Tout d’abord, vous devez disposer de votre point de terminaison et de votre clé de ressource :
Accédez à la page de présentation de votre ressource sur le Portail Azure. Dans le menu de gauche, sélectionnez Clés et point de terminaison. Le point de terminaison et la clé servent pour les demandes d’API.
Interroger votre modèle
Créez une demande POST en utilisant l’URL, les en-têtes et le corps JSON suivants pour commencer le test d’un modèle de flux de travail d’orchestration.
URL de la demande
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| Espace réservé |
Valeur |
Exemple |
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Version de l’API que vous appelez. |
2023-04-01 |
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé |
Valeur |
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Corps de la demande
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"text": "Text1",
"participantId": "1",
"id": "1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"directTarget": "qnaProject",
"targetProjectParameters": {
"qnaProject": {
"targetProjectKind": "QuestionAnswering",
"callingOptions": {
"context": {
"previousUserQuery": "Meet Surface Pro 4",
"previousQnaId": 4
},
"top": 1,
"question": "App Service overview"
}
}
}
}
}
Corps de la réponse
Une fois que vous avez envoyé la demande, vous recevez la réponse suivante comme prédiction.
{
"kind": "ConversationResult",
"result": {
"query": "App Service overview",
"prediction": {
"projectKind": "Orchestration",
"topIntent": "qnaTargetApp",
"intents": {
"qnaTargetApp": {
"targetProjectKind": "QuestionAnswering",
"confidenceScore": 1,
"result": {
"answers": [
{
"questions": [
"App Service overview"
],
"answer": "The compute resources you use are determined by the *App Service plan* that you run your apps on.",
"confidenceScore": 0.7384000000000001,
"id": 1,
"source": "https://learn.microsoft.com/azure/app-service/overview",
"metadata": {},
"dialog": {
"isContextOnly": false,
"prompts": []
}
}
]
}
}
}
}
}
}
Tout d’abord, vous devez disposer de votre point de terminaison et de votre clé de ressource :
Accédez à la page de présentation de votre ressource sur le Portail Azure. Dans le menu de gauche, sélectionnez Clés et point de terminaison. Le point de terminaison et la clé servent pour les demandes d’API.
Utiliser des bibliothèques de client (Kit de développement logiciel [SDK] Azure)
Vous pouvez également utiliser les bibliothèques de client fournies par le SDK Azure pour envoyer des requêtes à votre modèle.
Notes
La bibliothèque de client pour la compréhension du langage courant est disponible uniquement pour les langages suivants :
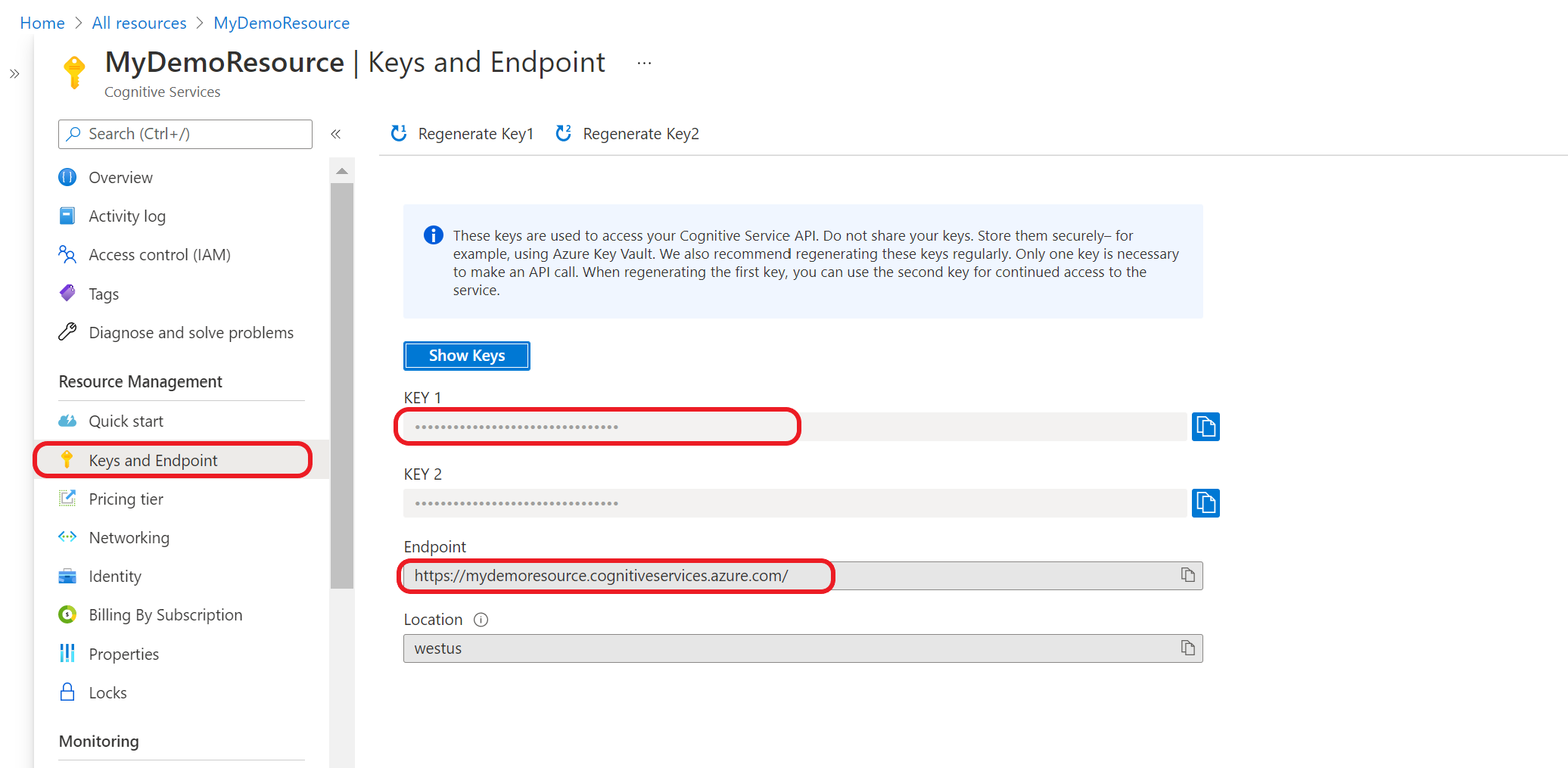
Accédez à la page de vue d’ensemble de votre ressource dans le portail Azure
Dans le menu de gauche, sélectionnez Clés et point de terminaison. Utilisez le point de terminaison pour les demandes d’API et la clé pour l’en-tête Ocp-Apim-Subscription-Key.
Téléchargez et installez le package de bibliothèque de clients pour le langage de votre choix :
| Langage |
Version du package |
| .NET |
1.0.0 |
| Python |
1.0.0 |
Une fois que vous avez installé la bibliothèque cliente, utilisez les exemples suivants sur GitHub pour démarrer l’appel de l’API.
Pour plus d’informations, consultez la documentation de référence ci-dessous :