Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
In a previous post, we looked at best practices for optimizing the performance of Row-Level Security (RLS) predicates: adding relevant indexes, minimizing excessive joins, etc. This post shows you how to discover and verify empirically which configurations yield the best performance for your workload. We’ll do this by A/B testing different RLS configurations, and using the Query Store (new on Azure SQL Database and SQL Server 2016) to measure the impact. Specifically, in this post we'll test the performance of different indexes on the AdventureWorks2014 sample database while using RLS to limit employees' access to sales data based on their position in the org hierarchy.
Full demo script: https://rlssamples.codeplex.com/SourceControl/latest#RLS-Query-Store.sql
Setup: Enabling RLS in AdventureWorks2014
For this demo, we’ll use the AdventureWorks2014 sample database. You can download it here.
AdventureWorks comes with several indexes pre-created. For the purposes of this demo, we’re going to drop all existing nonclustered indexes on the Employee, SalesOrderHeader, and SalesOrderDetail tables. Normally you wouldn’t do this, but for demo purposes, we’d like to start with a clean slate and then learn which indexes are most important to our workload:
DROP INDEX AK_Employee_LoginID ON HumanResources.Employee
DROP INDEX AK_Employee_NationalIDNumber ON HumanResources.Employee
DROP INDEX AK_Employee_rowguid ON HumanResources.Employee
DROP INDEX IX_Employee_OrganizationLevel_OrganizationNode ON HumanResources.Employee
DROP INDEX IX_Employee_OrganizationNode ON HumanResources.Employee
DROP INDEX AK_SalesOrderHeader_rowguid ON Sales.SalesOrderHeader
DROP INDEX AK_SalesOrderHeader_SalesOrderNumber ON Sales.SalesOrderHeader
DROP INDEX IX_SalesOrderHeader_CustomerID ON Sales.SalesOrderHeader
DROP INDEX IX_SalesOrderHeader_SalesPersonID ON Sales.SalesOrderHeader
DROP INDEX AK_SalesOrderDetail_rowguid ON Sales.SalesOrderDetail
DROP INDEX IX_SalesOrderDetail_ProductID ON Sales.SalesOrderDetail
go
AdventureWorks has a number of salespeople, whose LoginIDs are stored in the Employee table:
SELECT e.* FROM HumanResources.Employee e
INNER JOIN Sales.SalesPerson sp ON e.BusinessEntityID = sp.BusinessEntityID
go
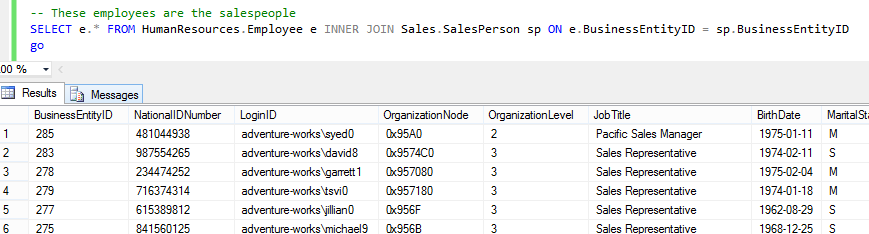
We’ll create a few test users for these salespeople, since AdventureWorks does not do this for us:
-- Create a few test users (salespeople) for the demo
CREATE USER stephen0 WITHOUT LOGIN -- North American Sales Manager (hierarchyid = /6/1/)
CREATE USER david8 WITHOUT LOGIN -- regular salesperson (hierarchyid = /6/1/9/)
CREATE USER amy0 WITHOUT LOGIN -- European Sales Manager (hierarchyid = /6/3/)
CREATE USER rachel0 WITHOUT LOGIN -- regular salesperson (hierarchyid = /6/3/1/)
GRANT SELECT ON Sales.SalesOrderHeader TO stephen0, david8, amy0, rachel0
GRANT SELECT ON Sales.SalesOrderDetail TO stephen0, david8, amy0, rachel0
go
Each order in the SalesOrderHeader and SalesOrderDetail tables is assigned to a salesperson. We want to ensure that salespeople can only see orders that are assigned to them, or are assigned to employees who report to them in the org hierarchy (i.e. a manager should be able to see all orders assigned to her team). So, we create the following RLS policy:
CREATE SCHEMA rls
go
CREATE FUNCTION rls.salesPersonPredicate(@SalesPersonID int)
RETURNS TABLE
WITH SCHEMABINDING
AS
-- only see orders assigned to you, or assigned to salespeople who report to you
RETURN SELECT 1 AS accessResult
FROM HumanResources.Employee e1
INNER JOIN HumanResources.Employee e2
ON e2.OrganizationNode.IsDescendantOf(e1.OrganizationNode) = 1
WHERE e1.LoginID = 'adventure-works\' + USER_NAME()
AND e2.BusinessEntityID = @SalesPersonID
go
CREATE FUNCTION rls.salesPersonPredicate_LookupSalesPerson(@SalesOrderID int)
RETURNS TABLE
WITH SCHEMABINDING
AS
-- only see orders assigned to you, or assigned to salespeople who report to you
-- (note: need to look up assigned SalesPersonID in SalesOrderHeader)
RETURN SELECT 1 AS accessResult
FROM HumanResources.Employee e1
INNER JOIN HumanResources.Employee e2
ON e2.OrganizationNode.IsDescendantOf(e1.OrganizationNode) = 1
INNER JOIN Sales.SalesOrderHeader soh
ON e2.BusinessEntityID = soh.SalesPersonID
WHERE e1.LoginID = 'adventure-works\' + USER_NAME()
AND soh.SalesOrderID = @SalesOrderID
go
CREATE SECURITY POLICY rls.salesPersonPolicy
ADD FILTER PREDICATE rls.salesPersonPredicate(SalesPersonID) ON Sales.SalesOrderHeader,
ADD FILTER PREDICATE rls.salesPersonPredicate_LookupSalesPerson(SalesOrderID) ON Sales.SalesOrderDetail
go
As a sanity check, we can verify that user ‘stephen0’ (the North American Sales Manager) can only see orders assigned to him or to his reports, and that user ‘david8’ (a regular salesperson) can only see orders assigned to him:
EXECUTE AS USER = 'stephen0' -- North American Sales Manager (hierarchyid = /6/1/)
SELECT * FROM Sales.SalesOrderHeader -- 2989 rows, assigned to stephen0 or his reports lower in the hierarchy
SELECT * FROM Sales.SalesOrderDetail -- 46680 rows, details for stephen0's or his reports' orders
REVERT
go
EXECUTE AS USER = 'david8' -- regular salesperson (hierarchyid = /6/1/9/)
SELECT * FROM Sales.SalesOrderHeader -- 189 rows, assigned to david8
SELECT * FROM Sales.SalesOrderDetail -- 2247 rows, details for david8's orders
REVERT
go
For a more realistic workload than the above ‘SELECT *’ queries, let’s create a stored procedure encapsulating a "critical query" that gets our best-selling products. Because of the security policy, the accessible data will be limited to the orders assigned to you or to your reports:
-- Create an example workload with a ‘critical query’ that gets the most-sold products
-- Security policy restricts this to orders assigned to you, or to your reports
CREATE PROC sp_get_top_products
AS
SELECT TOP 10 sod.ProductID, SUM(sod.OrderQty) AS TotalOrders
FROM Sales.SalesOrderDetail sod
GROUP BY sod.ProductID
ORDER BY TotalOrders DESC
go
GRANT EXECUTE ON sp_get_top_products TO stephen0, david8, amy0, rachel0
GRANT EXECUTE ON sp_get_top_products TO stephen0, david8, amy0, rachel0
go
Performance tuning with the Query Store
With the demo now set up, let's investigate performance optimizations. First, you should turn on the Query Store and clear the cache in case it was on already. We’ll also choose a fine-grained statistics aggregation interval of one minute to make performance changes easier to see for this demo.
ALTER DATABASE AdventureWorks2014 SET QUERY_STORE=ON
go
ALTER DATABASE AdventureWorks2014 SET QUERY_STORE (INTERVAL_LENGTH_MINUTES = 1, QUERY_CAPTURE_MODE = AUTO)
go
ALTER DATABASE AdventureWorks2014 SET QUERY_STORE CLEAR
go
Next, let’s simulate a workload by looping through our critical query ("sp_get_top_products") a few times as an example user:
EXECUTE AS USER = 'david8'
DECLARE @i int = 0
WHILE (@i < 100)
BEGIN
EXEC sp_get_top_products;
SET @i = @i + 1;
END
REVERT
go
Under the AdventureWorks2014 database in the SSMS Object Explorer, navigate to Query Store > Top Resource Consuming Queries. You’ll see that our top products query (query_id = 1, since it’s the first query we ran after clearing the cache) has a recommendation that we create a nonclustered index on Sales.SalesOrderHeader(SalesPersonID). This makes sense because the predicate function on Sales.SalesOrderDetail uses this column to determine whether the current user should have access to a given row.
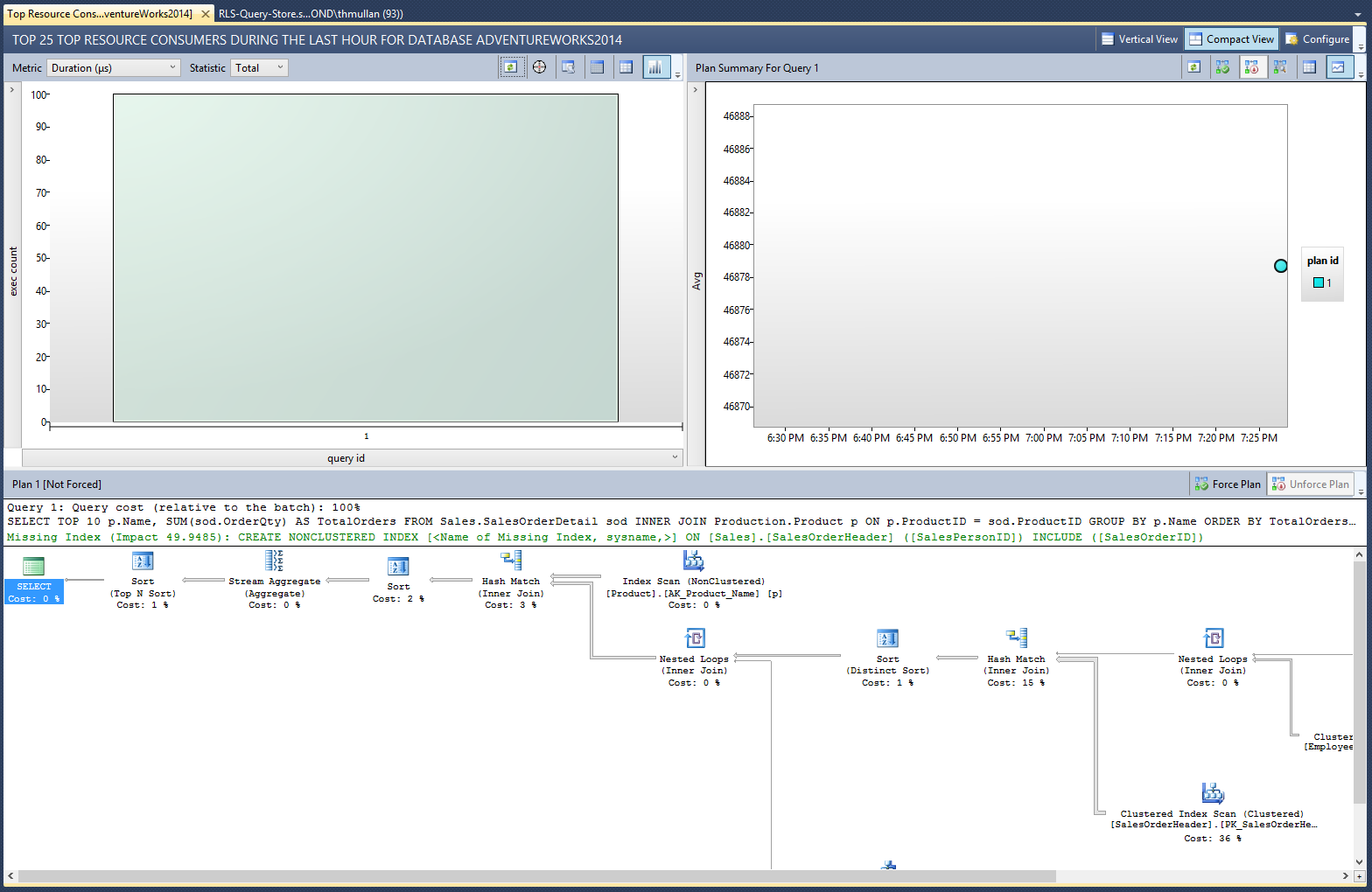
But how much will adding this index actually improve our query’s performance? To verify this recommendation empirically, let’s create the recommended index and then simulate our workload again:
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_SalesPersonID ON Sales.SalesOrderHeader (SalesPersonID)
go
EXECUTE AS USER = 'david8'
DECLARE @i int = 0
WHILE (@i < 100)
BEGIN
EXEC sp_get_top_products;
SET @i = @i + 1;
END
REVERT
go
Now if we return to the Top Resource Consuming Queries and hit refresh, we can see the performance benefit: On average, the new query plan yields about 50% better performance in terms of Duration, CPU Time, Logical Reads, and Memory Consumption.
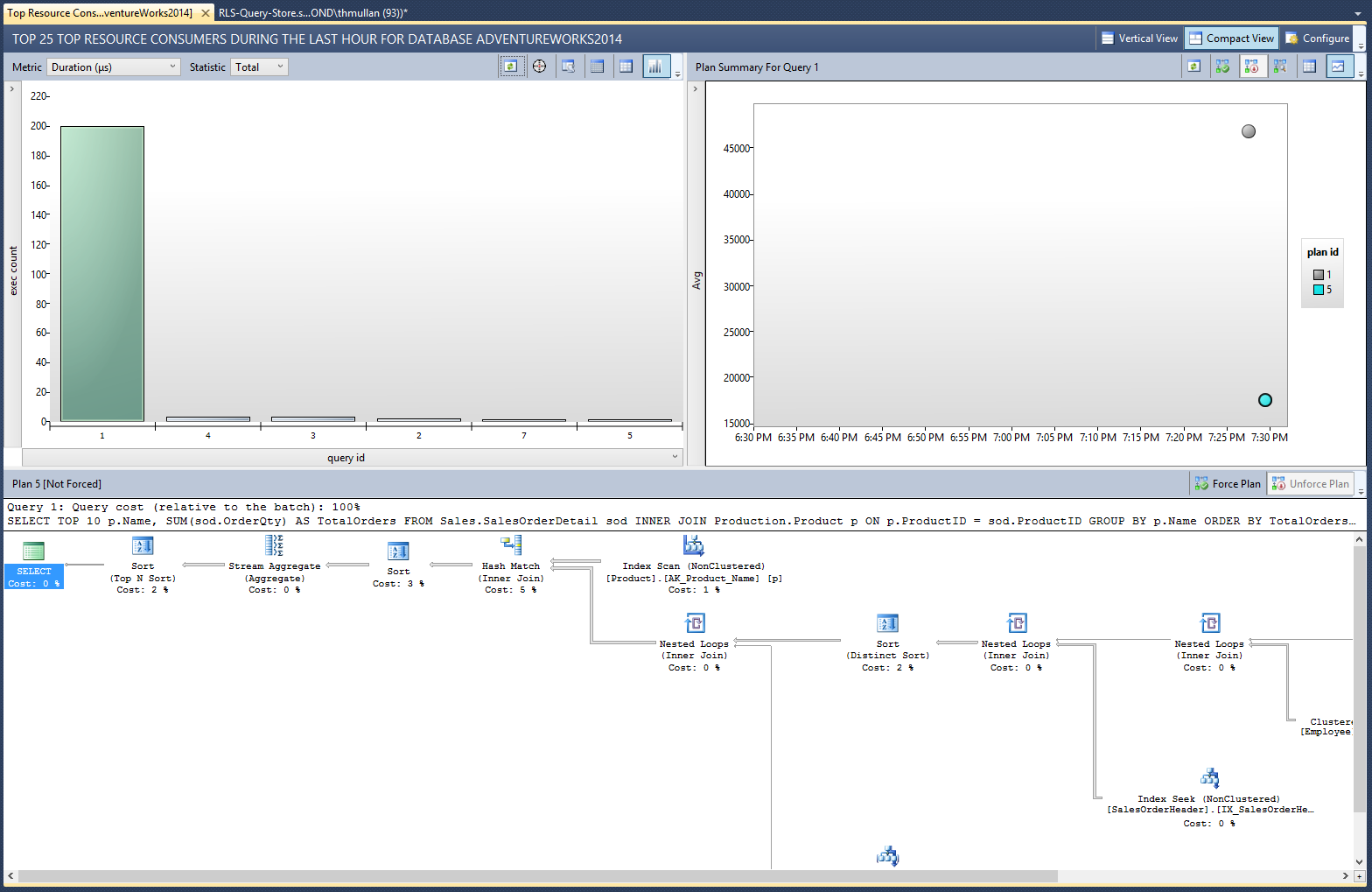
Note, if you prefer T-SQL over the SSMS UI, you can examine the performance results by querying the Query Store DMVs like this:
SELECT p.plan_id, q.query_id, qt.query_text_id, qt.query_sql_text, p.query_plan,
RANK() OVER (ORDER BY MIN(rs.first_execution_time) ASC) AS execution_order, -- identify plans by the order in which we ran them
SUM(rs.count_executions) AS total_execution_count,
AVG(rs.avg_duration) AS avg_avg_duration, -- 'average average' because Query Store already aggregates at a smaller interval
MIN(rs.min_duration) AS min_duration,
MAX(rs.max_duration) AS max_duration,
AVG(rs.avg_cpu_time) AS avg_avg_cpu_time,
AVG(rs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
AVG(rs.avg_physical_io_reads) AS avg_avg_physical_io_reads
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
WHERE qt.query_sql_text LIKE 'SELECT TOP 10 p.Name%' -- only show our query
GROUP BY p.plan_id, p.query_plan, q.query_id, qt.query_text_id, qt.query_sql_text
ORDER BY execution_order ASC;
We now have empirical evidence that this new index improves our critical query's performance by around 50 percent. What about other indexes we might add? For instance, looking at both our predicate functions and the two index scans at the far right in our current query plan, we might hypothesize that adding indexes on HumanResources.Employee(LoginID) and HumanResources.Employee(OrganizationNode) could also boost performance.
We can A/B test the performance impact of adding each of these indexes using the same methods as before:
- Set up the configuration you’d like to test
- Loop through the critical query many times, to generate meaningful averages
- Pause for a minute, to ensure that we’re in a new Query Store aggregation interval
- Repeat for as many different configurations as you’d like to test
- Compare results using either the Query Store UI or DMVs
In code:
CREATE UNIQUE NONCLUSTERED INDEX AK_Employee_LoginID ON HumanResources.Employee(LoginID)
go
EXECUTE AS USER = 'david8'
DECLARE @i int = 0
WHILE (@i < 100)
BEGIN
EXEC sp_get_top_products;
SET @i = @i + 1;
END
REVERT
go
WAITFOR DELAY '00:01:00' -- to make sure we're in a new Query Store aggregation interval
go
CREATE NONCLUSTERED INDEX IX_Employee_OrganizationNode ON HumanResources.Employee(OrganizationNode)
go
EXECUTE AS USER = 'david8'
DECLARE @i int = 0
WHILE (@i < 100)
BEGIN
EXEC sp_get_top_products;
SET @i = @i + 1;
END
REVERT
go


Note that exact numbers will vary across different machines and environments (particularly if there are other noisy processes that can cause temporary discrepancies in performance).
These results suggest that the first index we created (on SalesRepID) had a significantly positive impact on our critical query's performance, while the subsequent two indexes had relatively minor positive impacts on the performance. By considering the empirical evidence revealed by experiments like this, we can make informed, data-driven decisions about how to optimize our RLS-enabled workload.
Summary
This post has demonstrated one way to A/B test the performance of RLS predicates using the Query Store. In this demo, we focused on adding indexes to columns used for lookups and joins in the predicate function. However, the same methods can be used to test other kinds of configuration changes. For instance, you could evaluate the impact of eliminating a join in a predicate function, or of eliminating a disjunction, using a similar approach.
Questions or comments about Query Store and RLS? Please let us know in the comments below.
You can find more information about using the Query Store in this blog post and in the MSDN documentation.