Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Pour évaluer soigneusement les performances de votre application d’IA générative lorsqu’elle est appliquée à un jeu de données important, vous pouvez lancer un processus d’évaluation. Pendant cette évaluation, votre application est testée avec le jeu de données donné et ses performances seront mesurées quantitativement avec les métriques mathématiques et les métriques assistées par l’IA. Cette exécution d’évaluation vous fournit des insights complets sur les fonctionnalités et limitations de l’application.
Vous pouvez effectuer cette évaluation à l’aide du portail Azure AI Foundry, une plateforme complète qui offre des outils et des fonctionnalités permettant d’évaluer les performances et la sécurité de votre modèle d’IA générative. Dans le portail Azure AI Foundry, vous pouvez journaliser, afficher et analyser des métriques d’évaluation détaillées.
Dans cet article, vous allez apprendre à créer une exécution d’évaluation sur un modèle ou un jeu de données de test avec des métriques d’évaluation intégrées à partir de l’interface utilisateur Azure AI Foundry. Pour une plus grande flexibilité, vous pouvez établir un flux d’évaluation personnalisé et utiliser la fonctionnalité d’évaluation personnalisée. Vous pouvez également utiliser la fonctionnalité d’évaluation personnalisée si votre objectif consiste uniquement à exécuter un lot sans évaluation.
Conditions préalables
Pour exécuter une évaluation avec des métriques assistées par l’IA, vous devez disposer des éléments suivants :
- Jeu de données de test dans l’un de ces formats :
csvoujsonl. - Une connexion Azure OpenAI. Un déploiement de l’un de ces modèles : modèles GPT 3.5, modèles GPT 4 ou modèles Davinci. Obligatoire uniquement lorsque vous exécutez une évaluation de qualité assistée par l’IA.
Créer une évaluation avec des métriques d’évaluation intégrées
Une exécution d’évaluation vous permet de générer des sorties de métriques pour chaque ligne de données de votre jeu de données de test. Vous pouvez choisir une ou plusieurs métriques d’évaluation pour évaluer la sortie à partir de différents aspects. Vous pouvez créer une exécution d’évaluation à partir des pages d’évaluation ou de catalogue de modèles dans le portail Azure AI Foundry. Ensuite, un Assistant création d’évaluation s’affiche pour vous guider tout au long du processus de configuration d’une exécution d’évaluation.
À partir de la page évaluer
Dans le menu de gauche réductible, sélectionnez Évaluation>+ Créer une nouvelle évaluation.

À partir de la page du catalogue de modèles
Dans le menu de gauche réductible, sélectionnez Catalogue de modèles>, accédez à un modèle > spécifique, puis accédez à l’onglet Point de référence > Essayer avec vos propres données. Le volet d’évaluation du modèle s’ouvre pour vous permettre de créer une exécution d’évaluation sur votre modèle sélectionné.

Cible d’évaluation
Lorsque vous démarrez une évaluation à partir de la page d’évaluation, vous devez d’abord décider de la cible d’évaluation. En spécifiant la cible d’évaluation appropriée, nous pouvons adapter l’évaluation à la nature spécifique de votre application, en garantissant des métriques précises et pertinentes. Nous prenons en charge deux types de cibles d’évaluation :
- Modèle affiné : vous souhaitez évaluer la sortie générée par votre modèle sélectionné et l’invite définie par l’utilisateur.
- Jeu de données : vous disposez déjà de sorties générées par votre modèle dans un jeu de données de test.

Configurer des données de test
Lorsque vous entrez dans l'assistant de création d'évaluation, vous pouvez sélectionner parmi les jeux de données préexistants ou charger un nouveau jeu de données spécifiquement pour l'évaluation. Le jeu de données de test doit avoir les sorties générées par le modèle à utiliser pour l’évaluation. Un aperçu de vos données de test s’affiche dans le volet droit.
Choisir un jeu de données existant: vous pouvez choisir le jeu de données de test dans votre collection de jeux de données établie.
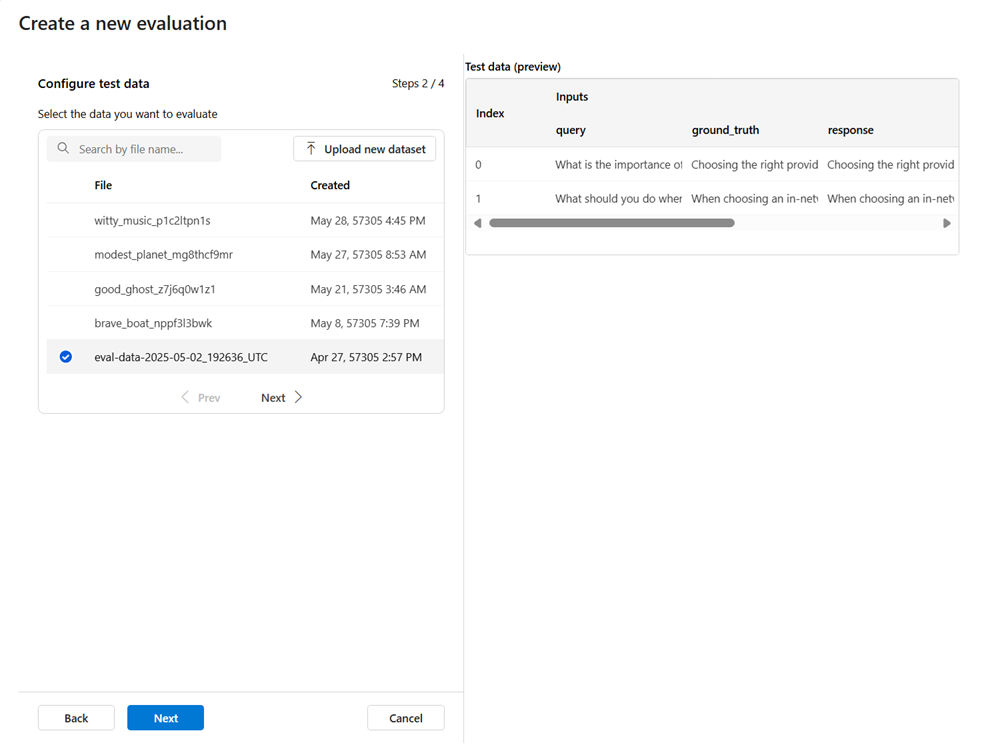
Ajouter un nouveau jeu de données : Vous pouvez charger des fichiers à partir de votre stockage local. Nous prenons uniquement en charge les formats de fichier
.csvet.jsonl. Un aperçu de vos données de test s’affiche dans le volet droit.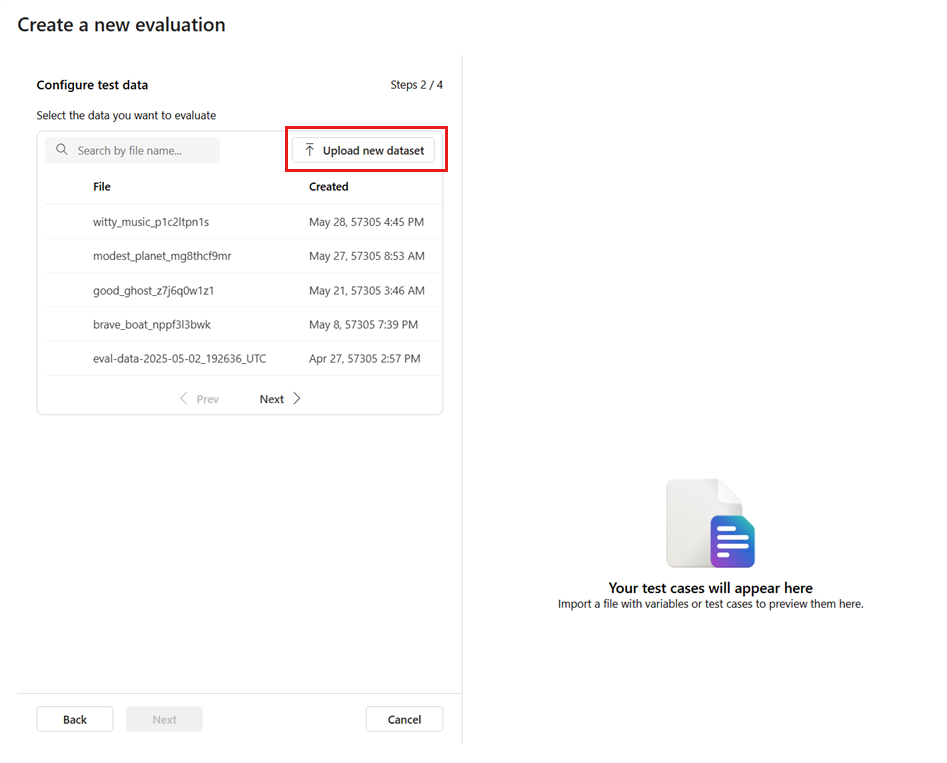


Configurer des critères de test
Nous prenons en charge deux types de métriques organisés par Microsoft pour faciliter une évaluation complète de votre application :
- Ces métriques évaluent la qualité globale et la cohérence du contenu généré. Pour exécuter ces métriques, il nécessite un déploiement de modèle en tant que juge.
- Qualité de l’IA (NLP) : ces métriques NLP sont mathématiques et évaluent également la qualité globale du contenu généré. Elles nécessitent souvent des données de réalité de terrain, mais elles ne nécessitent pas le déploiement de modèle comme juge.
- Métriques de risque et de sécurité : ces métriques se concentrent sur l’identification des risques potentiels liés au contenu ainsi que sur la sécurisation du contenu généré.

Lorsque vous ajoutez vos critères de test, différentes métriques seront utilisées dans le cadre de l’évaluation. Vous pouvez consulter le tableau pour obtenir la liste complète des métriques que nous prenons en charge dans chaque scénario. Pour plus d’informations détaillées sur chaque définition de métrique et la façon dont elle est calculée, consultez Qu’est-ce que les évaluateurs ?.
| Qualité de l’IA (assistée par l’IA) | Qualité de l’IA (NLP) | Métriques de risque et de sécurité |
|---|---|---|
| Fondement, pertinence, cohérence, fluidité, similarité GPT | Score F1, score ROUGE, score BLEU, score GLEU, score METEOR | Contenu lié à l’auto-préjudice, contenu haineux et injuste, contenu violent, contenu sexuel, matériel protégé, attaque indirecte |
Lors de l’exécution de l’évaluation de la qualité assistée par l’IA, vous devez spécifier un modèle GPT pour le processus de calcul/notation.

Les métriques de Qualité de l’IA (NLP) sont des mesures mathématiquement basées sur des mesures qui évaluent les performances de votre application. Elles nécessitent souvent des données de réalité de terrain pour le calcul. ROUGE est une famille de métriques. Vous pouvez sélectionner le type ROUGE pour calculer les scores. Différents types de métriques ROUGE offrent des moyens d’évaluer la qualité de la génération de texte. ROUGE-N mesure le chevauchement des n-grammes entre le candidat et les textes de référence.

Pour les métriques de risque et de sécurité, vous n’avez pas besoin de fournir un déploiement. Le service back-end des évaluations de sécurité du portail Azure AI Foundry approvisionne un modèle GPT-4, qui génère des scores de gravité et des explications sur les risques liés au contenu. Vous pouvez ainsi évaluer votre application en recherchant les problèmes potentiels liés à son contenu.

Remarque
Les métriques de risque et de sécurité assistées par IA sont hébergées par le service back-end des évaluations de sécurité d’Azure AI Foundry. Elles sont disponibles uniquement dans les régions suivantes : USA Est 2, France Centre, Royaume-Uni Sud, Suède Centre
Avertissement
Compatibilité descendante pour les utilisateurs Azure OpenAI intégrés à Foundry Developer Platform :
Les utilisateurs qui ont déjà utilisé oai.azure.com pour gérer leurs déploiements de modèles et exécuter des évaluations et qui ont depuis intégré à Foundry Developer Platform (FDP) ont quelques limitations lors de l’utilisation de ai.azure.com :
Tout d’abord, les utilisateurs ne pourront pas afficher leurs évaluations créées à l’aide de l’API Azure OpenAI. Au lieu de cela, pour afficher ces éléments, les utilisateurs doivent revenir à oai.azure.com.
Deuxièmement, les utilisateurs ne pourront pas utiliser l’API Azure OpenAI pour exécuter des évaluations dans AI Foundry. Au lieu de cela, ces utilisateurs doivent continuer à utiliser oai.azure.com pour cela. Toutefois, les utilisateurs peuvent utiliser les évaluateurs Azure OpenAI disponibles directement dans AI Foundry (ai.azure.com) dans l’option de création d’évaluation du jeu de données. L’option d’évaluation de modèle affinée n’est pas prise en charge si le déploiement est une migration du service Azure OpenAI vers Azure Foundry.
Pour le chargement du jeu de données + apportez votre propre scénario de stockage, quelques configurations doivent se produire :
- L'authentification du compte doit utiliser l'ID Entra.
- Le stockage doit être ajouté au compte (s’il est ajouté au projet, vous obtiendrez des erreurs de service).
- L’utilisateur doit ajouter son projet à son compte de stockage via le contrôle d’accès dans le portail Azure.
Pour en savoir plus sur la création d’évaluations spécifiquement avec des classateurs d’évaluation OpenAI dans Azure OpenAI Hub, consultez Comment utiliser l’évaluation du service Azure OpenAI
Mappage des données
Mappage des données pour l’évaluation : pour chaque métrique ajoutée, vous devez spécifier les colonnes de données de votre jeu de données correspondant aux entrées nécessaires dans l’évaluation. Différentes métriques d’évaluation demandent des types distincts d’entrées de données pour des calculs précis.
Pendant l’évaluation, la réponse du modèle est évaluée par rapport aux entrées clés telles que :
- Requête : obligatoire pour toutes les métriques
- Contexte : facultatif
- Réalité de terrain : facultative, requise pour les métriques de Qualité de l’IA (NLP)
Ces mappages garantissent un alignement précis entre vos données et les critères d’évaluation.

Pour obtenir des conseils sur les exigences de mappages de données spécifiques pour chaque métrique, reportez-vous aux informations fournies dans le tableau :
Exigences des métriques de requête et de réponse
| Unité de mesure | Requête | Réponse | Contexte | Vérité de terrain |
|---|---|---|---|---|
| Fondement | Obligatoire : Str | Obligatoire : Str | Obligatoire : Str | N/A |
| Cohérence | Obligatoire : Str | Obligatoire : Str | N/A | N/A |
| Fluidité | Obligatoire : Str | Obligatoire : Str | N/A | N/A |
| Pertinence | Obligatoire : Str | Obligatoire : Str | Obligatoire : Str | N/A |
| Similarité GPT | Obligatoire : Str | Obligatoire : Str | N/A | Obligatoire : Str |
| Score F1 | N/A | Obligatoire : Str | N/A | Obligatoire : Str |
| Score BLEU | N/A | Obligatoire : Str | N/A | Obligatoire : Str |
| Score GLEU | N/A | Obligatoire : Str | N/A | Obligatoire : Str |
| Score METEOR | N/A | Obligatoire : Str | N/A | Obligatoire : Str |
| score ROUGE | N/A | Obligatoire : Str | N/A | Obligatoire : Str |
| Contenu lié à l’automutilation | Obligatoire : Str | Obligatoire : Str | N/A | N/A |
| Contenu haineux et discriminatoire | Obligatoire : Str | Obligatoire : Str | N/A | N/A |
| Contenu violent | Obligatoire : Str | Obligatoire : Str | N/A | N/A |
| Contenu à caractère sexuel | Obligatoire : Str | Obligatoire : Str | N/A | N/A |
| Matériel protégé | Obligatoire : Str | Obligatoire : Str | N/A | N/A |
| Attaque indirecte | Obligatoire : Str | Obligatoire : Str | N/A | N/A |
- Requête recherchant des informations spécifiques.
- Réponse : réponse à la requête générée par le modèle.
- Contexte : la source de réponse est générée par rapport à (c’est-à-dire, les documents de base)...
- Réalité de terrain : réponse à une requête générée par un utilisateur/être humain et considérée comme la vraie réponse.
Passer en revue et terminer
Une fois toutes les configurations nécessaires terminées, vous pouvez fournir un nom facultatif pour votre évaluation. Vous pouvez ensuite passer en revue et continuer à sélectionner Envoyer pour soumettre l’exécution de l’évaluation.

Évaluation de modèle affinée
Pour créer une évaluation pour votre déploiement de modèle sélectionné, vous pouvez utiliser un modèle GPT pour générer des exemples de questions ou choisir parmi votre collection de jeux de données établie.

Configurer des données de test pour un modèle affiné
Configurez le jeu de données de test utilisé pour l’évaluation. Ce jeu de données est envoyé au modèle pour générer des réponses à des fins d’évaluation. Vous avez deux options pour configurer vos données de test :
- Générer des exemples de questions
- Utiliser un jeu de données existant (ou charger un nouveau jeu de données)
Générer des exemples de questions
Si vous n’avez pas de jeu de données facilement disponible et que vous souhaitez exécuter une évaluation avec un petit exemple, sélectionnez le déploiement de modèle que vous souhaitez évaluer en fonction d’une rubrique choisie. Nous prenons en charge les modèles Azure OpenAI et d’autres modèles ouverts compatibles avec le déploiement standard, tels que les modèles de famille Meta LIama et Phi-3. La rubrique permet d’adapter le contenu généré à votre domaine d’intérêt. Les requêtes et réponses sont générées en temps réel, et vous avez la possibilité de les régénérer si nécessaire.

Utilisation de votre jeu de données
Vous pouvez également choisir parmi votre collection de jeux de données établie ou charger un nouveau jeu de données.

Choisir les métriques d’évaluation
Ensuite, vous pouvez cliquer sur Suivant pour configurer vos critères de test. Lorsque vous sélectionnez vos critères, les métriques sont ajoutées et vous devez mapper les colonnes de votre jeu de données aux champs requis pour l’évaluation. Ces mappages garantissent un alignement précis entre vos données et les critères d’évaluation. Une fois que vous avez sélectionné les critères de test souhaités, vous pouvez passer en revue l’évaluation, modifier éventuellement le nom de l’évaluation, puis sélectionner Envoyer pour soumettre l’exécution de l’évaluation et accéder à la page d’évaluation pour afficher les résultats.

Remarque
Le jeu de données généré est enregistré dans le stockage d’objets blob du projet une fois l’exécution d’évaluation créée.
Afficher et gérer les évaluateurs dans la bibliothèque d’évaluateurs
La bibliothèque d’évaluateurs est un endroit centralisé qui vous permet de voir les détails et l’état de vos évaluateurs. Vous pouvez afficher et gérer les évaluateurs organisés par Microsoft.
La bibliothèque d’évaluateurs active également la gestion des versions. Vous pouvez comparer différentes versions de votre travail, restaurer les versions précédentes si nécessaire et collaborer plus facilement avec d’autres utilisateurs.
Pour utiliser la bibliothèque d’évaluateurs dans le portail Azure AI Foundry, accédez à la page Évaluation de votre projet et sélectionnez l’onglet Bibliothèque d’évaluateurs.

Vous pouvez sélectionner le nom de l’évaluateur pour afficher plus de détails. Vous pouvez voir le nom, la description et les paramètres, et vérifier les fichiers associés à l’évaluateur. Voici quelques exemples d’évaluateurs organisés par Microsoft :
- Pour les évaluateurs de performances et de qualité organisés par Microsoft, vous pouvez afficher l’invite d’annotations sur la page de détails. Vous pouvez adapter ces invites à votre propre cas d’usage en modifiant les paramètres ou les critères en fonction de vos données et objectifs dans le Kit de développement logiciel (SDK) Azure AI Evaluation. Par exemple, vous pouvez sélectionner Groundedness-Evaluator et vérifier le fichier Prompty montrant comment nous calculons la métrique.
- Pour les évaluateurs de risque et de sécurité organisés par Microsoft, vous pouvez voir la définition des métriques. Par exemple, vous pouvez sélectionner Évaluateur de contenu lié à l’automutilation et apprendre ce qu’il signifie et comment Microsoft détermine les différents niveaux de gravité pour cette métrique de sécurité.
Contenu connexe
En savoir plus sur la manière d’évaluer vos applications IA générative :