Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce contenu s’applique à :![]() v4.0 (GA) | Versions antérieures :
v4.0 (GA) | Versions antérieures :![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (retrait)
v3.0 (retrait)![]() v2.1 (mise hors service)
v2.1 (mise hors service)
::: moniker-end
Ce contenu s’applique à :![]() v3.0 (mise hors service) | Versions les plus récentes:
v3.0 (mise hors service) | Versions les plus récentes:![]() v4.0 (Disponibilité générale)
v4.0 (Disponibilité générale)![]() v3.1 | Version antérieure :
v3.1 | Version antérieure :![]() v2.1 (mise hors service)
v2.1 (mise hors service)
Ce contenu s’applique à :![]() v2.1 | Dernière version :
v2.1 | Dernière version :![]() v4.0 (GA)
v4.0 (GA)
Note
L’API Document Intelligence v4.0 2024-11-30 (GA) pour le modèle de document d’identité prédéfini prend désormais en charge les documents d’identification de toutes les régions du monde, y compris une couverture étendue en Amérique du Nord, en Amérique du Sud, en Asie, en Europe, en Afrique et en Océanie.
Le modèle document d’identité Document Intelligence (ID) combine la reconnaissance optique de caractères (OCR) avec des modèles d’apprentissage profond pour analyser et extraire des informations clés à partir de documents d’identité. L’API analyse les documents d’identité (y compris les éléments suivants) et retourne une représentation structurée des données JSON.
| Région | Types de documents |
|---|---|
| Mondial | Livret de passeport, Carte de passeport |
| États-Unis | Permis de conduire, Carte d’identification, Permis de résidence (carte verte), Carte de sécurité sociale, ID militaire |
| Inde | Permis de conduire, carte PAN, carte Aadhaar |
| Australie | Permis de conduire, carte photo, ID de passe de clé (y compris la version numérique) |
| Autres | Permis de conduire, carte d’identification, permis de résidence |
Document Intelligence peut analyser et extraire des informations provenant de documents d’identification émis par le gouvernement à l’aide de son modèle d’ID prédéfini. Il combine nos puissantes fonctionnalités de reconnaissance optique de caractères (OCR) avec des fonctionnalités de reconnaissance d’ID pour extraire des informations clés des licences des passeports mondiaux et des permis de conduire américains (toutes les 50 états et D.C.). L’API ID extrait les informations clés de ces documents d’identité, telles que le prénom, le nom, la date de naissance, le numéro de document, etc. Cette API est disponible dans Document Intelligence v2.1 en tant que service cloud.
Traitement des documents d’identité
Le traitement des documents d’identité implique l’extraction de données à partir de documents d’identité manuellement ou à l’aide de la technologie OCR. Le traitement des documents d’ID est une étape importante de toute opération métier qui nécessite une preuve d’identité. Par exemple, la vérification des clients dans les banques et d’autres institutions financières, les demandes hypothécaires, les visites médicales, le traitement des demandes de réclamation, l’industrie de l’hospitalité, etc. Les individus fournissent une preuve de leur identité via des permis de conduire, des passeports et d’autres documents similaires afin que l’entreprise puisse les vérifier efficacement avant de fournir des services et des avantages.
Exemple de permis de conduire américain traité avec Document Intelligence Studio
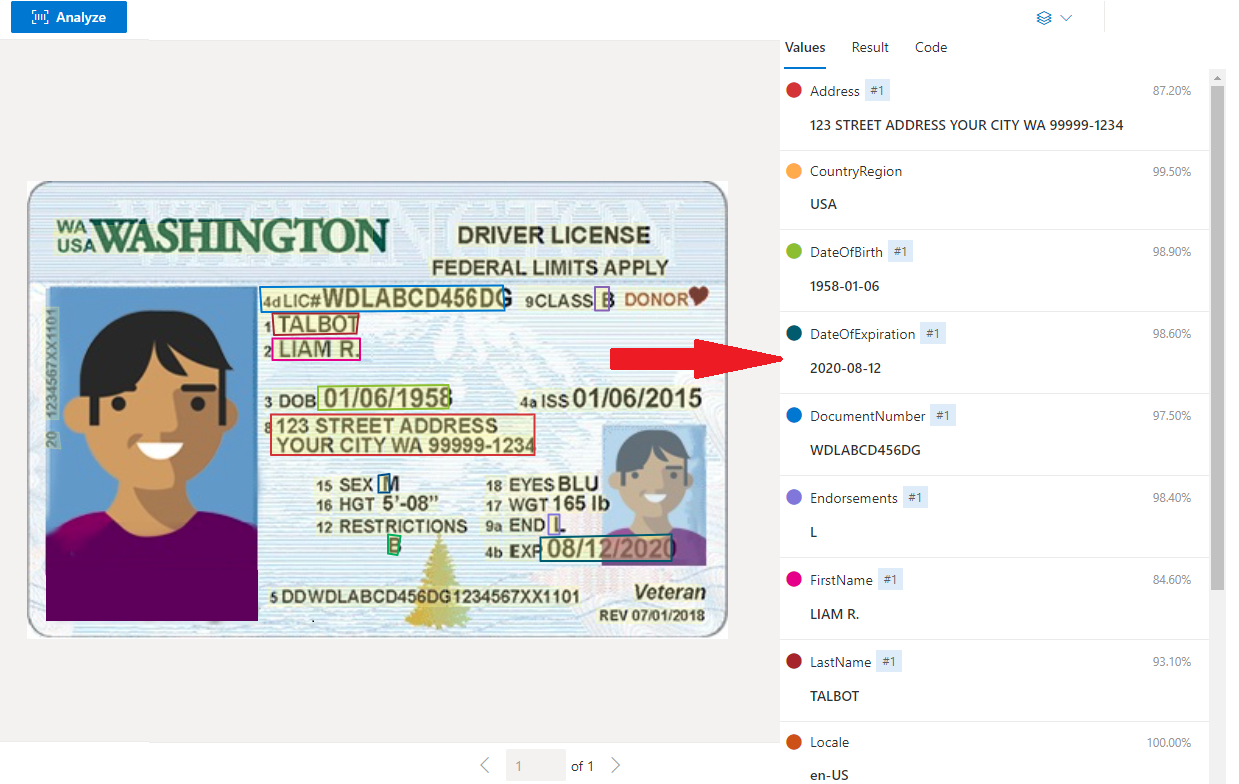
Extraction de données
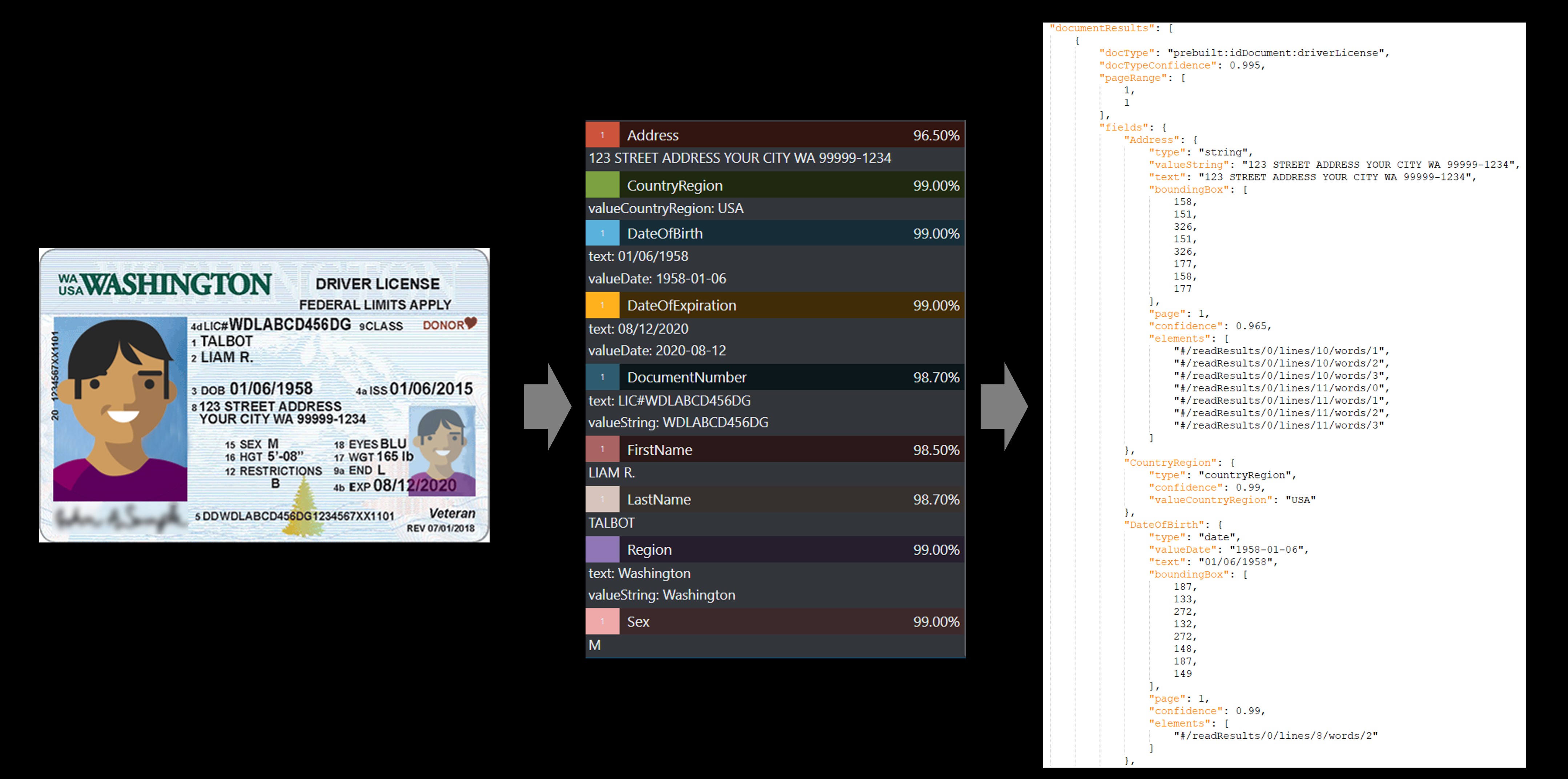
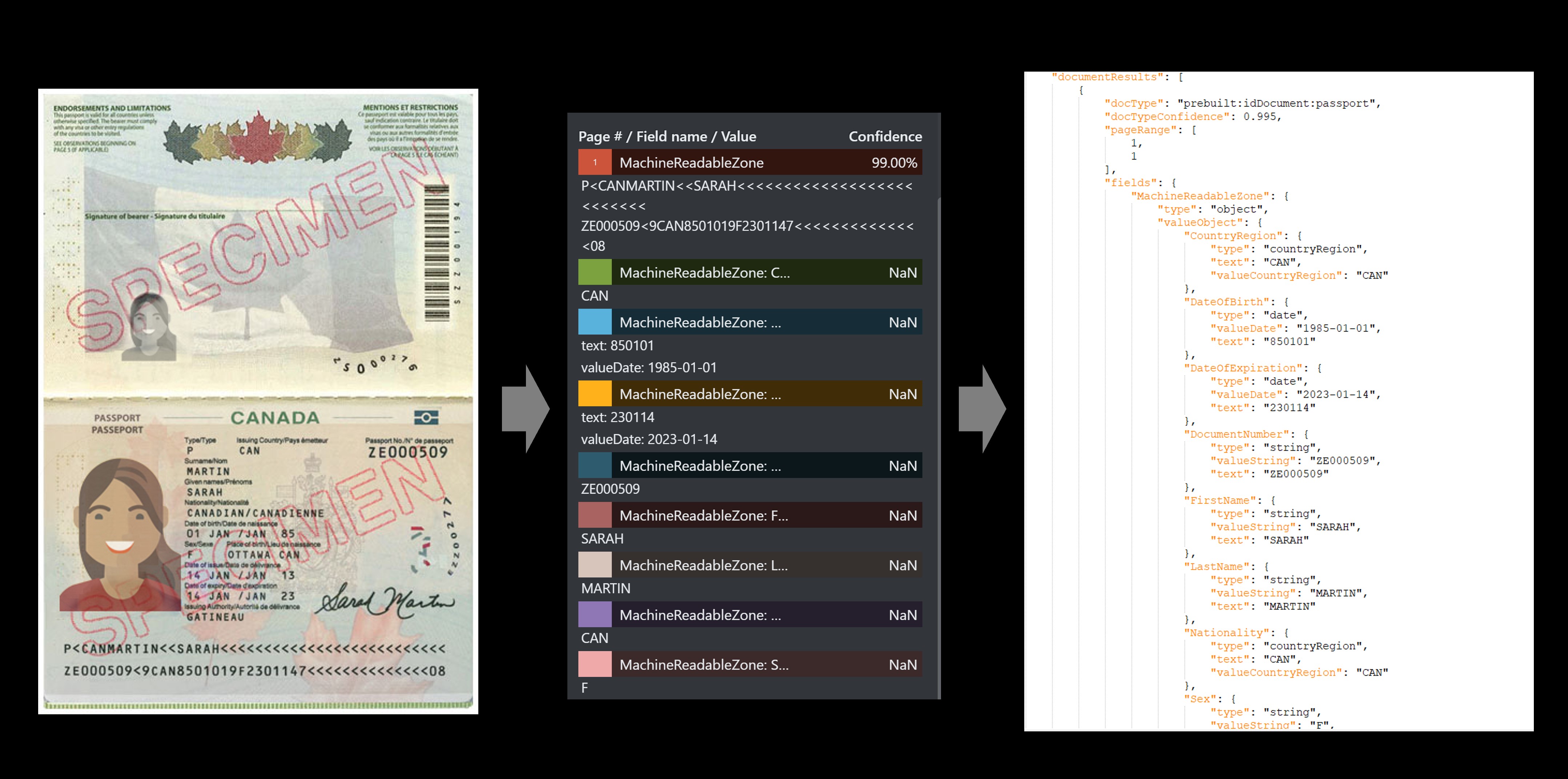
Le service d'IDs prédéfinis extrait les valeurs clés des passeports internationaux et des permis de conduire américains et les renvoie dans une réponse JSON structurée.
Exemple de permis de conduire
Exemple de passeport
Options de développement
Document Intelligence v4.0 : 2024-11-30 (GA) prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources | ID de modèle |
|---|---|---|
| Modèle de document d’ID | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v3.1 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources | ID de modèle |
|---|---|---|
| Modèle de document d’ID | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v3.0 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources | ID de modèle |
|---|---|---|
| Modèle de document d’ID | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v2.1 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources |
|---|---|
| Modèle de document d’ID | • Outil d’étiquetage Document Intelligence • API REST • bibliothèque cliente SDK • Conteneur Docker Document Intelligence |
Exigences pour les données
Les formats de fichier suivants sont pris en charge.
| Modèle | Image : JPEG/JPG, PNG, BMP, TIFF, HEIF |
Office : Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lire | ✔ | ✔ | ✔ |
| Mise en page | ✔ | ✔ | ✔ |
| Document général | ✔ | ✔ | |
| Préassemblé | ✔ | ✔ | |
| Extraction personnalisée | ✔ | ✔ | |
| Classification personnalisée | ✔ | ✔ | ✔ |
- Photos et analyses : pour obtenir de meilleurs résultats, fournissez une photo claire ou une analyse de haute qualité par document.
- PDF et TIFFs : pour les fichiers PDF et les TIFF, jusqu’à 2 000 pages peuvent être traitées. (Avec un abonnement de niveau gratuit, seules les deux premières pages sont traitées.)
- Taille du fichier : la taille de fichier pour l’analyse des documents est de 500 Mo pour le niveau payant (S0) et de 4 Mo pour le niveau gratuit (F0).
- Dimensions de l’image : les dimensions doivent être comprises entre 50 pixels x 50 pixels et 10 000 pixels x 10 000 pixels.
- Verrous de mot de passe : si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant la soumission.
- Hauteur du texte : la hauteur minimale du texte à extraire est de 12 pixels pour une image de 1 024 x 768 pixels. Cette dimension correspond à environ 8 points de texte à 150 points par pouce.
- Entraînement de modèle personnalisé : le nombre maximal de pages pour les données d’apprentissage est de 500 pour le modèle de modèle personnalisé et de 50 000 pour le modèle neuronal personnalisé.
- Entraînement du modèle d’extraction personnalisé : la taille totale des données d’entraînement est de 50 Mo pour le modèle de modèle et de 1 Go pour le modèle neuronal.
- Entraînement du modèle de classification personnalisé : la taille totale des données d’apprentissage est de 1 Go avec un maximum de 10 000 pages. Pour 2024-11-30 (GA), la taille totale des données d’apprentissage est de 2 Go avec un maximum de 10 000 pages.
- Types de fichiers Office (DOCX, XLSX, PPTX) : la limite maximale de longueur de chaîne est de 8 millions de caractères.
Formats de fichiers pris en charge : JPEG, PNG, PDF et TIFF.
Nombre de pages prises en charge pour les fichiers PDF et TIFF : jusqu’à 2 000 pages ou seulement les deux premières pages pour les abonnés de niveau gratuit.
Taille de fichier prise en charge : moins de 50 Mo TOTAL ; pixels minimum : 50 x 50 px ; pixels maximum 10 000 x 10 000 px.
Extraction des données du modèle de document d’ID
Extrayez des données, notamment le nom, la date de naissance et la date d’expiration, à partir de documents d’ID. Vous avez besoin des ressources suivantes :
Un abonnement Azure : vous pouvez créer un abonnement gratuitement.
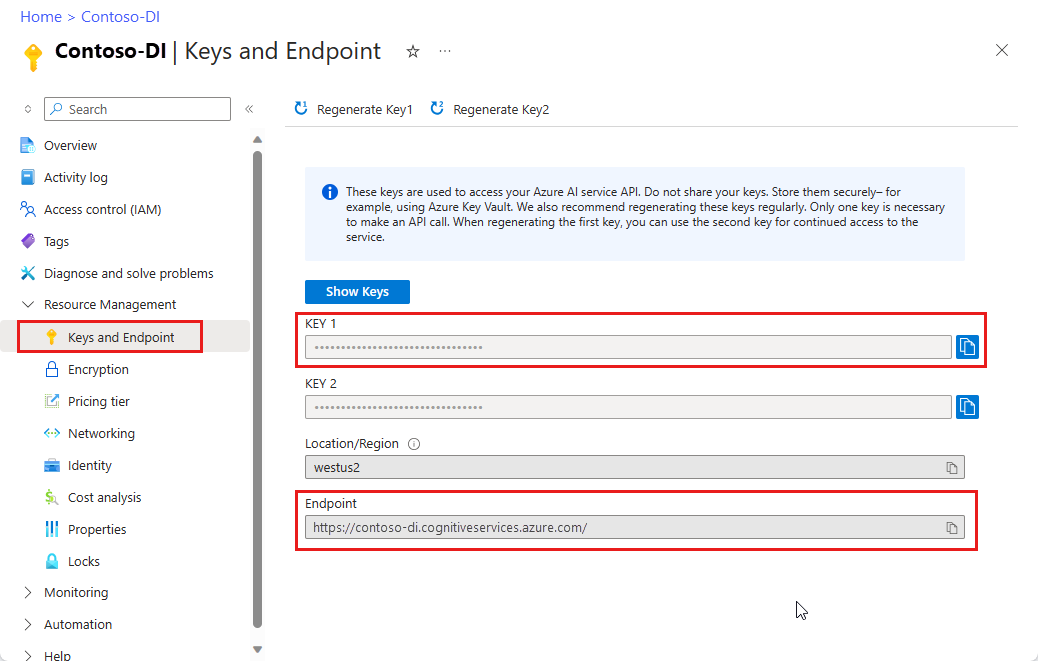
Une instance Document Intelligence dans le portail Azure. Vous pouvez utiliser le niveau tarifaire gratuit (
F0) pour essayer le service. Une fois votre ressource déployée, sélectionnez Accéder à la ressource pour obtenir votre clé et votre point de terminaison.
Note
Document Intelligence Studio est disponible avec les API v3.1 et v3.0 et versions ultérieures.
Dans la page d’accueil document Intelligence Studio, sélectionnez Documents d’identité.
Vous pouvez analyser l’exemple de facture ou charger vos propres fichiers.
Sélectionnez le bouton Exécuter l’analyse et, si nécessaire, configurez les options Analyser :

Outil d’étiquetage d’exemples pour Document Intelligence
Accédez à l'outil d'exemple Document Intelligence.
Sur la page d'accueil de l'outil d'exemple, sélectionnez la vignette Utiliser le modèle prédéfini pour obtenir des données.
Sélectionnez le type de formulaire à analyser dans le menu déroulant.
Choisissez une URL pour le fichier que vous souhaitez analyser dans les options ci-dessous :
- Document d'exemple de facture.
- Document d'identité échantillon.
- Image d'exemple de reçu.
- Exemple d'image de carte de visite.
Dans le champ Source , sélectionnez l’URL dans le menu déroulant, collez l’URL sélectionnée, puis sélectionnez le bouton Récupérer .
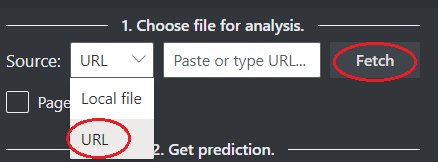
Dans le champ point de terminaison du service Document Intelligence , collez le point de terminaison que vous avez obtenu avec votre abonnement Document Intelligence.
Dans le champ clé , collez la clé que vous avez obtenue à partir de votre ressource Document Intelligence.
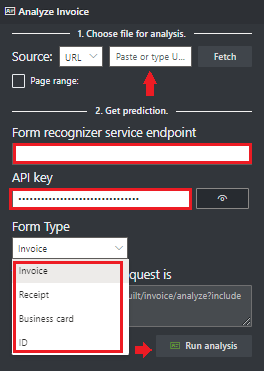
Sélectionnez Exécuter l’analyse. L'outil d'étiquetage d'exemples de Document Intelligence appelle l'API d'analyse pré-construite et analyse le document.
Affichez les résultats : consultez les paires clé-valeur extraites, les éléments de ligne, le texte en surbrillance extrait et les tableaux détectés.
Téléchargez le fichier de sortie JSON pour afficher les résultats détaillés.
- Le nœud « readResults » contient chaque ligne de texte avec sa position de cadre englobant respective dans la page.
- Le nœud « selectionMarks » affiche chaque marque de sélection (case à cocher, case d’option) et indique si son état est sélectionné ou non sélectionné.
- La section « pageResults » inclut les tables extraites. Pour chaque tableau, Document Intelligence extrait le texte, l’index de ligne et de colonne, l’étendue de ligne et de colonne, le cadre englobant, etc.
- Le champ « documentResults » contient des informations sur les paires clé/valeur et les informations sur les éléments de ligne pour les parties les plus pertinentes du document.
{kind=link}
{kind=link}
{kind=link}
Note
L’outil Exemple d’étiquetage ne prend pas en charge le format de fichier BMP. Cette restriction est une limitation de l’outil et non du service Document Intelligence.
Extractions de champs
Pour les champs d’extraction de documents pris en charge, voir le schéma du modèle de document ID dans notre référentiel d'exemples sur GitHub.
Types de documents pris en charge
Le modèle de document d’identification prend actuellement en charge l'extraction des permis de conduire américains et de la page des informations biographiques des passeports internationaux, à l’exclusion des visas et autres documents de voyage.
Champs extraits
| Nom | Type | Description | Valeur |
|---|---|---|---|
| Pays | Pays | Code de pays conforme à la norme ISO 3166 | « Usa » |
| Date de naissance | Date | Date de naissance au format AAAA-MM-JJ | "1980-01-01" |
| Date d'expiration | Date | Date d’expiration au format AAAA -MM-DD | "2019-05-05" |
| Numéro de document | string | Numéro de passeport approprié, numéro de permis de conduire, etc. | "340020013" |
| Prénom | string | Nom donné et initial moyen extraits le cas échéant | « JENNIFER » |
| Nom de famille | string | Nom de famille extrait | « BROOKS » |
| Nationalité | Pays | Code de pays conforme à la norme ISO 3166 | « Usa » |
| Sexe | Sexe | Les valeurs extraites possibles incluent « M » « F » « X » | « F » |
| Zone de lecture automatique | Objet | Passeport MRZ extrait comprenant deux lignes de 44 caractères chacun |
« P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307 715816< » |
| DocumentType | string | Type de document, par exemple Passport, Permis de conduire | « passeport » |
| Adresse | string | Adresse extraite (permis de conduire uniquement) | « 123 STREET ADDRESS YOUR CITY WA 99999-1234 » |
| Région | string | Région extraite, état, province, etc. (permis de conduire uniquement) | « Washington » |
Guide de migration
- Suivez notre guide de migration Document Intelligence v3.1 pour découvrir comment utiliser la version v3.0 dans vos applications et flux de travail.
Étapes suivantes
Essayez de traiter vos propres formulaires et documents avec Document Intelligence Studio.
Suivez un guide de démarrage rapide Document Intelligence et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.
Essayez de traiter vos propres formulaires et documents avec l'outil d'étiquetage d'exemples de Document Intelligence.
Suivez un guide de démarrage rapide Document Intelligence et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.