Antimodèle Serveur frontal occupé
L’exécution d’un travail asynchrone sur un grand nombre de threads d’arrière-plan peut priver les tâches de premier plan simultanées de ressources, donnant lieu à des temps de réponse inacceptables.
Description du problème
Les tâches nécessitant de nombreuses ressources peuvent augmenter les temps de réponse pour les requêtes utilisateur et entraîner une latence élevée. Pour améliorer les temps de réponse, une solution consiste à décharger une tâche nécessitant de nombreuses ressources vers un thread distinct. Cette approche permet à l’application de rester réactive pendant que le traitement est réalisé en arrière-plan. Cependant, les tâches exécutées sur un thread d’arrière-plan consomment toujours des ressources. Si ces tâches sont trop nombreuses, elles peuvent priver les threads qui traitent les requêtes de ressources.
Notes
Le terme ressource peut englober un grand nombre de choses, notamment l’utilisation du processeur, l’occupation de la mémoire et les E/S réseau ou de disque.
Ce problème se produit généralement quand une application est développée en tant que bloc de code monolithique, avec toute la logique métier regroupée dans un niveau unique partagé avec la couche de présentation.
Voici un exemple faisant appel à ASP.NET qui illustre le problème. Vous trouverez l’exemple complet ici.
public class WorkInFrontEndController : ApiController
{
[HttpPost]
[Route("api/workinfrontend")]
public HttpResponseMessage Post()
{
new Thread(() =>
{
//Simulate processing
Thread.SpinWait(Int32.MaxValue / 100);
}).Start();
return Request.CreateResponse(HttpStatusCode.Accepted);
}
}
public class UserProfileController : ApiController
{
[HttpGet]
[Route("api/userprofile/{id}")]
public UserProfile Get(int id)
{
//Simulate processing
return new UserProfile() { FirstName = "Alton", LastName = "Hudgens" };
}
}
La méthode
Postdans le contrôleurWorkInFrontEndimplémente une opération HTTP POST. Cette opération simule une tâche de longue durée nécessitant une utilisation importante du processeur. Le travail est réalisé sur un thread distinct afin de favoriser l’exécution rapide de l’opération POST.La méthode
Getdans le contrôleurUserProfileimplémente une opération HTTP GET. Cette méthode nécessite une utilisation beaucoup moins importante du processeur.
La principale préoccupation concerne les besoins en ressources de la méthode Post. Bien que cette méthode place le travail sur un thread d’arrière-plan, le travail est toujours susceptible de consommer un nombre considérable de ressources processeur. Ces ressources sont partagées avec les autres opérations exécutées par les autres utilisateurs simultanés. Si un nombre modéré d’utilisateurs envoient cette requête en même temps, les performances globales risquent d’être dégradées, entraînant un ralentissement de toutes les opérations. Les utilisateurs peuvent par exemple être confrontés à une latence importante pour la méthode Get.
Comment corriger le problème
Déplacez les processus qui consomment de nombreuses ressources sur un serveur principal distinct.
Avec cette approche, le serveur frontal place les tâches nécessitant de nombreuses ressources dans une file d’attente. Le serveur principal récupère les tâches à des fins de traitement asynchrone. La file d’attente assure également le nivellement de la charge, mettant les requêtes en tampon pour le serveur principal. Si la file d’attente devient trop longue, vous pouvez configurer la mise à l’échelle automatique pour effectuer un scale-out du serveur principal.
Voici une version révisée du code précédent. Dans cette version, la méthode Post place un message dans une file d’attente Service Bus.
public class WorkInBackgroundController : ApiController
{
private static readonly QueueClient QueueClient;
private static readonly string QueueName;
private static readonly ServiceBusQueueHandler ServiceBusQueueHandler;
public WorkInBackgroundController()
{
var serviceBusConnectionString = ...;
QueueName = ...;
ServiceBusQueueHandler = new ServiceBusQueueHandler(serviceBusConnectionString);
QueueClient = ServiceBusQueueHandler.GetQueueClientAsync(QueueName).Result;
}
[HttpPost]
[Route("api/workinbackground")]
public async Task<long> Post()
{
return await ServiceBusQueueHandler.AddWorkLoadToQueueAsync(QueueClient, QueueName, 0);
}
}
Le serveur principal extrait les messages de la file d’attente Service Bus et effectue le traitement.
public async Task RunAsync(CancellationToken cancellationToken)
{
this._queueClient.OnMessageAsync(
// This lambda is invoked for each message received.
async (receivedMessage) =>
{
try
{
// Simulate processing of message
Thread.SpinWait(Int32.MaxValue / 1000);
await receivedMessage.CompleteAsync();
}
catch
{
receivedMessage.Abandon();
}
});
}
Considérations
- Cette approche rend l’application un peu plus complexe. Vous devez gérer la mise en file d’attente et le retrait de la file d’attente de manière sûre pour éviter la perte de requêtes en cas de défaillance.
- L’application devient dépendante d’un service supplémentaire pour la file d’attente de messages.
- L’environnement de traitement doit être suffisamment évolutif pour gérer la charge de travail attendue et atteindre les objectifs de débit requis.
- Même si cette approche devrait normalement améliorer la réactivité globale, l’exécution des tâches déplacées sur le serveur principal peut prendre plus de temps.
Comment détecter le problème
Les symptômes d’un serveur frontal occupé incluent une latence élevée pendant l’exécution des tâches nécessitant de nombreuses ressources. Les utilisateurs finals sont susceptibles de signaler des temps de réponse plus longs que d’habitude ou des échecs causés par l’expiration du délai d’attente des services. Ces échecs peuvent également renvoyer des erreurs HTTP 500 (serveur interne) ou HTTP 503 (service indisponible). Examinez les journaux d’événements du serveur web, qui contiennent probablement des informations plus détaillées sur les causes et les circonstances de ces erreurs.
Vous pouvez procéder de la manière suivante pour identifier ce problème :
- Analysez le processus du système de production afin d’identifier les points où les temps de réponse augmentent.
- Examinez les données de télémétrie enregistrées à ces points pour déterminer les opérations exécutées en même temps et les ressources utilisées.
- Recherchez les corrélations entre les temps de réponse médiocres et les volumes et combinaisons d’opérations observés à ces moments-là.
- Procédez à un test de charge de chaque opération suspectée pour identifier les opérations qui consomment de nombreuses ressources et nuisent ainsi aux autres opérations.
- Révisez le code source de ces opérations afin de déterminer les raisons potentielles de cette consommation excessive de ressources.
Exemple de diagnostic
Les sections suivantes appliquent ces étapes à l’exemple d’application décrit précédemment.
Identifier les points de ralentissement
Instrumentez chaque méthode pour suivre la durée des différentes requêtes et les ressources consommées par celles-ci. Ensuite, analysez l’application en production. Vous bénéficierez ainsi d’une vue d’ensemble de la manière dont les requêtes s’opposent. Pendant les périodes de forte activité, les requêtes gourmandes en ressources et dont l’exécution est lente sont susceptibles d’affecter d’autres opérations. Il est possible de constater ce comportement en supervisant le système et en constatant la baisse des performances.
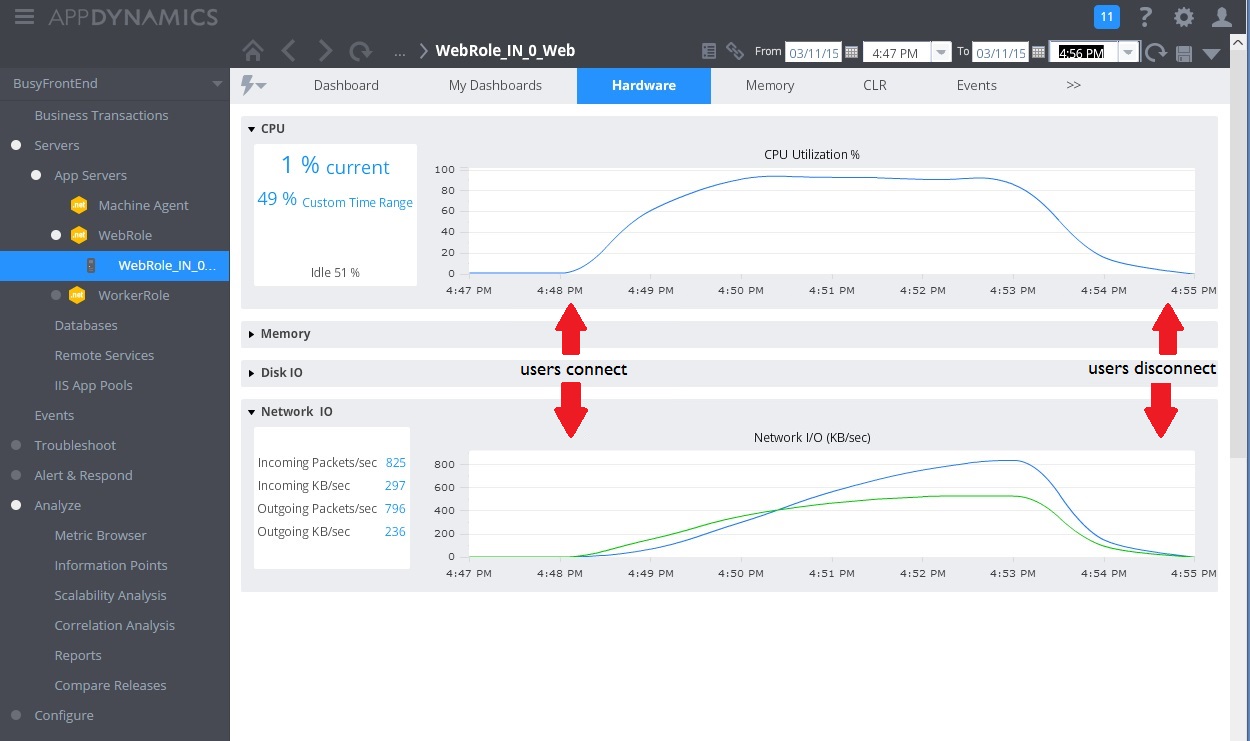
L’image suivante illustre un tableau de bord d’analyse (nous avons utilisé AppDynamics pour nos tests). Au départ, le système présente une charge faible. Ensuite, les utilisateurs commencent à envoyer des requêtes pour la méthode GET au contrôleur UserProfile. Les performances sont relativement bonnes jusqu'à ce que d’autres utilisateurs commencent à émettre des requêtes pour la méthode POST à destination du contrôleur WorkInFrontEnd. À ce moment-là, les temps de réponse augmentent considérablement (première flèche). Les temps de réponse s’améliorent uniquement après la diminution du volume de requêtes envoyées au contrôleur WorkInFrontEnd (seconde flèche).
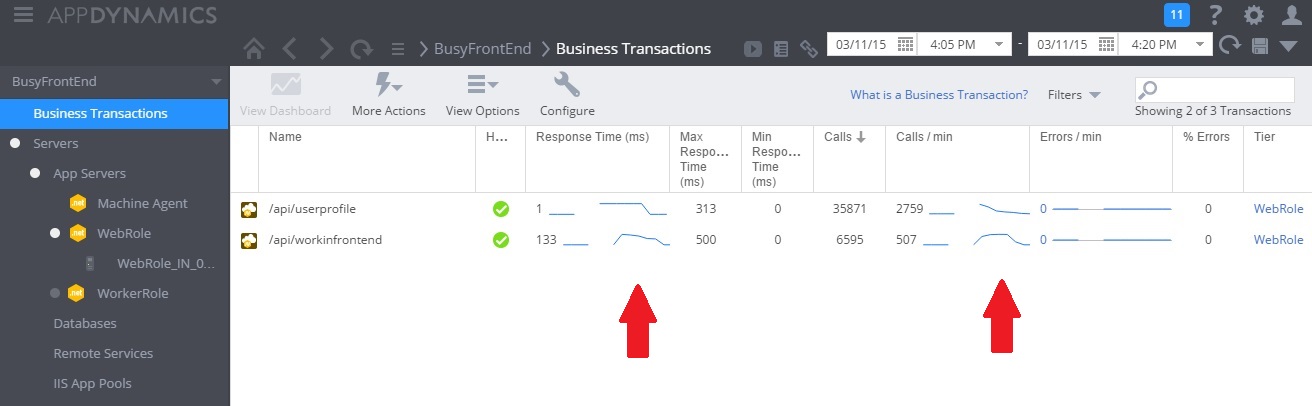
Examiner les données de télémétrie et rechercher les corrélations
L’image suivante illustre quelques-unes des mesures collectées pour surveiller l’utilisation des ressources pendant le même intervalle de temps. Au départ, peu d’utilisateurs accèdent au système. À mesure que d’autres utilisateurs se connectent, l’utilisation du processeur devient très élevée (100 %). Par ailleurs, vous remarquerez qu’initialement, le taux d’E/S réseau augmente parallèlement à l’utilisation du processeur. Cependant, une fois que l’utilisation du processeur est au plus haut, les E/S réseau diminuent. Cela s’explique par le fait que le système peut seulement traiter un nombre relativement restreint de requêtes une fois que le processeur a atteint sa capacité maximale. À mesure que les utilisateurs se déconnectent, la charge du processeur diminue.
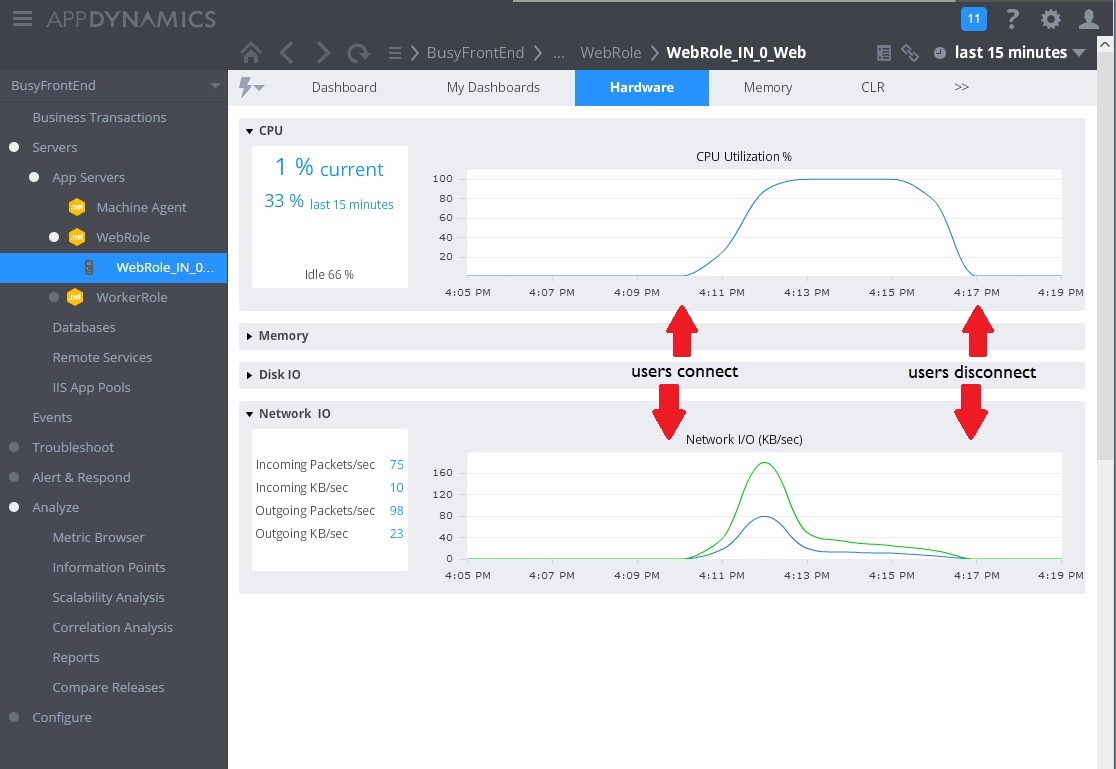
À ce stade, la méthode Post dans le contrôleur WorkInFrontEnd semble être un candidat de choix pour un examen plus approfondi. Un travail supplémentaire dans un environnement contrôlé est nécessaire pour confirmer cette hypothèse.
Effectuer des tests de charge
L’étape suivante consiste à effectuer des tests dans un environnement contrôlé. Par exemple, vous pouvez exécuter une série de tests de charge qui incluent puis omettent successivement chaque requête pour observer les effets.
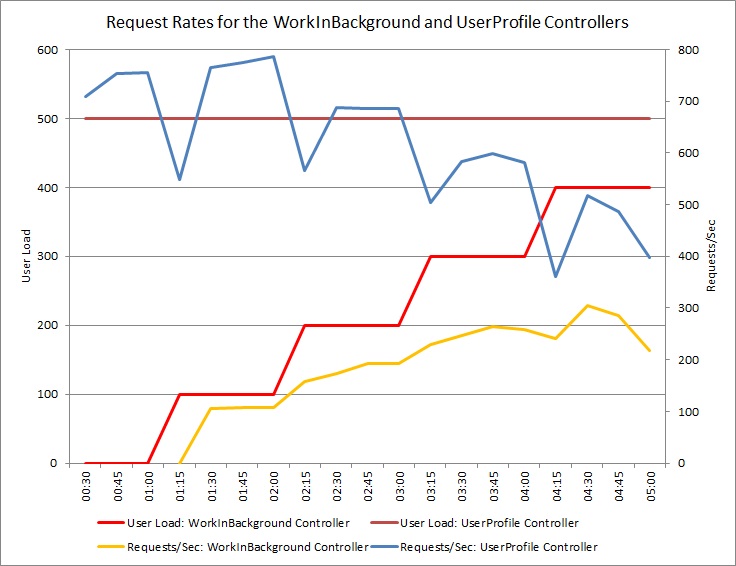
Le graphique ci-dessous montre les résultats d’un test de charge effectué sur un déploiement identique du service cloud utilisé dans les tests précédents. Pour ce test, une charge constante de 500 utilisateurs exécutant l’opération Get dans le contrôleur UserProfile et une charge progressive d’utilisateurs exécutant l’opération Post dans le contrôleur WorkInFrontEnd ont été utilisées.
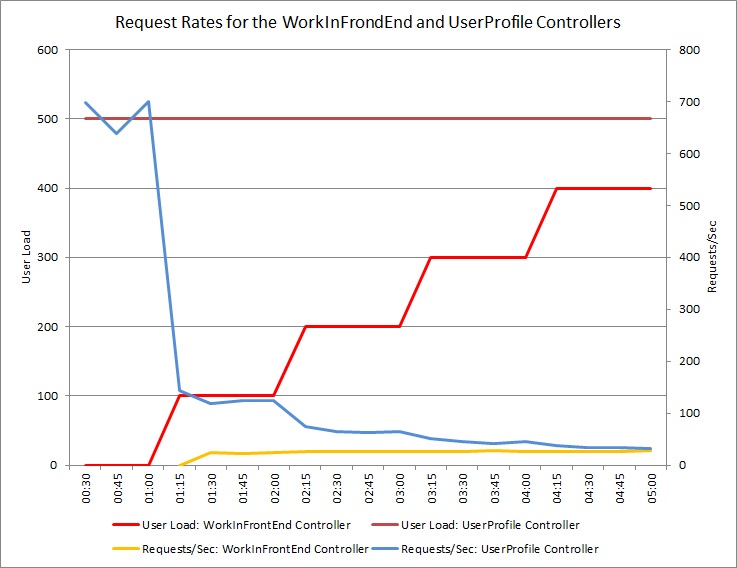
Au départ, la charge progressive est de 0, ce qui signifie que les seuls utilisateurs actifs envoient des requêtes UserProfile. Le système est capable de répondre à environ 500 requêtes par seconde. Après 60 secondes, une charge de 100 utilisateurs supplémentaires, qui commencent à envoyer des requêtes POST au contrôleur WorkInFrontEnd, est ajoutée. Presque immédiatement, la charge de travail envoyée au contrôleur UserProfile descend à environ 150 requêtes par seconde. Cela est dû au mode de fonctionnement de l’exécuteur de tests de charge. Celui-ci attend une réponse avant d’envoyer la requête suivante. Par conséquent, plus la réponse met de temps à arriver, plus le taux de requêtes est faible.
À mesure que des utilisateurs supplémentaires envoient des requêtes POST au contrôleur WorkInFrontEnd, le taux de requêtes du contrôleur UserProfile continue à diminuer. Notez cependant que le volume des requêtes traitées par le contrôleur WorkInFrontEnd reste relativement constant. La saturation du système devient apparente à mesure que le taux global des deux requêtes tend vers une limite constante mais faible.
Réviser le code source
La dernière étape consiste à examiner le code source. L’équipe de développement était consciente que la méthode Post pouvait prendre beaucoup de temps, c’est pourquoi l’implémentation d’origine utilisait un thread distinct. Cela a permis de résoudre le problème immédiat, car la méthode Post ne se bloquait pas en attendant qu’une tâche de longue durée se termine.
Cependant, le travail exécuté par cette méthode consomme toujours des ressources processeur, mémoire et autres. Permettre l’exécution asynchrone de ce processus est en fait susceptible de dégrader les performances, car les utilisateurs peuvent déclencher un grand nombre de ces opérations simultanément, de manière non contrôlée. Le nombre de threads qu’un serveur peut exécuter est limité. Au-delà de cette limite, l’application risque d’obtenir une exception en essayant de démarrer un nouveau thread.
Notes
Vous ne devez pas pour autant éviter les opérations asynchrones. L’exécution d’une opération await asynchrone sur un appel réseau est une pratique recommandée (Consultez l’antimodèle E/S synchrones.) Le problème ici est que le travail nécessitant une utilisation importante du processeur a été engendré sur un autre thread.
Implémenter la solution et vérifier le résultat
L’image suivante montre l’analyse des performances après l’implémentation de la solution. La charge était similaire à celle illustrée précédemment, mais les temps de réponse pour le contrôleur UserProfile sont maintenant beaucoup plus courts. Sur la même durée, le volume de requêtes est passé de 2 759 à 23 565.
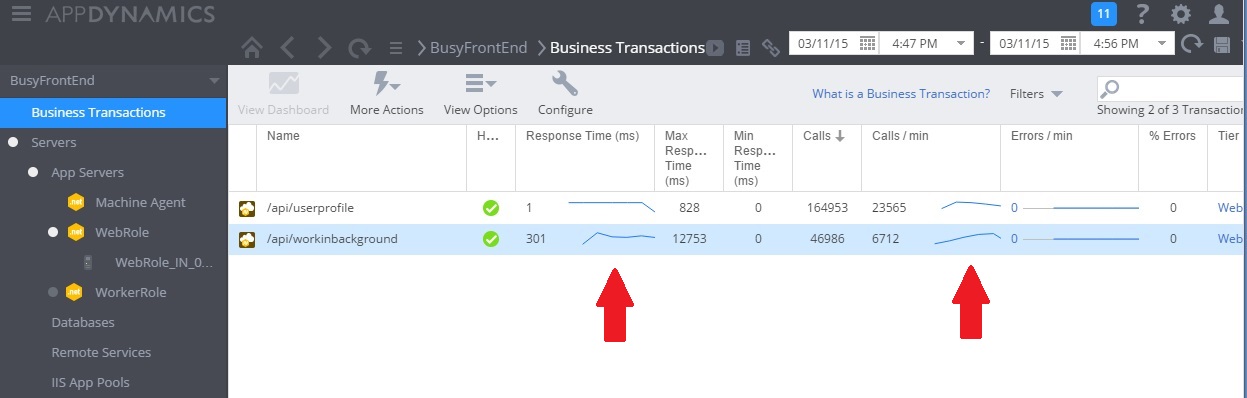
Vous remarquerez que le contrôleur WorkInBackground a également traité un volume beaucoup plus important de requêtes. Cependant, il n’est pas possible de faire de comparaison directe dans ce cas, car le travail exécuté dans ce contrôleur est très différent de celui du code d’origine. En effet, au lieu d’exécuter un long calcul, la nouvelle version met simplement une requête en file d’attente. Le point à retenir est que cette méthode ne ralentit plus l’ensemble du système sous charge.
L’utilisation du processeur et l’utilisation du réseau témoignent également de l’amélioration des performances. L’utilisation du processeur n’a jamais atteint 100 %, et le volume de requêtes réseau traitées a été bien plus important que précédemment, ne diminuant qu’au moment où la charge de travail a baissé.
Le graphique suivant présente les résultats d’un test de charge. Le volume total de requêtes traitées est en nette hausse par rapport aux tests précédents.
Aide connexe
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour