T-SQL Anti-pattern of the day: 'all-in-one' queries
Scenario
A common requirement for enquiry queries on an OLTP database is to have search criteria which are very specific ('get me details for for OrderID = NNNN') and also the occasional reports which ask for all the orders ('get me all the orders, no questions asked'.) Here is a sample from AdventureWorks which illustrates the problem:
CREATE PROCEDURE RptOrder(@OrderID int)
AS
BEGIN
SELECT *
FROM Sales.SalesOrderHeader
WHERE (SalesOrderID = @OrderID OR @OrderID IS NULL)
END
What is the meaning of the underlined predicate in the above WHERE clause? It is actually a 'special case' where the developer intends to get back all the rows, regardless of the OrderID. This 'special case' is triggered by passing in a value of NULL for the @OrderID parameter.
Problem
So while this construct looks good in theory, it lends itself to very poor performance. Take a look at the 2 cases where this procedure is executed.
Case A: with specific OrderID
EXEC RptOrder 43672
Case B: asking for all records
EXEC RptOrder NULL
The plan, it turns out, is the same for both cases and a scan is used! This is despite a seekable index being present on SalesOrderID column for the SalesOrderHeader table:

The reason the optimizer chooses to scan the SalesOrderHeader (in this case it chooses a non-clustered index scan) is because it has no way to determine at compile and optimization time, as to what the specific value of @OrderID would be. Hence it has no way to 'fold' the (@OrderID IS NULL) expression and therefore has no option but to look at all the records.
Workarounds
'IF-ELSE' Workaround: The straightforward workaround in simple cases like the one above is to separate out the 2 cases into an IF-ELSE block:
ALTER PROCEDURE RptOrder(@OrderID int)
AS
BEGIN
IF (@OrderID IS NOT NULL)
BEGIN
SELECT *
FROM Sales.SalesOrderHeader
WHERE (SalesOrderID = @OrderID)
END
ELSE
BEGIN
SELECT *
FROM Sales.SalesOrderHeader
END
END
Now, the 2 test cases work as expected. Here are the execution plans:
EXEC RptOrder 43672
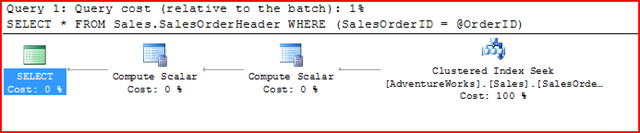
EXEC RptOrder NULL

Dynamic SQL Workaround: However, as the number of predicates in the WHERE clause increase, and if all those predicates (or most of them) have such 'catch-all' handling then the IF - ELSE construct becomes unviable. In those cases, a dynamic SQL construct should be considered. Of course, when dealing with dynamic SQL, we must consider security first, including the possibility of SQL Injection and also the Execution Context of the dynamic SQL statement. But that is a topic for another post. Right now, here is how we could handle something like that:
-- NOTE: This code is highly simplified and does not provide for any screening
-- or protection against SQL injection!!! Provided as-is, confers no warranties.
ALTER PROCEDURE RptOrder(@OrderID int)
AS
BEGIN
DECLARE @sDynamicSQL nvarchar(4000)
SELECT @sDynamicSQL = 'SELECT * FROM Sales.SalesOrderHeader 'IF (@OrderID IS NOT NULL)
BEGIN
SELECT @sDynamicSQL = @sDynamicSQL + ' WHERE (SalesOrderID = @OrderID)'
ENDEXEC sp_executesql @sDynamicSQL, N'@OrderID int', @OrderID = @OrderID
END
Different Code Paths: The cleanest way of course is to consider having separate procedures for each kind of query. For example we can have a procedure called RptSpecificOrder for the case where we are searching by specific OrderID, and another one called RptAllOrders for the 'get-me-everything' case. This does have the advantage of clean isolation, but it does not scale easily when the number of predicates are larger. But is does also have the advantage that if we are querying for specific orders 99% of the time, that code path is simplified and optimized accordingly.
Conclusion
Beware of this T-SQL anti-pattern as it is one of the most common ones we see and it does have a huge (negative) impact on query performance. As you can see, if they are not done with these patterns in mind, application design and reporting requirements can have a detrimental effect on OLTP query execution. Separating reporting and OLTP workloads could be the key to solving these kinds of issues. But if separation is not possible, then clever use of separate code paths and stored procedures could help ensure that the most efficient execution plan is selected for each case. For complex queries, dynamic SQL may offer the simplest way out, but due care has to be taken to ensure that permissions and SQL injection issues are kept in mind when dealing with dynamic SQL statements.