Décomposez une tâche qui exécute un traitement complexe en une série d’éléments séparés qui peuvent être réutilisés. Cette méthode peut améliorer les performances, l'évolutivité et la réutilisation des étapes initiales en permettant aux éléments de tâches qui effectuent le traitement d'être déployés et mis à l'échelle de manière indépendante. Le modèle de type « Canaux et filtres » permet un niveau élevé de modularité.
Contexte et problème
Vous disposez d’un pipeline de tâches séquentielles que vous devez traiter. Il existe une approche simple, mais assez rigide, permettant d’implémenter cette application. Elle consiste à effectuer ce traitement dans un module monolithique. Toutefois, cette approche est susceptible de réduire les opportunités de refactorisation, d’optimisation ou de réutilisation du code, si certaines parties du même processus de traitement doivent être utilisées à un autre emplacement de l’application.
Le diagramme suivant illustre l’un des problèmes liés au traitement des données à l’aide d’une approche monolithique, à savoir l’incapacité à réutiliser du code sur plusieurs pipelines. Dans cet exemple, une application reçoit et traite les données de deux sources. Un module distinct traite les données de chaque source en effectuant une série de tâches pour transformer les données, avant de passer le résultat vers la logique métier de l’application.
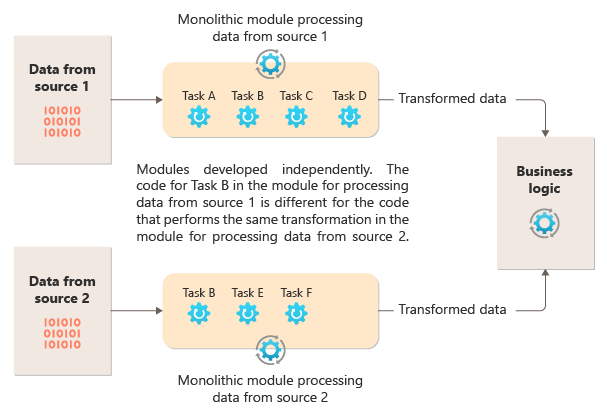
Certaines des tâches que les modules monolithiques effectuent sont fonctionnellement similaires, mais le code doit être répété dans les deux modules et est probablement étroitement couplé dans son module. En plus de l’incapacité à réutiliser la logique, cette approche introduit un risque lorsque les exigences changent. Vous devez vous rappeler de mettre à jour le code dans les deux emplacements.
Il existe d’autres défis avec une implémentation monolithique non liée à plusieurs pipelines ou à une réutilisation. Avec une implémentation monolithique, vous n’avez pas la possibilité d’exécuter des tâches spécifiques dans différents environnements ou de les mettre à l’échelle indépendamment. Certaines tâches peuvent être gourmandes en calcul et pourraient bénéficier d'une exécution sur du matériel performant ou de l’exécution de plusieurs instances en parallèle. D’autres tâches peuvent ne pas avoir les mêmes exigences. En outre, avec des implémentations monolithiques, il est difficile de réorganiser des tâches ou d’injecter de nouvelles tâches dans le pipeline. Ces modifications nécessitent de retester l’intégralité du pipeline.
Solution
Décomposez le traitement requis pour chaque flux en un ensemble de composants distincts (ou de filtres), qui exécuteront chacun une tâche unique. Les tâches composites doivent utiliser plusieurs filtres plutôt qu'un seul. Les filtres sont composés en pipelines en connectant les filtres avec des canaux. Les filtres sont indépendants, autonomes et généralement sans état. Les filtres reçoivent des messages provenant d’un canal entrant et publient des messages sur un canal sortant différent. Les filtres peuvent transformer le message ou le tester par rapport à un ou plusieurs critères afin d'inclure une logique conditionnelle. Les canaux n’effectuent pas de routage ni aucune autre logique. Ils connectent uniquement les filtres, en passant le message de sortie d’un filtre comme entrée pour le filtre suivant.
Les filtres agissent indépendamment et ne reconnaissent pas les autres filtres. Ils reconnaissent uniquement leurs schémas d’entrée et de sortie. Par conséquent, les filtres peuvent être organisés dans n’importe quel ordre tant que le schéma d’entrée pour n’importe quel filtre correspond au schéma de sortie du filtre précédent. L’utilisation d’un schéma standardisé pour tous les filtres améliore la possibilité de réorganiser les filtres. L'architecture de type « canaux et filtres » encourage la réutilisation de la composition.
Le couplage libre des filtres facilite les étapes suivantes :
- Créer des pipelines composés de filtres existants
- Mettre à jour ou remplacer la logique dans des filtres individuels
- Réorganiser les filtres, le cas échéant
- Exécuter des filtres sur un matériel différent, le cas échéant
- Exécuter des filtres en parallèle
Ce diagramme montre une solution implémentée avec des canaux et des filtres :
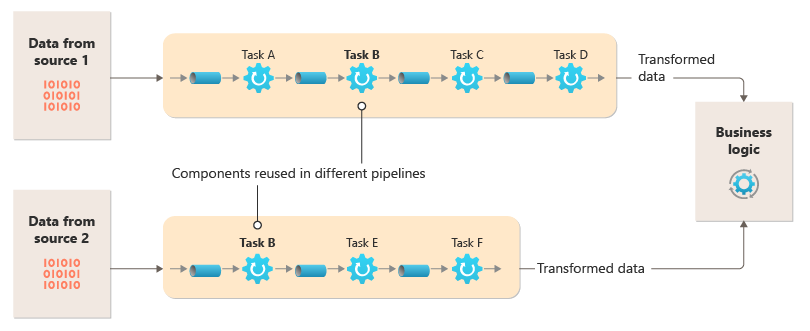
Le temps nécessaire pour traiter une requête unique dépend de la vitesse des filtres les plus lents dans le pipeline. Un ou plusieurs filtres peuvent être des goulots d’étranglement, surtout si un grand nombre de demandes s’affichent dans un flux à partir d’une source de données particulière. La possibilité d’exécuter des instances parallèles de filtres lents permet au système de répartir la charge et d’améliorer le débit.
La possibilité d'exécuter des filtres sur des instances de calcul différentes permet leur mise à l’échelle de manière indépendante et permet également de bénéficier de l’élasticité fournie par de nombreux environnements de cloud. Un filtre qui nécessite beaucoup de ressources système peut être exécuté sur du matériel de haute performance, tandis que d’autres filtres moins exigeants peuvent être exécutés sur du matériel standard moins coûteux. Il n’est pas obligatoire que les filtres se trouvent dans le même centre de données ou au même emplacement géographique, ce qui permet que chaque élément dans un pipeline s’exécute dans un environnement proche des ressources qu’il requiert. Ces efforts requièrent des techniques de conception spécifiques, comme la messagerie, le threading multiple, et autres, afin de maximiser l'élasticité de chaque canal ou filtre. Ce diagramme montre un exemple appliqué au pipeline pour les données de la source 1 :
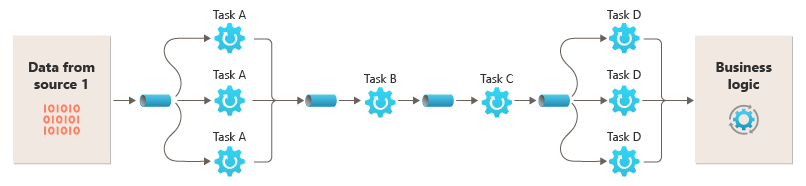
Si l’entrée et la sortie d’un filtre sont structurées sous forme de flux, vous pouvez réaliser le traitement pour chaque filtre en parallèle. Le premier filtre dans le pipeline peut démarrer son travail et sortir ses résultats, qui passent directement au filtre suivant dans la séquence avant que le premier filtre n’ait terminé son travail.
L’utilisation du modèle de canaux et de filtres conjointement avec le Modèle de transaction de compensation est une approche alternative à l’implémentation des transactions distribuées. Vous pouvez décomposer une transaction distribuée en tâches compensables distinctes, qui peuvent chacune être implémentées à l’aide d’un filtre qui implémente également le modèle de transaction de compensation. Les filtres dans un pipeline peuvent être implémentés en tant que tâches hébergées distinctes s’exécutant près des données qu’ils gèrent.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
Caractère monolithique. Ce modèle est généralement mis en œuvre sous la forme d'un pipeline monolithique, si bien que pour toute modification, l'ensemble de la chaîne de filtrage doit être testé d'un bout à l'autre. Il convient également de prendre en compte la tolérance aux pannes pour l'ensemble du processus; si un filtre ou un canal tombe en panne, c'est l'ensemble du pipeline qui risque de tomber en panne.
Complexité : La flexibilité accrue fournie par ce modèle peut également introduire de la complexité, surtout si les filtres dans un pipeline sont répartis sur différents serveurs.
Fiabilité. Utilisez une infrastructure qui permet de s’assurer que les données circulant entre les filtres dans un canal ne seront pas perdues.
Idempotence. Si un filtre dans un pipeline échoue après la réception d’un message et que le travail est replanifié vers une autre instance du filtre, une partie du travail peut déjà être terminée. Si le travail met à jour certains aspects de l’état global (par exemple, les informations stockées dans une base de données), une même mise à jour peut être répétée. Un problème similaire peut se produire si un filtre échoue après la publication de ses résultats dans le filtre suivant, mais avant d’indiquer qu’il a terminé son travail avec succès. Dans ces cas, une autre instance du filtre peut répéter ce travail, entraînant ainsi une seconde publication des mêmes résultats. Ce scénario peut entraîner un second traitement des mêmes données par les filtres suivants dans le pipeline. Par conséquent, les filtres dans un pipeline doivent être conçus pour être idempotents. Pour en savoir plus, consultez l’article Idempotency Patterns sur le blog de Jonathan Oliver.
Répétition des messages. Si un filtre dans un pipeline échoue après la publication d’un message à l’étape suivante du pipeline, une autre instance du filtre peut être exécutée, qui publiera une copie du même message dans le pipeline. Dans ce scénario, deux instances du même message seraient alors transmises vers le filtre suivant. Pour éviter ce problème, le pipeline doit détecter et éliminer les messages en double.
Notes
Si vous implémentez le pipeline à l’aide de files d’attente de messages, comme les files d’attente Azure Service Bus, l’infrastructure de la file d’attente de messages peut proposer la détection et la suppression automatique des messages en double.
Contexte et état. Dans un pipeline, chaque filtre s’exécute principalement de manière isolée et ne doit pas faire d’estimations concernant la manière dont il a été appelé. Ainsi, chaque filtre doit être accompagné d’un contexte suffisant pour effectuer son travail. Ce contexte peut inclure une quantité considérable d’informations d’état. Si les filtres utilisent un état externe, comme les données d’une base de données ou d’un stockage externe, vous devez alors prendre en compte l’impact sur les performances. Chaque filtre doit charger, fonctionner et conserver cet état, ce qui ajoute une surcharge sur les solutions qui chargent l’état externe une seule fois.
Tolérance aux messages. Les filtres doivent être tolérants aux données dans le message entrant sur lesquelles ils n'interviennent pas. Ils fonctionnent sur les données pertinentes pour eux, ignorent d’autres données et les transmettent sans modification dans le message de sortie.
Gestion des erreurs : chaque filtre doit déterminer ce qu’il faut faire en cas d’erreur avec rupture. Le filtre doit déterminer s’il échoue dans le pipeline ou s'il propage l’exception.
Quand utiliser ce modèle
Utilisez ce modèle dans les situations suivantes :
Le traitement requis par une application peut facilement être décomposé en un ensemble d’étapes indépendantes.
Les étapes de traitement réalisées par une application possèdent différentes exigences d’extensibilité.
Notes
Vous pouvez regrouper les filtres qui doivent être mis à l’échelle ensemble dans le même processus. Pour en savoir plus, consultez le Modèle de consolidation des ressources de calcul.
Une certaine flexibilité est nécessaire pour permettre la réorganisation des étapes de traitement effectuées par l'application ou pour permettre la possibilité d'ajout et de suppression des étapes.
Le système peut bénéficier de la distribution du traitement des étapes sur différents serveurs.
Une solution fiable est requise pour minimiser les effets de l’échec dans une étape lors du traitement des données.
Ce modèle peut ne pas avoir d’utilité dans les cas suivants :
L’application suit un modèle de requête-réponse.
Le traitement des tâches doit être effectué dans le cadre d’une requête initiale, telle qu’un scénario de requête/réponse.
Les étapes de traitement effectuées par une application ne sont pas indépendantes, mais elles doivent être exécutées simultanément dans le cadre de la même transaction.
La quantité d’informations de contexte ou d’état requise par une étape rend cette approche inefficace. Vous pourriez parvenir à conserver les informations d’état dans une base de données à la place, mais n’utilisez pas cette stratégie si la charge supplémentaire sur la base de données provoque une contention excessive.
Conception de la charge de travail
Un architecte doit évaluer comment le modèle Canaux et Filtres peut être utilisé dans la conception de leur charge de travail pour répondre aux objectifs et principes couverts par les piliers d’Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| Les décisions relatives à la fiabilité contribuent à rendre votre charge de travail résiliente aux dysfonctionnements et à s’assurer qu’elle retrouve un état de fonctionnement optimal après une défaillance. | La responsabilité unique de chaque étape permet une attention focalisée et évite la distraction du traitement de données mélangées. - RE:01 Simplicité - RE :07 Travaux en arrière-plan |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Exemple
Vous pouvez utiliser une séquence de files d’attente de message pour fournir l’infrastructure requise pour implémenter un pipeline. Une file d’attente de messages initiale reçoit des messages non traités qui deviennent le début de la mise en œuvre du modèle canaux et filtres. Un composant implémenté en tant que tâche de filtre attend un message dans cette file d’attente, effectue son travail, puis publie un nouveau message ou un message transformé dans la file d’attente suivante dans la séquence. Une autre tâche de filtre peut écouter les messages sur cette file, les traiter, poster les résultats vers une autre file, et ainsi de suite, jusqu’à l’étape finale qui termine le processus de canaux et filtres. Ce diagramme illustre un pipeline qui utilise des files d’attente de messages :

Une chaîne de traitement d’images pourrait être mise en œuvre en utilisant ce modèle. Si votre charge de travail prend une image, l’image pourrait passer à travers une série de filtres largement indépendants et ré-ordonnables pour effectuer des actions telles que :
- modération du contenu
- redimensionner
- l’ajout de filigrane
- la réorientation
- la suppression des métadonnées Exif
- la publication sur un réseau de distribution de contenu (CDN)
Dans cet exemple, les filtres pourraient être implémentés comme des fonctions Azure déployées individuellement ou même une seule application de fonction Azure qui contient chaque filtre comme un déploiement isolé. L’utilisation de déclencheurs de fonction Azure, de liaisons d’entrée et de sortie peut simplifier le code de filtre et fonctionner automatiquement avec un canal basé sur une file d’attente en utilisant un contrôle de réclamation pour l’image à traiter.

Voici un exemple de ce à quoi pourrait ressembler un filtre, implémenté comme une Fonction Azure, déclenché à partir d’un canal de Stockage File d’attente avec un contrôle de réclamation pour l’image, et écrivant un nouveau contrôle de réclamation vers une autre pipe de Stockage File d’attente. Par soucis de brièveté, l’implémentation a été remplacée par du pseudo-code dans les commentaires. Vous trouverez plus de code comme celui-ci dans la démonstration du modèle canaux et filtres disponible sur GitHub.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Remarque
L'environnement d'intégration Spring a une implémentation du modèle des canaux et des filtres.
Étapes suivantes
Les ressources suivantes peuvent vous être utiles lorsque vous implémentez ce modèle :
- Une démonstration du modèle Canaux et Filtres utilisant le scénario de traitement d’image est disponible sur GitHub.
- Modèles d’idempotence sur le blog de Jonathan Oliver.
Ressources associées
Les modèles suivants peuvent également être pertinents lors de l’implémentation de ce modèle :
- Modèle de réclamation-vérification. Un pipeline mis en œuvre à l’aide d’une file d’attente peut ne pas contenir l’objet réel envoyé à travers les filtres, mais plutôt un pointeur vers les données qui doivent être traitées. L’exemple utilise un contrôle de réclamation dans le Stockage File d’attente d’Azure pour les images stockées dans le Stockage Blob d’Azure.
- Modèle des consommateurs concurrents. Un pipeline peut contenir plusieurs instances d’un ou plusieurs filtres. Cette approche est utile pour exécuter des instances parallèles de filtres lents. Cela permet au système de répartir la charge et d’améliorer le débit. Chaque instance d’un filtre est en concurrence avec les autres pour l’entrée, deux instances d’un même filtre ne doivent pas être en mesure de traiter les mêmes données. Cet article explique l’approche.
- Modèle de consolidation des ressources de calcul. Il est possible de regrouper les filtres qui doivent être mis à l’échelle ensemble dans un même processus. Cet article fournit plus d’informations sur les avantages et les inconvénients de cette stratégie.
- Modèle de transaction de compensation. Un filtre peut être implémenté comme une opération qui peut être inversée ou qui possède une opération de compensation qui rétablit la version antérieure de l’état en cas de défaillance. Cet article explique comment implémenter ce modèle pour maintenir ou atteindre une cohérence éventuelle.
- Canaux et filtres - Modèles d’intégration Entreprise