Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Lors de l’exécution d’applications dans Azure Kubernetes Service (AKS), vous devrez peut-être augmenter ou diminuer activement la quantité de ressources de calcul dans votre cluster. Lorsque vous modifiez le nombre d’instances d’application dont vous disposez, vous devrez peut-être modifier le nombre de nœuds Kubernetes sous-jacents. Vous devrez peut-être également approvisionner un grand nombre d’autres instances d’application.
Cet article présente les principaux concepts de mise à l’échelle des applications AKS, notamment la mise à l’échelle manuelle des pods ou des nœuds, l’utilisation de la mise à l’échelle automatique des pods horizontaux, l’utilisation de la mise à l’échelle automatique de cluster et l’intégration à Azure Container Instances (ACI).
Mettre à l’échelle des pods ou des nœuds manuellement
Vous pouvez mettre à l’échelle des réplicas, des pods et des nœuds manuellement pour tester la façon dont votre application répond à une modification au niveau des ressources disponibles et de l’état. La mise à l’échelle manuelle des ressources vous permet de définir une quantité définie de ressources à utiliser, comme le nombre de nœuds, pour maintenir un coût fixe. Pour effectuer une mise à l’échelle manuelle, vous définissez un nombre de répliques ou de nœuds. L'API Kubernetes planifie ensuite la création de pods supplémentaires ou le drainage de nœuds en fonction du nombre de réplicas ou de nœuds.
Lorsque vous effectuez un scale-down de nœuds, l’API Kubernetes appelle l’API De calcul Azure appropriée liée au type de calcul utilisé par votre cluster. Par exemple, pour les clusters basés sur des groupes de machines virtuelles identiques, l’API Groupes de machines virtuelles identiques détermine les nœuds à supprimer. Pour en savoir plus sur la façon dont les nœuds sont sélectionnés pour la suppression lors d’un scale-down, consultez les Questions fréquentes (FAQ) sur VMSS.
Pour bien commencer avec la mise à l’échelle manuelle des nœuds, consultez Mettre à l’échelle manuellement des nœuds dans un cluster AKS. Pour mettre à l’échelle manuellement le nombre de pods, consultez Commande kubectl scale.
Autoscaler de pods élastique
Kubernetes utilise la mise à l’échelle automatique horizontale de pods pour superviser la demande en ressources et adapter automatiquement le nombre de pods. Par défaut, HPA vérifie l’API Metrics toutes les 15 secondes pour toute modification requise du nombre de réplicas, tandis que l’API Metrics récupère les données de Kubelet toutes les 60 secondes. Par conséquent, HPA est mis à jour toutes les 60 secondes. Lorsque des changements sont requis, le nombre de répliques est ajusté en conséquence. HPA fonctionne avec des clusters AKS qui ont déployé Metrics Server pour Kubernetes version 1.8 et ultérieure.
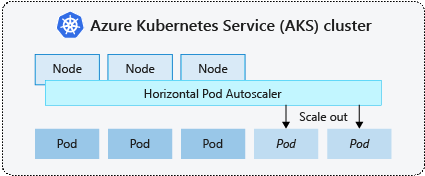
Lorsque vous configurez le HPA pour un déploiement donné, vous définissez le nombre minimal et maximal de réplicas qui peuvent s’exécuter. Vous définissez également la métrique à surveiller et sur laquelle baser les décisions de mise à l'échelle, telles que l'utilisation du processeur.
Pour vous familiariser avec l’autoscaler de pods élastique dans AKS, consultez Mettre à l’échelle des pods dans AKS.
Ralentissement des événements de mise à l’échelle
Étant donné que le HPA est mis à jour efficacement toutes les 60 secondes, les opérations de mise à l'échelle précédentes n'ont peut-être pas été complétées avec succès avant qu'une autre vérification ne soit effectuée. Ce comportement peut pousser le HPA à modifier le nombre de réplicas avant même que l’événement de mise à l’échelle précédent ait pu recevoir la charge de travail de l’application, et que les demandes en ressources soient ajustées en conséquence.
Pour réduire le nombre d’événements de concurrence, une valeur de délai est définie. Cette valeur précise la durée pendant laquelle le HPA doit attendre, entre la fin d’un événement de mise à l’échelle et le déclenchement d’un autre événement de mise à l’échelle. Ce comportement permet au nouveau nombre de réplicas d’être pris en compte, et à l’API de métriques de refléter la charge de travail distribuée. Il n’existe aucun délai pour les événements de scale-up à partir de Kubernetes 1.12. Toutefois, le délai par défaut sur les événements de scale-down est de 5 minutes.
Autoscaler de cluster
Pour répondre aux demandes changeantes de pods, la mise à l’échelle automatique de cluster Kubernetes ajuste le nombre de nœuds en fonction des ressources de calcul demandées dans le pool de nœuds. Par défaut, l’autoscaler de cluster vérifie le serveur d’API de métriques toutes les 10 secondes à la recherche de toute modification à apporter au nombre de nœuds. Si l’autoscaler de cluster détermine qu’un changement est nécessaire, le nombre de nœuds de votre cluster AKS augmente ou diminue selon le cas. L’autoscaler de cluster fonctionne avec les clusters AKS avec RBAC Kubernetes qui exécutent Kubernetes versions 1.10.x ou ultérieures.
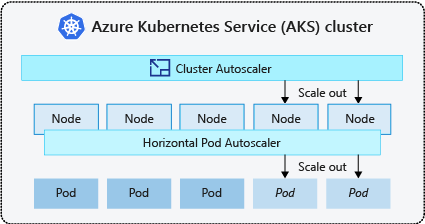
La mise à l’échelle automatique de cluster est généralement utilisé parallèlement à la mise à l’échelle automatique horizontale de pods. Lorsqu’ils sont combinés, la mise à l’échelle horizontale automatique de pods augmente ou diminue le nombre de pods en fonction de l’exigence des applications, tandis que l’autoscaler de cluster ajuste à proportion le nombre de nœuds pour exécuter davantage de pods.
Pour vous familiariser avec la mise à l’échelle automatique de cluster dans AKS, consultez mise à l’échelle automatique de cluster sur AKS.
Événements de scale-out
Si les ressources de calcul d’un nœud sont insuffisantes pour l’exécution d’un pod demandé, ce pod ne peut pas avancer dans le processus de planification. Le pod ne peut pas démarrer, sauf si d’autres ressources de calcul sont disponibles dans le pool de nœuds.
Lorsque l’autoscaler de cluster remarque que des pods ne sont pas panifiables en raison de contraintes liées aux ressources du pool de nœuds, le nombre de nœuds à l’intérieur de ce pool est augmenté pour fournir les ressources de calcul supplémentaires. Lorsque les nœuds sont correctement déployés et utilisables au sein du pool de nœuds, les pods sont alors planifiés pour s’exécuter sur eux.
Si votre application doit être mise à l’échelle rapidement, certains pods peuvent rester en attente d'être programmés jusqu’à ce que d’autres nœuds déployés par l’autoscaler de cluster puissent accepter les pods programmés. Pour les applications qui présentent des demandes de croissance extrêmement forte et rapide, vous pouvez mettre à l’échelle au moyen de nœuds virtuels et de Azure Container Instances.
Événements de scale-in
L’autoscaler de cluster surveille également le statut de planification des pods pour les nœuds qui n’ont pas reçu récemment de nouvelles demandes de planification. Ce scénario indique que le pool de nœuds détient plus de ressources de calcul que nécessaire et que le nombre de nœuds peut être réduit. Par défaut, les nœuds qui atteignent le seuil où ils ne sont plus nécessaires pendant 10 minutes sont programmés pour être supprimés. Lorsque cette situation se produit, les pods sont planifiés pour s’exécuter sur d’autres nœuds au sein du pool de nœuds tandis que l’autoscaler de cluster réduit le nombre de nœuds.
Vos applications peuvent rencontrer quelques perturbations au moment où les pods sont planifiés sur des nœuds différents et que l’autoscaler de cluster diminue le nombre de nœuds. Pour limiter ces perturbations, évitez les applications qui utilisent une seule instance de pod.
Mise à l’échelle automatique basée sur les événements Kubernetes (KEDA)
Kubernetes Event-driven Autoscaling (KEDA) est un composant open source de mise à l’échelle automatique pilotée par les événements pour les charges de travail. Les charges de travail sont mises à l’échelle de manière dynamique en fonction du nombre d’événements reçus. KEDA étend Kubernetes avec une définition de ressource personnalisée (CRD, Custom Resource Definition), appelée ScaledObject, qui décrit la façon dont les applications doivent être mises à l’échelle en réponse à un trafic spécifique.
La mise à l’échelle KEDA est utile dans les scénarios où les charges de travail reçoivent des pics de trafic ou gèrent des volumes élevés de données. KEDA diffère de la mise à l’échelle automatique des pods horizontaux, car KEDA est piloté par les événements et est mis à l’échelle en fonction du nombre d’événements, tandis que HPA est piloté par les métriques basées sur l’utilisation des ressources (par exemple, le processeur et la mémoire).
Pour commencer à utiliser le module complémentaire KEDA dans AKS, consultez la vue d’ensemble de KEDA.
Approvisionnement automatique des nœuds
Le provisionnement automatique de nœud (préversion) (NAP) utilise le projet Karpenter open source qui déploie, configure et gère automatiquement Karpenter sur votre cluster AKS. NAP provisionne dynamiquement des nœuds en fonction des besoins en ressources de pod en attente ; il sélectionne automatiquement la référence (SKU) de machine virtuelle optimale et la quantité pour répondre à la demande en temps réel.
NAP prend une liste prédéfinie des références SKU de machine virtuelle comme point de départ pour déterminer la référence SKU la mieux adaptée aux charges de travail en attente. Pour un contrôle plus précis, les utilisateurs peuvent définir les limites supérieures des ressources utilisées par un pool de nœuds et les préférences de l’endroit où les charges de travail doivent être planifiées s’il existe plusieurs pools de nœuds.
Mise à l’échelle et protections du plan de contrôle
Kubernetes a une enveloppe d’échelle multidimensionnelle avec chaque type de ressource représentant une dimension. Toutes les ressources ne sont pas les mêmes. Par exemple, les espions sont généralement définis sur des secrets. Ces secrets entraînent des appels de liste à kube-apiserver qui ajoutent des coûts et une charge disproportionnée plus élevée au plan de contrôle par rapport aux ressources sans espions.
Le plan de contrôle gère toute la mise à l’échelle des ressources dans le cluster, de sorte que plus vous mettez à l’échelle le cluster dans une dimension donnée, moins vous pouvez effectuer une mise à l’échelle dans d’autres dimensions. Par exemple, l’exécution de centaines de milliers de pods dans un cluster AKS a un impact sur la quantité d’attrition des pods (mutations de pods par seconde) que le plan de contrôle peut prendre en charge. Reportez-vous aux meilleures pratiques.
AKS met automatiquement à l’échelle les composants du plan de contrôle en fonction de signaux clés tels que le nombre total de cœurs dans le cluster et la pression de mémoire ou de processeur sur les composants du plan de contrôle.
Pour vérifier si le plan de contrôle a été mis à l’échelle, vérifiez le ConfigMap nommé « large-cluster-control-plane-scaling-status »
kubectl describe configmap large-cluster-control-plane-scaling-status -n kube-system
Protections du plan de contrôle
Si la mise à l’échelle du serveur d’API ne la stabilise pas automatiquement dans des scénarios de charge élevée, AKS déploie un service de protection du serveur d’API managé. Cette protection agit comme un mécanisme de dernier recours pour protéger le serveur d’API en limitant les demandes clientes non système et en empêchant le plan de contrôle de devenir complètement insensible. Les appels critiques système au serveur d’API à partir de composants tels que kubelet continueront de fonctionner normalement.
Pour vérifier si la protection du serveur d’API managée a été appliquée, vérifiez la présence de « aks-managed-apiserver-guard » FlowSchema et PriorityLevelConfiguration.
kubectl get flowschemas
kubectl get prioritylevelconfigurations
Reportez-vous au guide de résolution des problèmes du serveur d’API et etcd si les FlowSchema et PriorityLevelConfiguration « aks-managed-apiserver-guard » ont été appliqués sur le cluster pour une atténuation rapide.
Intégration à Azure Container Instances (ACI)
Pour faire évoluer rapidement votre cluster AKS, vous pouvez intégrer Azure Container Instances (ACI). Kubernetes dispose de composants intégrés pour mettre à l’échelle le nombre de réplicas et de nœuds. Toutefois, si votre application doit effectuer une mise à l’échelle rapide, l’autoscaler de pod horizontal peut planifier plus de pods que les ressources de calcul existantes dans le pool de nœuds. S’il est configuré, ce scénario déclenche ensuite le programme de mise à l’échelle automatique du cluster pour déployer davantage de nœuds dans le pool de nœuds, mais cela peut prendre quelques minutes pour que ces nœuds puissent correctement provisionner et autoriser le planificateur Kubernetes à exécuter des pods sur eux.
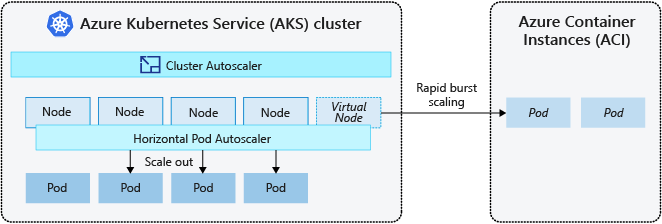
ACI vous permet de déployer rapidement des instances de conteneur sans surcharge d’infrastructure supplémentaire. Lorsque vous vous connectez à AKS, ACI devient une extension logique et sécurisée de votre cluster AKS. Le composant nœuds virtuels, qui est basé sur virtual Kubelet, est installé dans votre cluster AKS qui présente ACI comme un nœud Kubernetes virtuel. Kubernetes peut alors planifier les pods s’exécutant en tant qu’instances ACI via des nœuds virtuels, et non en tant que pods sur des nœuds de machine virtuelle, directement dans votre cluster AKS.
Votre application n’a besoin d’aucune modifications pour utiliser les nœuds virtuels. Vos déploiements peuvent mettre à l’échelle dans AKS et ACI, et sans aucun délai car la mise à l’échelle automatique de cluster déploie les nouveaux nœuds dans votre cluster AKS.
Les nœuds virtuels sont déployés sur un autre sous-réseau, dans le même réseau virtuel que votre cluster AKS. Cette configuration de réseau virtuel sécurise le trafic entre ACI et AKS. À l’instar d’un cluster AKS, une instance ACI est une ressource de calcul logique, sécurisée, isolée des autres utilisateurs.
Étapes suivantes
Pour bien commencer la mise à l’échelle des applications, consultez les ressources suivantes :
- Mettre à l’échelle des pods ou des nœuds manuellement
- Utiliser l’autoscaler de pods élastique
- Utiliser l’autoscaler de cluster
- Utiliser le module complémentaire Kubernetes Event-driven Autoscaling (KEDA)
Pour plus d’informations sur les concepts fondamentaux de Kubernetes et d’AKS, consultez les articles suivants :