Cet article a fait l'objet d'une traduction automatique.
Points de données
Syndication de données et stockage isolé de Silverlight
John Papa
Téléchargement de code disponible de la bibliothèque de code MSDN
Parcourir le code en ligne
Contenu
L'obtention de fin
Demandes Web HTTP et le threading
Ajouter un flux
L'analyse de flux
Demandes entre domaines pour les flux
Base stockage isolé
Organisé stockage isolé
Wrap-Up
Silverlight est idéal pour création d'une application lecteur news syndiqué. Il peut lire RSS et AtomPub formats syndiqués, communiquer avec les services Web via des demandes HTTP et gérer des stratégies entre domaines. Une fois que les données Syndication a été reçues, il peut être lu dans une structure de classe analysé avec LINQ et présentées à l'utilisateur via la liaison de données basée sur XAML.
Dans cette rubrique j'explique comment utiliser ces fonctionnalités uniques pour créer un lecteur de news Syndication. J'AI également affiche vous comment déboguer des problèmes avec communications de service Web de Silverlight et comment stocker les données localement à l'aide d'isolé de stockage. Tous les exemples sont disponibles dans le téléchargement de code MSDN.
L'obtention de fin
Flux de syndication fournit l'accès aux formats de RSS et AtomPub via des services Web. Chaque flux est accessible via un URI qui renvoie du XML contenant les éléments flux utilisant les formats RSS ou AtomPub. L'exemple d'application fourni avec cette colonne présente techniques que lire des données Syndication utilisant des demandes de service Web dans une application Silverlight. Avant de plonger dans les détails, il peut être utile si je vous affichez la version terminée de l'application. Ensuite, j'aborderai la logique et divers autres aspects de code de l'application.
La figure 1 Indique l'application Silverlight lecture de ces deux flux de syndication :
http://pipes.yahooapis.com/pipes/pipe.run?_id=957
d9624940693fb9f9644d7b12fb0e9&_render=rss
http://pipes.yahooapis.com/pipes/pipe.run?_id=057559bac7aad6640b
c17529f3421db0&_render=rss
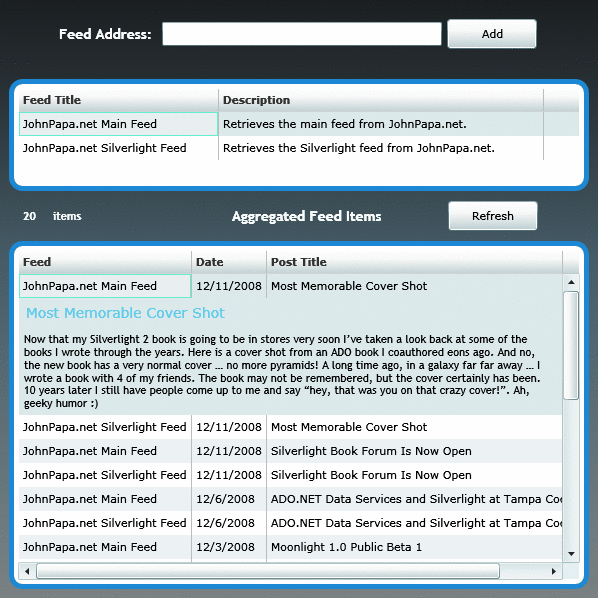
Figure 1 la SilverlightSyndicationApplication
Une demande Web est effectuée pour rassembler les données de flux lorsque l'utilisateur clique sur le bouton Ajouter. URI du flux est stockée localement sur l'ordinateur client, et le titre du service flux est affiché dans le contrôle DataGrid supérieur.
Stocker l'URI du flux sur l'ordinateur client permet à l'application Silverlight d'obtenir les données flux pour les flux lorsque l'application démarre. Lorsque les données de flux sont collectées, les éléments sont placés dans une liste d'objets et puis analyser à l'aide de LINQ. Les résultats sont ensuite liés au contrôle DataGrid inférieur dans l'ordre trié.
Demandes Web HTTP et le threading
Consomme flux syndiqué applications Silverlight commence à rendre les demandes Web. Le WebClient et les classes HttpWebRequest peuvent apportez de Web HTTP demandes émanant d'applications Silverlight. La première étape dans le processus est décider technique à utiliser pour rendre des demandes Web HTTP. Dans la plupart des cas, la classe WebClient est tout ce qui est nécessaire car il est plus simple d'utiliser (il appelle également la HttpWebRequest en coulisses). HttpWebRequest permet la personnalisation plus des demandes.
Cet extrait de code montre comment effectuer une demande via le service WebClient :
//feedUri is of type Uri
WebClient request = new WebClient();
request.DownloadStringCompleted += AddFeedCompleted;
request.DownloadStringAsync(feedUri);
Le code suivant, en revanche, montre comment effectuer un appel semblable à l'aide de HttpWebRequest :
//feedUri is of type Uri
WebRequest request = HttpWebRequest.Create(feedUri);
request.BeginGetResponse(new AsyncCallback(ReadCallback), request);
La classe WebClient est plus facile à utiliser, car il encapsule certaines des fonctionnalités de la classe HttpWebRequest.
Étant donné que toutes les demandes Web HTTP de Silverlight sont effectuées en mode asynchrone par le biais de WebClient et HttpWebRequest, il est important comprendre comment traiter les données lorsque les appels renvoient. Lorsque HttpWebRequest rend son appels asynchrones et elle est terminée, le gestionnaire d'événements terminée n'est pas garantie pour fonctionner sur le thread d'interface utilisateur. Si données ont été extraites et destinées à être affichées dans un élément d'interface utilisateur, l'appel à l'élément de l'interface utilisateur doit être effectué utilisant une technique qui transfère le contrôle vers le thread d'interface utilisateur du thread d'arrière-plan. Cette opération est possible avec le répartiteur ou via la classe SynchronizationContext. Le code suivant montre comment effectuer un appel à l'aide de la thread d'interface utilisateur avec la classe Répartiteur BeginInvoke :
Deployment.Current.Dispatcher.BeginInvoke(() =>
{
MyDataGrid.DataContext = productList;
});
Cet exemple de code est la variable productList (qui a été renseignée à partir des données renvoyées par un appel de service Web) et lui DataContext un élément de l'interface utilisateur. Dans ce cas, un contrôle DataGrid sera désormais lié à la liste des produits. Le répartiteur n'est pas nécessaire, cependant, si l'appel a été effectué via la classe WebClient. Dans ce cas, le code peut simplement défini la liste des produits directement sur DataContext l'élément de l'interface utilisateur.
Pour utiliser la classe SynchronizationContext, une instance de la classe SynchronizationContext doit être créée dans un endroit où le thread d'interface utilisateur est connu pour être disponible. Le constructeur et le gestionnaire d'événements de charge sont bons endroits pour créer l'instance d'un SynchronizationContext. Cet exemple de code affiche le champ _syncContext est initialisé dans le constructeur de classe :
public Page() {
_syncContext = SynchronizationContext.Current;
}
Et ce code indique l'instance de SynchronizationContext à l'aide la méthode Post pour effectuer l'appel à la méthode LoadProducts. Il s'assure que la méthode LoadProducts a accès à la thread d'interface utilisateur :
if (_syncContext != null) {
_syncContext.Post(delegate(object state){ LoadProducts(products); }
,null);
}
Outre être plus facile à utiliser, demandes de WebClient toujours revenir sur le thread d'interface utilisateur. Cela signifie que tous les résultats de demande le service WebClient peuvent être facilement liés aux éléments d'interface utilisateur sans devoir impliquant le Répartiteur (ou, éventuellement, la classe SynchronizationContext au lieu du répartiteur). Pour lire des données Syndication, la classe WebClient est adéquate et va être utilisée pour exemple d'application cette colonne.
Ajouter un flux
Dans l'exemple d'application, lorsque l'utilisateur entre une adresse de flux et clique sur le bouton Ajouter, le code illustré figure 2 exécute. Le code tente tout d'abord créer une URI à partir de l'adresse, utilisez la méthode Uri.TryCreate si possible. Si elle peut créer un URI, l'URI est renvoyé à la variable feedUri local. Sinon, feedUri reste null et le code se ferme.
Figure 2, Ajout d'un flux
private void btnAdd_Click(object sender, RoutedEventArgs e)
{
Uri feedUri;
Uri.TryCreate(txtAddress.Text, UriKind.Absolute, out feedUri);
if (feedUri == null)
return;
LoadFeed(feedUri);
}
public void LoadFeed(Uri feedUri)
{
WebClient request = new WebClient();
request.DownloadStringCompleted += AddFeedCompleted;
request.DownloadStringAsync(feedUri);
}
Lorsqu'un URI valide est créé, la méthode LoadFeed s'exécute, effectuer la requête HTTP pour rassembler les données de flux à l'aide de la classe WebClient. L'instance du service WebClient est créée, et un gestionnaire d'événements est attribuée à l'événement DownloadStringCompleted. Lorsque la méthode DownloadStringAsync est exécutée et est prête à renvoyer ses données, il doit savoir quel gestionnaire d'événements pour atteindre. C'est pourquoi le gestionnaire d'événements (dans ce cas, AddFeedCompleted) doit être affecté avant l'événement asynchrone est exécuté.
Une fois la requête terminée, le gestionnaire d'événements AddFeedCompleted exécutera (voir figure 3 ). Le paramètre DownloadStringCompletedEventArgs contient une propriété Result et une propriété erreur, les deux sont importants pour vérifier après chaque demande Web. La propriété e.Error sera null si aucun erreurs se sont produites lors la demande. La propriété e.Result contient les résultats de la demande Web. Pour l'application exemple, e.Result contient le code XML qui représente les données de flux.
La figure 3 AddFeedCompleted
private void AddFeedCompleted(object sender,
DownloadStringCompletedEventArgs e)
{
if (e.Error != null)
return;
string xml = e.Result;
if (xml.Length == 0)
return;
StringReader stringReader = new StringReader(xml);
XmlReader reader = XmlReader.Create(stringReader);
SyndicationFeed feed = SyndicationFeed.Load(reader);
if (_feeds.Where(f => f.Title.Text == feed.Title.Text).ToList().Count > 0)
return;
_feeds.Add(feed); // This also saves the feeds to isolated storage
ReBindAggregatedItems();
txtAddress.Text = string.Empty;
}
Une fois les données de flux sont collectées, il peut être lu dans la classe System.ServiceModel.SyndicationFeed à l'aide charge méthode de la classe SyndicationFeed. Notez que lors de la récupération de flux de données et il à l'aide d'une manière en lecture seule, utilisant LINQ to XML afin de récupérer le flux et du chargement d'un objet personnalisé peuvent être une meilleure option à SyndicationFeed. SyndicationFeed comporte plusieurs fonctionnalités, mais si elles sont n'est pas utilisé peut ne pas être important de la taille supplémentaire ajoutée à la XAP — SyndicationFeed ajoute 150KB environ à la XAP alors que LINQ to XML ajoute 40KB environ. Avec la puissance supplémentaire SyndicationFeed vous devez également des coûts de taille.
SyndicationFeed est une classe spéciale qui sait comment représenter les données flux (RSS et AtomPub) en tant qu'objet. Il dispose des propriétés qui décrivent le flux, telles que Titre et description, ainsi que d'une propriété d'éléments qui contient un IEnumerable <syndicationitem>. Chaque instance de classe SyndicationItem représente un élément de flux pour le flux. Par exemple, les flux sont représentés par les instances de la classe SyndicationFeed et leurs collections d'éléments contiennent les messages individuels à partir des flux.
Une fois la classe SyndicationFeed est chargée avec le flux et les ses éléments, le code illustré figure 3 vérifie si le même flux a déjà été recueilli. Si tel est le cas, le code se ferme immédiatement. Sinon, le flux est ajouté à la locale ObservableCollection <SyndicationFeed> appelée _feeds. À l'aide de la méthode ReBindAggregatedItems, les éléments de flux de tous les flux chargés sont puis filtrées, triées et liés le contrôle DataGrid inférieur. Depuis que la classe WebClient effectuée la demande Web HTTP, le gestionnaire d'événements AddFeedCompleted auront accès à la thread d'interface utilisateur. C'est pourquoi le code dans la méthode ReBindaggregatedItems pouvez lier les données à l'élément UI de grille de données sans l'aide le répartiteur.
L'analyse de flux
Lorsque la méthode ReBindAggregatedItems s'exécute, les données de flux sont stockées dans une collection d'instances SyndicatedFeed et leurs collections respectives des instances SyndicatedItem. LINQ est idéal pour interroger les données flux car il est présent dans une structure de l'objet. Les données n'a pas doivent être chargé en objets SyndicatedFeed. Au lieu de cela il pourrait ont été conservé dans son format XML natif (en tant que RSS ou AtomPub), et il pourrait ont été analysé utilisant un XmlReader ou LINQ to XML. Toutefois, la classe SyndicatedFeed facilite la gestion et LINQ peut toujours servir pour interroger les données.
L'affichage les éléments de flux pour plusieurs flux requiert que les éléments de flux sont tous mashed ensemble. La requête LINQ affichée dans la figure 4 montre comment récupérer tous les éléments flux (instances SyndicationItem) pour tous les flux (instances SyndicationFeed) et les trier par leur date de publication.
La figure 4 interrogation flux avec LINQ
private void ReBindAggregatedItems()
{
//Read the feed items and bind them to the lower list
var query = from f in _feeds
from i in f.Items
orderby i.PublishDate descending
select new SyndicationItemExtra
{ FeedTitle = f.Title.Text, Item = i };
var items = query.ToList();
feedItemsGridLayout.DataContext = items;
}
Notez dans la figure 4 que la requête renvoie une liste de classes SyndicationItemExtra. La classe SyndicationItemExtra est une classe personnalisée qui comporte propriété FeedTitle de type chaîne et une propriété d'élément de type SyndicationItem. L'application affiche les éléments de flux dans le contrôle DataGrid, et la plupart des données pour ce possible dans la classe SyndicationItem.
Toutefois, étant donné que l'application mashes ensemble d'éléments de plusieurs flux, affichant le titre du flux pour chaque élément de flux facilite Effacer le flux article provient. Le titre pour le flux est accessible à partir de la classe SyndicationItem, pas pour l'application utilise une classe personnalisée appelée SyndicationItemExtra qui stockera la SyndicationItem et le titre du flux.
Les éléments de flux sont puis liés à la feedItemsGridLayout du panneau de grille dans l'application Silverlight. Le panneau de grille contient le contrôle DataGrid ainsi que d'autres éléments d'interface utilisateur (tels que le nombre d'éléments affichés dans un TextBlock) impliqués dans les opérations de liaison de données pour afficher des informations sur les éléments de flux.
Demandes entre domaines pour les flux
Les demandes pour rassembler des flux sont que Web HTTP demande généralement que créer des demandes à un autre domaine Web. Toute demande Web de Silverlight qui communique avec un domaine différent de celui qui héberge l'application Silverlight doit respecte stratégie de domaines du domaine distant. Le schéma dans la figure 5 illustre cette situation.

La figure 5 appel entre domaines pour un flux
Pour plus d'informations sur les stratégies entre domaines, reportez-vous à monSeptembre 2008 les points de données de colonne. Dans cette colonne, j'explique les formats de fichier et comment fonctionnent les stratégies.
Lorsqu'une demande Web HTTP est effectuée sur plusieurs domaines, Silverlight prioritaire la demande en demandant le fichier de stratégie entre domaines à partir du serveur Web distant. Silverlight recherche tout d'abord le fichier clientaccesspolicy.xml (le fichier Stratégie de domaines Silverlight), et si elle est introuvable, il recherche le crossdomain.xml (fichier la stratégie de domaines Flash). Si aucun fichier est trouvé, la demande échoue et une erreur est générée. Cette erreur peut être détectée dans le gestionnaire d'événements DownloadStringCompleted et présentée à l'utilisateur, si vous le souhaitez.
Par exemple, si le http://johnpapa URI. NET/feed/default.aspx est entré dans l'exemple d'application, Silverlight tout d'abord recherchera un des fichiers stratégie de domaines sur le johnpapa. NET racine du serveur Web. Si aucun des fichiers sont trouvées, alors une erreur est renvoyée à l'application, à quel moment l'application peut avertit l'utilisateur si vous le souhaitez. la figure 6 illustre le FireBug plug-in, qui est suivi de toutes les demandes à partir du navigateur. Il affiche l'Explorateur recherche les fichiers de stratégie de domaines, pas recherche les et renvoi sans en fait la demande du RSS flux.
.gif)
La figure 6 débogage entre domaines flux appels
FireBug est un excellent outil pour regarder des demandes HTTP dans Firefox et Aide au développement Web est un outil très utile lorsque vous utilisez Internet Explorer. Une autre option est Fiddler2, qui est une application autonome que vous pouvez visualiser tout le trafic sur votre ordinateur.
Une solution à ce problème consiste à demandez à l'administrateur Web pour le flux de placer un fichier clientaccesspolicy.xml dans racine du serveur. Cela ne peut pas être réaliste, puisque vous probablement ne contrôlez pas le serveur Web distant ni savez-vous qui fait. Une autre option consiste pour voir si le flux utilise un service intermédiaire tel que canaux Yahoo. Par exemple, le principal flux au johnpapa. NET peut être récupérée via Yahoo canaux utilisant le http://pipes.yahooapis.com/pipes/pipe.run?\_id=057559bac7aad6640bc17529f3421db0&\_render=rss URI. La mesure où il est un fichier de stratégie de domaines situé à http://pipes.yahooapis.com/clientaccesspolicy.xml permettant l'accès ouvert, il constitue une alternative bonne.
Une troisième option consiste à utiliser un service tel que Popfly ou FeedBurner pour regrouper les flux, les relais efficacement via un service qui possède également une stratégie de domaines ouverte. Enfin, une quatrième option consisterait à écrire votre propre service Web personnalisé qui rassemble les flux et les transmet ensuite à l'application Silverlight. Utilisant un service comme Popfly ou canaux Yahoo propose les solutions plus simples.
Base stockage isolé
L'exemple d'application permet à un utilisateur ajouter plusieurs flux et afficher tous les éléments pour chacun de ces flux. Si un utilisateur entre des flux 10 et décide que qu'il doit fermer l'application et vient en ultérieure pour les lire, il serait probablement attendre que les flux s'être mémorisés par l'application. Dans le cas contraire, il souhaitez devez entrer l'URI pour chaque flux chaque fois que l'application est ouvert. Étant donné que ces flux est spécifiques à un utilisateur, elles peuvent être stockées sur le serveur certains jeton pour identifier l'utilisateur les entrées ou sur l'ordinateur de l'utilisateur.
Silverlight permet aux données d'être stockés à une zone protégée de l'ordinateur de l'utilisateur à l'aide de l'espace de noms System.IO.IsolatedStorage des classes. Le stockage isolé Silverlight est comme les cookies sur stéroïdes : elle permet stocker des valeurs scalaires simples ou même stocker graphiques d'objet complexes avec numéro de série sur l'ordinateur client. Pour enregistrer dans le stockage isolé, la plus simple consiste à créer une entrée ApplicationSettings et remplir vos données, comme illustré ici :
private void SaveFeedsToStorage_UsingSettings()
{
string data = GetFeedsFromStorage_UsingSettings() + FEED_DELIMITER +
txtAddress.Text;
if (IsolatedStorageSettings.ApplicationSettings.Contains(FEED_DATA))
IsolatedStorageSettings.ApplicationSettings[FEED_DATA] = data;
else
IsolatedStorageSettings.ApplicationSettings.Add(FEED_DATA, data);
}
<syndicationfeed>Cela peut être appelée chaque fois qu'un SyndicationFeed est ajouté ou supprimé de l'instance de champ ObservableCollection < SyndicationFeed > appelée _feeds. Étant donné que la ObservableCollection expose un événement CollectionChanged, un gestionnaire de vous pouvez affecter à l'événement qui effectue l'enregistrement, comme illustré ici :
_feeds.CollectionChanged += ((sender, e) => {
SaveFeedsToStorage_UsingSettings(); });
Lorsque la méthode SaveFeedsToStorage_UsingSettings est exécutée, elle appelle tout d'abord la méthode GetFeedsFromStorage_UsingSettings, qui extrait les adresses de tous les des flux de stockage isolé et les place dans une seule chaîne délimitée par un caractère spécial.
Lorsque l'application démarre tout d'abord, la méthode LoadFeedsFromStorage_UsingSettings récupère les flux de stockage isolé :
private void LoadFeedsFromStorage_UsingSettings()
{
string data = LoadFeedsFromStorage_UsingSettings();
string[] feedList = data.Split(new string[1] { FEED_DELIMITER },
StringSplitOptions.RemoveEmptyEntries);
foreach (var address in feedList)
LoadFeed(new Uri(address));
}
Le code lit tout d'abord la liste d'adresses URI pour chaque flux de stockage isolé. Ensuite effectue une itération dans les adresses puis il charge chaque personne saut à la fois, à l'aide de la méthode LoadFeed.
Organisé stockage isolé
Cette fonctionnalité permet à l'application de mémoriser les adresses de flux de l'utilisateur et les charge lorsque l'utilisateur exécute l'application. URI adresses de livraison dans une chaîne délimitée sont simple mais ni élégant ni nombreuses. Par exemple, si vous souhaitez stocker plus qu'une seule valeur scalaire, cela obtiendrez complexe à l'aide de cette technique.
Un autre pour stocker les données de stockage isolé consiste à utiliser les classes IsolatedStorageFile et IsolatedStorageFileStream, le permettent de vous stockez des structures de données plus complexes, y compris sérialisé objets, par utilisateur. Les données peuvent même être segmentées dans différents fichiers et dossiers de stockage isolé. Il est idéal pour organiser les données qui seront enregistrées dans le stockage isolé. Par exemple, un dossier peut créé pour toutes les listes statiques des données et un fichier distinct pour chaque liste peut être créé. Donc dans un dossier de stockage isolé, un fichier peut existe des préfixes de nom, une autre pour sexe et un autre pour les États-Unis indique.
L'exemple d'application peut créer un fichier dans le stockage isolé pour contenir la liste d'adresses URI. Les données doivent tout d'abord être sérialisé et puis envoyées dans le fichier dans stockage isolé (comme illustré à la figure 7 ). Tout d'abord, une instance de la classe IsolatedStorageFile pour l'utilisateur actuel est créée à l'aide de la méthode GetUserStoreForApplication. Ensuite un flux de fichier est créé pour l'application peut écrire l'adresse de l'URI. Les données sont ensuite sérialisées et écrites dans l'instance IsolatedStorageFileStream. L'exemple de cette application sérialise une chaîne, mais tout objet sérialisable peut être écrite sur ainsi le stockage isolé.
Enregistrer la figure 7 sérialisés des données à un fichier de stockage isolé
private void SaveFeedsToStorage_UsingFile() {
using (var isoStore = IsolatedStorageFile.GetUserStoreForApplication())
{
List<string> data = GetFeedsFromStorage_UsingFile();
if (data == null)
if (txtAddress.Text.Length == 0)
return;
else
data = new List<string>();
using (var isoStoreFileStream =
new IsolatedStorageFileStream(FEED_FILENAME,
FileMode.Create, isoStore)) {
data.Add(txtAddress.Text);
byte[] bytes = Serialize(data);
isoStoreFileStream.Write(bytes, 0, bytes.Length);
}
}
}
Lecture des données avec numéro de série d'un fichier de stockage isolé est un peu plus complexe que l'exemple précédent. la figure 8 montre que première vous devez obtenir une instance de la classe IsolatedStorageFile pour l'utilisateur et vérifiez si le fichier existe avant de vous lire. Si le fichier existe, le fichier est ouvert pour l'accès en lecture, qui permet de lire les données via un flux de type IsolatedStorageFileStream. Les données sont lire à partir du flux, mettre en place et puis désérialisées afin puissent être utilisée pour charger les flux de syndication.
Lecture de la figure 8 sérialisés données à partir d'un fichier de stockage isolé
private List<string> GetFeedsFromStorage_UsingFile() {
byte[] feedBytes;
var ms = new MemoryStream();
using (var isoStore =
solatedStorageFile.GetUserStoreForApplication())
{
if (!isoStore.FileExists(FEED_FILENAME)) return null;
using (var stream = isoStore.OpenFile(FEED_FILENAME,
FileMode.Open, FileAccess.Read)) {
while (true) {
byte[] tempBytes = new byte[1024];
int read = stream.Read(tempBytes, 0, tempBytes.Length);
if (read <= 0) {
//feedBytes = ms.ToArray();
break;
}
ms.Write(tempBytes, 0, read);
}
}
feedBytes = ms.ToArray();
List<string> feedList = Deserialize(typeof(List<string>),
feedBytes) as List<string>;
return feedList;
}
}
private void LoadFeedsFromStorage_UsingFile() {
var feedList = GetFeedsFromStorage_UsingFile();
foreach (var address in feedList) {
Uri feedUri;
Uri.TryCreate(address, UriKind.Absolute, out feedUri);
if (feedUri != null)
LoadFeed(feedUri);
}
}
De structures de données plus simples, à l'aide sérialisé objets et fichiers de stockage isolé ne peuvent pas être nécessaires.Toutefois, lorsque stockage isolé est utilisé pour plusieurs types de stockage local, il permet d'organiser les données et facilitent l'accès pour lire et écrire dessus.Stockage isolé doit servir intelligemment pour stocker les données doivent être mis en cache localement.
Notez également que les utilisateurs peuvent, au final, désactiver le stockage à tout moment car ils ont un contrôle total sur leurs paramètres.Cela signifie que les données stockées dans le stockage isolé ne doivent pas être considérées comme garantie stockage persistant.Un autre bon exemple est stocker une liste des États-Unisindique dans le stockage isolé donc un site Web demande (et des accès de base de données) ne doit pas être effectuées chaque fois qu'une zone de liste modifiable doit être rempli avec une liste des États-Unisindique.
Wrap-Up
L'application exemple présente combien il est facile à charger le flux RSS et AtomPub dans une application Silverlight.Silverlight permet de définir une Web demander, accepter ses résultats, gérer les appels de stratégie de domaines, charger des flux de données dans SyndicationFeed classes, les requêtes avec LINQ, liez-les aux éléments d'interface utilisateur et stocker les flux de données de stockage isolé.
Mois dernier et ce mois-ci, Hanu Kommalapati couvert Création d'une application métier d'avec Silverlight, vous pouvez consulter dans ses articles »Silverlight : créer une ligne de Business Enterprise Applications avec Silverlight, partie 1« et »Silverlight : créer une ligne de Business Enterprise Applications avec Silverlight, partie 2."
Envoyez vos questions et commentaires à John àmmdata@microsoft.com.
John Papa(johnpapa.NET) est consultant senior avecASPSOFTet un ventilateur base-ball qui passe nuits d'été supporter les Yankees avec sa famille.Jean, un MVP C# et les haut-parleurs INETA, a créé plusieurs livres et travaille désormais sur ses dernières intitulé Data-Driven Services with Silverlight 2.Il parle souvent à des conférences telles que DevConnections et VSLive.