Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
La voix personnelle vous permet d’autoriser vos utilisateurs à obtenir la réplication générée par l’IA de leur voix en quelques secondes. Avec un énoncé oral et un bref échantillon vocal comme requête audio, vous pouvez créer une voix personnelle pour vos utilisateurs, et leur permettre de générer un message dans l’une des 90 langues prises en charge dans plus de 100 paramètres régionaux.
Remarque
La voix personnelle est disponible dans ces régions : Europe Ouest, USA Est, USA Ouest 2, Asie Sud-Est, et Asie Est. Pour plus d’informations sur les paramètres régionaux pris en charge, consultez la prise en charge des langues par la voix personnelle.
Le tableau suivant résume la différence entre la voix personnelle et la voix professionnelle.
| Comparaison | Voix personnelle | Voix professionnelle |
|---|---|---|
| Scénarios cibles | Les clients professionnels doivent créer une application pour permettre à leurs utilisateurs de créer et d’utiliser leur propre voix personnelle dans l’application. | Des scénarios professionnels comme des voix de marque et de personnages pour les bots conversationnels ou la lecture de contenu audio. |
| Cas d’usage | Elle est limitée aux cas d’usage. Consultez la note de transparence. | |
| Données d’entraînement | Veillez à suivre le code de conduite. | Apportez vos propres données. L’enregistrement dans un studio professionnel est recommandé. |
| Taille de données requise | Une minute de parole humaine. | 300 à 2 000 énoncés (environ 30 minutes à trois heures de parole humaine). |
| Durée d’entraînement | Moins de cinq secondes | Environ 20 à 40 heures de calcul |
| Qualité de la voix | Naturelle | Hautement naturelle |
| Prise en charge multilingue | Oui. La voix est en mesure de parler environ 100 langues, avec la détection automatique de la langue activée. | Oui. Vous devez sélectionner la fonctionnalité « Neural – Cross lingual » pour entraîner un modèle qui parle une langue différente des données d’entraînement. |
| Disponibilité | La démonstration sur Speech Studio est disponible lors de l’inscription. L’accès à l’API est limité aux clients éligibles et aux cas d’usage approuvés. Demandez l’accès via le formulaire d’entrée. | Vous ne pouvez utiliser le réglage de la voix professionnelle qu’après l’approbation de l’accès. L’accès au réglage de la voix professionnel est limité en fonction des critères d’éligibilité et d’utilisation. Demandez l’accès via le formulaire d’entrée. |
| Tarifs | Consultez les détails des prix ici1. | Consultez les détails des prix ici. |
| Exigences en matière d’IA responsable | Un énoncé oral de l’orateur est requis. Aucun cas d’usage non approuvé n’est autorisé. | La déclaration orale de l’orateur est requise. Aucun cas d’usage non approuvé n’est autorisé. |
1 Notez que la tarification de la voix personnelle ne sera visible que pour les régions du service où la fonctionnalité est disponible, c’est-à-dire, Europe Ouest, USA Est, USA Ouest 2, Asie Sud-Est, et Asie Est.
Essayer la démonstration
Si vous disposez d’une ressource S0, vous pouvez accéder à la démonstration de voix personnelle dans Speech Studio. Pour utiliser l’API de voix personnelle, vous pouvez demander l’accès ici.
Accédez à Speech Studio.
Sélectionnez la carte Voix personnelle.
Vous pouvez enregistrer votre voix et tester les exemples de sortie vocale dans différentes langues. La démonstration comprend un sous-ensemble des langues prises en charge par la voix personnelle.
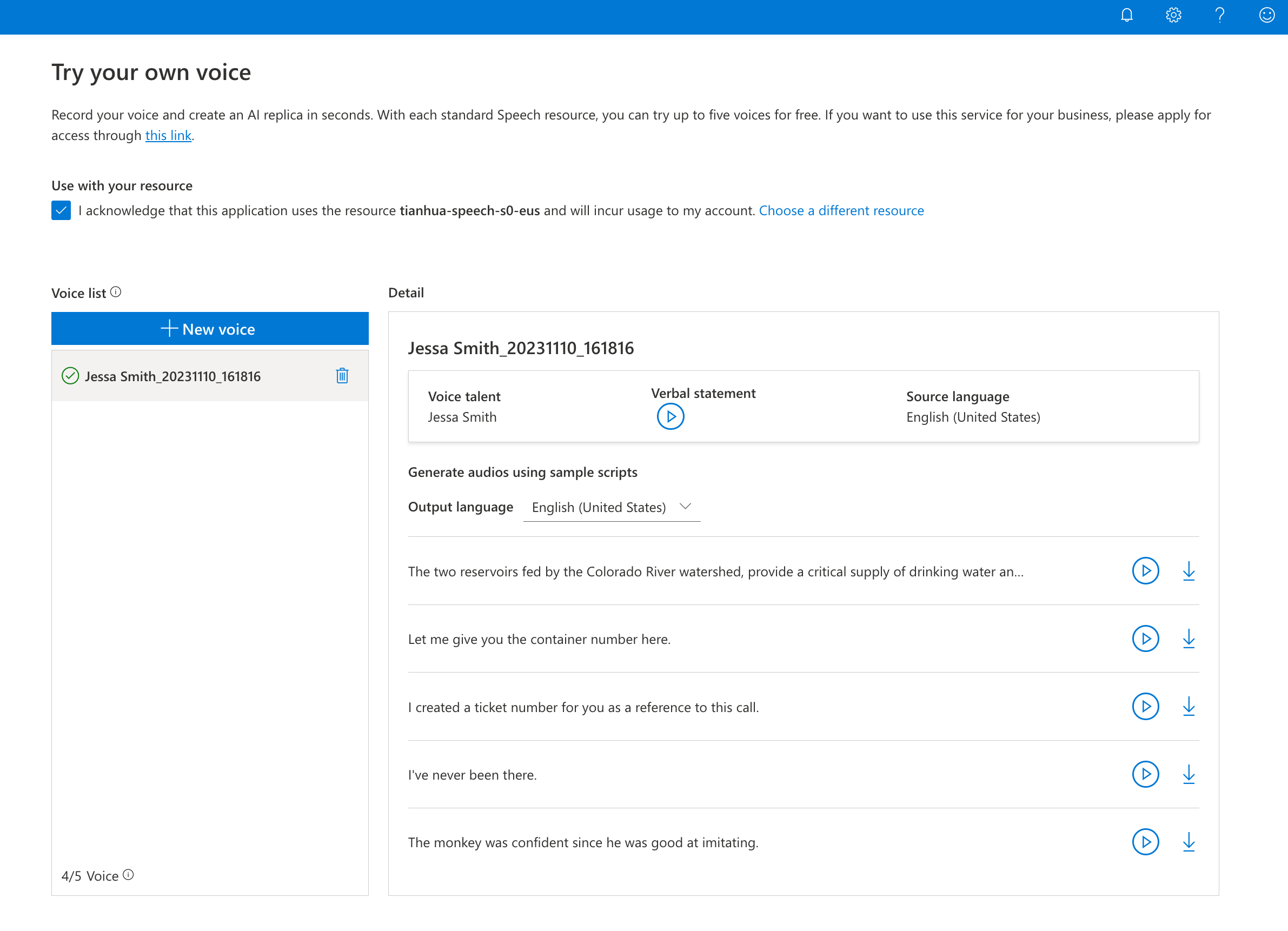

Procédure de création d’une voix personnelle
Pour démarrer, voici un résumé des étapes de création d’une voix personnelle :
- Créer un projet.
- Charger le fichier de consentement. Avec la fonctionnalité de voix personnelle, chaque voix doit être créée avec le consentement explicite de l’utilisateur. Une déclaration enregistrée de l’utilisateur (propriétaire de la ressource Azure AI Speech) acceptant que le client crée et utilise sa voix est requise.
- Obtenez un ID de profil d’orateur pour la voix personnelles. Vous obtenez un ID de profil d’orateur basé sur la déclaration de consentement oral de l’orateur et une requête audio. Les caractéristiques vocales de l’utilisateur sont encodées dans la propriété
speakerProfileIdutilisée pour la synthèse vocale.
Une fois que vous disposez d’une voix personnelle, vous pouvez l’utiliser pour synthétiser un message dans l’une des 91 langues prises en charge dans plus de 100 paramètres régionaux. Une balise de paramètres régionaux n’est pas obligatoire. La voix personnelle utilise la détection automatique de la langue au niveau de la phrase. Pour plus d’informations, consultez Utiliser la voix personnelle dans votre application.
Conseil
Consultez les exemples de code dans le dépôt du SDK Speech sur GitHub pour découvrir comment utiliser la voix personnelle dans votre application.
Documentation de référence
IA responsable
Nous nous soucions des personnes qui utilisent l’IA et qui en sont affectées autant que nous nous soucions de la technologie. Pour plus d’informations, consultez les notes de transparence sur l’IA responsable.
Étapes suivantes
- Créer un projet.
- En savoir plus sur la voix personnalisée dans la vue d’ensemble.
- Apprenez-en davantage sur Speech Studio dans la vue d’ensemble.