Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
- Les publications de préversion publique d’Azure AI Language offrent un accès en avant-première aux fonctionnalités en cours de développement.
- Les fonctionnalités, les approches et les processus peuvent changer, avant la disponibilité générale (GA), en fonction des commentaires des utilisateurs.
Azure AI Language est un service cloud qui applique des fonctionnalités de traitement du langage naturel (NLP, Natural Language Processing) aux données textuelles. Le résumé des documents utilise le traitement du langage naturel pour générer des résumés extractifs (extraction de phrases clés) ou abstractifs (extraction de mots contextuels) de documents. Les API AbstractiveSummarization et ExtractiveSummarization prennent en charge le traitement des documents natifs. Un document natif fait référence au format de fichier utilisé pour créer le document d’origine, comme un fichier Microsoft Word (docx) ou un fichier de document portable (pdf). La prise en charge des documents natifs évite de prétraiter le texte avant d’utiliser les fonctionnalités des ressources Azure AI Language. La capacité de prise en charge des documents natifs vous permet d’envoyer des requêtes d’API de manière asynchrone en utilisant un corps de requête HTTP POST pour envoyer vos données et une chaîne de requête HTTP GET pour récupérer les résultats d’état. Vos documents traités se trouvent dans votre conteneur cible Stockage Blob Azure.
Formats de document pris en charge
Les applications utilisent des formats de fichiers natifs pour créer, enregistrer ou ouvrir des documents natifs. Actuellement, les fonctionnalités Informations d’identification personnelle et Résumé des documents prennent en charge les formats de document natifs suivants :
| Type de fichier | Extension de fichier | Descriptif |
|---|---|---|
| Texto | .txt |
Document texte non mis en forme. |
| Adobe PDF | .pdf |
Document au format de fichier de document portable. |
| Microsoft Word | .docx |
Fichier de document Microsoft Word. |
Recommandations concernant les entrées
Formats de fichiers pris en charge
| Catégorie | prise en charge et limitations |
|---|---|
| Fichiers PDF | Les fichiers PDF entièrement analysés ne sont pas pris en charge. |
| Texte dans les images | Les images numériques avec du texte incorporé ne sont pas prises en charge. |
| Tableaux numériques | Les tableaux dans les documents analysés ne sont pas pris en charge. |
Taille des documents
| Caractéristique | Limite d’entrée |
|---|---|
| Nombre total de documents par requête | ≤ 20 |
| Taille totale du contenu par requête | PLUS PETIT OU ÉGAL À 10 MO |
Inclure des documents natifs avec une requête HTTP
Commençons :
Pour ce projet, nous utilisons l’outil en ligne de commande cURL pour effectuer des appels d’API REST.
Remarque
Le package cURL est préinstallé sur la plupart des systèmes Windows 10 et Windows 11 et sur la plupart des distributions macOS et Linux. Vous pouvez vérifier la version du package avec les commandes suivantes : Windows :
curl.exe -VmacOScurl -VLinux :curl --versionSi cURL n’est pas installé, voici les liens d’installation pour votre plateforme :
Un compte Azure actif. Si vous n’en avez pas, vous pouvez créer un compte gratuit.
Un compte de stockage Blob Azure. Vous devez également créer des conteneurs dans votre compte de stockage Blob Azure pour vos fichiers sources et cibles :
- Conteneur source. Ce conteneur est l’emplacement où vous chargez vos fichiers natifs pour l’analyse (obligatoire).
- Conteneur cible. Ce conteneur est l’emplacement où vos fichiers analysés sont stockés (obligatoire).
Une ressource de langage à service unique (et non une ressource Azure AI Foundry multiservices) :
Complétez les champs des détails du projet de ressource Language et de l’instance comme suit :
Abonnement. Sélectionnez l’un de vos abonnements Azure disponibles.
Groupe de ressources Vous pouvez créer un groupe de ressources ou ajouter votre ressource à un groupe de ressources préexistant qui partage le même cycle de vie, les mêmes autorisations et les mêmes stratégies.
Région de la ressource. Choisissez Globale, sauf si votre entreprise ou votre application nécessite une région spécifique. Si vous envisagez d’utiliser une identité managée affectée par le système pour l’authentification, choisissez une région géographique telle que USA Ouest.
Nom. Entrez le nom choisi pour votre ressource. Le nom choisi doit être unique dans Azure.
Niveau tarifaire. Vous pouvez utiliser le niveau tarifaire Gratuit (
Free F0) pour tester le service, puis passer par la suite à un niveau payant pour la production.Sélectionnez Vérifier + créer.
Passez en revue les conditions du service, puis sélectionnez Créer pour déployer votre ressource.
Une fois votre ressource correctement déployée, sélectionnez Accéder à la ressource.
Récupérer votre clé et votre point de terminaison de service de langage
Les demandes adressées au service Language nécessitent une clé en lecture seule et un point de terminaison personnalisé pour authentifier l’accès.
Si vous avez créé une ressource, après son déploiement, sélectionnez Accéder à la ressource. Si vous disposez déjà d’une ressource de service de langage, accédez directement à la page de votre ressource.
Dans le rail de gauche, sous Gestion des ressources, sélectionnez Clés et point de terminaison.
Vous pouvez copier et coller vos
keyetlanguage service instance endpointdans les exemples de code pour authentifier votre requête auprès du service Language. Une seule clé est nécessaire pour effectuer un appel d’API.
Créer des conteneurs de stockage Blob Azure
Créez des conteneurs dans votre compte Stockage Blob Azure pour les fichiers sources et cibles.
- Conteneur source. Ce conteneur est l’emplacement où vous chargez vos fichiers natifs pour l’analyse (obligatoire).
- Conteneur cible. Ce conteneur est l’emplacement où vos fichiers analysés sont stockés (obligatoire).
Authentification
Votre ressource Language doit recevoir un accès à votre compte de stockage avant de pouvoir créer, lire ou supprimer des blobs. Il existe deux méthodes principales que vous pouvez utiliser pour accorder l’accès à vos données de stockage :
Jetons de signature d’accès partagé (SAS). Les jetons SAS de délégation d’utilisateur sont sécurisés avec des informations d’identification Microsoft Entra. Un jeton SAS fournit un accès délégué sécurisé aux ressources dans votre compte de stockage Azure.
Contrôle d’accès en fonction du rôle (RBAC) d’identité managée. Les identités managées pour les ressources Azure sont des principaux de service qui créent une identité Microsoft Entra et des autorisations spécifiques pour les ressources managées Azure.
Pour ce projet, nous authentifions l’accès aux URL source location et target location avec des jetons SAS (Shared Access Signature) ajoutés en tant que chaînes de requête. Chaque jeton est affecté à un blob spécifique (fichier).

- Votre blob ou conteneur source doit désigner un accès de lecture et de liste.
- Votre blob ou conteneur cible doit désigner un accès écriture et liste.
L’API de résumé extractif utilise des techniques de traitement automatique des langues pour localiser les phrases clés d’un document texte non structuré. Ces phrases transmettent collectivement l’idée principale du document.
Le résumé extractif renvoie un score de classement dans le cadre de la réponse du système, ainsi que les phrases extraites et leur position dans les documents d’origine. Un score de classement est un indicateur de la pertinence d’une phrase par rapport à l’idée principale d’un document. Le modèle attribue un score compris entre 0 et 1 (inclus) à chaque phrase et renvoie les phrases les mieux notées par requête. Par exemple, si vous demandez un résumé de trois phrases, le service renvoie les trois phrases les mieux notées.
Il existe une autre fonctionnalité d’Azure AI Language : I’extraction de phrases clés, qui permet d’extraire des informations essentielles. Pour décider entre l’extraction de phrases clés et le résumé extractif, voici des considérations utiles :
- L’extraction de phrases clés renvoie des expressions alors que le résumé extractif renvoie des phrases.
- Le résumé extractif retourne des phrases avec un score de classement, les phrases les mieux classées sont retournées sur demande.
- Le résumé extractif retourne également les informations de position suivantes :
- Décalage : position de début de chaque phrase extraite.
- Longueur : longueur de chaque phrase extraite.
Déterminer le mode de traitement des données (facultatif)
Envoi de données
Les documents sont envoyés à l’API sous forme de chaînes de texte. L’analyse est effectuée à la réception de la demande. Comme l’API est asynchrone, il peut y avoir un délai entre l’envoi d’une demande d’API et la réception des résultats.
Lorsque vous utilisez cette fonctionnalité, les résultats de l’API sont disponibles pendant 24 heures à partir du moment où la demande a été ingérée, et sont indiqués dans la réponse. Après cette période, les résultats sont purgés et ne sont plus disponibles pour récupération.
Récupération des résultats du résumé de texte
Lorsque vous recevez des résultats de la détection de langue, vous pouvez diffuser les résultats dans une application ou enregistrer la sortie dans un fichier sur le système local.
Voici un exemple de contenu que vous pouvez soumettre pour résumé, qui est extrait à l’aide de l’article de blog Microsoft Une représentation holistique vers l’IA intégrative. Cet article n’est qu’un exemple. L’API peut accepter du texte d’entrée plus long. Pour plus d’informations, consultezles limites de données et de service.
« Chez Microsoft, nous cherchons à faire progresser l’IA au-delà des techniques existantes, en adoptant une approche plus holistique et plus humaine de l’apprentissage et de la compréhension. En tant que directeur de la technologie d’Azure AI services, je collabore avec une équipe de scientifiques et d’ingénieurs exceptionnels pour faire de cette quête en réalité. Dans le cadre de mes fonctions, je bénéficie d’une perspective unique pour observer la relation entre trois attributs de la cognition humaine : le texte monolingue (X), les signaux sensoriels audio ou visuels (Y) et le texte multilingue (Z). La magie se produit à l’intersection de ces trois attributs : c’est ce que nous appelons le code XYZ, comme l’illustre la figure 1, une représentation conjointe permettant de créer une IA plus puissante, capable de mieux parler, entendre, voir et comprendre les humains. Nous pensons que le code XYZ nous permet de réaliser notre vision à long terme : l’apprentissage de transfert entre domaines, couvrant différentes modalités et différentes langues. L’objectif est de disposer de modèles préentraînés capables d’apprendre conjointement des représentations pour prendre en charge un large éventail de tâches d’IA en aval, comme les humains le font aujourd’hui. Au cours des cinq dernières années, nous avons obtenu des résultats de l’ordre des performances humaines dans des tests d’évaluation portant sur la reconnaissance vocale du langage courant, la traduction automatique, les réponses aux questions du langage courant, la compréhension de la lecture automatique et le sous-titrage d’images. Ces cinq percées nous ont fourni des signaux forts en direction de notre aspiration plus ambitieuse : faire un bond en avant dans les capacités de l’IA, en réalisant un apprentissage multisensoriel et multilingue plus proche de la façon dont les humains apprennent et comprennent. Je pense que le code XYZ conjoint constitue un élément fondamental de cette aspiration, s’il est fondé sur des sources de connaissances externes dans les tâches d’IA en aval.
La requête API de résumé de texte est traitée dès réception de la demande en créant une tâche pour le back-end de l’API. Si la tâche réussit, la sortie de l’API est retournée. La sortie peut être récupérée pendant 24 heures. après quoi elle est vidée. En raison de la prise en charge multilingue et des émojis, la réponse peut contenir des décalages de texte. Pour plus d’informations, consultezcomment traiter les décalages.
Lorsque vous utilisez l’exemple précédent, l’API peut retourner ces phrases résumées :
Résumé extractif :
- « Chez Microsoft, nous cherchons à faire progresser l’IA au-delà des techniques existantes, en adoptant une approche plus holistique et plus humaine de l’apprentissage et de la compréhension. »
- «Nous pensons que le code XYZ nous permet de réaliser notre vision à long terme l’apprentissage de transfert entre domaines, couvrant différentes modalités et différentes langues.»
- «L’objectif est de disposer de modèles pré-entraînés capables d’apprendre conjointement des représentations pour prendre en charge un large éventail de tâches d’IA en aval, comme les humains le font aujourd’hui.»
Résumé abstractif :
- « Microsoft adopte une approche plus holistique et humaine de l’apprentissage et de la compréhension. Nous pensons que le code XYZ nous permet de réaliser notre vision à long terme : l’apprentissage de transfert entre domaines, couvrant différentes modalités et différentes langues. Au cours des cinq dernières années, nous avons atteint des performances humaines sur les benchmarks. »
Essayer le résumé par extraction de texte
Vous pouvez utiliser le résumé par extraction de texte pour obtenir des résumés d’articles, de papiers ou de documents. Pour voir un exemple, consultez l’article sur le démarrage rapide.
Vous pouvez utiliser le paramètre sentenceCount pour guider le nombre de phrases qui sont renvoyées, 3 étant la valeur par défaut. La plage est comprise entre 1 et 20.
Par ailleurs, le paramètre sortby permet de spécifier l’ordre dans lequel les phrases extraites sont retournées : Offset ou Rank, par défaut Offset.
| Valeur du paramètre | Descriptif |
|---|---|
| Classement | Trie les phrases en fonction de leur pertinence pour le document d’entrée, déterminée par le service. |
| Offset | Conserve l’ordre d’origine dans lequel les phrases apparaissent dans le document d’entrée. |
Essayez le résumé par abstraction du texte
L’exemple suivant vous permet de commencer à utiliser le résumé par abstraction de texte :
- Copiez la commande ci-après dans un éditeur de texte. L’exemple BASH utilise le caractère de continuation de ligne
\. Si votre console ou terminal utilise un caractère de continuation de ligne différent, utilisez ce caractère à la place.
curl -i -X POST https://<your-language-resource-endpoint>/language/analyze-text/jobs?api-version=2023-04-01 \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>" \
-d \
'
{
"displayName": "Text Abstractive Summarization Task Example",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en",
"text": "At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding. As Chief Technology Officer of Azure AI services, I have been working with a team of amazing scientists and engineers to turn this quest into a reality. In my role, I enjoy a unique perspective in viewing the relationship among three attributes of human cognition: monolingual text (X), audio or visual sensory signals, (Y) and multilingual (Z). At the intersection of all three, there's magic—what we call XYZ-code as illustrated in Figure 1—a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We believe XYZ-code enables us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. The goal is to have pretrained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today. Over the past five years, we have achieved human performance on benchmarks in conversational speech recognition, machine translation, conversational question answering, machine reading comprehension, and image captioning. These five breakthroughs provided us with strong signals toward our more ambitious aspiration to produce a leap in AI capabilities, achieving multi-sensory and multilingual learning that is closer in line with how humans learn and understand. I believe the joint XYZ-code is a foundational component of this aspiration, if grounded with external knowledge sources in the downstream AI tasks."
}
]
},
"tasks": [
{
"kind": "AbstractiveSummarization",
"taskName": "Text Abstractive Summarization Task 1",
}
]
}
'
Modifiez la commande comme ci-dessous :
- Remplacez la valeur
your-language-resource-keypar votre propre clé. - Remplacez la première partie de l’URL de la requête
your-language-resource-endpointpar votre propre URL de point de terminaison.
- Remplacez la valeur
Ouvrez une fenêtre d’invite de commandes (par exemple : BASH).
Collez la commande à partir de l’éditeur de texte dans la fenêtre d’invite de commandes, puis exécutez la commande.
Obtenez l’emplacement de l’opération (
operation-location) de l’en-tête de la réponse. La valeur ressemble à l’URL suivante :
https://<your-language-resource-endpoint>/language/analyze-text/jobs/12345678-1234-1234-1234-12345678?api-version=2022-10-01-preview
- Pour obtenir les résultats de la requête, utilisez la commande cURL suivante. Veillez à remplacer
<my-job-id>par la valeur d’ID numérique que vous avez reçue de l’en-tête de réponseoperation-locationprécédent :
curl -X GET https://<your-language-resource-endpoint>/language/analyze-text/jobs/<my-job-id>?api-version=2022-10-01-preview \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>"
Exemple de réponse JSON pour un résumé de texte par abstraction
{
"jobId": "cd6418fe-db86-4350-aec1-f0d7c91442a6",
"lastUpdateDateTime": "2022-09-08T16:45:14Z",
"createdDateTime": "2022-09-08T16:44:53Z",
"expirationDateTime": "2022-09-09T16:44:53Z",
"status": "succeeded",
"errors": [],
"displayName": "Text Abstractive Summarization Task Example",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "AbstractiveSummarizationLROResults",
"taskName": "Text Abstractive Summarization Task 1",
"lastUpdateDateTime": "2022-09-08T16:45:14.0717206Z",
"status": "succeeded",
"results": {
"documents": [
{
"summaries": [
{
"text": "Microsoft is taking a more holistic, human-centric approach to AI. We've developed a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We've achieved human performance on benchmarks in conversational speech recognition, machine translation, ...... and image captions.",
"contexts": [
{
"offset": 0,
"length": 247
}
]
}
],
"id": "1"
}
],
"errors": [],
"modelVersion": "latest"
}
}
]
}
}
| paramètre | Descriptif |
|---|---|
-X POST <endpoint> |
Spécifie le point de terminaison de votre ressource Language pour accéder à l’API. |
--header Content-Type: application/json |
Type de contenu pour l’envoi de données JSON. |
--header "Ocp-Apim-Subscription-Key:<key> |
Spécifie la clé de ressource Language pour accéder à l’API. |
-data |
Fichier JSON contenant les données que vous souhaitez transmettre avec votre requête. |
Les commandes cURL suivantes sont exécutées à partir d’un interpréteur de commandes bash. Modifiez ces commandes avec vos propres nom de ressource, clé de ressource et valeurs JSON. Essayez d’analyser des documents natifs en sélectionnant l’exemple de projet de code Personally Identifiable Information (PII) ou Document Summarization :
Exemple de document de résumé
Pour ce projet, vous avez besoin d’un document source chargé dans votre conteneur source. Vous pouvez télécharger notre exemple de document Microsoft Word ou Adobe PDF pour ce guide de démarrage rapide. La langue source est l’anglais.
Créer la requête POST
À l’aide de votre éditeur ou IDE préféré, créez un répertoire nommé
native-documentpour votre application.Créez un fichier json appelé document-summarization.json dans votre répertoire native-document.
Copiez et collez l’exemple de requête de Résumé des documents dans votre fichier
document-summarization.json. Remplacez{your-source-container-SAS-URL}et{your-target-container-SAS-URL}par les valeurs de votre instance de conteneurs de compte de stockage du portail Azure :
Exemple de requête
{
"tasks": [
{
"kind": "ExtractiveSummarization",
"parameters": {
"sentenceCount": 6
}
}
],
"analysisInput": {
"documents": [
{
"source": {
"location": "{your-source-blob-SAS-URL}"
},
"targets": {
"location": "{your-target-container-SAS-URL}"
}
}
]
}
}
Exécuter la requête POST
Avant d’exécuter la requête POST, remplacez {your-language-resource-endpoint} et {your-key} par la valeur de point de terminaison de votre instance de ressource Language du portail Azure.
Important
N’oubliez pas de supprimer la clé de votre code une fois que vous avez terminé, et ne la postez jamais publiquement. Pour la production, utilisez un moyen sécurisé de stocker et d’accéder à vos informations d’identification comme Azure Key Vault. Si vous souhaitez en savoir plus, veuillez consulter la rubriqueSécurité Azure AI services.
PowerShell
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" -i -X POST --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
invite de commandes/terminal
curl -v -X POST "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
Exemple de réponse :
HTTP/1.1 202 Accepted
Content-Length: 0
operation-location: https://{your-language-resource-endpoint}/language/analyze-documents/jobs/f1cc29ff-9738-42ea-afa5-98d2d3cabf94?api-version=2024-11-15-preview
apim-request-id: e7d6fa0c-0efd-416a-8b1e-1cd9287f5f81
x-ms-region: West US 2
Date: Thu, 25 Jan 2024 15:12:32 GMT
Réponse POST (jobId)
Vous recevez une réponse 202 (Réussite) incluant un en-tête en lecture seule Operation-Location. La valeur de cet en-tête contient un jobId qui peut être interrogé pour obtenir l’état de l’opération asynchrone et récupérer les résultats à l’aide d’une requête GET :
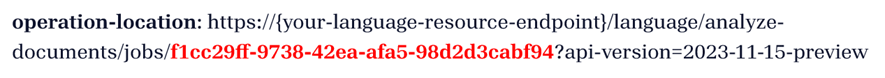
Obtenir les résultats d’analyse (requête GET)
Une fois que votre requête POST a réussi, interrogez l’en-tête operation-location retourné dans la requête POST pour afficher les données traitées.
Voici la structure de la requête GET :
GET {cognitive-service-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-previewAvant d’exécuter la commande, apportez les modifications suivantes :
Remplacez {jobId} par l’en-tête Operation-Location de la réponse POST.
Remplacez {your-language-resource-endpoint} et {your-key} par les valeurs de votre instance de service Language dans le portail Azure.
Requête GET
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" -i -X GET --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
curl -v -X GET "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
Examiner la réponse
Vous recevez une réponse 200 (Réussite) avec une sortie JSON. Le champ status indique le résultat de l’opération. Si l’opération n’est pas terminée, la valeur de status est « running » ou « notStarted ». Vous devrez alors appeler l’API une nouvelle fois, manuellement ou via un script. Nous vous recommandons d’attendre une seconde ou plus entre chaque appel.
Exemple de réponse
{
"jobId": "f1cc29ff-9738-42ea-afa5-98d2d3cabf94",
"lastUpdatedDateTime": "2024-01-24T13:17:58Z",
"createdDateTime": "2024-01-24T13:17:47Z",
"expirationDateTime": "2024-01-25T13:17:47Z",
"status": "succeeded",
"errors": [],
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "ExtractiveSummarizationLROResults",
"lastUpdateDateTime": "2024-01-24T13:17:58.33934Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "doc_0",
"source": {
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-input/input.pdf"
},
"targets": [
{
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-output/df6611a3-fe74-44f8-b8d4-58ac7491cb13/ExtractiveSummarization-0001/input.result.json"
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2023-02-01-preview"
}
}
]
}
}
Après la réussite de l’opération :
- Vous trouverez les documents analysés dans votre conteneur cible.
- La méthode POST réussie retourne un code de réponse
202 Acceptedindiquant que la requête de lots a été créée par le service. - La requête POST a retourné également des en-têtes de réponse, notamment
Operation-Locationqui fournit une valeur utilisée dans les requêtes GET suivantes.
Nettoyer les ressources
Si vous souhaitez nettoyer et supprimer un abonnement Azure AI services, vous pouvez supprimer la ressource ou le groupe de ressources. La suppression du groupe de ressources efface également les autres ressources qui y sont associées.