Qu’est-ce que l’Observabilité du réseau de conteneurs ?
L’Observabilité du réseau de conteneurs est une fonctionnalité de la suite Services avancés de mise en réseau de conteneurs. Elle vous fournit des outils avancés de surveillance et de diagnostic, offrant une visibilité inégalée sur vos charges de travail conteneurisées. Ces outils vous permettent d’identifier et de résoudre facilement les problèmes réseau, ce qui garantit des performances optimales pour vos applications.
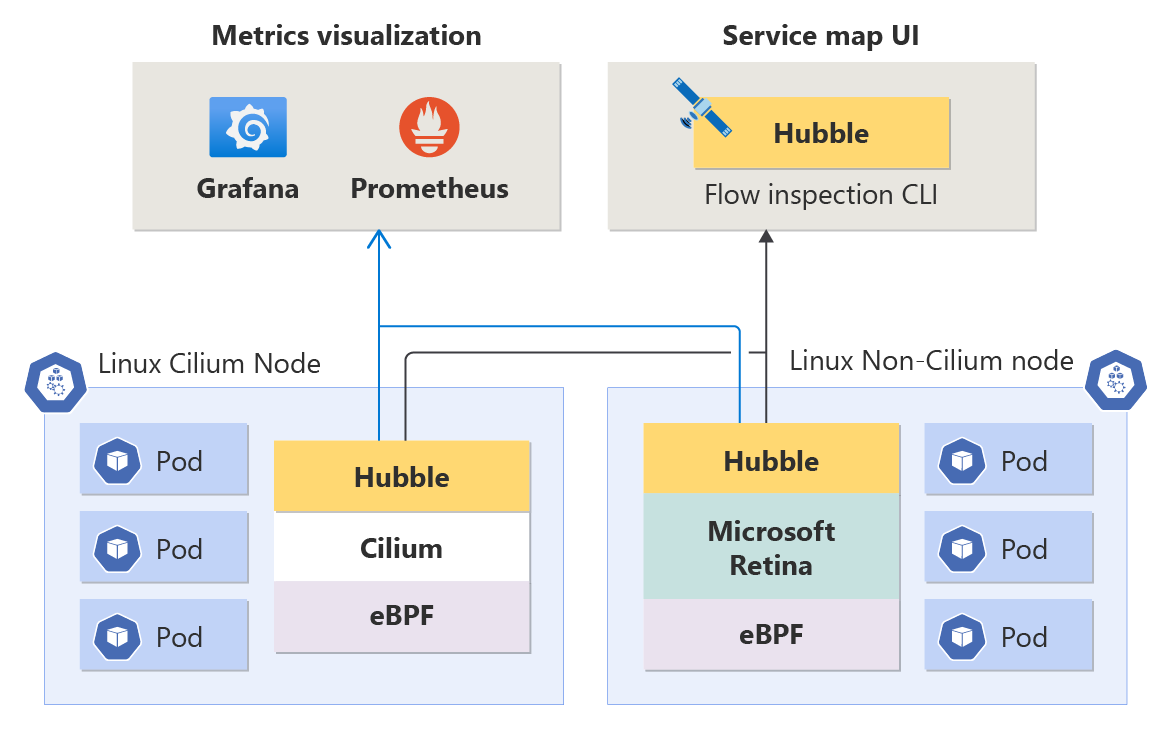
L’Observabilité du réseau de conteneurs est compatible avec toutes les charges de travail Linux et s’intègre de façon transparente à Hubble, que le plan de données sous-jacent soit Cilium ou non-Cilium (les deux sont pris en charge), garantissant une flexibilité pour les besoins en matière de réseau de vos conteneurs.
Remarque
Pour les scénarios de plan de données Cilium, l’Observabilité du réseau de conteneurs est disponible à partir de la version 1.29 de Kubernetes. L’Observabilité du réseau de conteneurs est prise en charge sur toutes les distributions Linux, y compris Azure Linux à compter de la version 2.0.
Fonctionnalités de l’Observabilité du réseau de conteneurs
L’Observabilité du réseau de conteneurs offre les fonctionnalités suivantes pour surveiller les problèmes liés au réseau dans votre cluster :
Métriques au niveau du nœud : bien comprendre l’intégrité du réseau de vos conteneurs au niveau du nœud est essentiel pour maintenir des performances optimales pour les applications. Ces métriques fournissent des insights sur le volume de trafic, les paquets supprimés, le nombre de connexions, etc. par nœud. Les métriques sont stockées au format Prometheus et vous pouvez donc les visualiser dans Grafana.
Métriques Hubble (Métriques DNS et au niveau des pods) : ces métriques Prometheus incluent des informations sur les pods source et de destination, ce qui vous permet d’identifier les problèmes liés au réseau à un niveau granulaire. Les métriques couvrent le volume de trafic, les paquets supprimés, les réinitialisations TCP, les flux de paquets L4/L7, etc. Il existe également des métriques DNS (actuellement seulement pour les plans de données non-Cilium), couvrant les erreurs DNS et les réponses manquantes à des requêtes DNS.
Journaux de flux Hubble : les journaux de flux donnent une visibilité détaillée de l’activité réseau de votre cluster. Toutes les communications vers et depuis les pods sont journalisées, ce qui vous permet d’investiguer les problèmes de connectivité au fil du temps. Les journaux de flux permettent de répondre à des questions telles que : le serveur a-t-il reçu la requête du client ? Quelle est la latence aller-retour entre la requête du client et la réponse du serveur ?
Interface CLI Hubble : l’interface de ligne de commande Hubble (CLI) peut récupérer les journaux de flux sur l’ensemble du cluster, avec un filtrage et une mise en forme personnalisables.
Interface utilisateur Hubble : l’interface utilisateur Hubble est une interface conviviale basée sur un navigateur pour explorer l’activité réseau du cluster. Il crée un graphique service-connexion basé sur les journaux de flux et affiche les journaux de flux pour l’espace de noms sélectionné. Les utilisateurs sont responsables de l’approvisionnement et de la gestion de l’infrastructure nécessaire pour exécuter l’interface utilisateur Hubble.
Avantages clés de l’Observabilité du réseau de conteneurs
Indépendante de CNI : prise en charge sur toutes les variantes d’Azure CNI, y compris kubenet.
Cilium et non-Cilium : offre une expérience uniforme et transparente sur les plans de données Cilium et non-Cilium.
Observabilité réseau basée sur eBPF : tire parti d’eBPF (extended Berkeley Packet Filter) pour les performances et la scalabilité pour identifier les goulots d’étranglement et les problèmes de congestion potentiels avant qu’ils aient un impact sur les performances des applications. Obtenez des insights sur les indicateurs d’intégrité réseau clés, notamment le volume de trafic, les paquets supprimés et les informations de connexion.
Visibilité approfondie de l’activité réseau : comprenez bien comment vos applications communiquent entre elles via des journaux de flux réseau détaillés.
Options de stockage et de visualisation simplifiées des métriques : choisissez entre :
- Prometheus et Grafana managé par Azure : Azure gère l’infrastructure et la maintenance, ce qui permet aux utilisateurs de se concentrer sur la configuration des métriques et leur visualisation.
- BYO (Apportez votre propre) Prometheus et Grafana : les utilisateurs déploient et configurent leurs propres instances et gèrent l’infrastructure sous-jacente.
Métriques
Métriques au niveau des nœuds
Les métriques suivantes sont agrégées par nœud. Toutes les métriques incluent des étiquettes :
clusterinstance(Nom du nœud)
Pour les scénarios de plan de données Cilium, l’Observabilité du réseau de conteneurs fournit des métriques seulement pour Linux ; Windows n’est actuellement pas pris en charge. Cilium expose plusieurs métriques, dont les suivantes, utilisées par l’Observabilité du réseau de conteneurs.
| Nom de métrique | Description | Étiquettes supplémentaires | Linux | Windows |
|---|---|---|---|---|
| cilium_forward_count_total | Nombre total de paquets transférés | direction |
✅ | ❌ |
| cilium_forward_bytes_total | Nombre total d’octets transférés | direction |
✅ | ❌ |
| cilium_drop_count_total | Nombre total de paquets ignorés | direction, reason |
✅ | ❌ |
| cilium_drop_bytes_total | Nombre total d’octets ignorés | direction, reason |
✅ | ❌ |
Métriques au niveau des pods (Métriques Hubble)
Les métriques suivantes sont agrégées par pod (les informations de nœud sont conservées). Toutes les métriques incluent des étiquettes :
clusterinstance(Nom du nœud)sourceoudestination
Pour le trafic sortant, il y aura une étiquette source avec l’espace de noms/le nom du pod source.
Pour le trafic entrant, il y aura une étiquette destination avec l’espace de noms/le nom du pod de destination.
| Nom de métrique | Description | Étiquettes supplémentaires | Linux | Windows |
|---|---|---|---|---|
| hubble_dns_queries_total | Nombre total de demandes DNS par requête | source ou destination, query, qtypes (type de requête) |
✅ | ❌ |
| hubble_dns_responses_total | Nombre total de réponses DNS par requête/réponse | source ou destination, query, qtypes (type de requête), rcode (code de retour), ips_returned (nombre d’adresses IP) |
✅ | ❌ |
| hubble_drop_total | Nombre total de paquets ignorés | source ou destination, protocol, reason |
✅ | ❌ |
| hubble_tcp_flags_total | Nombre total de paquets TCP par indicateur. | source ou destination, flag |
✅ | ❌ |
| hubble_flows_processed_total | Nombre total de flux réseau traités (trafic L4/L7) | source ou destination, protocol, verdict, type, subtype |
✅ | ❌ |
Limites
- Les métriques au niveau des pods sont disponibles seulement sur Linux.
- Le plan de données Cilium est pris en charge à partir de Kubernetes version 1.29.
- Les étiquettes de métrique peuvent avoir des différences subtiles entre les clusters Cilium et non-Cilium.
- Pour les clusters Cilium, les métriques DNS sont uniquement disponibles pour les pods qui ont des stratégies réseau Cilium configurées sur leurs clusters.
- Les journaux de flux ne sont actuellement pas disponibles dans le cloud en environnement isolé.
- Le relais Hubble peut se bloquer si l’un des agents de nœud hubble tombe en panne et peut entraîner des interruptions dans l’interface CLI Hubble.
Mise à l’échelle
Prometheus et Grafana managés par Azure, imposent des limites d’échelle spécifiques au service. Pour plus d’informations, consultez l’article Supprimer les métriques Prometheus à grande échelle dans Azure Monitor.
Tarification
Important
Services avancés de mise en réseau de conteneurs est une offre payante. Pour plus d’informations sur la tarification, consultez Tarification des services avancés de mise en réseau de conteneurs.
Étapes suivantes
- Pour créer un cluster AKS avec l’Observabilité du réseau de conteneurs, consultez configurer l’Observabilité du réseau de conteneurs pour Azure Kubernetes Service (AKS).

Azure Kubernetes Service