分散型可用性グループのフェールオーバーについて
このポストは 2019年1月に公開された Replica Failover within the Secondary Availability Group in a Distributed Availability Group の翻訳です。
---------------
分散型可用性グループ (distributed AG) は、特別な可用性グループであり、2つの可用性グループにまたがっています。このブログでは、分散型可用性グループのフェールオーバーについての問題を説明します。特に可用性グループ間の同期状態にかかわらず、分散型可用性グループのデータ損失への耐性をご紹介します。
検証のために、シンプルな分散型可用性グループ 'TIWENDAG' を作成します。 'TIWENDAG' の構成は次の図のとおりです。 'TIWENAG1' が分散型可用性グループ 'TIWENDAG' のプライマリ可用性グループで、'TIWENVM1' がプライマリ レプリカ、'TIWENVM2' がセカンダリレプリカです。'TIWENAG2' が分散型可用性グループ 'TIWENDAG' のセカンダリ可用性グループで、'TIWENVM3' がプライマリ レプリカ、'TIWENVM4' がセカンダリレプリカです。 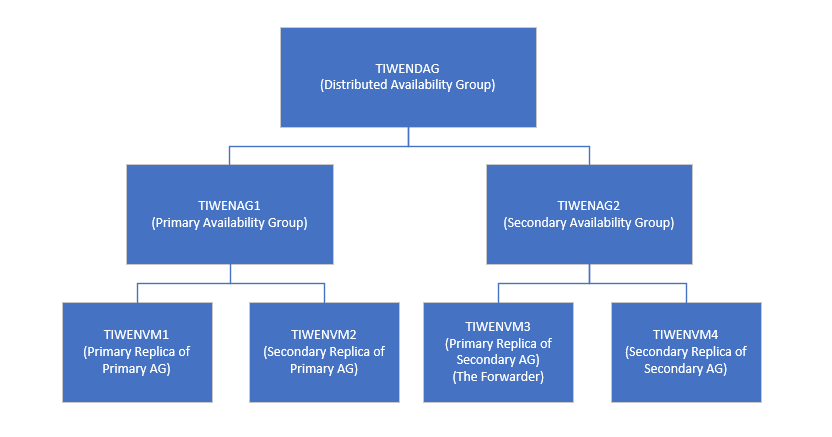
分散型可用性グループで定義されている、2つの可用性グループの自動フェールオーバーはサポートされています。例えば、可用性グループ TIWENAG1 でフェールオーバーモードが "自動" で設定されていると、TIWENAG1 がダウンした際にはTIWENAG1 (プライマリ) と TIWENAG2 (同期セカンダリ) 間で自動フェールオーバーが発生します。同様に、可用性グループ TIWENAG2 でTIWENVM3 (プライマリ) がダウンした場合には、TIWENVM4 (同期セカンダリ) に自動的にフェールオーバーされます。
可用性グループのプライマリ レプリカがダウンした際、プライマリ レプリカ (可用性グループが分散型可用性グループの一部かどうかにかかわらず) は同期セカンダリ レプリカに自動的にフェールオーバーされます。
もしセカンダリ可用性グループ (フォワーダーとも呼ばれます) のプライマリ レプリカが失われて自動フェールオーバーが発生した場合や、分散型可用性グループのセカンダリ可用性グループで手動フェールオーバーが行われた場合、次の条件を満たしていれば、データ損失は発生しません。
- プライマリ可用性グループ のプライマリ レプリカ (グローバル プライマリとも呼ばれます)が、データベース ミラーリング エンドポイントを通して、セカンダリ可用性グループのフォワーダー レプリカと正常に同期している。
- セカンダリ可用性グループのフォワーダー レプリカが、データベース ミラーリング エンドポイントを通して、セカンダリ可用性グループのセカンダリ レプリカと正常に同期している。
グローバルプライマリ“TIWENVM1" に最後に書き込まれた LSN (last_hardend_lsn) が 10:15:1 と仮定します。プライマリAG のセカンダリレプリカ “TIWENVM2” は同期されており、最後に書き込まれた LSN (last_hardend_lsn) は 10:15:1 です。セカンダリAG に関しては、プライマリAG とフォワーダーの間の同期モードは非同期コミットモードで、フォワーダー “TIWENVM3” の最後に書き込まれた LSN (last_hardend_lsn) は 10:12:1 です。セカンダリAG のセカンダリレプリカ “TIWENVM4” は、まだ同期されていないため最後に書き込まれた LSN (last_hardend_lsn) は 10:10:1 です。この分散型可用性グループ内では、 “TIWENVM4” が最後に書き込まれたLSN として最も低い値を持っています。また、この時グローバルプライマリのトランケート LSN (truncation_lsn) は 10:10:1 を下回りません。これは、“TIWENVM3” が失われたとき、“TIWENVM4” が新しいフォワーダーとなりプライマリAG と同期出来るようにするためです。

この理由は、トランザクションログのバックアップが取られたとき、分散型可用性グループ内のすべてのレプリカ(プライマリAG,セカンダリAG 両方のレプリカ)に適用済みのトランザクションログのみが切り捨てられるからです。以下のテスト結果が、本記事の冒頭にて説明したテスト環境の分散型可用性グループにて、トランザクションログがどのように切り捨てられるかの例になります。
このシナリオは、以下手順にて簡単に証明出来ます。
- 現在の truncation_lsn と last_hardend_lsn を各レプリカで記録します。
- データベースに変更を加えます。ここでは test データベースに INSERT 文を10回発行します。
- 各レプリカにて LSN が同じ分だけ進む事を確認します。
- トランザクションログのバックアップを、グローバルプライマリの test データベースにて取得します。
- 現在の truncation_lsn と last_hardend_lsn の確認をします。
- セカンダリAG のセカンダリレプリカへのデータ移動を中断します。
- 2-5 を繰り返します。
以下スクリーンショットがこの再現テストシナリオのすべての結果です。
Step1 -
この Step で使用した DMV:
USE test
SELECT COUNT(*) AS '# of transaction logs' FROM fn_dblog(null, null)
SELECT database_id,
group_id,
replica_id,
is_local,
is_primary_replica,
truncation_lsn,
last_hardened_lsn
FROM sys.dm_hadr_database_replica_states
WHERE database_id=6 AND is_local=1
SELECT replica_id, replica_server_name
FROM sys.availability_replicas
WHERE replica_id=
(SELECT replica_id FROM sys.dm_hadr_database_replica_states WHERE database_id=6 AND is_local=1)
SELECT COUNT(*) AS '# of entries in testt1 table' FROM testt1
4つのレプリカでの結果 :
プライマリAG のプライマリレプリカ (グローバルプライマリ): 
プライマリAG のセカンダリレプリカ: 
セカンダリAG のプライマリレプリカ (フォワーダー): 
セカンダリAG のセカンダリレプリカ: 
このテスト環境のように、すべてのレプリカが同期されている場合、上記スクリーンショットのように、すべてのレプリカは同じ数のトランザクションログと truncation_lsn を返します。
Step 2 -
INSERT 文を10回実行します。
INSERT INTO testt1 (NAME, ID) VALUES ('John Smith', 1)
GO
Step 3 -
プライマリAG のプライマリレプリカ (グローバルプライマリ): 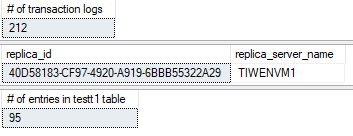
プライマリAG のセカンダリレプリカ:
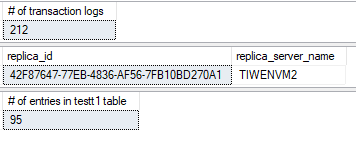
セカンダリAG のプライマリレプリカ (フォワーダー):
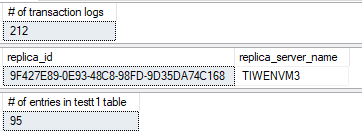
セカンダリAG のセカンダリレプリカ: 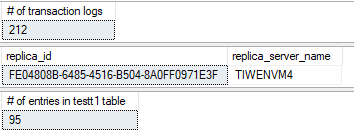
トランザクションログのサイズがINSET 文の実行により大きくなります。test データベースで内のエントリーの数も 10行分増加しています。
Step 4 -
グローバルプライマリにてトランザクションログのバックアップを取得します。
Step 5 -
プライマリAG のプライマリレプリカ (グローバルプライマリ):

プライマリAG のセカンダリレプリカ:

セカンダリAG のプライマリレプリカ (フォワーダー):

セカンダリAG のセカンダリレプリカ:

各レプリカの truncation_lsn が現在の LSN まで増加し、トランザクションログも切り捨てられるため、トランザクションログは圧縮されます。
Step 6 -
セカンダリ AG のセカンダリレプリカにある test データベースへのデータ移動を中断します。 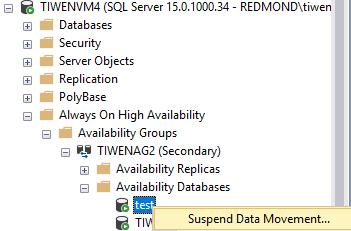
Step 7 -
Step 2 と Step3 を繰り返したのちに、セカンダリ AG のセカンダリレプリカ (TIWENVM4) 以外のすべてのレプリカの test データベースのデータは もう10行 insert されたデータの分だけ更新されています。セカンダリAG のセカンダリレプリカに存在するデータベースのデータは、データ移動が中断されているため、同期されていません。
プライマリAG のプライマリレプリカ (グローバルプライマリ):
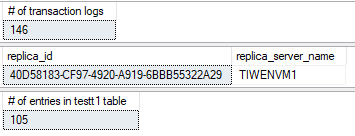
プライマリAG のセカンダリレプリカ:
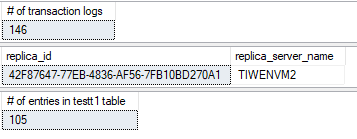
セカンダリAG のプライマリレプリカ (フォワーダー):
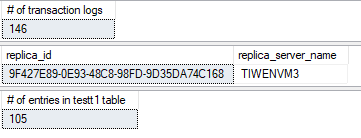
セカンダリAG のセカンダリレプリカ:
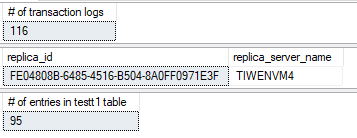
Step4と Step5 を繰り返したあとの結果は以下です。
プライマリAG のプライマリレプリカ (グローバルプライマリ):

プライマリAG のセカンダリレプリカ:

セカンダリAG のプライマリレプリカ (フォワーダー):

セカンダリAG のセカンダリレプリカ:

新しく生成されたトランザクションログは、プライマリAG のセカンダリレプリカでは切り捨てられています。しかしながら、プライマリAGのプライマリレプリカでは truncation_lsn は、10行のInsert とトランザクションログのバックアップによって変化していません。前述した通り、これはセカンダリAG のセカンダリレプリカ"TIWENVM4" が同期されておらず、Insert クエリによって生成されたトランザクションログが適用されていないからです。
分散型可用性グループのグローバルプライマリでは、分散型可用性グループに参加するすべてのレプリカ内で一番古い LSN までしかトランザクションログを切り捨てません、このロジックにより、フォワーダーとセカンダリAGのセカンダリレプリカが完全に同期されていない状況下において、フォーワーダーが消失した場合でも、グローバルプライマリが健全な状態であり、またセカンダリAGのセカンダリレプリカと通信が出来ていれば、データロスがない事を保証しています。
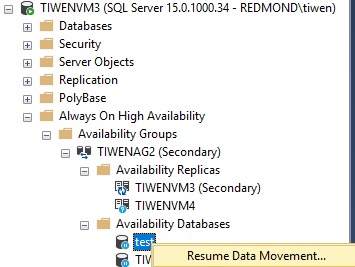
上記シナリオをシミュレーションするために、セカンダリAG のプライマリレプリカ(TIWENVM3) のネットワークを遮断します。これにより、セカンダリAG のセカンダリレプリカ (TIWENVM4)のデータ移動を再開する前に TIWENVM3 が使用不可になります。 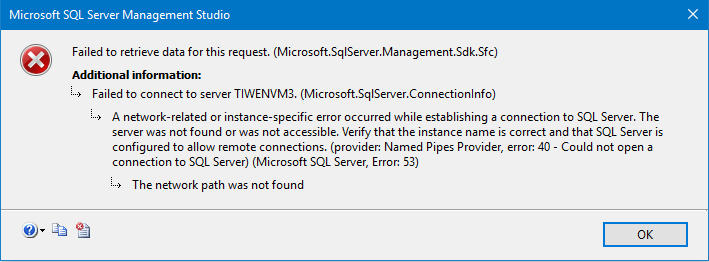
TIWENVM4 上の test データベースのデータ移動を再開させると、セカンダリAG TIWENAG2は、解決中のステータスになります。これは、セカンダリAG TIWENAG2 上のプライマリレプリカ TIWENVM3 と通信が出来ないためです。これを解消するには、フェールオーバーをする必要があります。分散型可用性グループのセカンダリAGのフォワーダーが使用可能でない場合、セカンダリAGのセカンダリレプリカにて実行可能なフェールオーバーオプションは FORCE_FAILOVER_ALLOW_DATA_LOSS のみです。
ALTER AVAILABILITY GROUP TIWENAG2 FORCE_FAILOVER_ALLOW_DATA_LOSS
セカンダリAG のセカンダリレプリカ TIWENVM4 にて FORCE_FAILOVER_ALLOW_DATA_LOSS オプションにてフェールオーバーを実行した後、以前のフォワーダーが使用不可な状況においてもデータベースの同期は行われます。これは、グローバルプライマリがセカンダリAG上のセカンダリレプリカのトランザクションログの同期されていない分を管理しているからです。

このシナリオでは、 FORCE_FAILOVER_ALLOW_DATA_LOSS オプションをつけてフェールオーバーではあるものの、データ損失は発生しません。
一つ注意したいのは、FORCE_FAILOVER_ALLOW_DATA_LOSS 後に以前のプライマリレプリカ(TIWENVM3) が復旧した場合、データ移動は自動的に再開されないため、手動でデータ移動を再開させる必要があります。この動作は、分散型可用性グループに限らず、一般的な可用性グループにて FORCE_FAILOVER_ALLOW_DATA_LOSS が行われた場合の仕様となります。これは、以前のプライマリレプリカと現在のプライマリレプリカにてデータの差異や競合が発生する可能性があり、ユーザーが自身でどのデータが適切か判断する必要があるからです。
TIWENVM3 のデータ移動を再開させたあと、分散型可用性グループ内のすべてのレプリカは同期がされ、トランザクションログの切り捨ても同じ時点まで行われます。
プライマリAG のプライマリレプリカ (グローバルプライマリ):

プライマリAG のセカンダリレプリカ:

(New) セカンダリAG のセカンダリレプリカ: (元フォワーダー):

(New) セカンダリAG のプライマリレプリカ (新フォワーダー): 
今回のシナリオでは FORCE_FAILOVER_ALLOW_DATA_LOSS にてフェールオーバーをしデータ損失はありませんでしたが、これは必ずしも分散型可用性グループにてこのオプションを使用した場合にデータ損失がないわけではありません。例えば、プライマリAG が損失した場合、セカンダリAG にて強制フェールオーバーを行う場合は、データ損失が発生する可能性があります。またこの例に限らずデータ損失が発生する可能性がある点についても注意が必要です。