Utiliser DISKSPD pour tester les performances de stockage d'une charge de travail
S’applique à : Azure Stack HCI, versions 22H2 et 21H2 ; Windows Server 2022, Windows Server 2019
Cette rubrique explique comment utiliser DISKSPD pour tester les performances de stockage d'une charge de travail. Vous disposez d'un cluster Azure Stack HCI configuré et prêt à l'emploi ? Très bien, mais êtes-vous certain de bénéficier des métriques de performances promises en termes de latence, de débit ou d'IOPS ? C'est là que DISKSPD entre en scène. Au terme de cette rubrique, vous saurez exécuter DISKSPD, identifier un sous-ensemble de paramètres, interpréter la sortie, et vous en saurez plus sur les variables qui affectent les performances de stockage d'une charge de travail.
Qu'est-ce que DISKSPD ?
DISKSPD est un outil en ligne de commande de génération d'E/S pour le micro-benchmarking. Mais que signifient tous ces termes ? Toute personne qui configure un serveur physique ou un cluster Azure Stack HCI le fait pour une raison précise. Par exemple pour configurer un environnement d'hébergement web ou pour exécuter des bureaux virtuels pour des employés. Quel que soit le cas d'usage réel, il peut être judicieux de simuler un test avant de déployer l'application. En revanche, il est souvent difficile de tester une application dans un scénario réel ; d'où l'intérêt d'utiliser DISKSPD.
DISKSPD est un outil que vous pouvez personnaliser pour créer vos propres charges de travail synthétiques et tester votre application avant son déploiement. L'avantage de cet outil est qu'il vous permet de configurer et d'ajuster les paramètres pour créer un scénario semblable à votre charge de travail réelle. DISKSPD peut vous donner un aperçu des possibilités de votre système avant son déploiement. Fondamentalement, DISKSPD ne fait qu'émettre une série d'opérations de lecture et d'écriture.
Maintenant que vous avez ce qu'est DISKSPD, quand devez-vous l'utiliser ? DISKSPD a du mal à émuler les charges de travail complexes. Mais DISKSPD est parfait lorsque votre charge de travail n'a rien à voir avec une copie de fichier à thread unique, et que vous recherchez un outil simple produisant des résultats de base acceptables.
Démarrage rapide : installer et exécuter DISKSPD
Suivez les instructions ci-dessous :
À partir de votre PC de gestion, ouvrez PowerShell en tant qu'administrateur pour vous connecter à l'ordinateur de destination que vous souhaitez tester à l'aide de DISKSPD, puis entrez la commande suivante et appuyez sur Entrée.
Enter-PSSession -ComputerName <TARGET_COMPUTER_NAME>Dans cet exemple, nous exécutons une machine virtuelle appelée « node1 ».
Pour télécharger l'outil DISKSPD, entrez les commandes suivantes et appuyez sur Entrée :
$client = new-object System.Net.WebClient$client.DownloadFile("https://github.com/microsoft/diskspd/releases/download/v2.1/DiskSpd.zip","<ENTER_PATH>\DiskSpd-2.1.zip")Utilisez la commande suivante pour décompresser le fichier téléchargé :
Expand-Archive -LiteralPath <ENTERPATH>\DiskSpd-2.1.zip -DestinationPath C:\DISKSPDAccédez au répertoire DISKSPD et recherchez le fichier exécutable correspondant au système d'exploitation Windows exécuté par l'ordinateur de destination.
Dans cet exemple, nous utilisons la version amd64.
Notes
Vous pouvez également télécharger l'outil DISKSPD directement à partir du référentiel GitHub qui contient le code open source et une page wiki détaillant tous les paramètres et spécifications. Dans le référentiel, sous Versions, sélectionnez le lien permettant de télécharger automatiquement le fichier ZIP.
Le fichier ZIP contient trois sous-dossiers : amd64 (systèmes 64 bits), x86 (systèmes 32 bits) et ARM64 (systèmes ARM). Ces options vous permettent d'exécuter l'outil dans chaque version du serveur ou du client Windows.

Exécutez DISKSPD à l'aide de la commande PowerShell suivante. Remplacez les crochets et leur contenu par les paramètres appropriés.
.\[INSERT_DISKSPD_PATH] [INSERT_SET_OF_PARAMETERS] [INSERT_CSV_PATH_FOR_TEST_FILE] > [INSERT_OUTPUT_FILE.txt]Exemple de commande que vous pouvez exécuter :
.\diskspd -t2 -o32 -b4k -r4k -w0 -d120 -Sh -D -L -c5G C:\ClusterStorage\test01\targetfile\IO.dat > test01.txtNotes
Si vous n'avez pas de fichier de test, utilisez le paramètre -c pour en créer un. Si vous utilisez ce paramètre, veillez à inclure le nom du fichier de test lorsque vous définissez votre chemin d'accès. Par exemple : [INSERT_CSV_PATH_FOR_TEST_FILE] = C:\ClusterStorage\CSV01\IO.dat. Dans l'exemple de commande, IO.dat correspond au nom du fichier de test, et test01.txt au nom du fichier de sortie de DISKSPD.

Spécifier les paramètres de clé
Facile, non ? Malheureusement, ça ne s'arrête pas là. Poursuivons. Tout d'abord, certains paramètres peuvent être modifiés. Ici, nous avons utilisé les paramètres de base suivants :
Notes
Les paramètres de DISKSPD respectent la casse.
-t2 : indique le nombre de threads par fichier cible/test. Ce nombre repose souvent sur le nombre de cœurs du processeur. Dans cet exemple, deux threads ont été utilisés pour solliciter tous les cœurs du processeur.
-o32 : indique le nombre de demandes d'E/S en attente par cible et par thread. C'est ce qu'on appelle la profondeur de la file d'attente, et dans cet exemple, 32 demandes ont été utilisées pour solliciter le processeur.
-b4K : indique la taille de bloc en octets, Kio, Mio ou Gio. Dans cet exemple, la taille de bloc 4K a été utilisée pour simuler un test d'E/S aléatoire.
-r4K : indique que les E/S aléatoires sont alignées sur la taille spécifiée en octets, Kio, Mio, Gio ou blocs (remplace le paramètre -s). La taille commune de 4K octets a été utilisée pour l'alignement avec la taille de bloc.
-w0 : spécifie le pourcentage d'opérations correspondant à des demandes d'écriture (-w0 équivaut à 100 % de lectures). Dans cet exemple, 0 % d'écritures ont été utilisées dans le cadre d'un test simple.
-d120 : spécifie la durée du test, sans compter le temps de recharge ou de préchauffage. La valeur par défaut est de 10 secondes, mais nous vous recommandons d'utiliser au moins 60 secondes pour toute charge de travail importante. Dans cet exemple, 120 secondes ont été utilisées pour réduire les valeurs hors norme.
-Suw : désactive la mise en cache en écriture des logiciels et du matériel (équivalent de -Sh).
-D : capture les statistiques IOPS, telles que l'écart type, par intervalles de quelques millisecondes (par thread, par cible).
-L : mesure les statistiques de latence.
-c5g : définit la taille de l'exemple de fichier utilisée dans le cadre du test. Celle-ci peut être définie en octets, en Kio, en Mio, en Gio ou en blocs. Dans cet exemple, un fichier cible de 5 Go a été utilisé.
Pour obtenir la liste complète des paramètres, reportez-vous au référentiel GitHub.
Comprendre l'environnement
Les performances dépendent fortement de votre environnement. Alors, de quel environnement disposons-nous ? Notre spécification implique un cluster Azure Stack HCI avec pool de stockage et espaces de stockage direct (S2D). Plus précisément, il y a cinq machines virtuelles : DC, node1, node2, node3 et le nœud de gestion. Le cluster proprement dit est un cluster à trois nœuds avec une structure de résilience en miroir triple. Par conséquent, trois copies des données sont conservées. Chaque « nœud » du cluster est une machine virtuelle Standard_B2ms avec une limite maximale de 1 920 E/S par seconde. Chaque nœud comporte quatre disques SSD P30 Premium avec une limite maximale de 5 000 E/S par seconde. Enfin, chaque disque SSD dispose de 1 To de mémoire.
Vous générez le fichier de test sous l'espace de noms unifié fourni par le volume partagé de cluster (C:\ClusteredStorage) pour utiliser l'ensemble du pool de disques.
Notes
L'exemple d'environnement ne contient pas de système Hyper-V ou de structure de virtualisation imbriquée.
Comme vous allez le constater, il est tout à fait possible d'atteindre indépendamment le plafond d'IOPS ou de bande passante à la limite de la machine virtuelle ou du disque. Il est donc important d'identifier la taille de la machine virtuelle et le type du disque, car tous deux présentent une limite maximale d'IOPS et un plafond de bande passante. Ces informations permettent de localiser les goulots d'étranglement et d'interpréter les résultats de performances. Pour en savoir plus sur la taille qui convient à votre charge de travail, consultez les ressources suivantes :
Comprendre la sortie
Maintenant que vous comprenez les paramètres et l'environnement, vous êtes prêt à interpréter les résultats. L'objectif du test précédent était d'atteindre le nombre maximum d'IOPS sans tenir compte de la latence. De cette façon, vous pouvez visuellement déterminer si vous atteignez la limite artificielle d'IOPS dans Azure. Si vous souhaitez visualiser sous forme graphique le nombre total d'IOPS, utilisez Windows Admin Center ou le Gestionnaire de tâches.
Le schéma suivant illustre le processus DISKSPD dans notre exemple d'environnement. Il présente un exemple d'opération d'écriture de 1 Mio à partir d'un nœud non coordinateur. La structure de résilience triple, associée à l'opération à partir d'un nœud non coordinateur, mène à deux sauts réseau, ce qui diminue les performances. Si vous vous demandez ce qu'est un nœud coordinateur, ne vous en faites pas, nous y reviendrons à la section Points importants à prendre en compte. Les petits carrés rouges représentent les goulots d'étranglement des machines virtuelles et des disques.

Maintenant que vous visualisez les choses, examinons les quatre principales sections de la sortie du fichier .txt :
Paramètres d’entrée
Cette section décrit la commande que vous avez exécutée, les paramètres d'entrée ainsi que des détails supplémentaires sur la série de tests.

Détails sur l'utilisation des processeurs
Cette section met en évidence des informations telles que la durée du test, le nombre de threads, le nombre de processeurs disponibles et l'utilisation moyenne de chaque cœur de processeur pendant le test. Cet exemple comporte deux cœurs de processeur dont l'utilisation moyenne est d'environ 4,67 %.

Nombre total d'E/S
Cette section comprend trois sous-sections. La première section met en évidence les données de performances globales, opérations de lecture et d'écriture comprises. Les deuxième et troisième sections fractionnent les opérations de lecture et d'écriture en catégories distinctes.
Dans cet exemple, vous pouvez constater qu'un nombre total de 234 408 E/S a été atteint pendant la durée de 120 secondes. Par conséquent, IOPS = 234408 / 120 = 1953,30. La latence moyenne était de 32,763 millisecondes et le débit de 7,63 Mio/s. Sur la base d'informations antérieures, nous savons que les 1953,30 IOPS sont proches de la limite de 1920 IOPS pour notre machine virtuelle Standard_B2ms. Vous n'y croyez pas ? Si vous réexécutez ce test en utilisant des paramètres différents, par exemple en augmentant la profondeur de la file d'attente, vous constaterez que les résultats sont toujours plafonnés à ce nombre.
Les trois dernières colonnes montrent l'écart type d'IOPS à 17,72 (paramètre -D), l'écart type de la latence à 20,994 millisecondes (paramètre -L) et le chemin d'accès au fichier.

Grâce aux résultats, vous pouvez rapidement déterminer que la configuration du cluster est mauvaise. Vous pouvez constater que la limite de 1 920 machines virtuelles a été atteinte avant la limite de 5 000 disques SSD. Si vous aviez été limité par les disques SSD plutôt que par les machines virtuelles, vous auriez pu profiter de 20 000 IOPS (4 disques * 5 000) en appliquant le fichier de test à plusieurs disques.
Au bout du compte, vous devez décider quelles valeurs sont acceptables pour votre charge de travail. L'illustration suivante présente quelques relations importantes pour vous aider à envisager des compromis :
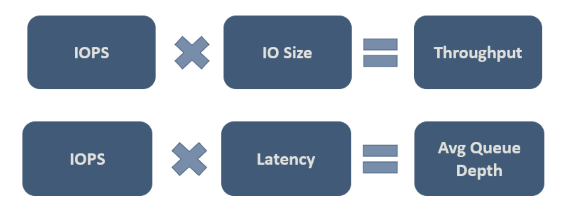
La deuxième relation de la figure, parfois appelée « loi de Little », est particulièrement importante. Cette loi introduit l'idée selon laquelle trois caractéristiques régissent le comportement du processus et démontre qu'il suffit d'en changer une pour influencer les deux autres, et donc l'ensemble du processus. Par conséquent, si vous n'êtes pas satisfait des performances de votre système, vous disposez de trois dimensions de liberté pour agir sur celles-ci. Conformément à la loi de Little, dans notre exemple, les IOPS correspondent au « débit » (opérations d'entrée/sortie par seconde), la latence correspond au « temps d'attente » et la profondeur de la file d'attente correspond à l'« inventaire ».
Analyse du centile de latence
Cette dernière section détaille les latences en centile par type d'opération de performances de stockage, de la valeur minimale à la valeur maximale.
Cette section est importante car elle détermine la « qualité » de vos IOPS. Elle révèle combien d'opérations d'E/S ont pu atteindre une valeur de latence donnée. À vous de déterminer quelle latence est acceptable pour ce centile.
De plus, « nines » fait référence au nombre de neuf. Par exemple, « 3-nines » équivaut au 99e centile. Le nombre de neuf indique le nombre d'opérations d'E/S exécutées à ce centile. Finalement, vous atteindrez un point où les valeurs de latence n'ont plus d'importance. Dans cet exemple, vous pouvez constater que les valeurs de latence restent constantes après « 4-nines ». À ce stade, la valeur de latence repose sur une seule opération d'E/S sur les 234 408.






Points importants à prendre en compte
Maintenant que vous avez commencé à utiliser DISKSPD, différents points sont à prendre en compte pour obtenir des résultats de test dans le monde réel. Vous devez notamment prêter une attention particulière aux paramètres que vous définissez, à l'intégrité et aux variables de l'espace de stockage, à la propriété du volume partagé de cluster et à la différence entre DISKSPD et la copie de fichiers.
DISKSPD et monde réel
Le test artificiel de DISKSPD vous donne des résultats relativement comparables pour votre charge de travail réelle. Cela dit, vous devez être très attentif aux paramètres que vous définissez et vous assurer qu'ils correspondent à votre scénario réel. Sachez que les charges de travail synthétiques ne représenteront jamais parfaitement la charge de travail réelle de votre application pendant le déploiement.
Préparation
Avant de procéder à un test DISKSPD, nous vous recommandons de prendre quelques mesures. Vous devez notamment vérifier l'intégrité de l'espace de stockage, contrôler l'utilisation de vos ressources afin qu'aucun autre programme n'interfère pas avec le test, et préparer le gestionnaire de performances si vous souhaitez collecter des données supplémentaires. Toutefois, l'objectif de cette rubrique étant d'exécuter rapidement DISKSPD, les spécificités de ces mesures n'y sont pas présentées. Pour plus d’informations, consultez Test Storage Spaces Performance Using Synthetic Workloads in Windows Server.
Variables qui affectent les performances
Les performances de stockage constituent un point relativement délicat. Car de nombreuses variables peuvent affecter les performances. Il se peut donc que certaines ne soient pas conformes à vos attentes. Les variables suivantes affectent les performances (liste non exhaustive) :
- Bande passante du réseau
- Choix de résilience
- Configuration du disque de stockage : NVME, SSD, HDD
- Mémoire tampon E/S
- Cache
- Configuration RAID
- Sauts réseau
- Vitesses de rotation du disque dur
Propriété du volume partagé de cluster
Un nœud est considéré comme le propriétaire du volume ou comme le nœud coordinateur (par opposition à un nœud non coordinateur qui correspondrait à un nœud non propriétaire du volume en question). Un nœud est attribué à chaque volume standard et les autres nœuds peuvent accéder à ce volume au moyen de sauts réseau, ce qui entraîne un ralentissement des performances (latence plus élevée).
De même, un volume partagé de cluster (CSV) possède également un « propriétaire ». Cela dit, un volume CSV est « dynamique » en ce sens qu'il changera de propriétaire chaque fois que vous redémarrerez le système (RDP). Il est donc important de vérifier que DISKSPD est exécuté à partir du nœud coordinateur propriétaire du volume CSV. Si ce n'est pas le cas, vous devrez peut-être modifier manuellement la propriété du volume CSV.
Pour vérifier la propriété du volume CSV :
Vérifiez la propriété en exécutant la commande PowerShell suivante :
Get-ClusterSharedVolumeSi la propriété du volume CSV est incorrecte (par exemple, vous êtes sur Node1 alors que le volume CSV appartient à Node2), déplacez le volume CSV vers le nœud qui convient en exécutant la commande PowerShell suivante :
Get-ClusterSharedVolume <INSERT_CSV_NAME> | Move-ClusterSharedVolume <INSERT _NODE_NAME>
Copie de fichiers et DISKSPD
Certaines personnes pensent pouvoir « tester les performances de stockage » en copiant et en collant un fichier extrêmement volumineux et en mesurant la durée de ce processus. Pourquoi cette approche ? Probablement parce qu'elle est simple et rapide. L'idée n'est pas mauvaise dans le sens où elle teste une charge de travail spécifique, mais il est difficile de classer cette méthode dans la catégorie « test des performances de stockage ».
Si votre objectif réel est de tester les performances de copie de fichiers, cette méthode peut tout à fait convenir. En revanche, si votre objectif est de mesurer les performances de stockage, nous vous déconseillons d'y avoir recours. Vous pouvez considérer que le processus de copie de fichiers utilise un ensemble différent de « paramètres » (comme la file d'attente, la parallélisation, etc.) propres aux services de fichiers.
Le bref résumé suivant explique pourquoi l'utilisation de la copie de fichiers pour mesurer les performances de stockage peut ne pas fournir les résultats escomptés :
Les copies de fichiers risquent ne pas être optimisées. Il existe deux niveaux de parallélisme, l'un interne et l'autre externe. En interne, si la copie de fichiers est dirigée vers une cible distante, le moteur CopyFileEx applique une certaine parallélisation. En externe, le moteur CopyFileEx peut être appelé de différentes façons. Par exemple, les copies de l'Explorateur de fichiers sont à thread unique, mais Robocopy est multi-thread. Il est donc important de déterminer si les implications du test correspondent à ce que vous recherchez.
Chaque copie possède deux côtés. Lorsque vous copiez et collez un fichier, vous utilisez peut-être deux disques : le disque source et le disque de destination. Si l'un est plus lent que l'autre, vous mesurez les performances du disque plus lent. Il existe d'autres cas où la communication entre la source, la destination et le moteur de copie peut affecter les performances de manière unique.
Pour en savoir plus, consultez Utiliser la copie de fichiers pour mesurer les performances de stockage.
Expériences et charges de travail courantes
Cette section comprend d'autres exemples, expériences et types de charges de travail.
Vérifier le nœud coordinateur
Comme mentionné précédemment, si la machine virtuelle que vous testez n'est pas propriétaire du volume CSV, vous constaterez une baisse des performances (IOPS, débit et latence) par rapport à un test effectué lorsque le nœud en est propriétaire. En effet, pour chaque opération d'E/S émise, le système effectue un saut réseau jusqu'au nœud coordinateur afin d'exécuter cette opération.
Dans le cas d'un miroir triple et à trois nœuds, les opérations d'écriture effectuent toujours un saut réseau, car les données doivent être stockées sur tous les disques des trois nœuds. Par conséquent, les opérations d'écriture font malgré tout un saut réseau. Mais si vous utilisez une autre structure de résilience, cela peut changer.
Voici un exemple :
- Exécution sur nœud local : .\DiskSpd-2.0.21a\amd64\diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
- Exécution sur nœud non local : .\DiskSpd-2.0.21a\amd64\diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
À partir de cet exemple, vous pouvez clairement voir dans les résultats illustrés ci-dessous que la latence diminue, que les IOPS augmentent et que le débit augmente lorsque le nœud coordinateur est propriétaire du volume CSV.

Charge de travail OLTP
Les requêtes de charge de travail OLTP (traitement transactionnel en ligne), à savoir Update, Insert et Delete, se concentrent sur les tâches orientées transaction. Par rapport au traitement OLAP (traitement analytique en ligne), OLTP dépend de la latence de stockage. Comme chaque opération génère peu d'E/S, ce qui compte, c'est le nombre d'opérations par seconde que vous pouvez prendre en charge.
Vous pouvez concevoir un test de charge de travail OLTP pour vous concentrer sur les performances d'E/S aléatoires et peu volumineuses. Pour ces tests, demandez-vous dans quelle mesure vous pouvez pousser le débit tout en conservant des latences acceptables.
Le choix de la conception de base de ce test de charge de travail doit au minimum inclure ce qui suit :
- Taille de bloc de 8 Ko => taille de page que SQL Server utilise pour ses fichiers de données
- 70 % de lectures, 30 % d’écritures => comportement OLTP classique
Charge de travail OLAP
Les charges de travail OLAP (traitement analytique en ligne) se concentrent sur l'extraction et l'analyse des données, ce qui permet aux utilisateurs d'effectuer des requêtes complexes pour extraire des données multidimensionnelles. Contrairement au traitement OLTP, ces charges de travail ne sont pas sensibles à la latence du stockage. Elles mettent l'accent sur la mise en file d'attente de nombreuses opérations sans trop se soucier de la bande passante. Par conséquent, les charges de travail OLAP entraînent souvent des temps de traitement plus longs.
Vous pouvez concevoir un test de charge de travail OLAP pour vous concentrer sur les performances d'E/S séquentielles et volumineuses. Pour ces tests, concentrez-vous sur le volume de données traitées par seconde plutôt que sur le nombre d'IOPS. Les exigences en matière de latence sont également moins importantes, mais cela reste subjectif.
Le choix de la conception de base de ce test de charge de travail doit au minimum inclure ce qui suit :
Taille de bloc de 512 Ko => taille des E/S quand le serveur SQL charge un lot de 64 pages de données pour une analyse de table avec la technique de lecture anticipée.
1 thread par fichier => actuellement, vous devez limiter vos tests à un seul thread par fichier, car des problèmes peuvent survenir dans DISKSPD en cas de test de plusieurs threads séquentiels. Si vous utilisez plusieurs threads (par exemple, deux) et le paramètre -s, les threads commenceront de manière non déterministe à émettre des opérations d'E/S les unes sur les autres au même emplacement. Cela est dû au fait qu'ils suivent chacun leur propre décalage séquentiel.
Pour résoudre ce problème, deux « solutions » sont possibles :
La première solution consiste à utiliser le paramètre -si. Avec ce paramètre, les deux threads partagent un même décalage imbriqué, de sorte que les threads émettent en coopération un seul modèle séquentiel d'accès au fichier cible. Cela permet d'éviter de traiter plusieurs fois le même point du fichier. Mais comme elles se font encore la course pour émettre leur opération d'E/S dans la file d'attente, les opérations peuvent arriver dans le désordre.
Cette solution fonctionne bien si un thread est limité par le processeur. Vous pouvez aussi engager un deuxième thread sur un deuxième cœur de processeur pour fournir plus d'E/S de stockage au système du processeur et le saturer davantage.
La deuxième solution consiste à utiliser -T<offset>. Celle-ci vous permet de spécifier la taille du décalage (écart inter-E/S) entre les opérations d'E/S exécutées sur le même fichier cible par différents threads. Par exemple, les threads commencent normalement au décalage 0, mais cette spécification vous permet d'espacer les deux threads afin qu'ils ne se chevauchent pas. Dans un environnement multithread, les threads seront probablement sur différentes parties de la cible de travail, et ceci constitue un moyen de simuler cette situation.
Étapes suivantes
Pour plus d'informations et pour accéder à des exemples détaillés sur l'optimisation de vos paramètres de résilience, consultez également :
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour