Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Avec Custom Speech, vous pouvez évaluer et améliorer l’exactitude de la Custom Speech pour vos applications et produits. Un modèle vocal personnalisé peut être utilisé pour la reconnaissance vocale en temps réel, la traduction vocale et la transcription par lots.
Prête à l’emploi, la Custom Speech utilise un modèle de langage universel comme modèle de base qui est entraîné avec des données appartenant à Microsoft et reflète la langue couramment parlée. Le modèle de base est préentraîné avec des dialectes et des phonétiques représentant divers domaines communs. Quand vous effectuez une requête de reconnaissance vocale, le modèle de base le plus récent pour chaque langue prise en charge est utilisé par défaut. Le modèle de base fonctionne bien dans la plupart des scénarios de Custom Speech.
Il est possible d’utiliser un modèle personnalisé pour augmenter le modèle de base dans le but d’améliorer la reconnaissance du vocabulaire propre à un domaine spécifique à l’application. Pour cela, vous entraînez le modèle en lui fournissant des données de texte. Vous pouvez aussi vous en servir pour améliorer la reconnaissance en fonction des conditions audio spécifiques de l’application en fournissant des données audio avec des transcriptions de référence.
Vous pouvez également entraîner un modèle avec du texte structuré lorsque les données suivent un pattern, spécifier des prononciations personnalisées, et personnaliser la mise en forme du texte d’affichage avec une normalisation du texte inversé personnalisée, une réécriture personnalisée et un filtrage des grossièretés personnalisé.
Comment cela fonctionne-t-il ?
Avec Custom Speech, vous pouvez charger vos propres données, tester et entraîner un modèle personnalisé, comparer l’exactitude entre les modèles, et déployer un modèle sur un point de terminaison personnalisé.
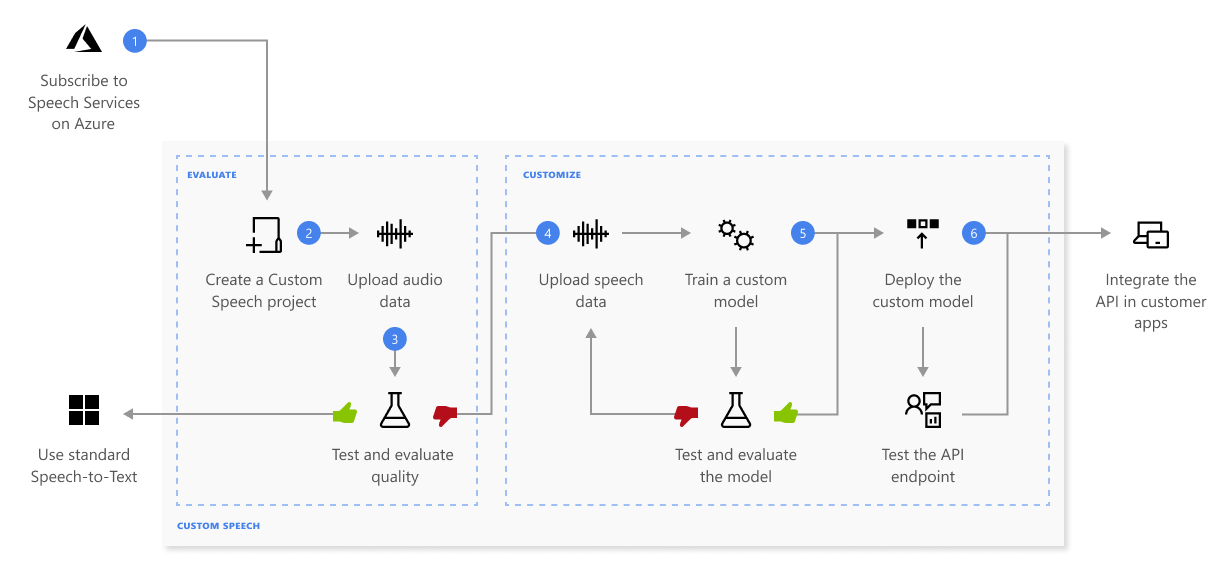
Voici des informations supplémentaires sur la série d’étapes présentées dans le diagramme précédent :
Créez un projet et choisissez un modèle. Utilisez une ressource Speech que vous créez dans le Portail Azure. Si vous entraînez un modèle personnalisé avec des données audio, sélectionnez une ressource de service dans une région avec du matériel dédié pour l’entraînement des données audio. Pour plus d’informations, consultez les notes de bas de page du tableau des régions.
Charger des données de test. Chargez des données de test pour évaluer l’offre de reconnaissance vocale pour vos applications, outils et produits.
Effectuer l’apprentissage d’un modèle. Fournissez des transcriptions écrites et du texte associé avec les données audio correspondantes. Il n’est pas obligatoire de tester un modèle avant et après l’entraînement, mais cela est recommandé.
Remarque
Vous payez pour l’utilisation du modèle vocal personnalisé et l’hébergement des points de terminaison. Vous serez également facturé pour la formation du modèle vocal personnalisé si le modèle de base a été créé le 1er octobre 2023 ou à une date ultérieure. La formation ne vous est pas facturée si le modèle de base a été créé avant octobre 2023. Pour plus d’informations, consultez Tarification d’Azure AI Speech et la section Frais d’adaptation dans le guide de migration de la reconnaissance vocale 3.2.
Tester la qualité de la reconnaissance. Utilisez Speech Studio pour lire le contenu audio chargé et inspecter la qualité de Custom Speech de vos données de test.
Tester le modèle quantitativement. Évaluez et améliorez l’exactitude du modèle de reconnaissance vocale. Le service Speech indique un taux d’erreurs du mot (WER) quantitatif, ce qui vous permet de déterminer si davantage d’entraînement est nécessaire.
Déployer un modèle. Une fois que vous êtes satisfait des résultats des tests, déployez le modèle sur un point de terminaison personnalisé. À l’exception de la transcription par lots, vous devez déployer un point de terminaison personnalisé pour utiliser un modèle de reconnaissance vocale.
Conseil
Un point de terminaison de déploiement hébergé n’est pas nécessaire pour utiliser Custom Speech avec l’API de transcription par lots. Vous pouvez conserver des ressources si le modèle vocal personnalisé est utilisé uniquement pour la transcription par lots. Pour plus d’informations, consultez les tarifs du service Speech.
Choisir votre modèle
Il existe quelques approches pour utiliser des modèles vocaux personnalisée :
- Le modèle de base fournit Custom Speech précise prête à l’emploi pour une gamme de scénarios. Les modèles de base sont régulièrement mis à jour pour améliorer la précision et la qualité. Si vous utilisez des modèles de base, nous vous recommandons d’utiliser les derniers modèles de base par défaut. Si une fonctionnalité de personnalisation requise n’est disponible qu’avec un modèle plus ancien, vous pouvez choisir un modèle de base plus ancien.
- Un modèle personnalisé augmente le modèle de base pour inclure le vocabulaire spécifique au domaine partagé dans toutes les zones du domaine personnalisé.
- Plusieurs modèles personnalisés peuvent être utilisés lorsque le domaine personnalisé a plusieurs zones, chacune avec un vocabulaire spécifique.
Un moyen recommandé de voir si le modèle de base suffit pour analyser la transcription produite à partir du modèle de base et à la comparer avec une transcription générée par un humain pour le même audio. Vous pouvez comparer les transcriptions et obtenir un score de taux d’erreur de mot (WER). Si le score WER est élevé, il est recommandé d’entraîner un modèle personnalisé pour qu’il puisse reconnaître les mots identifiés incorrectement.
Plusieurs modèles sont recommandés si le vocabulaire varie entre les zones du domaine. Par exemple, les commentateurs olympiques présentent différents événements, chacun associé à son propre champ lexical. Étant donné que chaque vocabulaire d’événement olympique diffère considérablement des autres, la création d’un modèle personnalisé spécifique à un événement augmente la précision en limitant les données d’énoncé par rapport à cet événement particulier. Par conséquent, le modèle n’a pas besoin de parcourir des données non liées pour faire une correspondance. Dans tous les cas, la formation nécessite toujours une diversité décente de données de formation. Incluez l’audio de divers commentateurs avec différents accents, genres, âges, etc.
Stabilité et cycle de vie des modèles
Un modèle de base ou personnalisé déployé sur un point de terminaison à l’aide d’un système vocal personnalisé est fixe jusqu’à ce que vous décidiez de le mettre à jour. La précision et la qualité de Custom Speech restent cohérentes, même quand un nouveau modèle de base est publié. Cela vous permet de verrouiller le comportement d’un modèle spécifique jusqu’à ce que vous décidiez d’utiliser un modèle plus récent.
Que vous entraîniez votre propre modèle ou utilisiez un instantané d’un modèle de base, vous pouvez utiliser le modèle pendant une durée limitée. Pour plus d’informations, consultez Cycle de vie des modèles et des points de terminaison.
IA responsable
Un système d’IA englobe non seulement la technologie, mais aussi ses utilisateurs, les personnes concernées et l’environnement dans lequel il est déployé. Lisez les notes de transparence pour en savoir plus sur l’utilisation et le déploiement d’une IA responsable dans vos systèmes.
- Note de transparence et cas d’usage
- Caractéristiques et limitations
- Intégration et utilisation responsable
- Données, confidentialité et sécurité