Hadoop Yarn memory settings in HDInsight
(Edit: thanks Mostafa for the valuable feedback, I updated this post with explanation about the relationship between Yarn base and Java base memory settings)
There are several related memory settings for jobs running in HDInsight cluster which most customers need to pay close attention to. When not correctly set, it will cause obscure failures in Hive/Pig/Mapreduce/Tez jobs.
Note that HDInsight service provides default memory settings, however, the defaults may be subject to change as we tune the service for various workloads or as we move to different VM types and hardware. It is advised that customers explicit set these settings once they know the right settings for their specific jobs. There are two ways to apply these settings: 1) provide it when creating HDInsight cluster using SDK. or 2) set it on a per job basis. E.g. use "-Define" option in Powershell SDK, or "set property=value" in a hive script, or set it in mapreduce code directly. Note that the Yarn level settings can only be changed during cluster creation.
1. Yarn memory settings:
HDInsight 3.x service deploys Hadoop 2.x clusters. Hadoop 2.x (Yarn) introduced the concept of containers. Unlike Hadoop 1.x where each node is assigned a fixed number of "slots", in Hadoop 2.x each Yarn task (mapper, reducer or Tez task) is assigned a container which has an memory limit. This affects 1) how many containers can run in parallel in any given node; and 2) Yarn Node Manager will monitor the memory usage of the task and kill a container when the memory usage exceeds that limit.
Yarn defines how much memory is available for allocation and what is the minimum and maximum container size:
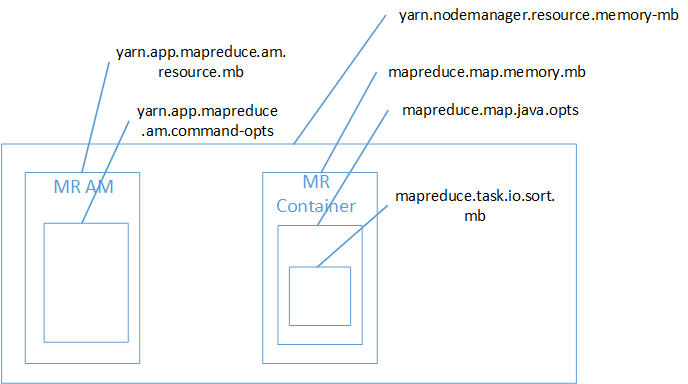
yarn.nodemanager.resource.memory-mb = 5376
yarn.scheduler.minimum-allocation-mb = 768
yarn.scheduler.maximum-allocation-mb = 5376
Note that you can only ask for container size of multiples of minimum-allocation-mb. In the above example settings, if you ask for a container of size 1024MB, you will actually get a container of 1536MB.
2. Mapreduce memory settings:
These are the default Yarn container memory settings in HDInsight for the mapper, reducer and AM(Application Master):
mapreduce.map.memory.mb = 768
mapreduce.reduce.memory.mb = 1536
yarn.app.mapreduce.am.resource.mb = 1536
This is a typical error message in your job attempt log, if these limits are exceeded:
Container[pid=container_1406552545451_0009_01_000002,containerID=container_1406552545451_0009_01_000002] is running beyond physical memory limits. Current usage: 519.1 MB of 512 MB physical memory used; 770.1 MB of 1.0 GB virtual memory used. Killing container. Dump of the process-tree for container_1406552545451_0009_01_000002 : |- PID CPU_TIME(MILLIS) VMEM(BYTES) WORKING_SET(BYTES) |- 4912 15 667648 2502656 |-4712 9546 232022016 97697792 |- 6000 78 1867776 2605056 |- 4780 50234 571166720 438947840 |- 4516 31 1810432 2588672 Container killed on request. Exit code is 137
Aside from the memory monitoring, each Java process has its own heap space settings. These are the default settings for the mapper, reducer and AM:
mapreduce.map.java.opts = "-Xmx512m"
mapreduce.reduce.java.opts = "-Xmx1024m"
yarn.app.mapreduce.am.command-opts = "-Xmx1024m"
This is a typical error message in your job attempt log if these limits are exceeded:
Error: java.lang.RuntimeException: java.lang.OutOfMemoryError: GC overhead limit exceeded
or
Error: java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
The Yarn based and Java based settings are related. The Java heap settings should be smaller than the Yarn container memory limit because we need reserve memory for Java code. The best practice is to reserve 20% memory for code. So if settings are correct, theoretically pure Java-based Hadoop tasks should never get killed by Yarn Node Manager unless there is a bug in your Java code somewhere. If the Yarn based error is seen, the cure is to either increase the Yarn container memory or decrease Java heap space. If the Java heap error is seen, you can either increase both memory settings (in which case you'll get fewer tasks running in parallel), or bring down the memory usage if possible.
For streaming jobs, the developer needs to make sure the streaming program don't exceeds Yarn container memory settings. This might require trial run and iterative tuning.
Eventually the memory usage depends on the job you are doing. For example, if you are doing hive query "CREATE TABLE AS SELECT" on huge tables your mapper may demand more memory than 512MB. To increase memory settings for the mapper, you can overwrite these settings in Mapreduce configuration:
mapreduce.map.memory.mb = 1536
mapreduce.map.java.opts = "-Xmx1024m"
There is another memory setting that depends on the container memory size:
mapreduce.task.io.sort.mb = 307
This is the max memory a mapreduce task can use to sort data in buffer during the shuffle stage. This value should be 1/3 to 1/2 of the task heap size.
This is an illustration of various memory settings for Mapreduce to help you visualize the relative size of them:
3. Tez memory settings
These are the default Tez memory settings for Tez AM:
tez.am.resource.memory.mb = 1536
tez.am.java.opts = 1024
For tez container, it uses mapper's memory settings:
mapreduce.map.memory.mb = 768
mapreduce.map.java.opts = "-Xmx512m"
This is an illustration of various memory settings for Tez:

4. Hive memory settings for Tez:
When using Tez for Hive, you can specify Tez task's memory settings, these are default values:
hive.tez.container.size = -1
hive.tez.java.opts = ""
The default settings mean that the actual Tez task will use the mapper's memory setting:
hive.tez.container.size = mapreduce.map.memory.mb
hive.tez.java.opts = mapreduce.map.java.opts
If you want to have Tez use different memory setting from the Mapreduce framework, you can modify these settings for Hive configuration.
There is another important memory setting in hive that depends on Tez container size:
hive.auto.convert.join.noconditionaltask.size = 159519866
This is memory used for caching smaller joining table. During hive join operation, if the smaller one of the two joined tables is smaller than this value, hive will perform map side join, which is significantly faster. This value should fit in the container memory along with the io.sort.memory, as shown in this illustration for Hive on Tez:

5. WebHCat memory settings:
WebHCat(also known as Templeton) uses Mapreduce job (the LaunchMapper) to submit user's Hadoop job. So the Mapreduce memory settings are also applicable to WebHCat's LaunchMapper. However, usually the LaunchMapper will need more memory than the default mapper memory limit of 512MB. For example, for a user's Hive job submitted through WebHCat, LaunchMapper will call hive command line which may start local task that requires close to 1GB memory. In this case you can use this configuration to set LaunchMapper's memory limit to 1GB:
templeton.mapper.memory.mb = 1024
References:
Comments
Anonymous
August 06, 2014
Thanks for this useful piece of information. You saved my day!Anonymous
November 04, 2014
Very useful, thanks.Anonymous
August 06, 2015
Useful !! Thanks