seul élément de calcul ne sont pas affectées par ces expressions.
Voici une vue d’ensemble de ces expressions et de leur comportement par défaut s’ils ne sont pas spécifiés :
| Type de sélection | Expression de sélection non définie (par défaut) | Expression de sélection définie |
|---|---|---|
| Sélection unique | La sélection est appliquée | La sélection est appliquée |
| Sélection multiple | Le groupe de calcul n’est pas filtré | Retourner le résultat de l’évaluation de multipleOrEmptySelectionExpression |
| Sélection vide | Le groupe de calcul n’est pas filtré | Retourner le résultat de l’évaluation de multipleOrEmptySelectionExpression |
| Aucune sélection | Le groupe de calcul n’est pas filtré | Résultat de retour de l’évaluation de noSelectionExpression |
Remarque
Utilisez le paramètre selectionExpressionBehavior du modèle pour influencer davantage ce qu’un groupe de calcul retourne quand les expressions de sélection ne sont pas définies.
Paramètre de modèle SelectionExpressionBehavior
Les modèles ont un paramètre selectionExpressionBehavior qui permet un contrôle supplémentaire sur le comportement des groupes de calcul dans ce modèle. Ce paramètre accepte les trois valeurs suivantes :
- Automatique. Il s’agit de la valeur par défaut et est identique à celle nonvisuelle. Cela garantit que vos modèles existants ne changent pas de comportement. Les modèles avec un niveau de compatibilité futur supérieur défini sur automatique utiliseront visuel. Il y aura une annonce à ce moment-là.
-
Nonvisual. Si le groupe de calcul ne définit pas d’expression multipleOrEmptySelection , le groupe de calcul retourne
SELECTEDMEASURE()et lors du regroupement par le groupe de calcul, les valeurs de sous-total sont masquées. -
Visuel. Si le groupe de calcul ne définit pas d’expression multipleOrEmptySelection , le groupe de calcul retourne
BLANK(). Lors du regroupement par le groupe de calcul, les valeurs de sous-total sont déterminées en évaluant la mesure sélectionnée dans le contexte du groupe de calcul.
Utilisez TMDL pour définir la propriété sur votre modèle :
createOrReplace
model Model
...
selectionExpressionBehavior: <automatic|nonvisual|visual>
...
Sélection multiple ou vide
Si plusieurs sélections sur le même groupe de calcul sont effectuées, le groupe de calcul évalue et retourne le résultat du multipleOrEmptySelectionExpression s’il est défini. Si cette expression n’a pas été définie, le groupe de calcul retourne le résultat suivant si le paramètre selectionExpressionBehavior du modèle est défini sur automatique ou nonvisuel :
SELECTEDMEASURE()
Si le paramètre selectionExpressionBehavior du modèle est défini sur visuel, le groupe de calcul retourne :
BLANK()
Par exemple, examinons un groupe de calcul appelé MyCalcGroup qui a un multipleOrEmptySelectionExpression configuré comme suit :
IF (
ISFILTERED ( 'MyCalcGroup' ),
"Filters: "
& CONCATENATEX (
FILTERS ( 'MyCalcGroup'[Name] ),
'MyCalcGroup'[Name],
", "
)
)
À présent, imaginez la sélection suivante sur le groupe de calcul :
EVALUATE
{
CALCULATE (
[MyMeasure],
'MyCalcGroup'[Name] = "item1" || 'MyCalcGroup'[Name] = "item2"
)
}
Ici, nous sélectionnons deux éléments dans le groupe de calcul, « item1 » et « item2 ». Il s’agit d’une sélection multiple et, par conséquent, le multipleOrEmptySelectionExpression est évalué et retourne le résultat suivant : « Filtres : élément1, élément2 ».
Ensuite, effectuez la sélection suivante sur le groupe de calcul :
EVALUATE
{
CALCULATE (
[MyMeasure],
'MyCalcGroup'[Name] = "item4" -- item4 does not exists
)
}
Il s’agit d’un exemple de sélection vide, car « item4 » n’existe pas sur ce groupe de calcul. Par conséquent, le multipleOrEmptySelectionExpression est évalué et retourne le résultat suivant : « Filtres : « .
Aucune sélection
NoSelectionExpression sur un groupe de calcul est appliqué si le groupe de calcul n’a pas été filtré. Cela est principalement utilisé pour effectuer des actions par défaut sans avoir besoin que l’utilisateur prenne des mesures tout en fournissant une flexibilité à l’utilisateur pour remplacer l’action par défaut. Par exemple, examinons la conversion automatique des devises avec le dollar américain comme devise pivot centrale.
Nous pouvons configurer un groupe de calcul avec le noSelectionExpression suivant :
IF (
//Check one currency in context & not US Dollar, which is the pivot currency:
SELECTEDVALUE (
DimCurrency[CurrencyName],
"US Dollar"
) = "US Dollar",
SELECTEDMEASURE (),
SUMX (
VALUES ( DimDate[DateKey] ),
CALCULATE (
DIVIDE ( SELECTEDMEASURE (), MAX ( FactCurrencyRate[EndOfDayRate] ) )
)
)
)
Nous allons également définir une mise en formeStringDefinition pour cette expression :
SELECTEDVALUE(
DimCurrency[FormatString],
SELECTEDMEASUREFORMATSTRING()
)
Maintenant, si aucune devise n’est sélectionnée, toutes les devises seront automatiquement converties en devise pivot (dollar américain) si nécessaire. En plus de cela, vous pouvez toujours choisir une autre devise à convertir en cette devise sans avoir à changer d’éléments de calcul, car vous devrez le faire sans le noSelectionExpression.
Priorité
La priorité est une propriété définie pour un groupe de calculs. Elle spécifie l’ordre dans lequel les groupes de calcul sont combinés avec la mesure sous-jacente lors de l’utilisation de SELECTEDMEASURE() dans l’élément de calcul.
Exemple de précédence
Prenons un exemple simple. Ce modèle a une mesure avec une valeur spécifiée de 10 et deux groupes de calcul, chacun avec un seul élément de calcul. Nous allons appliquer les deux éléments de calcul du groupe de calcul à la mesure. Voici comment nous l’avons configuré :
'Measure group'[Measure] = 10
Le premier groupe de calcul est 'Calc Group 1 (Precedence 100)' et l’élément de calcul est 'Calc item (Plus 2)':
'Calc Group 1 (Precedence 100)'[Calc item (Plus 2)] = SELECTEDMEASURE() + 2
Le deuxième groupe de calculs est 'Calc Group 2 (Precedence 200)' et l’élément de calcul est 'Calc item (Times 2)':
'Calc Group 2 (Precedence 200)'[Calc item (Times 2)] = SELECTEDMEASURE() * 2
Vous pouvez voir que le groupe de calcul 1 a une valeur de précédence de 100, et le groupe de calcul 2 a une valeur de précédence de 200.
À l’aide de SQL Server Management Studio (SSMS) ou d’un outil externe avec des fonctionnalités xmlA en lecture-écriture , comme l’éditeur tabulaire open source, vous pouvez utiliser des scripts XMLA pour créer des groupes de calcul et définir les valeurs de priorité. Ici, nous ajoutons "Calc group 1 (Precedence 100)":
{
"createOrReplace": {
"object": {
"database": "CHANGE TO YOUR DATASET NAME",
"table": "Calc group 1 (Precedence 100)"
},
"table": {
"name": "Calc group 1 (Precedence 100)",
"calculationGroup": {
"precedence": 100,
"calculationItems": [
{
"name": "Calc item (Plus 2)",
"expression": "SELECTEDMEASURE() + 2",
}
]
},
"columns": [
{
"name": "Calc group 1 (Precedence 100)",
"dataType": "string",
"sourceColumn": "Name",
"sortByColumn": "Ordinal",
"summarizeBy": "none",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
},
{
"name": "Ordinal",
"dataType": "int64",
"isHidden": true,
"sourceColumn": "Ordinal",
"summarizeBy": "sum",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
}
],
"partitions": [
{
"name": "Partition",
"mode": "import",
"source": {
"type": "calculationGroup"
}
}
]
}
}
}
Et ce script ajoute "Calc group 2 (Precedence 200)":
{
"createOrReplace": {
"object": {
"database": "CHANGE TO YOUR DATASET NAME",
"table": "Calc group 2 (Precedence 200)"
},
"table": {
"name": "Calc group 2 (Precedence 200)",
"calculationGroup": {
"precedence": 200,
"calculationItems": [
{
"name": "Calc item (Times 2)",
"expression": "SELECTEDMEASURE() * 2"
}
]
},
"columns": [
{
"name": "Calc group 2 (Precedence 200)",
"dataType": "string",
"sourceColumn": "Name",
"sortByColumn": "Ordinal",
"summarizeBy": "none",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
},
{
"name": "Ordinal",
"dataType": "int64",
"isHidden": true,
"sourceColumn": "Ordinal",
"summarizeBy": "sum",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
}
],
"partitions": [
{
"name": "Partition",
"mode": "import",
"source": {
"type": "calculationGroup"
}
}
]
}
}
}
Dans Power BI Desktop, nous avons un visuel de carte montrant la mesure et un segment pour chacun des groupes de calcul dans la vue rapport :
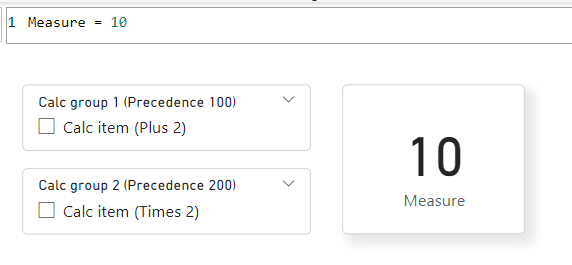
Lorsque les deux segmentations sont sélectionnées, nous devons combiner les expressions DAX. Pour ce faire, nous commençons par l’élément de calcul de priorité le plus élevé, 200, puis remplacez l’argument SELECTEDMEASURE() par le plus élevé suivant, 100.
Par conséquent, notre expression DAX pour l'élément de calcul doté de la priorité la plus élevée est la suivante :
SELECTEDMEASURE() * 2
Et notre deuxième expression DAX de l’élément de calcul de priorité le plus élevé est :
SELECTEDMEASURE() + 2
Maintenant, ils sont combinés en remplaçant la partie SELECTEDMEASURE() de l’élément de calcul de priorité la plus élevée par l’élément de calcul de priorité la plus élevée suivante, comme suit :
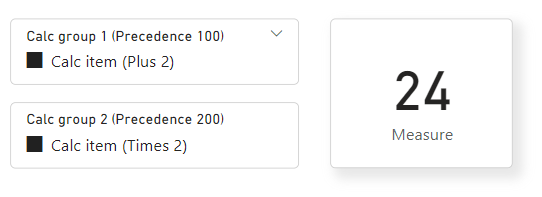
( SELECTEDMEASURE() + 2 ) * 2
Ensuite, si nous avons d'autres éléments de calcul, nous continuons jusqu’à obtenir la mesure sous-jacente. Il n’existe que deux groupes de calcul dans ce modèle. Nous remplaçons maintenant selectedMEASURE() par la mesure elle-même, comme suit :
( ( [Measure] ) + 2 ) * 2
Comme notre Measure = 10, c’est la même chose que :
( ( 10 ) + 2 ) * 2
Lorsqu’il n’y a plus d’arguments SELECTEDMEASURE(), l’expression DAX combinée est évaluée :
( ( 10 ) + 2 ) * 2 = 24
Dans Power BI Desktop, lorsque les deux groupes de calcul sont appliqués avec un segment de données, la sortie de la mesure ressemble à ceci :
Mais gardez à l’esprit que la combinaison est imbriquée de telle sorte que la sortie ne sera pas 10 + 2 * 2 = 14 comme vous le voyez ici :
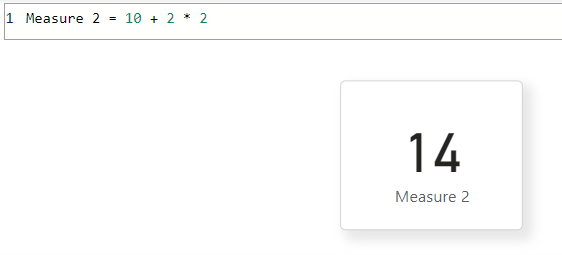
Pour les transformations simples, l’évaluation est d’une priorité inférieure à supérieure. Par exemple, 10 a 2 ajoutés, puis il est multiplié par 2. Dans DAX, il existe des fonctions telles que CALCULATE qui appliquent des filtres ou des modifications de contexte aux expressions internes. Dans ce cas, la priorité la plus élevée modifie une expression de précédence inférieure.
La priorité détermine également quelle chaîne de format dynamique est appliquée à l’expression DAX combinée pour chaque mesure. La chaîne de format dynamique du groupe de calcul de priorité la plus élevée est la seule appliquée. Si une mesure elle-même a une chaîne de format dynamique, elle est considérée comme une priorité inférieure à n’importe quel groupe de calcul dans le modèle.
Ordre de priorité avec un exemple de moyennes
Examinons un autre exemple utilisant le même modèle que celui indiqué dans l’exemple Time Intelligence décrit précédemment dans cet article. Mais cette fois, nous allons également ajouter un groupe de calcul Averages . Le groupe de calcul Averages contient des calculs moyens indépendants de l’intelligence temporelle traditionnelle dans le sens où ils ne modifient pas le contexte de filtre de date . Ils appliquent simplement des calculs moyens dans celui-ci.
Dans cet exemple, un calcul moyen quotidien est défini. Les calculs tels que les barils moyens de pétrole par jour sont courants dans les applications pétrolières et gazières. D’autres exemples commerciaux courants incluent la moyenne des ventes de magasins dans la vente au détail.
Bien que ces calculs soient calculés indépendamment des calculs d’intelligence temporelle, il peut être nécessaire de les combiner. Par exemple, un utilisateur peut souhaiter voir des barils d’huile par jour YTD pour afficher le taux d’huile quotidien du début de l’année à la date actuelle. Dans ce scénario, la priorité doit être définie pour les éléments de calcul.
Nos hypothèses sont les suivantes :
Le nom de la table est Averages.
Le nom de colonne est Calcul moyen.
La priorité est 10.
Éléments de calcul pour les moyennes
Aucune moyenne
SELECTEDMEASURE()
Moyenne quotidienne
DIVIDE(SELECTEDMEASURE(), COUNTROWS(DimDate))
Voici un exemple de requête DAX et de table de retour :
Requête pour calcul des moyennes
EVALUATE
CALCULATETABLE (
SUMMARIZECOLUMNS (
DimDate[CalendarYear],
DimDate[EnglishMonthName],
"Sales", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "Current",
'Averages'[Average Calculation] = "No Average"
),
"YTD", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "YTD",
'Averages'[Average Calculation] = "No Average"
),
"Daily Average", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "Current",
'Averages'[Average Calculation] = "Daily Average"
),
"YTD Daily Average", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "YTD",
'Averages'[Average Calculation] = "Daily Average"
)
),
DimDate[CalendarYear] = 2012
)
Retour de requête moyenne
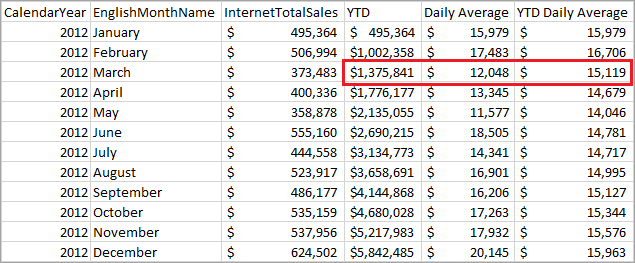
Le tableau suivant montre comment les valeurs de mars 2012 sont calculées.
| Nom de colonne | Calcul |
|---|---|
| Année en cours | Somme des ventes pour jan, février 2012 = 495 364 + 506 994 + 373 483 |
| Moyenne quotidienne | Ventes pour mars 2012 divisées par nombre de jours en mars = 373 483 / 31 |
| Moyenne quotidienne YTD | YTD pour mars 2012 divisé par nombre de jours en jan, février et mar = 1 375 841 / (31 + 29 + 31) |
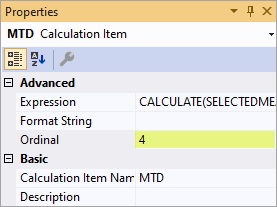
Voici la définition de l’élément de calcul YTD, avec une priorité de 20.
CALCULATE(SELECTEDMEASURE(), DATESYTD(DimDate[Date]))
Voici la moyenne quotidienne, appliquée avec une priorité de 10.
DIVIDE(SELECTEDMEASURE(), COUNTROWS(DimDate))
Étant donné que la priorité du groupe de calcul Time Intelligence est supérieure à celle du groupe de calcul Moyennes, celle-ci est appliquée aussi largement que possible. Le calcul de la moyenne quotidienne YTD applique YTD à la fois au numérateur et au dénominateur (nombre de jours) du calcul moyen quotidien.
Cela équivaut à l’expression suivante :
CALCULATE(DIVIDE(SELECTEDMEASURE(), COUNTROWS(DimDate)), DATESYTD(DimDate[Date]))
Pas cette expression :
DIVIDE(CALCULATE(SELECTEDMEASURE(), DATESYTD(DimDate[Date])), COUNTROWS(DimDate)))
Récursivité latérale
Dans l’exemple Time Intelligence ci-dessus, certains éléments de calcul font référence à d’autres dans le même groupe de calcul. C’est ce qu’on appelle la récursivité latérale. Par exemple, YOY% référence à la fois YOY et PY.
DIVIDE(
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="YOY"
),
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="PY"
)
)
Dans ce cas, les deux expressions sont évaluées séparément, car elles utilisent différentes instructions calculate. Les autres types de récursivité ne sont pas pris en charge.
Élément de calcul unique dans le contexte de filtre
Dans notre exemple Time Intelligence, l’élément de calcul PY YTD a une expression de calcul unique :
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "YTD"
)
L’argument YTD de la fonction CALCULATE() remplace le contexte de filtre pour réutiliser la logique déjà définie dans l’élément de calcul YTD. Il n’est pas possible d’appliquer py et YTD dans une seule évaluation. Les groupes de calcul sont appliqués uniquement si un seul élément de calcul du groupe de calcul est dans le contexte de filtre.
Classement
Par défaut, lorsqu’une colonne d’un groupe de calcul est placée dans un rapport, les éléments de calcul sont classés par ordre alphabétique par nom. L’ordre dans lequel les éléments de calcul apparaissent dans un rapport peut être modifié en spécifiant la propriété Ordinal. La spécification de l’ordre d’élément de calcul avec la propriété Ordinal ne change pas de priorité, l’ordre dans lequel les éléments de calcul sont évalués. Elle ne modifie pas également l’ordre dans lequel les éléments de calcul apparaissent dans l’Explorateur de modèles tabulaires.
Pour spécifier la propriété ordinale pour les éléments de calcul, vous devez ajouter une deuxième colonne au groupe de calcul. Contrairement à la colonne par défaut où le type de données est Text, une deuxième colonne utilisée pour classer les éléments de calcul a un type de données Nombre entier. Le seul objectif de cette colonne est de spécifier l’ordre numérique dans lequel les éléments de calcul du groupe de calcul apparaissent. Étant donné que cette colonne ne fournit aucune valeur dans un rapport, il est préférable de définir la propriété Hidden sur True.
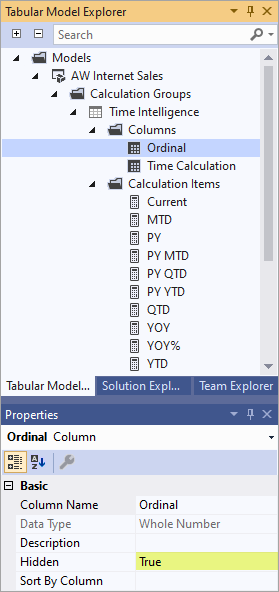
Une fois qu’une deuxième colonne est ajoutée au groupe de calcul, vous pouvez spécifier la valeur de propriété Ordinal pour les éléments de calcul que vous souhaitez commander.
Pour plus d’informations, consultez Pour commander des éléments de calcul.
Créer un groupe de calcul
Les groupes de calcul sont pris en charge dans Visual Studio avec Analysis Services Projects VSIX mise à jour 2.9.2 et versions ultérieures. Les groupes de calcul peuvent également être créés à l’aide du langage TMSL (Tabulaire Model Scripting Language) ou de l’éditeur tabulaire open source.
Pour créer un groupe de calcul à l’aide de Visual Studio
Dans l’Explorateur de modèles tabulaires, cliquez avec le bouton droit sur Groupes de calcul, puis cliquez sur Nouveau groupe de calcul. Par défaut, un nouveau groupe de calcul a une seule colonne et un seul élément de calcul.
Utilisez Propriétés pour modifier le nom et entrer une description pour le groupe de calcul, la colonne et l’élément de calcul par défaut.
Pour entrer une expression de formule DAX pour l’élément de calcul par défaut, cliquez avec le bouton droit, puis cliquez sur Modifier la formule pour ouvrir l’éditeur DAX. Entrez une expression valide.
Pour ajouter d’autres éléments de calcul, cliquez avec le bouton droit sur Éléments de calcul, puis cliquez sur Nouvel élément de calcul.
Pour commander les éléments de calcul
Dans l’Explorateur de modèles tabulaires, cliquez avec le bouton droit sur un groupe de calcul, puis cliquez sur Ajouter une colonne.
Nommez la colonne Ordinal (ou quelque chose de similaire), entrez une description, puis définissez la propriété Masquée sur Vrai.
Pour chaque élément de calcul que vous souhaitez commander, définissez la propriété Ordinal sur un nombre positif. Chaque nombre est séquentiel, par exemple, un élément de calcul avec une propriété Ordinale de 1 apparaît en premier, une propriété de 2 apparaît seconde, et ainsi de suite. Les éléments de calcul avec les -1 par défaut ne sont pas inclus dans l’ordre, mais apparaissent avant les éléments ordonnés dans un rapport.
Considérations
Dès qu’un groupe de calcul est ajouté à un modèle sémantique, les rapports Power BI utilisent le type de données variant pour toutes les mesures. Si par la suite, tous les groupes de calcul sont supprimés du modèle, les mesures sont retournées à nouveau à leurs types de données d’origine.
Limites
La sécurité au niveau de l’objet (OLS) définie sur les tables de groupe de calcul n’est pas prise en charge. Toutefois, OLS peut être défini sur d’autres tables du même modèle. Si un élément de calcul fait référence à un objet sécurisé OLS, une erreur générique est retournée.
La sécurité au niveau des lignes (RLS) n’est pas prise en charge. Définissez RLS sur les tables du même modèle, mais pas sur les groupes de calcul eux-mêmes (directement ou indirectement).
Les expressions de lignes de détail ne sont pas prises en charge avec les groupes de calcul.
Les visuels de narration intelligente dans Power BI ne sont pas pris en charge avec les groupes de calcul.
Les agrégations de colonnes implicites dans Power BI ne sont pas prises en charge pour les modèles avec des groupes de calcul. Actuellement, si la propriété DiscourageImplicitMeasures a la valeur false (par défaut), les options d’agrégation s’affichent, mais elles ne peuvent pas être appliquées. Si DiscourageImplicitMeasures a la valeur true, les options d’agrégation n’apparaissent pas.
Lors de la création de rapports Power BI à l’aide de LiveConnection, les chaînes de format dynamique ne sont pas appliquées aux mesures au niveau du rapport.