Acquisition de données et phase de présentation du cycle de vie du processus Team Data science Process
Cet article présente les objectifs, tâches et livrables associés à la phase d’acquisition de données et de compréhension du processus TDSP. Ce processus indique un cycle de vie recommandé que votre équipe peut utiliser pour structurer vos projets de science des données. Le cycle de vie décrit les principales étapes que votre équipe effectue, souvent par itération :
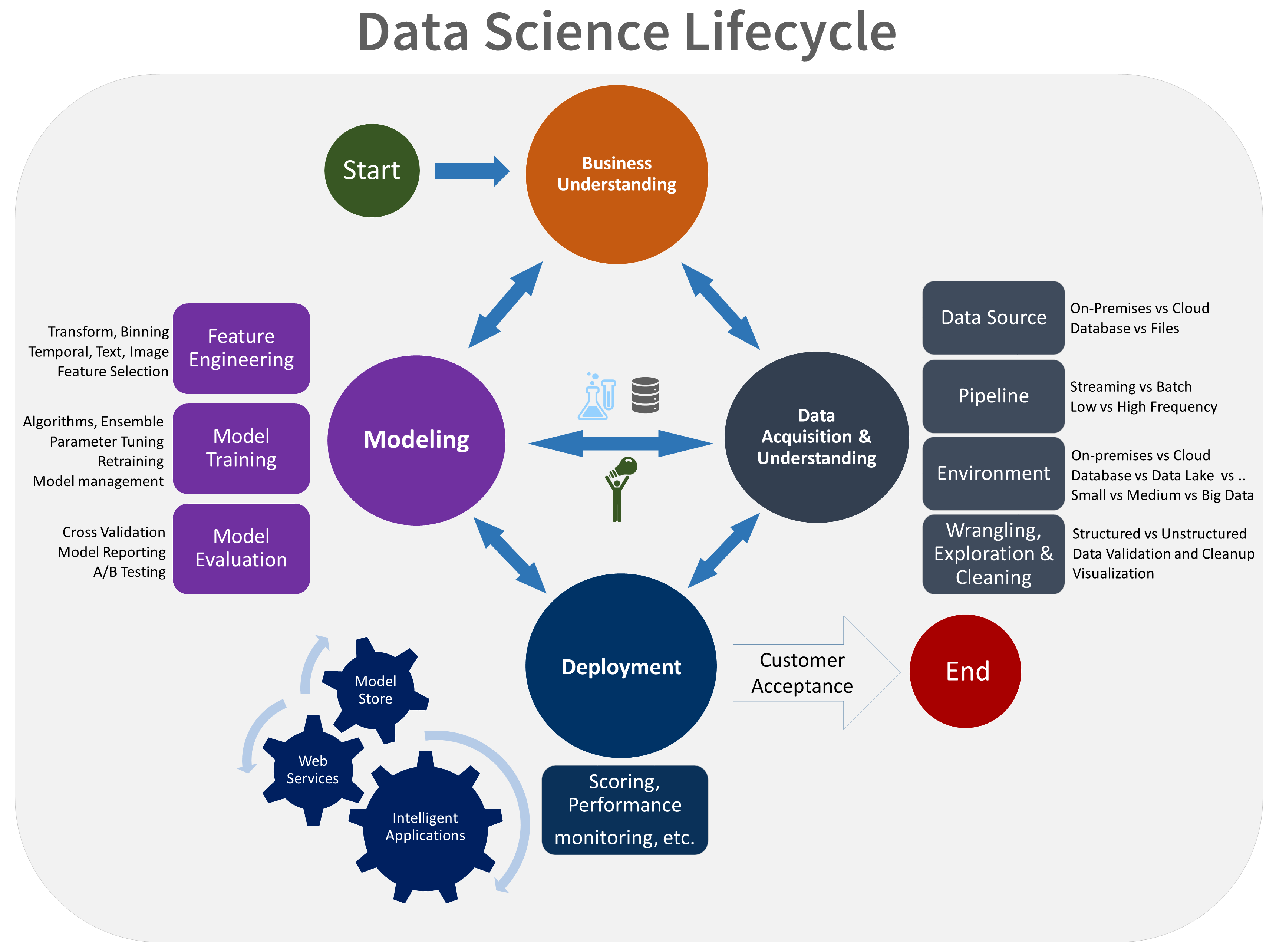
- Présentation de l’entreprise
- Acquisition et compréhension des données
- Modélisation
- Déploiement
- Acceptation du client
Voici une représentation visuelle du cycle de vie TDSP :
Objectifs
Les objectifs de la phase d’acquisition et de compréhension des données sont les suivants :
Produire un ensemble de données nettoyées et de qualité élevée qui se rapporte clairement aux variables cibles. Localiser le jeu de données dans l’environnement d’analyse approprié afin que votre équipe soit prête pour l’étape de modélisation.
Développer une architecture de la solution du pipeline de données qui actualise et évalue les données régulièrement.
Mener à bien les tâches
L’acquisition et la compréhension des données couvrent trois tâches principales :
Ingérer les données dans l’environnement d’analyse cible.
Explorer les données pour déterminer si elles peuvent répondre à la question.
Configurer un pipeline de données pour évaluer les données nouvelles ou régulièrement actualisées.
Ingérer des données
Configurez le processus permettant de déplacer les données des emplacements sources vers les emplacements cibles où vous devez exécuter les opérations d’analyse telles que l’apprentissage et les prédictions.
Explorer des données
Avant de former vos modèles, vous devez développer une parfaite compréhension des données. Les jeux de données réels sont souvent parasités, ne contiennent pas certaines valeurs ou comportent une multitude d’autres anomalies. Vous pouvez utiliser la visualisation et la synthèse des données pour auditer la qualité de vos données et partager les informations nécessaires pour traiter les données en vue de leur modélisation. Ce processus est souvent itératif.
Une fois que vous êtes satisfait de la qualité des données nettoyées, l’étape suivante consiste à mieux comprendre les modèles dans les données. Cette analyse des données vous permet de choisir et de développer un modèle prédictif approprié pour votre cible. Déterminez la quantité de données correspondant à la cible. Décidez ensuite sI votre équipe dispose des données suffisantes pour passer aux étapes de modélisation suivantes. Là encore, ce processus est souvent itératif. Vous devrez peut-être rechercher de nouvelles sources de données avec des données plus précises ou mieux appropriées pour ajuster le jeu de données identifié au cours de la phase précédente.
Configurer un pipeline de données
Outre l’ingestion et le nettoyage des données, vous devez généralement définir un processus pour noter les nouvelles données ou actualiser les données régulièrement dans le cadre d’un processus de formation continue. Vous pouvez utiliser un pipeline de données ou un flux de travail pour noter les données. Nous recommandons un pipeline qui utilise Azure Data Factory.
Dans cette étape, vous développez une architecture de la solution du pipeline de données. Vous créez le pipeline parallèlement à l’étape suivante du projet de science des données. Suivant les besoins de votre entreprise et les contraintes de vos systèmes existants auxquels cette solution est en cours d’intégration, le pipeline peut être :
- Par lot
- En temps réel ou diffusion en continu
- Hybride
Intégrer à MLflow
Pendant la phase de compréhension des données, vous pouvez utiliser le suivi des expériences de MLflow pour suivre et documenter diverses stratégies de prétraitement des données et une analyse exploratoire des données.
Artifacts
Au cours de cette phase, votre équipe livre :
Un rapport de qualité des données qui contient des synthèses de données, les relations entre chaque attribut et cible, le classement des variables, etc.
Architecture de solution, telle qu’un diagramme ou une description de votre pipeline de données que votre équipe utilise pour exécuter des prédictions sur de nouvelles données. Ce diagramme contient également le pipeline avec lequel former le modèle en fonction des nouvelles données. Lorsque vous utilisez le modèle de structure de répertoire TDSP, stockez le document dans le répertoire du projet.
Décision de point de contrôle : avant de procéder à l’ingénierie des caractéristiques et à la modélisation complètes, vous pouvez réévaluer le projet afin de déterminer si cela vaut la peine de le poursuivre. Vous pouvez, par exemple, être en mesure de continuer, avoir besoin de collecter des données supplémentaires ou abandonner le projet si vous ne parvenez pas à trouver de données qui répondent aux questions.
Documentation examinée par les pairs
Les chercheurs publient des études sur le TDSP dans la documentation examinée par les pairs. Les citations permettent d'étudier d'autres applications ou idées similaires à la TDSP, y compris l'étape du cycle de vie de l'acquisition et de la compréhension des données.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Mark Tabladillo | Architecte de solution cloud senior
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Ressources associées
Les articles suivants décrivent les autres étapes du cycle de vie TDSP :