CosmosDB change feed support for manual checkpoint
It was quite long time I wrote last post about the change feed processor. Let's continue the series. This time, let's look into a manual checkpoint feature.
Basics
Let's refresh the knowledge. CosmosDB change feed processor SDK is a library for dispatching the document-related changes (inserts, updates) as a stream of documents. The documents can be split into multiple partitions (determined by partition key). The change feed processor is able to read the changes from all partitions and the reading is executed in the batches. In order to move forward with reading the documents, the change feed need to track the last processed batch. The tracking process is in the form of storing the continuation token from the last processed batch - that's done using "checkpoint" method. The checkpoints are kept in the lease documents.
Automatic checkpoint
By default, the change feed processor checkpoints the processed batches automatically. Updating the lease document takes some time and costs some request units (RUs). In order to fine-tune it, it's possible to set the frequency of this process.
Let's look at the change feed processing logic for one partition in the pseudo steps:
- read the change feed from the last known "continuation token"
- dispatch the documents for processing by calling IObserver.ProcessChangesAsync
- wait for the observer to process whole batch
- if it's time to checkpoint (based on the configured checkpoint frequency), update the lease document with the continuation token from the last processed batch of documents. That's so called "checkpoint" step.
- repeat from step 1
The whole process is shown on the following picture:

In most cases, the above algorithm works without issues. But do you see a possible problem?
Stuck partition problem
It's the step 3. The automatic checkpoint algorithm waits until whole batch is processed and then checkpoints. While this waiting no other documents are read and hence processed. It could happen that, e.g. in the batch with 10 documents, there is one document whose processing takes several minutes. In such case, whole change feed partition processing is "paused" and you can't do anything about it. Such situation can be easily detected when change feed estimator is used (for more information see my previous post). See the following graph showing the remaining work on such stuck partition:
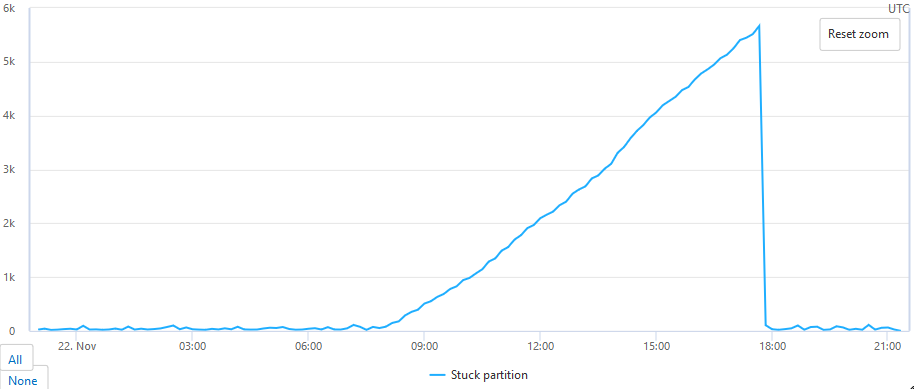
I simulated that the processing of some document takes several hours. This stopped reading from the change feed (the number of polling reads per second dropped to zero). The remaining work started to grow. If there would be a defined SLA agreement stating that the events are scheduled for handling within 2 seconds from the time they were inserted into the collection, then the system would not able to meet it.
Solution - manual checkpoint
The solution is to use the manual checkpoint. It's possible to turn off that the automatic checkpoint process. See the following code:
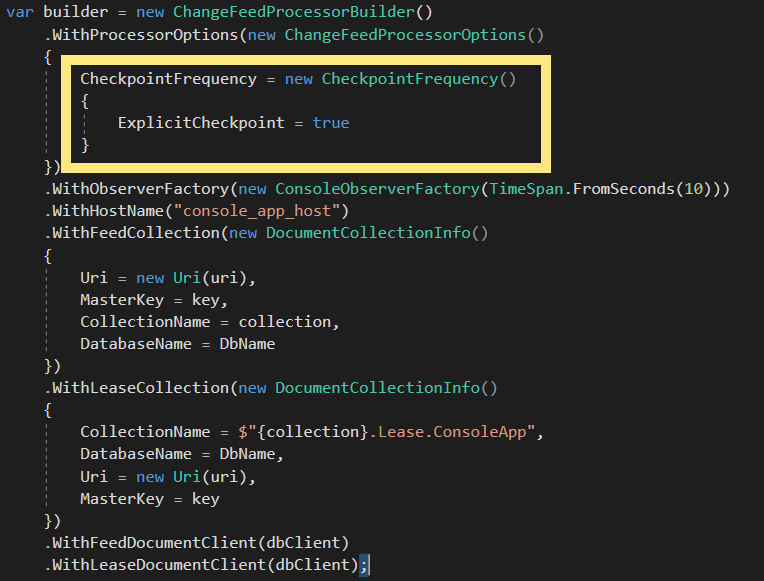
By doing this, the result lease document is never automatically updated. See the following:
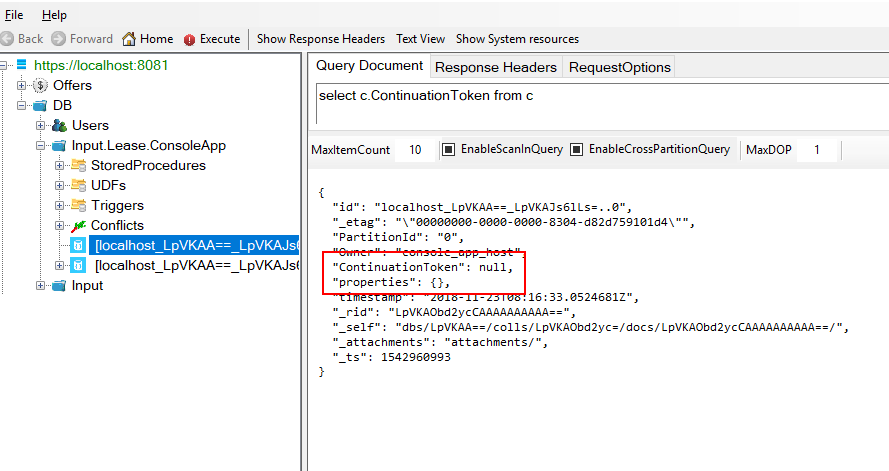
That's not good. After the process restart, the change feed would start back from the beginning. We need to checkpoint manually. That's possible using CheckpointAsync method exposed on the interface IChangeFeedObserverContext. But when? We can not wait for whole batch to be processed and then call CheckpointAsync. The simple solution could be like this:
- read the change feed from the last known "continuation token"
- dispatch the documents for processing by calling IObserver.ProcessChangesAsync
- schedule processing all documents, this will create as many Tasks as we have documents,
- register scheduled Tasks and IChangeFeedObserverContext instance into manual periodic checkpointer
- repeat from step 1
See the sample code of the observer:
The code above is for demonstrating purposes. It integrates the periodic partition checkpointer into the observer. The checkpointer is started when the observer is opened and stops when the observer is closed. In between, when the batches are dispatched for processing, the processing tasks are scheduled and the whole batch is enqueued into the checkpointer. The periodically checks for the last processed batch in the queue. For the running example check the sample here.
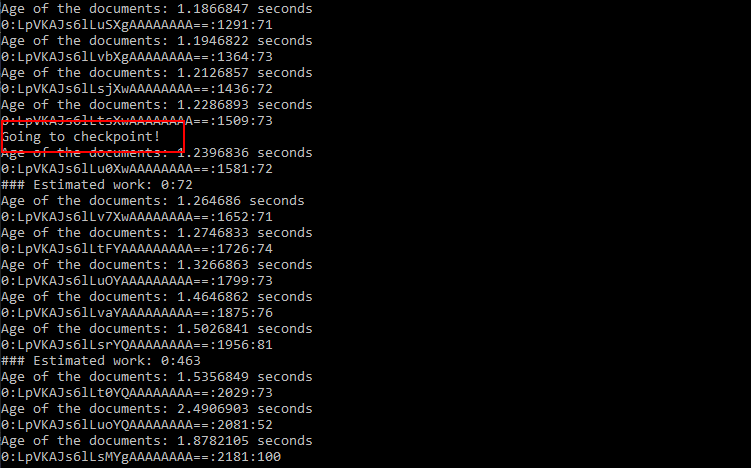
After running the sample, the result is:

And the console would look like:
Prons and cons of the solutions
The above solution solves the issue with stuck partition, that's great (advantage). The change feed processor is reading the changes while the previously read documents are still being processed. But if the reading documents and scheduling the work is much faster than its actual processing then it's possible that the instance will be overloaded (disadvantage). It's necessary to limit the number of concurrent document processings, e.g. using Semaphore.
That's all for now. In the future posts I'll describe the pitfalls of the change feed processing in general.