Tolérance de panne et efficacité du stockage sur des clusters Azure Stack HCI et Windows Server
S’applique à : Azure Stack HCI, versions 22H2 et 21H2 ; Windows Server 2022, Windows Server 2019
Cet article décrit les options de résilience disponibles, et présente leurs exigences en matière d’échelle et d’efficacité du stockage, ainsi que les avantages et inconvénients généraux de chacune d’elles.
Vue d’ensemble
Les espaces de stockage direct assurent la tolérance de panne, ou « résilience », de vos données. Leur implémentation est similaire à celle de la technologie RAID, à la différence près qu’ils sont distribués sur les serveurs et implémentés au niveau logiciel.
Comme pour RAID, il existe plusieurs façons d’utiliser les espaces de stockage pour parvenir à l’objectif fixé, d’où différents compromis entre tolérance de panne, efficacité du stockage et complexité des calculs. L’approche que vous suivez appartient généralement à l’une des deux catégories suivantes : « mise en miroir » et « parité » (parfois appelée « codage d’effacement »).
Mise en miroir
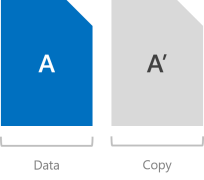
La mise en miroir fournit la tolérance de panne en conservant plusieurs copies de toutes les données. Cette approche s’apparente à RAID-1. La façon dont ces données sont rayées et placées n’est pas triviale (consultez ce blog pour en savoir plus), mais il est absolument vrai de dire que toutes les données stockées à l’aide de la mise en miroir sont écrites, dans son intégralité, plusieurs fois. Chaque copie est écrite sur différents supports physiques (lecteurs différents sur différents serveurs) qui sont supposés échouer de manière indépendante.
Vous avez le choix entre deux types de mise en miroir : « double » et « triple ».
Miroir double
La mise en miroir double écrit deux copies de tout. Son efficacité de stockage est de 50 % : pour écrire 1 To de données, vous devez disposer d’au moins 2 To de capacité de stockage physique. De même, vous devez disposer d’au moins deux « domaines d’erreur » matériels. Avec les espaces de stockage direct, cela signifie deux serveurs.
Avertissement
Si vous avez plus de deux serveurs, nous vous recommandons d’utiliser à la place la mise en miroir triple.
Miroir triple
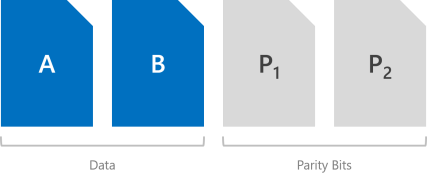
La mise en miroir triple écrit trois copies de tout. Son efficacité de stockage est de 33,3% : pour écrire 1 To de données, vous devez disposer d’au moins 3 To de capacité de stockage physique. De même, vous devez disposer d’au moins trois domaines d’erreur matériels. Avec les espaces de stockage direct, cela signifie trois serveurs.
La mise en miroir triple peut tolérer en toute sécurité au moins deux problèmes matériels (lecteur ou serveur) à la fois. Par exemple, si vous redémarrez un serveur et qu’un autre lecteur ou serveur échoue, toutes les données restent protégées et accessibles en continu.

Parité
L’encodage de parité (souvent appelé « codage d’effacement ») assure la tolérance de panne à l’aide d’opérations arithmétiques au niveau du bit, ce qui peut devenir extrêmement compliqué. Cette solution est plus complexe que la mise en miroir, et de nombreuses ressources en ligne (comme le document Dummies Guide to Erasure Coding) peuvent vous aider à vous en faire une idée plus précise. Il va sans dire qu’elle offre un stockage plus efficace sans compromettre la tolérance de panne.
Les espaces de stockage proposent deux types de parité : la parité « simple » et la parité « double », la seconde employant une technique avancée appelée « codes de reconstruction locale » à plus grande échelle.
Important
Nous vous recommandons d’utiliser la mise en miroir pour la plupart des charges de travail sensibles aux performances. Pour en savoir plus sur la façon d’équilibrer les performances et la capacité en fonction de votre charge de travail, consultez Planifier des volumes.
Parité simple
La parité simple conserve un seul symbole de parité au niveau du bit, ce qui assure la tolérance de panne pour une seule défaillance à la fois. Cette approche s’apparente à RAID-5. Pour utiliser la parité simple, vous devez disposer d’au moins trois domaines d’erreur matériels. Avec les espaces de stockage direct, cela signifie trois serveurs. Étant donné que la mise en miroir triple fournit une plus grande tolérance de panne à la même échelle, nous déconseillons l’utilisation de la parité simple. Mais il est là si vous insistez sur l’utilisation, et il est entièrement pris en charge.
Avertissement
Nous déconseillons l’utilisation de la parité simple car elle ne tolère qu’une défaillance matérielle à la fois : si vous redémarrez un serveur et qu’un autre lecteur ou serveur tombe soudainement en panne, vous subissez un temps d’arrêt. Si vous n’avez que trois serveurs, nous vous recommandons d’utiliser la mise en miroir triple. Si vous en avez quatre ou plus, consultez la section suivante.
Parité double
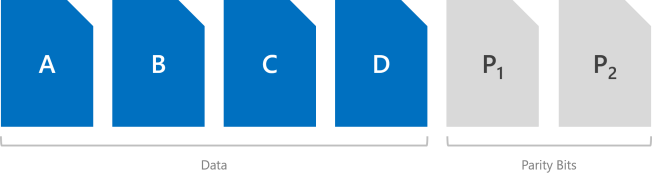
La parité double implémente les codes de correction d’erreur Reed-Solomon pour conserver deux symboles de parité au niveau du bit. Elle offre ainsi la même tolérance de panne que la mise en miroir triple (c’est-à-dire jusqu’à deux défaillances en même temps), mais avec une meilleure efficacité de stockage. Cette approche s’apparente à RAID-6. Pour utiliser la parité double, vous devez disposer d’au moins quatre domaines d’erreur matériels. Avec les espaces de stockage direct, cela signifie quatre serveurs. À cette échelle, l’efficacité du stockage est de 50 % : pour stocker 2 To de données, vous devez disposer de 4 To de capacité de stockage physique.
L’efficacité du stockage de la parité double passe de 50 % à 80 % quand vous augmentez votre nombre de domaines d’erreur matériels. Par exemple, si vous avez sept domaines d’erreur matériels (soit sept serveurs avec les espaces de stockage direct), l’efficacité passe à 66,7 %. Pour stocker 4 To de données, vous n’avez donc besoin que de 6 To de capacité de stockage physique.
Pour connaître l’efficacité de la parité double et des codes de reconstruction locale à chaque échelle, consultez la section Récapitulatif.
Codes de reconstruction locale
Les espaces de stockage introduisent une technique de pointe développée par Microsoft Research appelée « codes de reconstruction locale » (LRC, Local Reconstruction Codes). À grande échelle, la parité double utilise LRC pour fractionner son encodage/décodage en groupes plus petits afin de réduire la surcharge associée aux écritures ou à la récupération après des défaillances.
Avec des lecteurs de disque dur (HDD), la taille des groupes est de quatre symboles. Avec les disques SSD, la taille des groupes est de six symboles. Par exemple, voici à quoi ressemble la disposition avec des lecteurs de disque dur et 12 domaines d’erreur matériels (c’est-à-dire 12 serveurs). Vous avez deux groupes de quatre symboles de données. L’efficacité du stockage est de 72,7 %.

Nous vous recommandons de suivre cette procédure pas-à-pas dans laquelle Claus Joergensen explique en détail, mais de manière très compréhensible, comment les codes de reconstruction locale gèrent différents scénarios de défaillance et pourquoi ils sont intéressants.
Parité avec accélération par miroir
Un volume d’espaces de stockage direct peut utiliser à la fois la mise en miroir et la parité. Les écritures sont dans un premier temps hébergées dans la partie miroir, puis progressivement déplacées dans la partie parité. Il s’agit en fait d’utiliser la mise en miroir pour accélérer le codage d’effacement.
Pour combiner le miroir triple et la parité double, vous devez disposer d’au moins quatre domaines d’erreur (soit quatre serveurs).
L’efficacité du stockage de la parité avec accélération par miroir varie entre ce que vous pouvez tirer d’une utilisation 100 % miroir et d’une utilisation 100 % parité, et dépend des proportions que vous choisissez.
Important
Nous vous recommandons d’utiliser la mise en miroir pour la plupart des charges de travail sensibles aux performances. Pour en savoir plus sur la façon d’équilibrer les performances et la capacité en fonction de votre charge de travail, consultez Planifier des volumes.
Résumé
Cette section récapitule les types de résilience disponibles dans les espaces de stockage direct, l’échelle minimale requise pour chaque type, le nombre de défaillances que chaque type peut tolérer et l’efficacité du stockage correspondante.
Types de résilience
| Résilience | Tolérance de panne | Efficacité du stockage |
|---|---|---|
| Miroir double | 1 | 50,0 % |
| Miroir triple | 2 | 33,3 % |
| Parité double | 2 | 50,0 % - 80,0 % |
| Mixte | 2 | 33,3 % - 80,0 % |
Échelle minimale requise
| Résilience | Nombre minimal de domaines d’erreur requis |
|---|---|
| Miroir double | 2 |
| Miroir triple | 3 |
| Parité double | 4 |
| Mixte | 4 |
Conseil
À moins que vous n’utilisiez la tolérance de panne de châssis ou de racks, le nombre de domaines d’erreur fait référence au nombre de serveurs. Le nombre de lecteurs dans chaque serveur n’affecte pas les types de résilience que vous pouvez utiliser tant que vous respectez les exigences minimales applicables aux espaces de stockage direct.
Efficacité de la parité double pour les déploiements hybrides
Ce tableau montre l’efficacité du stockage de la parité double et des codes de reconstruction locale à chaque échelle pour les déploiements hybrides, qui contiennent à la fois des disques durs (HDD) et des disques SSD ..
| Domaines d’erreur | Disposition | Efficacité |
|---|---|---|
| 2 | – | – |
| 3 | – | – |
| 4 | RS 2+2 | 50,0 % |
| 5 | RS 2+2 | 50,0 % |
| 6 | RS 2+2 | 50,0 % |
| 7 | RS 4+2 | 66,7 % |
| 8 | RS 4+2 | 66,7 % |
| 9 | RS 4+2 | 66,7 % |
| 10 | RS 4+2 | 66,7 % |
| 11 | RS 4+2 | 66,7 % |
| 12 | LRC (8, 2, 1) | 72,7 % |
| 13 | LRC (8, 2, 1) | 72,7 % |
| 14 | LRC (8, 2, 1) | 72,7 % |
| 15 | LRC (8, 2, 1) | 72,7 % |
| 16 | LRC (8, 2, 1) | 72,7 % |
Efficacité de la parité double pour les déploiements 100 % flash
Ce tableau montre l’efficacité du stockage de la parité double et des codes de reconstruction locale à chaque échelle pour les déploiements flashs, qui contiennent uniquement des disques SSD. La disposition de parité peut utiliser des groupes plus volumineux et offrir un stockage plus efficace dans une configuration 100 % flash.
| Domaines d’erreur | Disposition | Efficacité |
|---|---|---|
| 2 | – | – |
| 3 | – | – |
| 4 | RS 2+2 | 50,0 % |
| 5 | RS 2+2 | 50,0 % |
| 6 | RS 2+2 | 50,0 % |
| 7 | RS 4+2 | 66,7 % |
| 8 | RS 4+2 | 66,7 % |
| 9 | RS 6+2 | 75,0 % |
| 10 | RS 6+2 | 75,0 % |
| 11 | RS 6+2 | 75,0 % |
| 12 | RS 6+2 | 75,0 % |
| 13 | RS 6+2 | 75,0 % |
| 14 | RS 6+2 | 75,0 % |
| 15 | RS 6+2 | 75,0 % |
| 16 | LRC (12, 2, 1) | 80,0 % |
Exemples
À moins que vous n’ayez que deux serveurs, nous vous recommandons d’utiliser la mise en miroir triple et/ou la parité double car elles offrent une meilleure tolérance de panne. Plus précisément, ces approches garantissent la sécurité et l’accessibilité de toutes les données en permanence, même en cas de défaillance simultanée des deux domaines d’erreur (soit deux serveurs avec les espaces de stockage direct).
Exemples où tout reste en ligne
Ces six exemples montrent ce que la mise en miroir triple et/ou la parité double peuvent tolérer.
- 1. Perte d’un lecteur (lecteurs de cache inclus)
- 2. Perte d’un serveur
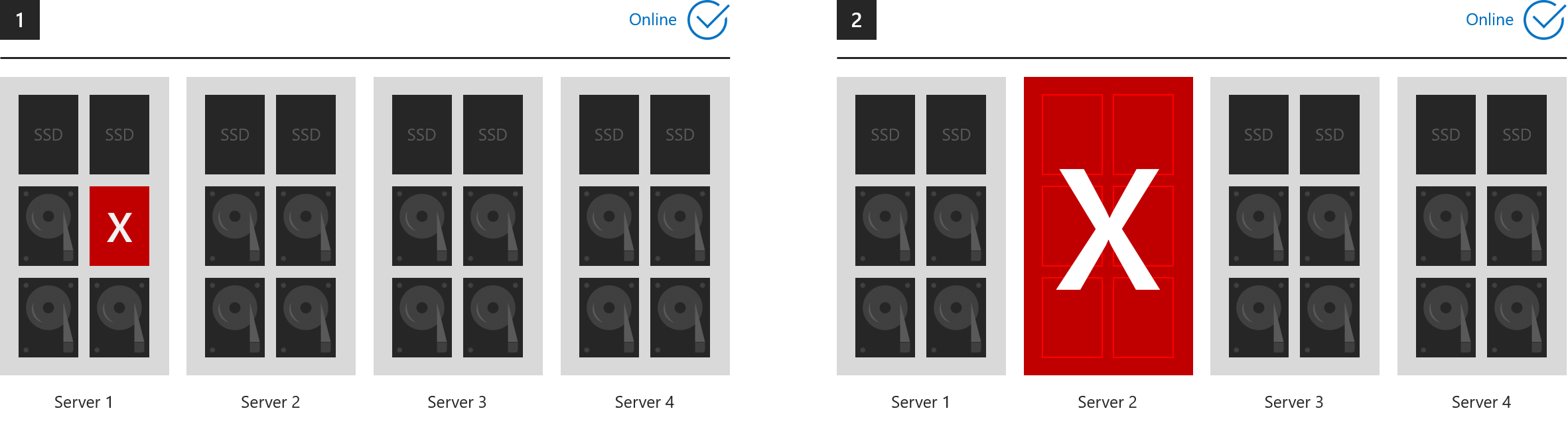
- 3. Perte d’un serveur et d’un lecteur
- 4. Perte de deux lecteurs dans des serveurs différents

- 5. Perte de plus de deux lecteurs, tant que deux serveurs au maximum sont affectés
- 6. Perte de deux serveurs
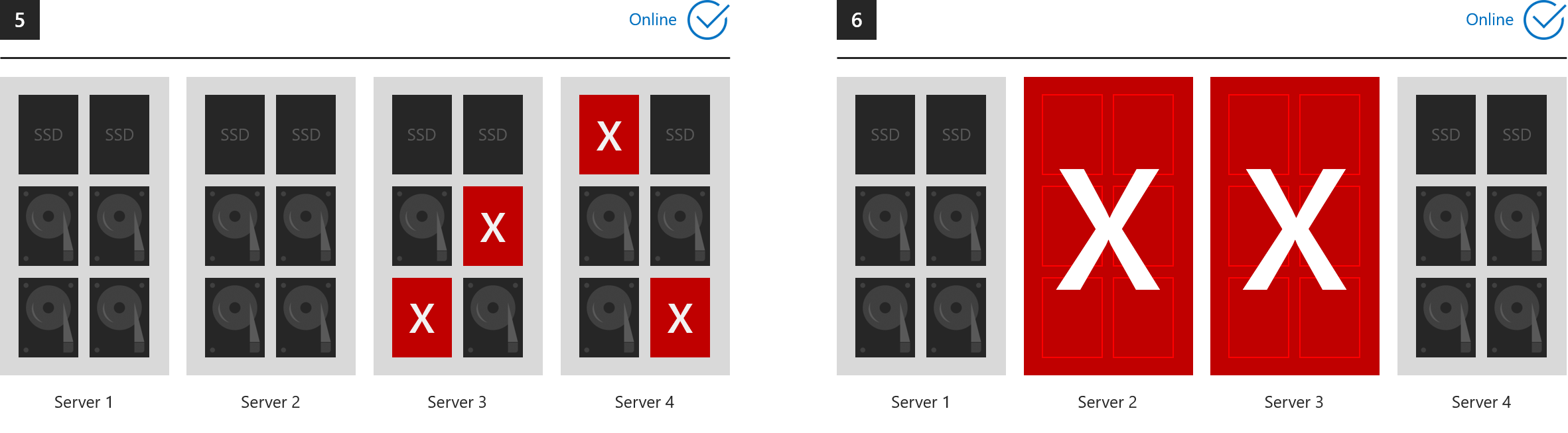
... dans tous les cas, tous les volumes restent en ligne. (Vérifiez que votre cluster conserve le quorum.)
Exemples où tout passe hors connexion
Pendant leur durée de vie, les espaces de stockage peuvent tolérer un nombre illimité de défaillances car ils restaurent une résilience totale après chaque incident, à condition qu’ils en aient le temps. Toutefois, au maximum deux domaines peuvent être affectés par des défaillances à un moment donné. Les exemples suivants montrent ce que la mise en miroir triple et/ou la parité double ne peuvent pas tolérer.
- 7. Perte de lecteurs dans trois serveurs ou plus à la fois
- 8. Perte de trois serveurs ou plus à la fois
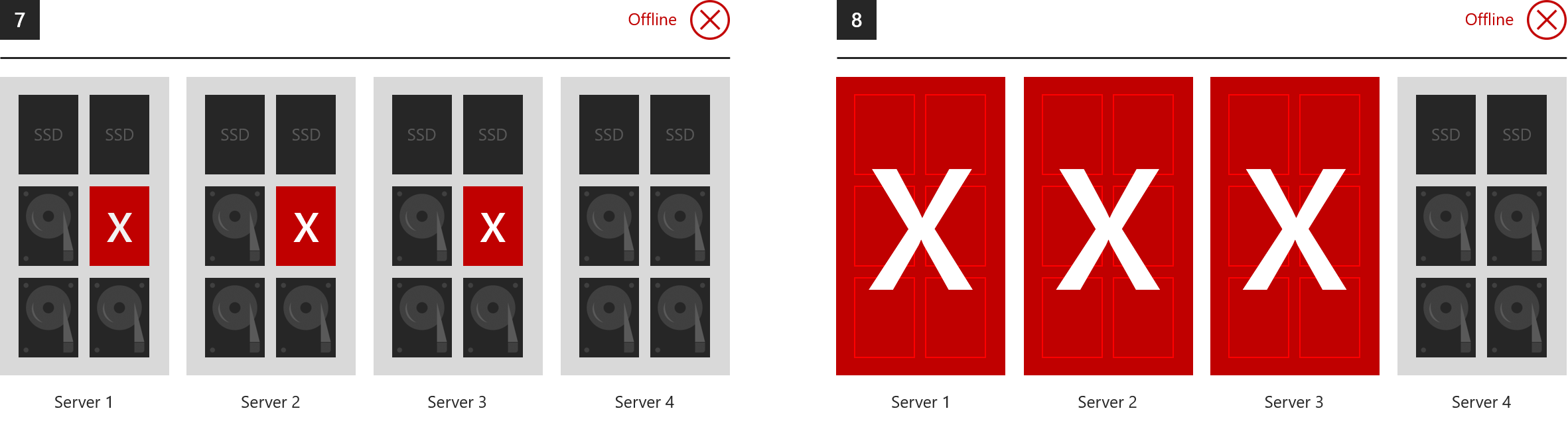
Usage
Consultez Créer des volumes.
Étapes suivantes
Pour plus d’informations sur les sujets mentionnés dans cet article, consultez les pages suivantes :