Style d’architecture de niveau N
Une architecture multiniveau divise une application en couches logiques et en niveaux physiques.

Les couches permettent de séparer les responsabilités et de gérer les dépendances. Chaque couche a une responsabilité spécifique. Une couche supérieure peut utiliser des services dans une couche inférieure, mais pas de l’autre façon.
Les niveaux sont physiquement séparés, exécutés sur des ordinateurs distincts. De façon contractuelle, le niveau peut avoir leurs modèles de communication stricts ou détendus. Dans le modèle strict, une demande doit passer par des niveaux adjacents, un par un et ne peut pas ignorer un niveau entre deux. Par exemple, du pare-feu d’applications web au niveau web, puis au niveau intermédiaire 1, et ainsi de suite. En revanche, dans l’approche détendue, la demande peut ignorer certains niveaux s’il est nécessaire. L’approche stricte a plus de latence et de surcharge, et l’approche détendue a plus de couplages et, par la suite, il est plus difficile de changer. Un système peut utiliser une approche hybride : avoir des niveaux détendus et stricts si nécessaire.
Un niveau peut appeler directement un autre niveau ou utiliser des modèles de messagerie asynchrones via une file d’attente de messages. Bien que chaque couche puisse être hébergée dans son propre niveau, cela n’est pas obligatoire. Plusieurs couches peuvent être hébergées sur le même niveau. La séparation physique des niveaux améliore la scalabilité et la résilience, mais ajoute également la latence à partir de la communication réseau supplémentaire.
Une application traditionnelle à trois niveaux dispose d’un niveau de présentation, d’un niveau intermédiaire et d’une couche base de données. Le niveau intermédiaire est facultatif. Les applications plus complexes peuvent avoir plus de trois niveaux. Le diagramme ci-dessus montre une application avec deux niveaux intermédiaires, encapsulant différentes zones de fonctionnalités.
Une application multiniveau peut avoir une architecture de couche fermée ou une architecture de couche ouverte :
- Dans une architecture de couche fermée, une couche peut uniquement appeler la couche suivante immédiatement vers le bas.
- Dans une architecture de couche ouverte, une couche peut appeler l’une des couches situées en dessous.
Une architecture de couche fermée limite les dépendances entre les couches. Toutefois, il peut créer un trafic réseau inutile, si une couche transmet simplement les requêtes au niveau de la couche suivante.
Quand utiliser cette architecture
Les architectures à plusieurs niveaux sont généralement implémentées en tant qu’applications IaaS (Infrastructure-as-Service), chaque niveau s’exécutant sur un ensemble distinct de machines virtuelles. Toutefois, une application multiniveau n’a pas besoin d’être iaaS pure. Souvent, il est avantageux d’utiliser des services managés pour certaines parties de l’architecture, en particulier la mise en cache, la messagerie et le stockage de données.
Prenons l’exemple d’une architecture de niveau N pour :
- Applications web simples.
- Un bon point de départ lorsque les exigences architecturales ne sont pas encore claires.
- Migration d’une application locale vers Azure avec une refactorisation minimale.
- Développement unifié d’applications locales et cloud.
Les architectures à plusieurs niveaux sont très courantes dans les applications locales traditionnelles. Il s’agit donc d’un ajustement naturel pour la migration de charges de travail existantes vers Azure.
Avantages
- Portabilité entre le cloud et l’environnement local et entre les plateformes cloud.
- Courbe d’apprentissage moindre pour la plupart des développeurs.
- Coût relativement faible en ne réarchisant pas la solution
- Évolution naturelle du modèle d’application traditionnel.
- Ouvrir à un environnement hétérogène (Windows/Linux)
Défis
- Il est facile de se retrouver avec un niveau intermédiaire qui effectue uniquement des opérations CRUD sur la base de données, en ajoutant une latence supplémentaire sans effectuer de travail utile.
- La conception monolithique empêche le déploiement indépendant des fonctionnalités.
- La gestion d’une application IaaS est plus importante qu’une application qui utilise uniquement des services managés.
- Il peut être difficile de gérer la sécurité réseau dans un système volumineux.
- Les flux d’utilisateurs et de données s’étendent généralement sur plusieurs niveaux, ce qui ajoute de la complexité aux problèmes tels que le test et l’observabilité.
Meilleures pratiques
- Utilisez la mise à l’échelle automatique pour gérer les modifications de charge. Consultez les meilleures pratiques de mise à l’échelle automatique.
- Utilisez de messagerie asynchrone pour dissocier les niveaux.
- Mettre en cache des données semi-statiques. Consultez les meilleures pratiques de mise en cache .
- Configurez le niveau de base de données pour la haute disponibilité, à l’aide d’une solution telle que des groupes de disponibilité Always On SQL Server.
- Placez un pare-feu d’applications web (WAF) entre le serveur frontal et Internet.
- Placez chaque niveau dans son propre sous-réseau et utilisez des sous-réseaux comme limite de sécurité.
- Limitez l’accès au niveau des données en autorisant uniquement les requêtes provenant des couches intermédiaires.
Architecture multiniveau sur les machines virtuelles
Cette section décrit une architecture de niveau N recommandée s’exécutant sur des machines virtuelles.
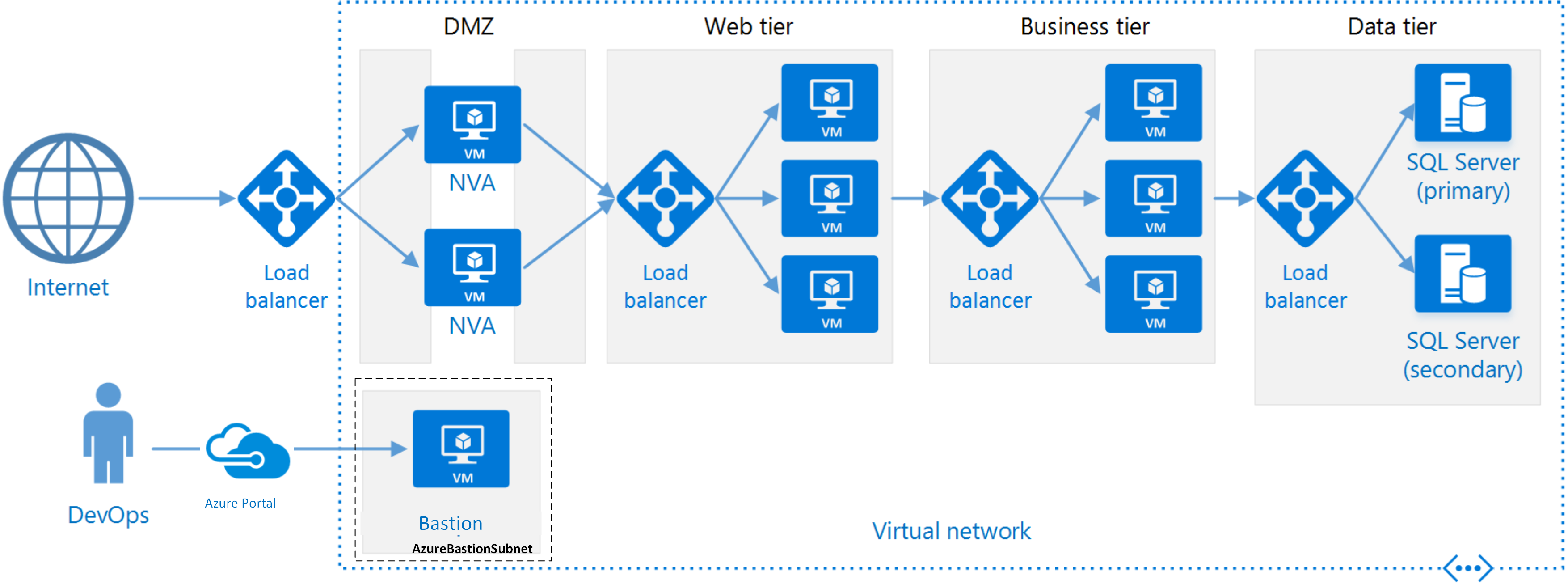
Chaque niveau se compose de deux machines virtuelles ou plus, placées dans un groupe à haute disponibilité ou un groupe de machines virtuelles identiques. Plusieurs machines virtuelles offrent une résilience en cas d’échec d’une machine virtuelle. Les équilibreurs de charge sont utilisés pour distribuer les requêtes entre les machines virtuelles d’un niveau. Un niveau peut être mis à l’échelle horizontalement en ajoutant d’autres machines virtuelles au pool.
Chaque niveau est également placé à l’intérieur de son propre sous-réseau, ce qui signifie que leurs adresses IP internes se trouvent dans la même plage d’adresses. Cela permet d’appliquer facilement des règles de groupe de sécurité réseau et des tables de routage à des niveaux individuels.
Les niveaux web et métier sont sans état. N’importe quelle machine virtuelle peut gérer n’importe quelle demande pour ce niveau. Le niveau de données doit se composer d’une base de données répliquée. Pour Windows, nous vous recommandons SQL Server, à l’aide de groupes de disponibilité Always On pour la haute disponibilité. Pour Linux, choisissez une base de données qui prend en charge la réplication, telle qu’Apache Cassandra.
Les groupes de sécurité réseau limitent l’accès à chaque niveau. Par exemple, le niveau de base de données autorise uniquement l’accès à partir du niveau Entreprise.
Remarque
La couche intitulée « Niveau entreprise » dans notre diagramme de référence est un moniker au niveau logique métier. De même, nous appelons également le niveau de présentation « Niveau Web ». Dans notre exemple, il s’agit d’une application web, bien que des architectures multiniveau puissent également être utilisées pour d’autres topologies (comme les applications de bureau). Nommez vos niveaux qui conviennent le mieux à votre équipe pour communiquer l’intention de ce niveau logique et/ou physique dans votre application. Vous pouvez même exprimer ce nom dans les ressources que vous choisissez de représenter ce niveau (par exemple, vmss-appName-business-layer).
Considérations supplémentaires
Les architectures à plusieurs niveaux ne sont pas limitées à trois niveaux. Pour les applications plus complexes, il est courant d’avoir plus de niveaux. Dans ce cas, envisagez d’utiliser le routage de couche 7 pour router les demandes vers un niveau particulier.
Les niveaux sont la limite de scalabilité, de fiabilité et de sécurité. Envisagez d’avoir des niveaux distincts pour les services avec des exigences différentes dans ces domaines.
Utilisez des groupes de machines virtuelles identiques pour la mise à l’échelle automatique.
Recherchez des emplacements dans l’architecture où vous pouvez utiliser un service managé sans refactorisation significative. En particulier, examinez la mise en cache, la messagerie, le stockage et les bases de données.
Pour une sécurité plus élevée, placez une zone DMZ réseau devant l’application. La zone DMZ inclut des appliances virtuelles réseau qui implémentent des fonctionnalités de sécurité telles que les pare-feu et l’inspection des paquets. Pour plus d’informations, consultez l’architecture de référence network DMZ.
Pour la haute disponibilité, placez deux appliances virtuelles réseau ou plus dans un groupe à haute disponibilité, avec un équilibreur de charge externe pour distribuer des requêtes Internet entre les instances. Pour plus d’informations, consultez Déployer des appliances virtuelles réseau hautement disponibles.
N’autorisez pas l’accès RDP direct ou SSH aux machines virtuelles qui exécutent du code d’application. Au lieu de cela, les opérateurs doivent se connecter à un jumpbox, également appelé hôte bastion. Il s’agit d’une machine virtuelle sur le réseau que les administrateurs utilisent pour se connecter aux autres machines virtuelles. Le jumpbox a un groupe de sécurité réseau qui autorise RDP ou SSH uniquement à partir d’adresses IP publiques approuvées.
Vous pouvez étendre le réseau virtuel Azure à votre réseau local à l’aide d’un réseau privé virtuel de site à site (VPN) ou d’Azure ExpressRoute. Pour plus d’informations, consultez l’architecture de référence du réseau hybride.
Si votre organisation utilise Active Directory pour gérer l’identité, vous pouvez étendre votre environnement Active Directory au réseau virtuel Azure.
Ressources associées
- [Application multiniveau Windows sur Azure avec SQL Server][n-tier-windows-SQL]
- Module Microsoft Learn : Visite guidée du style d’architecture de niveau N
- Azure Bastion
- Plus d’informations sur la messagerie dans un style d’architecture de niveau N sur Azure