Modèle Surveillance de point de terminaison
Vous pouvez utiliser le modèle de surveillance de point de terminaison d’intégrité pour vérifier que les applications et les services fonctionnent correctement. Ce modèle spécifie l’utilisation de vérifications fonctionnelles dans une application. Les outils externes peuvent accéder à ces vérifications à intervalles réguliers via des points de terminaison exposés.
Contexte et problème
Il est recommandé de surveiller les applications web et les services de back-end. La supervision permet de s’assurer que les applications et les services sont disponibles et fonctionnent correctement. Les besoins métier incluent souvent la supervision.
Il est parfois plus difficile de surveiller les services cloud que les services locaux. L’une des raisons est que vous n’avez pas le contrôle total de l’environnement d’hébergement. Une autre est que les services dépendent généralement d’autres services fournis par les fournisseurs de plateforme et d’autres.
De nombreux facteurs affectent les applications hébergées dans le cloud. Les exemples comprennent la latence du réseau, les performances et la disponibilité des systèmes de calcul et de stockage sous-jacents, et la bande passante réseau entre eux. Un service peut échouer entièrement ou partiellement en raison de l’un de ces facteurs. Pour garantir un niveau de disponibilité requis, vous devez vérifier à intervalles réguliers que votre service fonctionne correctement. Votre contrat de niveau de service (SLA) peut spécifier le niveau que vous devez respecter.
Solution
Implémentez la surveillance de l’intégrité en envoyant des demandes à un point de terminaison sur votre application. L’application doit effectuer les vérifications nécessaires puis retourner une indication de son état.
Un contrôle de surveillance de l’intégrité combine en général deux facteurs :
- Les contrôles (le cas échéant) effectués par l’application ou le service en réponse à la demande envoyée au point de terminaison de vérification de l’intégrité.
- L’analyse des résultats par l’outil ou le framework qui effectue le contrôle de vérification de l’intégrité
Le code de réponse indique l’état de l’application. Si vous le souhaitez, le code de réponse fournit également l’état des composants et services utilisés par l’application. Le contrôle de latence ou de temps de réponse est effectué par l’outil ou le framework de surveillance.
La figure suivante présente une vue d’ensemble du modèle.
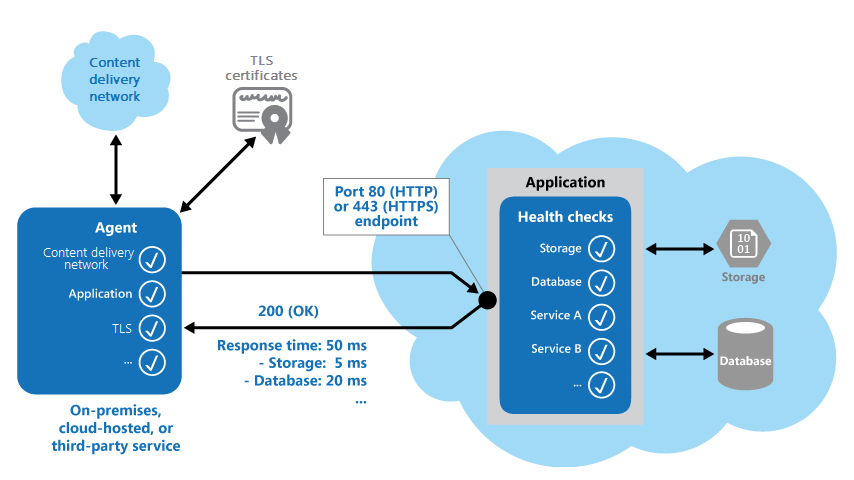
Le code de surveillance de l’intégrité dans l’application peut également exécuter d’autres vérifications pour déterminer :
- La disponibilité et le temps de réponse du stockage cloud ou d’une base de données.
- L’état des autres ressources ou services que l’application utilise. Ces ressources et services peuvent se trouver dans l’application ou en dehors de celle-ci.
Il existe des outils et services qui surveillent des applications web en soumettant une demande à un ensemble de points de terminaison configurable. Ces services et outils évaluent ensuite les résultats par rapport à un ensemble de règles configurables. Il est relativement facile de créer un point de terminaison de service dont la seule fonction est d’effectuer certains tests fonctionnels sur le système.
Voici quelques-uns des contrôles que les outils de surveillance effectuent :
- Validation du code de réponse. Par exemple, une réponse HTTP 200 (OK) indique que l’application a répondu sans erreur. Le système de surveillance peut également contrôler d’autres codes de réponse pour fournir des résultats plus complets.
- Vérification du contenu de la réponse pour détecter les erreurs, même quand le code d’état 200 (OK) est retourné. En vérifiant le contenu, vous pouvez détecter les erreurs qui affectent uniquement une section de la page web retournée ou de la réponse du service. Par exemple, vous pouvez vérifier le titre d’une page ou rechercher une expression spécifique qui indique que l’application a retourné la page correcte.
- Mesure du temps de réponse. La valeur inclut la latence du réseau et le temps que l’application a pris pour émettre la requête. Une valeur croissante peut indiquer un problème au niveau de l’application ou du réseau.
- Vérification des ressources ou des services situés en dehors de l’application. Par exemple, un réseau de distribution de contenu que l’application utilise pour fournir du contenu à partir de caches globaux.
- Vérification de l’expiration des certificats TLS.
- Mesure du temps de réponse d’une recherche DNS pour l’URL de l’application. Cette vérification mesure la latence DNS et les échecs DNS.
- Validation de l’URL retournée par une recherche DNS. En validant, vous pouvez vous assurer que les entrées sont correctes. Vous pouvez également empêcher la redirection de requête malveillante qui peut se produire après une attaque sur votre serveur DNS.
Il est également utile, dans la mesure du possible, d’exécuter ces contrôles à partir de différents emplacements locaux ou hébergés pour comparer les temps de réponse. Dans l’idéal, vous devez surveiller les applications à partir d’emplacements qui sont proches des clients. Vous obtenez ainsi une vue précise des performances de chaque emplacement. Cette pratique fournit un mécanisme de vérification plus robuste. Les résultats peuvent également vous aider à prendre les décisions suivantes :
- Où déployer votre application
- S’il faut la déployer dans plusieurs centres de données
Pour vous assurer que votre application fonctionne correctement pour tous les clients, exécutez des tests sur toutes les instances de service utilisées par les clients. Par exemple, si le stockage du client est réparti sur plusieurs comptes de stockage, le processus de surveillance doit tous les vérifier.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
Réfléchissez à la façon de valider la réponse. Par exemple, déterminez si un code d’état 200 (OK) suffit pour vérifier que l’application fonctionne correctement. La vérification du code d’état est l’implémentation minimale de ce modèle. Un code d’état fournit une mesure de base de la disponibilité des applications. Mais un code fournit peu d’informations sur les opérations, les tendances et les éventuels problèmes à venir dans l’application.
Déterminez le nombre de points de terminaison à exposer pour une application. Une approche consiste à exposer au moins un point de terminaison pour les services de base utilisés par l’application, et un autre pour les services de priorité inférieure. Avec cette approche, vous pouvez affecter différents niveaux d’importance à chaque résultat de surveillance. Envisagez également d’exposer des points de terminaison supplémentaires. Vous pouvez en exposer un pour chaque service principal afin d’augmenter la granularité de la surveillance. Ainsi, un contrôle de vérification de l’intégrité peut vérifier la base de données, le stockage et un service de géocodage externe utilisé par une application. Chacun peut nécessiter un niveau de temps de fonctionnement et de temps de réponse différent. Le service de géocodage ou une autre tâche en arrière-plan peut être indisponible pendant quelques minutes. Mais l’application peut toujours être saine.
Décidez s’il faut utiliser le même point de terminaison pour la surveillance et pour l’accès général. Vous pouvez utiliser le même point de terminaison pour les deux, mais concevoir un chemin d’accès spécifique pour les vérifications d’intégrité. Par exemple, vous pouvez utiliser /health sur le point de terminaison d’accès général. Avec cette approche, les outils de supervision peuvent exécuter des tests fonctionnels dans l’application. Par exemple, l’inscription d’un nouvel utilisateur, la connexion et l’envoi d’une commande de test. Dans le même temps, vous pouvez également vérifier que le point de terminaison d’accès général est disponible.
Déterminez le type d’informations à collecter dans le service en réponse aux demandes de surveillance. Vous devez également déterminer comment retourner ces informations. La plupart des outils et frameworks existants examinent uniquement le code d’état HTTP retourné par le point de terminaison. Pour retourner et valider des informations supplémentaires, vous devrez peut-être créer un service ou un utilitaire de surveillance personnalisé.
Identifiez la quantité d’informations à collecter. Un traitement excessif lors de la vérification peut surcharger l’application et avoir un impact sur d’autres utilisateurs. Le temps de traitement peut également dépasser le délai d’expiration du système de surveillance. Par conséquent, le système peut marquer l’application comme indisponible. La plupart des applications incluent des instrumentations, comme des gestionnaires d’erreurs et des compteurs de performances. Ces outils peuvent consigner les performances et des informations détaillées sur les erreurs, ce qui peut être suffisant. Envisagez d’utiliser ces données au lieu de retourner des informations supplémentaires à partir d’un contrôle de vérification de l’intégrité.
Envisagez de mettre en cache l’état du point de terminaison. L’exécution fréquente du contrôle d’intégrité peut être coûteuse. Si l’état d’intégrité est indiqué sur un tableau de bord (par exemple), vous ne souhaitez pas que chaque requête faite vers le tableau de bord déclenche un contrôle d’intégrité. Vérifiez plutôt l’intégrité du système périodiquement et mettez l’état en cache. Exposez un point de terminaison qui retourne l’état mis en cache.
Planifiez la configuration de la sécurité pour les points de terminaison de surveillance. En configurant la sécurité, vous pouvez protéger les points de terminaison contre l’accès public, qui pourrait sinon :
- Exposer l’application à des attaques malveillantes.
- Créer un risque d’exposition d’informations sensibles.
- Attirer les attaques par déni de service (DoS).
En règle générale, vous configurez la sécurité dans la configuration de l’application. Vous pouvez ensuite mettre à jour les paramètres facilement sans redémarrer l’application. Vous pouvez appliquer une ou plusieurs des techniques suivantes :
Sécurisez le point de terminaison en exigeant l’authentification. Si le service ou l’outil de surveillance prend en charge l’authentification, vous pouvez utiliser une clé de sécurité d’authentification dans l’en-tête de la requête. Vous pouvez également transmettre des informations d’identification avec la requête. Lorsque vous utilisez l’authentification, réfléchissez à la façon d’accéder à vos points de terminaison de contrôle d’intégrité. À titre d’exemple, le contrôle d’intégrité présent dans Azure App Service s’intègre aux fonctionnalités d’authentification et d’autorisation d’App Service.
Utilisez un point de terminaison obscur ou masqué. Par exemple, exposez le point de terminaison sur une adresse IP différente de celle que l’URL d’application par défaut utilise. Configurez le point de terminaison sur un port HTTP non standard. Envisagez également d’utiliser un chemin d’accès complexe à votre page de test. Vous pouvez généralement spécifier des adresses de point de terminaison et des ports supplémentaires dans la configuration de l’application. Si nécessaire, vous pouvez ajouter des entrées pour ces points de terminaison au serveur DNS. Vous évitez ainsi d’avoir à spécifier l’adresse IP directement.
Exposez une méthode sur un point de terminaison qui accepte un paramètre tel qu’une valeur de clé ou une valeur de mode d’opération. Lorsqu’une requête arrive, le code peut exécuter des tests spécifiques qui dépendent de la valeur du paramètre. Le code peut retourner une erreur 404 (introuvable) s’il ne reconnaît pas la valeur du paramètre. Permet de définir des valeurs de paramètre dans la configuration de l’application.
Utilisez un point de terminaison distinct qui effectue des tests fonctionnels de base sans compromettre le fonctionnement de l’application. Avec cette approche, vous pouvez aider à réduire l’impact d’une attaque DoS. Dans l’idéal, évitez d’utiliser un test susceptible d’exposer des informations sensibles. Parfois, vous devez retourner des informations qui pourraient être utiles à un attaquant. Dans ce cas, réfléchissez à la façon de protéger le point de terminaison et les données contre les accès non autorisés. S’appuyer sur l’obscurité ne suffit pas. Envisagez également l’utilisation d’une connexion HTTPS et le chiffrement des données sensibles, mais cette approche augmentera la charge sur le serveur.
Choisissez comment vérifier que les performances de l’agent de surveillance sont correctes. Une approche consiste à exposer un point de terminaison qui retourne une valeur à partir de la configuration de l’application ou une valeur aléatoire que vous pouvez utiliser pour tester l’agent. Assurez-vous également que le système de surveillance effectue des vérifications sur lui-même. Vous pouvez utiliser un auto-test ou un test intégré pour empêcher le système de surveillance d’émettre des faux positifs.
Quand utiliser ce modèle
Ce modèle est utile dans les situations suivantes :
- Surveillance d’applications web et de sites web pour vérifier la disponibilité.
- Surveillance d’applications web et de sites web pour vérifier le bon fonctionnement.
- Surveillance de services de couche intermédiaire ou de services partagés pour détecter et isoler une défaillance susceptible de perturber d’autres applications.
- En complément de l’instrumentation existante dans l’application, telle que les compteurs de performances et les gestionnaires d’erreurs. La vérification de l’intégrité ne se substitue pas à l’obligation de journalisation et d’audit dans l’application. L’instrumentation peut fournir des informations précieuses pour un framework existant qui surveille des compteurs et des journaux d’activité d’erreurs pour détecter les défaillances ou autres problèmes. Toutefois, l’instrumentation ne peut pas fournir d’informations si une application n’est pas disponible.
Conception de la charge de travail
Un architecte doit évaluer de quelle façon le modèle de Surveillance d’intégrité de point de terminaison être utilisé dans la conception de leur charge de travail pour répondre aux objectifs et principes couverts par les piliers d’Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| Les décisions relatives à la fiabilité contribuent à rendre votre charge de travail résiliente aux dysfonctionnements et à s’assurer qu’elle retrouve un état de fonctionnement optimal après une défaillance. | Ces points de terminaison soutiennent les efforts d’alerte et de tableau de bord de fiabilité d’une charge de travail. Ils peuvent également être utilisés comme un signal pour la remédiation auto-réparatrice. - RE:07 Auto-réparation et auto-préservation - RE:10 Stratégie de surveillance et d’alerte |
| L’excellence opérationnelle permet de fournir une qualité de charge de travail grâce à des processus standardisés et à la cohésion d’équipe. | Normaliser quels points de terminaison de santé exposer, et le niveau de détail dans les résultats, à travers votre charge de travail vous aidera à trier les problèmes. - OE :07 Système de supervision |
| L’efficacité des performances permet à votre charge de travail de répondre efficacement aux demandes grâce à des optimisations de la mise à l’échelle, des données, du code. | Les points de terminaison de santé améliorent la logique d’équilibrage de charge en acheminant le trafic uniquement vers les nœuds qui sont vérifiés comme sains. Avec une configuration supplémentaire, vous pouvez également obtenir des métriques sur la capacité disponible des nœuds. - PE :05 Mise à l’échelle et partitionnement |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Exemple
Vous pouvez utiliser l’intergiciel et les bibliothèques de contrôles d’intégrité ASP.NET pour signaler l’intégrité des composants d’infrastructure d’application. Cette infrastructure permet de signaler les contrôles d’intégrité de manière cohérente. Elle implémente la plupart des pratiques décrites dans cet article. Par exemple, les vérifications d’intégrité ASP.NET comprennent des contrôles externes comme la connectivité de base de données et des concepts spécifiques tels que des diagnostics « probe liveness » et « probe readiness ».
Plusieurs exemples d’implémentations qui utilisent les contrôles d’intégrité ASP.NET sont disponibles sur GitHub.
Surveillance des points de terminaison dans les applications hébergées Azure
Voici des options pour la surveillance des points de terminaison dans les applications Azure :
- Utilisez les fonctionnalités de supervision intégrées d’Azure, comme Azure Monitor.
- Utiliser un service ou un framework tiers comme Microsoft System Center Operations Manager.
- Créer un utilitaire ou un service personnalisé qui s’exécute sur votre propre serveur ou sur un serveur hébergé
Bien qu’Azure fournisse des options de surveillance complètes, vous pouvez utiliser des services et des outils supplémentaires pour obtenir d’autres informations. Application Insights, une fonctionnalité de Monitor, est conçu pour les équipes de développement. Cette fonctionnalité peut vous aider à comprendre les performances et l’utilisation de votre application. Application Insights surveille les taux de demande, les temps de réponse, les taux d’échec et les taux de dépendance. Il peut vous aider à déterminer si des services externes vous ralentissent.
Les conditions que vous pouvez surveiller dépendent du mécanisme d’hébergement que vous choisissez pour votre application. Toutes les options de cette section prennent en charge les règles d’alerte. Une règle d’alerte utilise un point de terminaison web que vous spécifiez dans les paramètres de votre service. Ce point de terminaison doit répondre en temps opportun pour que le système d’alerte puisse détecter si l’application fonctionne correctement. Pour plus d’informations, consultez Créer une règle d’alerte.
En cas de panne majeure, le trafic client doit être acheminable vers un déploiement d’applications qui restent disponibles dans d’autres régions ou zones. Cette situation est adaptée pour la connectivité intersite et l’équilibrage de charge global. Le choix varie selon que l’application est accessible en interne ou en externe. Des services comme Azure Front Door, Azure Traffic Manager ou les réseaux de distribution de contenu peuvent acheminer le trafic entre les régions en fonction des données que fournissent les sondes d’intégrité.
Traffic Manager est un service de routage et d’équilibrage de charge. Il peut utiliser une gamme de règles et de paramètres pour distribuer des requêtes à des instances spécifiques de votre application. Outre les requêtes de routage, Traffic Manager peut effectuer régulièrement un test ping sur une URL, un port et un chemin relatif. Vous spécifiez les cibles de ping dans le but de déterminer quelles instances de votre application sont actives et de répondre aux requêtes. Si Traffic Manager détecte un code d’état 200 (OK), Traffic Manager marque l’application comme étant disponible. S’il détecte un autre code d’état, il marque l’application comme étant hors connexion. La console Traffic Manager affiche l’état de chaque application. Vous pouvez configurer chaque règle pour rediriger les demandes vers d’autres instances de l’application qui répondent.
Traffic Manager n’attend que pendant un temps déterminé pour recevoir une réponse à partir de l’URL de surveillance. Assurez-vous que votre code de vérification de l’intégrité s’exécute pendant cette période. Prenez en compte la latence du réseau pour l’aller-retour entre Traffic Manager et votre application.
Étapes suivantes
Les conseils suivants sont utiles lors de l’implémentation de ce modèle :
- Conseils pour la surveillance de l’intégrité dans les applications basées sur des microservices
- Surveillance de l’intégrité des applications à des fins de fiabilité, dans le cadre de Well-Architected Framework
- Créer une nouvelle règle d’alerte