Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
- Compréhension de contenu IA Azure AI est disponible en avant-première. Les versions d'aperçu publiques offrent un accès anticipé aux fonctionnalités en cours de développement.
- Les fonctionnalités, les approches et les processus peuvent changer ou avoir des fonctionnalités limitées avant la mise en disponibilité générale.
- Pour plus d’informations, consultez les Conditions d’utilisation supplémentaires pour les versions préliminaires de Microsoft Azure.
Aperçu
Les fonctionnalités d’analyse de documents d’Azure AI Content Understanding vous aident à transformer des données de document non structurées en informations structurées lisibles par l’ordinateur. En identifiant et en extrayant précisément les éléments de document tout en préservant leurs relations structurelles, vous pouvez créer des workflows de traitement de documents puissants pour un large éventail d’applications.
Cet article explique les fonctionnalités d’analyse de document qui vous permettent d’extraire du contenu significatif de vos documents, de préserver les structures de documents et de déverrouiller le plein potentiel de vos données de document.
Éléments de document
Les éléments de document suivants peuvent être extraits via l’extraction de contenu :
- Markdown
- Éléments de contenu
- Éléments de disposition
Remarque
Tous les éléments de contenu et de disposition ne sont pas applicables ou actuellement pris en charge par tous les types de fichiers de document.
Éléments de contenu Markdown
Content Understanding génère un markdown richement mis en forme qui préserve la structure du document d’origine, ce qui permet aux modèles de langage volumineux de mieux comprendre le contexte de document et les relations hiérarchiques pour les tâches d’analyse et de génération optimisées par l’IA. En plus des mots, des marques de sélection, des codes-barres, des formules et des images en tant que contenu, le markdown inclut également des sections, des tableaux et des métadonnées de page pour le rendu visuel et le traitement automatique. En savoir plus sur la façon dont Content Understanding représente le contenu et l’élément de disposition dans Markdown.
Mots
A word est un élément de contenu composé d’une séquence de caractères. Content Understanding utilise des limites de mots définies par l’annexe standard Unicode #29. Pour les langues latines, les mots peuvent être séparés de la ponctuation même sans espaces intermédiaires. Dans certaines langues, comme le chinois, des dictionnaires supplémentaires sont utilisés pour faciliter le découpage des mots aux frontières sémantiques. Pour plus d’informations, consultezAnalyse des limites.

Marques de sélection
Un selection mark est un élément de contenu qui représente un glyphe visuel indiquant l'état d'une sélection. Elles peuvent être illustrées sous forme de cases à cocher, de coches, de boutons radio, etc. L'état d'un indicateur de sélection peut être activé ou désactivé, avec une présentation visuelle différente pour signaler son état. Ils sont codés en tant que mots dans le résultat d’analyse du document à l’aide ☒ (sélectionné) et ☐ (non sélectionné).
La compréhension de contenu détecte les marques de vérification dans la cellule du tableau comme des marques de sélection dans l’état sélectionné. Toutefois, elle ne détecte pas les cellules de tableau vides en tant que marques de sélection dans l’état non sélectionné.

Codes-barres
A barcode est un élément de contenu qui décrit les codes-barres linéaires (par exemple UPC, EAN) et 2D (ex. QR, MaxiCode). Content Understanding représente des codes-barres à l’aide de son type détecté et de sa valeur extraite. Les formats de codes-barres suivants sont actuellement acceptés :
QR CodeCode 39Code 93Code 128UPC (UPC-A & UPC-E)PDF417EAN-8EAN-13CodabarDatabarDatabar (expanded)ITFData Matrix
Formules
Un formula est un élément de contenu représentant des expressions mathématiques dans le document. Il peut s’agir d’une inline formule incorporée avec d’autres textes ou d’une display formule qui prend une ligne entière. Les formules multilignes sont représentées sous la forme de plusieurs display éléments de formule regroupés paragraphs pour préserver les relations mathématiques.
Images
Un image est un élément de contenu qui représente une image intégrée, une figure ou un graphique dans le document. Content Understanding extrait tout texte incorporé des images, ainsi que toutes les légendes et notes de bas de page associées.
Éléments de disposition
Les éléments de disposition de document sont des composants visuels et structurels, tels que des pages, des tables, des paragraphes, des lignes, des tables, des sections et une structure globale, qui aident à interpréter le contenu. L’extraction de ces éléments permet aux outils d’analyser efficacement les documents pour des tâches telles que la récupération d’informations, la compréhension sémantique et la structuration des données.
Feuilles
Il page s’agit d’un regroupement de contenu qui correspond généralement à un côté d’une feuille de papier. Une page rendue est caractérisée par width et height dans le fichier spécifié unit. En général, les images utilisent le pixel tandis que les fichiers PDF utilisent le pouce. La angle propriété décrit l’angle de texte global en degrés pour les pages qui peuvent être pivotées.
Remarque
Pour les feuilles de calcul comme Excel, chaque feuille est mappée à une page. Pour les présentations, comme PowerPoint, chaque diapositive est mappée à une page. Pour les formats de fichier tels que les documents HTML ou Word, qui n’ont pas de concept de page native sans rendu, le contenu principal entier est traité comme une seule page.
Paragraphes
Un paragraph est une séquence ordonnée de lignes qui forment une unité logique. En général, les lignes partagent un alignement commun et un espacement entre les lignes. Les paragraphes sont souvent délimités par une mise en retrait, un espacement supplémentaire ou des puces/numérotations. Certains paragraphes du document peuvent contenir des role fonctionnels spéciaux. Les rôles actuellement pris en charge incluent l’en-tête de page, le pied de page, le numéro de page, le titre, le titre de section, la note de bas de page et le bloc de formule.
Lignes
Il line s’agit d’une séquence ordonnée d’éléments de contenu consécutifs, souvent séparés par des espaces visuels. Les éléments de contenu situés dans le même plan horizontal (rangée) mais séparés par plus d’un espace visuel seront généralement divisés en plusieurs lignes. Si cette fonctionnalité permet parfois de diviser un contenu sémantiquement contigu en lignes distinctes, elle permet aussi de représenter un contenu textuel divisé en plusieurs colonnes ou cellules. Les lignes en écriture verticale sont détectées dans le sens vertical.
Tableaux
Un table organise un contenu en un groupe de cellules dans une disposition de grille. Les lignes et colonnes peuvent être séparées visuellement par des lignes de grille, une bande de couleurs ou un espacement supérieur. La position d’une cellule de tableau est spécifiée par ses indices de ligne et de colonne. Une cellule peut s’étendre sur plusieurs lignes et colonnes.
En fonction de sa position et de son style, une cellule peut être classée comme contenu général, en-tête de ligne, en-tête de colonne, en-tête de stub ou description :
Une cellule d’en-tête de ligne est généralement la première cellule d’une ligne qui décrit les autres cellules de la ligne.
Une cellule d’en-tête de colonne est généralement la première cellule d’une colonne qui décrit les autres cellules de la colonne.
Une ligne ou une colonne peut contenir plusieurs cellules d’en-tête pour décrire le contenu hiérarchique.
Une cellule de tête stub est généralement la cellule située dans la première rangée et la première colonne. Elle peut être vide ou décrire les valeurs dans les cellules d’en-tête dans la même ligne/colonne.
Une cellule de description apparaît généralement en haut ou en bas de la plupart des zones d’un tableau, décrivant le contenu global de la table. Toutefois, elle peut parfois apparaître au milieu d’un tableau pour décomposer le tableau en sections. En général, les cellules de description s’étendent sur plusieurs cellules d’une même ligne.
Une légende de tableau spécifie le contenu qui explique le tableau. Un tableau peut également avoir un ensemble de notes de bas de page. Contrairement à une cellule de description, une légende se trouve généralement en dehors de la disposition de la grille. Les notes de bas de page du tableau annotent le contenu à l’intérieur du tableau, souvent marquées avec des symboles de note de bas de page. Elles se trouvent souvent sous la grille du tableau.
Une table peut s’étendre sur plusieurs pages consécutives d’un document. Dans ce cas, les continuations de tables dans les pages suivantes conservent généralement le même nombre de colonnes, la largeur et le style. Elles répètent souvent les en-têtes de colonne. En dehors des en-têtes de page, des pieds de page et des numéros de page, il n’existe généralement aucun contenu intermédiaire entre la table initiale et ses continuations.
Remarque
L’étendue des tables couvre uniquement le contenu principal et exclut les légendes et notes de bas de page associées.
Rubriques
Il section s’agit d’un regroupement logique d’éléments de contenu connexes qui forment une structure hiérarchique dans le document. Il commence souvent par un titre de section comme premier paragraphe. Une section peut contenir des sous-sections, créant une structure de document imbriquée qui préserve les relations sémantiques.
Propriétés de l’élément
Les documents se composent de différents composants qui peuvent être classés en éléments structurels, textuels et liés aux formulaires. Ces éléments définissent non seulement l’organisation et la présentation du document, mais peuvent également être identifiés et extraits systématiquement pour une analyse ou une application supplémentaires.
Portées
La propriété span spécifie la position logique de l’élément dans le document via le décalage de caractères et la longueur indiquée dans la propriété de chaîne markdown de niveau supérieur. Par défaut, les décalages de caractères et les longueurs sont retournés sous forme de points de code Unicode, utilisés par Python 3. Pour prendre en charge différents environnements de développement qui utilisent différentes unités de caractères, l’utilisateur peut spécifier le stringEncoding paramètre de requête pour retourner des décalages d’étendue et des longueurs dans les unités de code UTF16 (Java, JavaScript, .NET) ou UTF8 octets (Go, Rust, Ruby, PHP).
Origine
La source propriété décrit la position visuelle de l’élément dans le fichier à l’aide d’une chaîne encodée. Pour les documents, la chaîne source peut se trouver dans l’un des formats suivants :
- Polygone englobant :
D({pageNumber},{x1},{y1},{x2},{y2},{x3},{y3},{x4},{y4}) - Cadre englobant aligné sur l’axe :
D({pageNumber},{left},{top},{width},{height})
Les numéros de page sont 1-indexed. Le polygone englobant décrit une séquence de points, dans le sens des aiguilles d’une montre à partir de la gauche par rapport à l’orientation naturelle de l’élément. Pour les quadrilatérales, les points représentent les coins supérieur gauche, supérieur droit, inférieur droit et inférieur gauche. Chaque point représente la coordonnée x, y dans l’unité de longueur spécifiée par la unit propriété. En général, l’unité de mesure pour les images est de pixels tandis que les fichiers PDF utilisent des pouces.
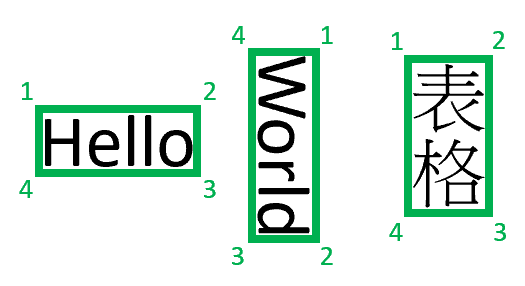
Remarque
Actuellement, la compréhension de contenu retourne uniquement 4-point quadrilatères comme polygones englobants. Les versions ultérieures peuvent retourner différents nombres de points pour décrire des formes plus complexes, telles que des lignes courbes ou des images nonrectangulaires. Actuellement, la source est retournée uniquement pour les éléments provenant de fichiers rendus (pdf/image).
Éléments de contenu et de disposition pris en charge
Différents formats de fichiers prennent en charge différents sous-ensembles de contenu et d’éléments de disposition. Le tableau suivant répertorie les éléments actuellement pris en charge pour chaque type de fichier.
| Type de document | Format pris en charge |
|---|---|
| Portable Document Format | .pdf |
| Image | .jpeg/.jpg, , .png.bmp, , .tiff.heif |
| Microsoft Office | .docx.pptx.xls |
Étapes suivantes
- Essayez de traiter votre contenu du document à l’aide de Content Understanding dans Azure AI Foundry.
- Apprenez à analyser les modèles d’analyseur de contenu de document.
- Passez en revue les exemples de code : recherche de documents visuels.
- Passez en revue l’exemple de code : modèles d’analyseur.