Cet article a fait l'objet d'une traduction automatique.
Fondations
Erreur de traitement de flux de travail
Matt Milner
Téléchargement de code disponible de la bibliothèque de code MSDN
Parcourir le code en ligne
Contenu
Gestion des erreurs dans les flux de travail
Gestion des erreurs dans le processus hôte
Gestion des erreurs dans les activités personnalisées
À l'aide de compensation
Réessayer d'activité
Windows Workflow Foundation (WF) fournit les outils pour définir processus métier riche et un environnement d'exécution pour exécuter et gérer ces processus. Dans n'importe quel processus métier, exceptions au flux attendue de l'exécution se produisent et les développeurs doivent pouvoir écrire la logique d'application robuste récupérer à partir de ces exceptions. La plupart des exemples de n'importe quelle technologie ont tendance à ignorer la gestion des pannes et la récupération appropriée. Dans article de ce mois-ci, j'explique comment gérer les exceptions correctement à plusieurs niveaux du modèle de programmation du Pare-feu Windows et comment générer des capacités de gestion des exception enrichie dans votre flux de travail et les hôtes.
Gestion des erreurs dans les flux de travail
Les développeurs qui créent des processus d'entreprise doivent pouvoir gérer les exceptions à l'étude de cas pour vous assurer que le processus lui-même est réactifs et peuvent continuer après que la défaillance se produit. Ceci est particulièrement important avec les flux de travail, comme ils définissent souvent processus durables et une erreur non gérée, dans la plupart des cas, signifie avoir à redémarrer le processus. Le comportement par défaut d'un flux de travail est que si une exception se produit dans le flux de travail et n'est pas gérée, le flux de travail va être arrêté. Par conséquent, il est essentiel pour les développeurs du flux de travail d'étendue travail correctement, gérer les erreurs et créer dans les flux de travail la possibilité de nouvelle tentative de travail lorsque défaillances se produisent.
Gestion des erreurs dans les flux de travail a plusieurs choses en commun avec gestion des erreurs dans le code ciblé .NET Framework de Microsoft et quelques nouveaux concepts. Pour gérer une erreur, la première étape consiste à définir une étendue de l'exécution. Dans le code .NET, cela avec le mot-clé essayez. Dans les flux de travail, la plupart des activités composites utilisable pour créer une exception gestion étendue. Chaque activité composite a l'affichage principal indiquant l'enfant activités et dispose également d'autres affichages. Dans la figure 1 le menu contextuel sur une activité Sequence affiche comment différents affichages sont accessibles et le résultat de sélectionner l'option de gestionnaires d'erreur afficher.
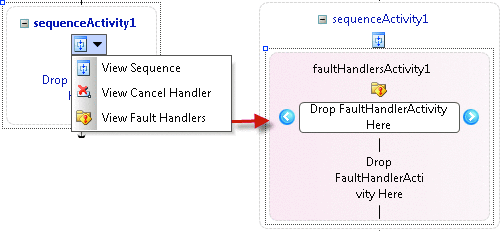
Figure 1 alternative menu Affichage et gestionnaires d'erreur SelectingView
Lorsque vous passez à l'affichage des gestionnaires d'erreur, une activité FaultHandlers est ajoutée à la collection d'activités de l'activité Sequence. De l'activité FaultHandlers, activités FaultHandler individuelles peuvent être ajoutées. Chaque les activités FaultHandler possède une propriété pour définir le type de panne et agit comme une expression catch dans .NET.
L'activité FaultHandler est une activité composite qui permet aux développeurs flux de travail d'ajouter des activités enfant qui définissent comment traiter l'exception. Ces activités peuvent fournissent les fonctionnalités pour ouvrir une session d'erreurs, les administrateurs de contacts ou les autres actions que vous souhaitez normalement effectuer lors du traitement des exceptions dans votre code.
L'activité FaultHandler a également une propriété d'erreur qui contient l'exception est interceptée. Activités enfants peuvent lier à cette propriété pour accéder à l'exception. Ce est illustré dans la figure 2 , où une activité de journalisation personnalisée a sa propriété exception lié à la propriété erreur sur l'activité FaultHandler. L'activité de journalisation peux maintenant écrire les informations d'exception à un enregistrement API, le journal des événements Windows, WMI (Windows Management Instrumentation) ou toute autre destination.
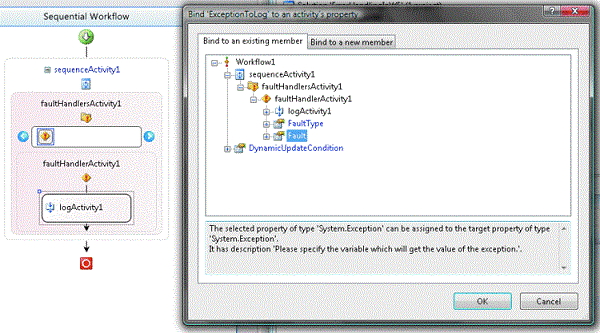
La figure 2 de la liaison à des erreurs
Comme catch blocs, les activités FaultHandler sont évaluées basés sur leurs types de pannes. Lors de la définition du flux de travail, les activités FaultHandler à ajouter au FaultHandlers dans l'ordre de la panne plus spécifique à la moins spécifique, de gauche à droite.
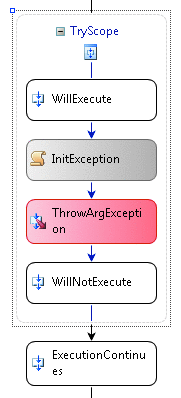
La figure 3 l'exécution continue après le composite
Lorsqu'une exception se produit et est prises dans le code .NET, une fois le bloc catch terminée l'exécution se poursuit après l'étendue de try. Donc dans un flux de travail, l'exécution continue à l'activité suivante après l'activité composite qui gère l'exception (voir figure 3 ).
Il existe deux concepts clés sur comment les activités FaultHandler sont évaluées et exécutées. Lorsque l'activité de jeter exécute (comme dans la figure 3 ) ou une autre activité lève une exception, le runtime place l'activité dans l'état faulted et planifie la méthode HandleFault de l'activité à exécuter. Je passe en plus de détails sur comment activités implémenter cette méthode peu, mais pour maintenant qu'il est suffisante pour savoir que cela est la possibilité de l'activité nettoyer.
Lorsque l'activité de fin de nettoyage et revient à l'état fermé, l'activité parent est placée dans l'état défaillant et porte même l'occasion de nettoyer des activités enfant et signaler qu'il est prêt à déplacer vers l'état fermé. Il est à ce stade, quand l'activité composite signale qu'il est prêt à passer à l'état fermé, que le runtime vérifie l'état et, lorsqu'it is défaillant, examine la collection FaultHandlers. Si une activité FaultHandler est détectée avec des erreurs de type qui correspond à l'exception en cours, qui FaultHandler est planifiée et l'évaluation est interrompue. Une fois le FaultHandler se ferme, l'exécution peut puis continuer à l'activité suivante.
Lorsqu'une exception se produit, le runtime tente de trouver les activités de gestion des pannes de l'activité composite parent immédiat. Si aucun gestionnaires correspondants ne sont trouvées, cette épreuve est défectueuses et l'exception bubbles vers l'activité composite suivante dans l'arborescence de la. Ceci est similaire à la exceptions .NET bulles haut de la pile pour les méthodes d'appel lorsqu'ils sont non prise en charge. Si l'exception bubbles tout à la racine des activités de flux de travail et aucun gestionnaire sont trouvée, puis le flux de travail est terminé.
Notez que le flux de travail lui-même est une activité composite et, par conséquent, peut avoir logique de gestion des pannes définie pour gérer les exceptions qui atteignent le niveau supérieur. C'est le dernier risque pour un développeur de flux de travail à intercepter et de gérer les exceptions dans le processus métier.
Gestion des erreurs dans le processus hôte
Création de workflows robustes est important, avoir un ordinateur hôte peut traiter des exceptions est également important pour la stabilité de votre application. Heureusement, le runtime de workflow est robuste de gestion des ces exceptions de la zone et protège le processus ordinateur hôte depuis la plupart des exceptions phénomène de propagation des.
Lorsqu'une exception se produit dans un flux de travail, les bulles dans la hiérarchie et est uncaught, le flux de travail va se terminer et un événement est déclenché sur le runtime. Le ordinateur hôte du runtime peut enregistrer un gestionnaire pour être notifiées lorsque ces exceptions se produisent, mais les exceptions ne provoquent pas l'ordinateur hôte blocage. Pour être notifiées sur ces arrêts de, le processus ordinateur hôte peut utiliser un code comme suit pour obtenir des informations sur l'exception des arguments d'événement :
workflowRuntime.WorkflowTerminated += delegate(
object sender, WorkflowTerminatedEventArgs e)
{
Console.WriteLine(e.Exception.Message);
};
Outre préoccuper des flux de travail terminé, le processus ordinateur hôte a la possibilité d'être notifié sur les exceptions qui se produisent dans services de runtime. Par exemple, si SqlWorkflowPersistenceService est chargé dans l'exécution, il s'interroger la base de données et peut essayer de charger des flux de travail régulièrement lorsque qu'ils ont plus de travail à faire. Lorsque vous tentez de charger un flux de travail, le service de persistance peut lever une exception lorsque vous tentez de désérialiser le flux de travail, par exemple. Dans ce cas, il est important que le processus ordinateur hôte pas échouer, c'est pourquoi ces services n'est pas rethrow ces exceptions à nouveau. Au lieu de cela, ils déclencher un événement au runtime de workflow. Le runtime génère à son tour un événement ServicesExceptionNotHandled qui peut être traité dans le code, comme illustré ici :
workflowRuntime.ServicesExceptionNotHandled += delegate(
object sender, ServicesExceptionNotHandledEventArgs snhe)
{
Console.WriteLine(snhe.Exception.Message);
};
En règle générale, les développeurs de services d'exécution doivent effectuer un choix lorsque interception une exception indiquant si l'exception est critique. Dans SqlWorkflowPersistenceService, l'impossibilité charger un workflow simple ne signifie pas que le service ne peut pas fonctionner. Par conséquent, il est judicieux dans ce cas pour simplement déclencher un événement pour permettre le processus ordinateur hôte afin de déterminer si plus action est nécessaire. Toutefois, si le service de persistance ne peut pas vous connecter à la base de données SQL Server, puis il ne peut pas fonctionner du tout. Dans ce cas, plutôt que déclencher un événement, il est plus judicieux pour que le service lève une exception et renvoyer le ordinateur hôte arrêter que le problème peut soient résolu.
Lorsque vous développez services de runtime personnalisé, l'approche recommandée consiste pour que ces services dérivés de la classe de base WorkflowRuntimeService. Cette classe de base fournit que deux accès à l'exécution et une méthode protégée pour déclencher un événement ServicesExceptionNotHandled. Lorsqu'une exception se produit dans l'exécution d'un service d'exécution, le service doit uniquement cette exception générée s'il est réellement une erreur irrécupérable. Si l'erreur est liée à une instance de workflow simple et pas l'exécution générale du service, puis un événement devrait être déclenché à la place.
Gestion des erreurs dans les activités personnalisées
Pour les auteurs activité, la gestion des exceptions prend une signification légèrement différente. L'objectif avec exception gestion dans les activités est double : gérer les exceptions qui se produisent pour conserver les, dans la mesure du possible, de remontée des et interrompre le flux de travail et nettoyer correctement dans les cas où une exception non gérée bubbles hors de l'activité.
Comme une activité est simplement une classe, gestion des exceptions de l'activité sont non différent dans aucune autre classe. Vous utilisez try/catch blocs lors appeler d'autres composants qui peut lever des erreurs. Toutefois, une fois que vous intercepter une exception dans une activité, vous devez décider de rethrow l'exception. Si l'exception est quelque chose qui n'affecte pas le résultat de l'activité ou votre activité a une plus contrôlée moyen d'indiquant que n'a pas réussi, ce est préférable pour que commentaires. Si, toutefois, l'exception signifie que votre activité a échoué et ne peut pas terminer son traitement ou fournir une indication de l'échec, puis vous devez lever une exception, le développeur du flux de travail pouvez créer le processus métier pour traiter l'exception.
L'autre élément de gestion des exceptions dans les activités est affaire à nettoyage des ressources d'activité. Contrairement à dans un flux de travail, où Gestion des pannes se concentre sur les processus métier, la journalisation et notification, gestion des erreurs dans les activités sont principalement axé sur nettoyage les ressources utilisées dans l'exécution d'activité.
La gestion des erreurs de façon également dépend si vous écrivez une activité de feuille ou une activité composite. Dans une activité feuille, la méthode HandleFault est appelée lorsqu'une exception non gérée interceptée par le runtime afin de permettre l'activité libérer les ressources qui peuvent être en cours d'utilisation et nettoyer toute exécution qui a commencé. Par exemple, si l'activité utilise une base de données lors de l'exécution, dans la méthode HandleFault il Assurez-vous fermer la connexion si elle n'est pas déjà fermée et céder les autres ressources qui peuvent être en cours d'utilisation. Si l'activité a commencé tout travail asynchrone, ce serait le temps d'annuler fonctionne et libérer les ressources utilisées pour que le traitement.
Pour une activité composite, lorsque la méthode HandleFault se produit, il est peut-être en raison d'une erreur logique dans l'activité lui-même ou il peut être car une activité enfant a défectueuses. Dans les deux cas, l'objectif en appelant la méthode HandleFault sur une activité composite est pour permettre à l'activité nettoyer ses activités enfant. Ce nettoyage implique assurant que le composite n'est pas demander les activités plus être exécutées et l'annulation de toutes les activités qui sont en cours d'exécution. Heureusement, l'implémentation par défaut de la méthode HandleFault, définie dans la classe de base CompositeActivity, est d'appeler la méthode Cancel de l'activité composite.
L'annulation est un autre mécanisme qui permet d'activités qui ont commencé certains fonctionne de manière asynchrone et attendent actuellement de ce travail à effectuer pour être averti qu'ils doivent Annuler le travail qu'ils ont commencé et nettoyer leurs ressources afin qu'ils peuvent fermer. Une activité seront facturée si une autre activité est générée une erreur, ou dans des circonstances normales si la logique de flux de contrôle de l'activité composite parent décide d'annuler le travail.
Lorsqu'une activité est à annuler, le runtime définit l'état de cette activité à Canceling et appelle la méthode Cancel de l'activité. Par exemple, l'activité Replicator peut démarrer plusieurs itérations d'une activité enfant, un pour chaque élément de données fournies et planifier ces activités pour s'exécuter en parallèle. Il possède également une propriété UntilCondition qui va être évaluée comme chaque activité enfant se ferme. Il est possible et probable, cette évaluation de la UntilCondition provoquent l'activité déterminer que qu'il doit effectuer.
Afin que le Réplicateur fermer, il devez tout d'abord fermer toutes les activités enfant. Puisque chacun de ces activités a déjà été planifiée et est potentiellement en cours d'exécution, l'activité Replicator vérifie la valeur actuelle de la propriété ExecutionStatus et, si elle is exécution, effectue une requête pour que le runtime pour annuler cette activité.
À l'aide de compensation
Gestion des erreurs dans les flux de travail permet aux développeurs traitent des conditions d'exception immédiate. L'utilisation de transactions permet également à portée de travail pour garantir la cohérence. Toutefois, en cours d'exécution longue flux de travail, il est possible que deux unités de travail nécessitent de cohérence, mais ne pouvez pas utiliser une transaction.
Par exemple, une fois que démarre un flux de travail qu'il peut mettre à jour les données dans une application de métier, peut-être ajouter un client dans le système CRM. Ce travail peut même faire partie d'une transaction pour fournir la cohérence entre plusieurs opérations dans le CRM et avec l'état du flux de travail. Met à puis, après attend entrée supplémentaire de votre d'un utilisateur qui peut jours à se produire, le flux de travail jour un système comptable avec les client informations. Il est important que les le système de comptabilité et le système CRM ont des données cohérentes, mais il n'est pas possible d'utiliser une transaction atomique pour ces ressources sur ce un grand intervalle. Ainsi, la question devient, comment faire gérer exceptions survenir lors de la mise à jour le deuxième système pour garantir la cohérence avec les modifications déjà engagées sur le premier système ?
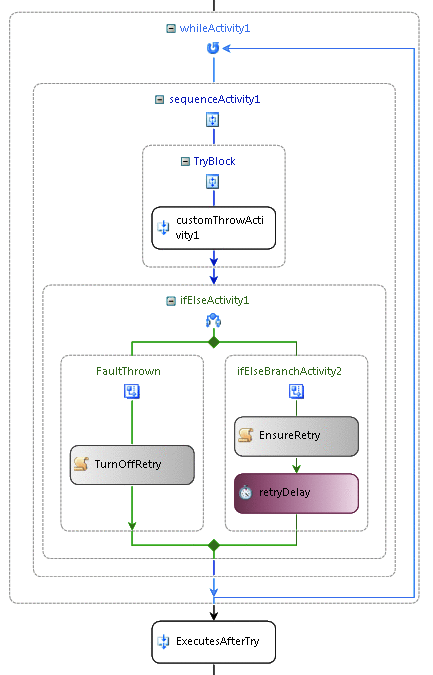
La figure 4 lors de l'activité comme réessayer logique
Car le travail dans les deux systèmes ne peuvent pas cohérent avec une transaction, ce dont vous avez besoin est un mécanisme pour détecter les erreurs qui se produisent lors de la mise à jour le système de deuxième et fournissent une occasion de revenir en arrière et annuler le travail appliqué dans le système initial, ou dans le cas contraire apporter des modifications pour garantir la cohérence. Si la loi de détecter cette modification et de lancer ce processus peut être automatique, le travail de réparation du système initial évidemment doit être spécifiée par le développeur.
Dans WF ce processus est considérée comme compensation et plusieurs activités sont fournies pour aider développez des workflows qui utilisent la compensation. Pour savoir compensation et comment utiliser la compensation activités connexes, consultez colonne pointe Dino Esposito sur flux de travail transactionnel dans le problème de juin 2007 de MSDN Magazine " Flux de travail transactionnel").
Réessayer d'activité
Un des problèmes avec Traitement des exceptions dans les flux de travail est, lorsqu'une exception se produit, même si vous l'intercepter, l'exécution déplace dans à l'étape suivante dans le processus. Dans plusieurs processus d'entreprise, l'exécution vraiment pas continuez jusqu'à ce que la logique métier définie dans les flux de travail s'exécute correctement. Les développeurs souvent traitent cela en utilisant un lors activité pour fournir logique de nouvelle tentative et définir la condition de l'activité pour indiquer que l'activité doit continuer à exécuter comme une erreur s'est produite. En outre, une activité de retard est souvent utilisée pour empêcher la logique de nouvelle tentative de se produit immédiatement.
Pour activer ce modèle de nouvelle tentative, vous pouvez employer une activité Sequence comme l'enfant d'un lors activité. En outre, une unité de travail de la séquence spécifique est généralement encapsulée dans une autre activité séquence ou composite pour gérer les exceptions, agissant en tant que l'étendue de gestion des pannes avec tous les gestionnaires panne définis dans les gestionnaires d'erreur afficher. Une activité IfElse est généralement utilisée pour modifier l'état du flux de travail pour influencer la condition de la lors activité.
Dans le cas où aucune exception se produit, la logique définit une propriété ou indicateur de certains tri ainsi la lors activité pouvez fermer. Si une exception se produire, puis l'indicateur est défini pour que le temps activité à exécuter à nouveau et une activité de retard est utilisée pour suspendre avant d'effectuer la tentative suivante. figure 4 illustre un exemple d'utilisation de la lors activité pour réessayer d'activités dans un flux de travail.
Si ce modèle spécifique fonctionne dans de nombreux scénarios, imaginez un flux de travail 5 ou 10 différentes opérations qui doivent être retentée. Vous réalisez rapidement qu'il est beaucoup de travail pour créer la logique de nouvelle tentative pour chaque activité. Heureusement, WF permet aux développeurs de écrire des activités personnalisées, notamment les activités composites personnalisées. Cela signifie que je peux écrire mon propre activité Réessayer pour encapsuler les exécuter à nouveau les activités enfant lorsqu'une exception se produit. Pour que cela est utile, je souhaite fournir deux entrées clées pour les utilisateurs : un intervalle de délai entre tentatives et un nombre maximal de tentatives du travail avant de laisser la bulle exception haut et être traitée.
Dans le reste de cette chronique, je détaille la logique de l'activité de nouvelle tentative. Pour en arrière-plan d'informations sur la création d'activités personnalisées, voir mon article précédent " Windows Workflow : créer des activités personnalisées pour étendre la communication de votre flux de travail» et pour plus d'informations sur l'utilisation de la ActivityExecutionContext pour créer des activités qui peuvent effectuer une itération sur une activité enfant, consultez l'article de juin 2007 de cette (colonne » ActivityExecutionContext dans les flux de travail").
Pour gérer correctement l'activité enfant, il est important d'être en mesure d'analyser l'activité de savoir lorsque des erreurs se produisent. Par conséquent, lors de l'exécution de l'activité enfant, l'activité de nouvelle tentative enregistre non seulement pour être notifiées lorsque l'activité enfant se ferme, mais il enregistre également pour être notifiées de l'activité enfant est placée dans un état Faulting. figure 5 illustre la méthode BeginIteration utilisée pour démarrer chaque itération de l'activité enfant. Avant de planifier l'activité, les événements fermé et Faulting ont des gestionnaires enregistrés.
Figure 5 Exécution des activités enfant et enregistrement des erreurs
Activity child = EnabledActivities[0];
ActivityExecutionContext newContext =
executionContext.ExecutionContextManager.CreateExecutionContext(child);
newContext.Activity.Closed +=
new
EventHandler<ActivityExecutionStatusChangedEventArgs>(child_Closed);
newContext.Activity.Faulting +=
new
EventHandler<ActivityExecutionStatusChangedEventArgs>(Activity_Faulting);
newContext.ExecuteActivity(newContext.Activity);
Normalement si une erreurs activité enfant, l'activité parent est également être placée dans l'état défaillant. Afin d'éviter cette situation, lorsque les pannes d'activités enfant, l'activité de nouvelle tentative vérifie pour voir si l'activité a déjà été retentée le nombre maximal de fois. Si le nombre de nouvelles tentatives a été atteint, ce Null code sortie l'exception en cours de l'activité enfant, supprimant ainsi l'exception :
void Activity_Faulting(object sender,
ActivityExecutionStatusChangedEventArgs e)
{
e.Activity.Faulting -= Activity_Faulting;
if(CurrentRetryAttempt < RetryCount)
e.Activity.SetValue(
ActivityExecutionContext.CurrentExceptionProperty, null);
}
Lorsque l'activité enfant se ferme, la logique doit déterminer comment l'activité avez obtenu à l'état fermé et utilise la propriété ExecutionResult pour ce faire. Étant donné que toutes les activités de fin dans l'état fermé, le ExecutionStatus ne fournit pas les informations nécessaires pour déterminer le résultat réel, mais le ExecutionResult indique si l'activité défectueuses, a réussi ou a été annulée. Si l'activité enfant réussie, puis aucune tentative n'est nécessaire et l'activité de nouvelle tentative ferme simplement :
if (e.ExecutionResult == ActivityExecutionResult.Succeeded)
{
this.SetValue(ActivityExecutionContext.CurrentExceptionProperty, null);
thisContext.CloseActivity();
return;
}
Si le résultat de l'activité de fermeture n'est pas réussite, et le nombre de nouvelles tentatives n'a pas été atteint, puis l'activité doit être exécutée à nouveau, mais pas avant la nouvelle tentative intervalle a expiré. Dans figure 6 , au lieu de début autre itération directement, un abonnement de minuteur est créé à l'aide de l'intervalle configuré sur l'activité.
La figure 6 Création d'un abonnement du minuteur
if (CurrentRetryAttempt++ < RetryCount &&
this.ExecutionStatus == ActivityExecutionStatus.Executing) {
this.SetValue(ActivityExecutionContext.CurrentExceptionProperty, null);
DateTime expires = DateTime.UtcNow.Add(RetryInterval);
SubscriptionID = Guid.NewGuid();
WorkflowQueuingService qSvc =
thisContext.GetService<WorkflowQueuingService>();
WorkflowQueue q = qSvc.CreateWorkflowQueue(SubscriptionID, false);
q.QueueItemAvailable += new EventHandler<QueueEventArgs>(TimerExpired);
TimerEventSubscription subscription = new TimerEventSubscription(
SubscriptionID, WorkflowInstanceId, expires);
TimerEventSubscriptionCollection timers =
GetTimerSubscriptionCollection();
timers.Add(subscription);
return;
}
Lorsque le timer expire, la méthode TimerExpired est invoquée, comme illustré ici :
void TimerExpired(object sender, QueueEventArgs e)
{
ActivityExecutionContext ctx =
sender as ActivityExecutionContext;
CleanupSubscription(ctx);
BeginIteration(ctx);
}
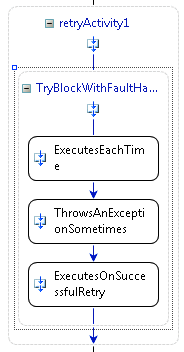
La figure 7 l'activité réessayer dans un flux de travail
Il commence l'itération suivante de l'activité enfant. En l'utilisation de la classe TimerEventSubscription et en ajoutant le minuteur à du minuteur collection le flux de travail, l'activité est en mesure de prendre part correctement à la persistance et la reprise avec le service de persistance est actuellement configuré dans le service d'exécution. Si l'intervalle de nouvelle tentative est longue, le flux de travail entière peut provenir de mémoire jusqu'à ce que la minuterie arrive à expiration.
Le comportement de l'activité de flux de travail de la touche a été atteinte à ce stade. Si une erreurs activité enfant, l'activité de nouvelle tentative ne va pas panne. Au lieu de cela qu'il s'interrompre pour l'intervalle de nouvelle tentative, puis tentez réexécuter l'activité enfant.
L'étape finale consiste à traiter le cas où l'activité a atteint le nombre de nouvelles tentatives et l'activité enfant a continué à échouer. Dans ce cas, la méthode Activity_Faulting n'efface pas l'exception de l'activité enfant, que l'objectif est pour permettre cette défaillance activité comme d'habitude. Et lorsque l'activité enfant se ferme, l'activité de nouvelle tentative ferme également.
Lors de la ferme de nouvelle tentative après tout recommencer tentatives ont échoué, le résultat est le même comme si le travail d'origine a échoué dans une séquence. L'activité de nouvelle tentative peut avoir FaultHandler activités définies et les gestionnaires d'erreur sont exécuter uniquement après que toutes les tentatives ont été exécutées. À l'aide de ce modèle simplifie le développement de flux de travail par des actions devant peuvent être retentée maintient encore l'expérience de développement même aux développeurs de flux de travail en matière de gestion des erreurs, comme illustré figure 7 .
En outre, les gestionnaires d'erreur sont exécutés pour l'activité enfant lorsque les tentatives de tentatives ont échoué, donc les développeurs de flux de travail peuvent choisir de traiter les pannes de l'activité. La méthode HandleFault est appelée sur l'activité enfant de chaque échec s'assurer que l'activité a une occasion de nettoyage de chaque itération.
Veuillez envoyer vos questions et commentaires à mmnet30@Microsoft.com.
Matt Milner est membre du personnel technique au Pluralsight, où il travaille sur les technologies de systèmes connectés. Matt est également un consultant indépendant spécialisé dans les technologies Microsoft .NET avec une spécialisation sur Windows Workflow Foundation, BizTalk Server, ASP.NET et Windows Communication Foundation. Matt vit dans Minnesota avec sa femme, Kristen et ses deux fils. Contactez Matt via son blog à pluralsight.com/community/blogs/Matt.