Columnstore Index Performance: SQL Server 2016 – String Predicate Pushdown
SQL product team has made significant improvements in columnstore index functionality, supportability and performance during SQL Server 2016 based on the feedback from customers. This blog series focuses on the performance improvements done as part of SQL Server 2016. Please refer to one of the previous blogs No performance cliff for details.
The topic of this blog is how SQL Server columnstore index processes string data types. When designing a Data Warehouse, a general recommendation is to use non-string columns to filter rows or to apply join predicates. However, in many customer workloads, we found that string based columns are often used for filtering the data. As you can imagine, applying predicates on String values is lot more expensive than filtering on an Integer column and can slowdown analytics queries significantly specially on large DWs. The columnstore index in SQL Server 2016 allows string predicates to be pushed down to the SCAN node resulting in significant improvement in query performance. Like before, this speed up is automatic when you upgrade to SQL Server 2016 requiring no changes to your query or workload.
Methodology:
The String predicate push down leverages the ‘dictionaries’ that are created per column with each compressed rowgroups. Please refer to columnstore index overview and impact of dictionary on rowgroup size for some context. There are two kinds of dictionaries, Global and Local, but for this discussion, we will not differentiate between the two. The important point to note is that dictionary entries store the full column value and each column segment contains the reference to the dictionary entry. If same value is repeated multiple times, it is stored in the dictionary once but referenced multiple times. SQL Server 2016 utilizes dictionary entries to speed the string predicates.
Now, let us first look into how string predicates are processed in SQL Server 2014. The query in the picture below is counting number of orders that have the string ‘tool’ in its name. The ‘FILTER’ node applies the string predicate for each of the rows in BatchMode. Since there are 10 million rows scanned, there will be 10 million string comparisons. Note, the query processing is still benefitting from BatchMode processing

SQL Server 2016 leverage strings stored in the dictionary to minimize the string comparisons by pushing it to the SCAN node. If you assume that each item is repeated 100 times on average, then there are approximately 100K distinct values. The reason I indicated ‘approximate’ because assuming 10 compressed rowgroups, these values will be distributed randomly across these. SQL Server compares the strings stored in the dictionary and returns the rows that qualify. For example, if a dictionary entry matched with ‘%tool%’, then all referencing rows in the rowgroup are returned. So instead of comparing each value separately, we compared only one. For the example above, this allows us to reduce the string comparison by approximately 100x there by speeding up the query performance as shown in the picture below. I have made the picture a bit more complicated to show that 100K rows were in delta rowgroup where there is no dictionary so this optimization can’t be used but for other 9.9 million rows, the string predicate was applied to dictionary entries. 
Now, let us take a real example and show its execution both on both versions on SQL Server
SQL Server 2014
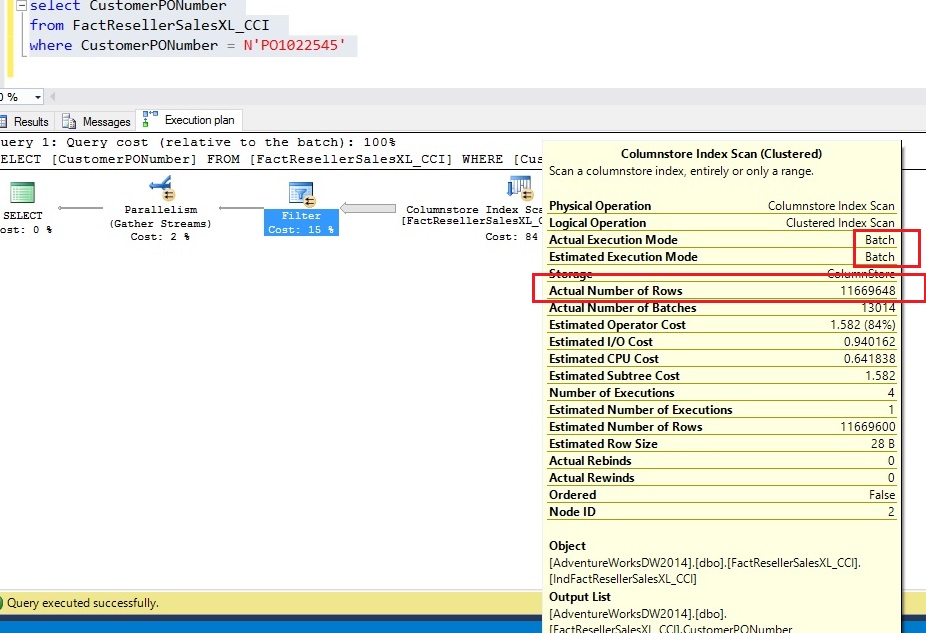
As shown in the picture below, columnstore index was indeed executed in BatchMode and 11+ million rows were returned. So the string predicate was applied to all the rows at the ‘Filter’ node. The query execution time was as follows
SQL Server Execution Times:
CPU time = 3984 ms, elapsed time = 1185 ms
SQL Server 2016
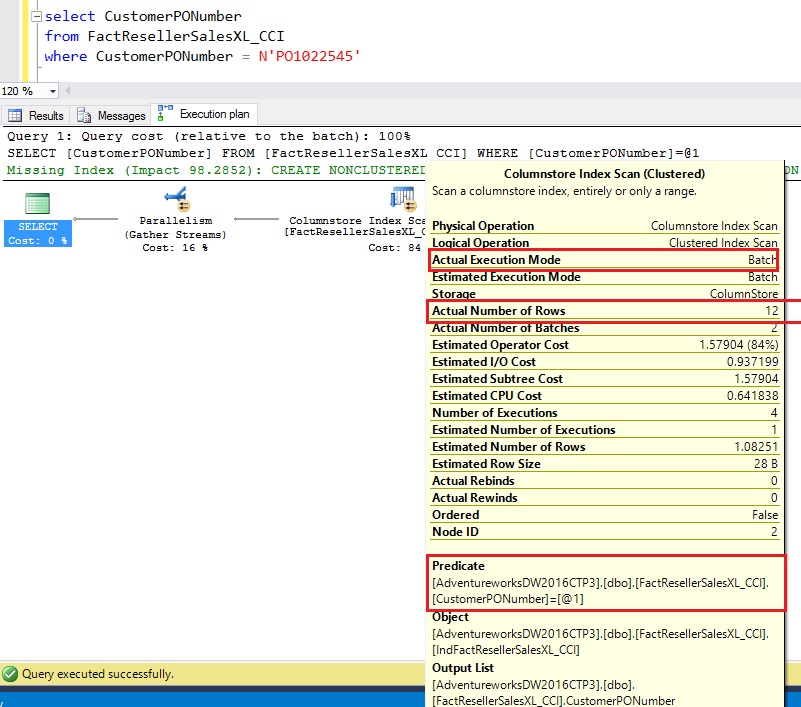
SQL Server 2016 pushes the string predicate to the SCAN node and only 12 rows are returned unlike 11+ million rows in SQL Server 2014. Also, there is no explicit ‘Filter’ node because there were no delta RGs. The query execution time improved as well
SQL Server Execution Times:
CPU time = 2671 ms, elapsed time = 987 ms
Like before, you get the query performance improvement automatically when you upgrade to SQL Server 2016. This optimization is available across all database compatibility modes.
Couple of important points to note about string predicate pushdown
- Works only on compressed rowgroups
- We only allow up to 64K entries in the bitmap so if the number of entries in the dictionary are larger than that, this optimization is not available. I expect this to be a rare case
Happy upgrading to SQL Server 2016!
Thanks,
Sunil Agarwal
SQL Server Tiger Team Twitter | LinkedIn
Follow us on Twitter: @mssqltiger | Team Blog: Aka.ms/sqlserverteam
Comments
- Anonymous
May 02, 2017
Sturle: Thanks for posting the performance that you are seeing with string predicate pushdown. We are indeed looking into addressing efficient string processing in future release. No firm commit at this time