De nombreux services utilisent un modèle de limitation pour contrôler les ressources qu’elles consomment, en limitant la cadence à laquelle d’autres applications ou services peuvent y accéder. Vous pouvez utiliser un modèle de limitation de débit pour éviter ou réduire les erreurs liées à ces seuils de limitation, et pour à prédire le débit de manière plus précise.
Si un modèle de limitation de débit est approprié dans de nombreux cas, il est particulièrement utile pour les tâches automatisées répétitives à grande échelle, telles que le traitement par lots.
Contexte et problème
L’exécution d’un grand nombre d’opérations à l’aide d’un service limité peut entraîner une augmentation du trafic et du débit, car vous devez à la fois suivre les requêtes rejetées et retenter ces opérations. À mesure que le nombre d’opérations augmente, un seuil de limitation peut nécessiter plusieurs renvois des données, ce qui accentue l’impact sur les performances.
À titre d’exemple, considérez le processus naïf suivant de nouvelle tentative suite à une erreur pour l’ingestion de données dans Azure Cosmos DB :
- Votre application doit ingérer 10 000 enregistrements dans Azure Cosmos DB. L’ingestion de chaque enregistrement coûte 10 unités de requête (RU). L’accomplissement du travail nécessite dont un total de 100 000 unités de requête.
- Votre instance Azure Cosmos DB a une capacité approvisionnée de 20 000 unités de requête.
- Vous envoyez les 10 000 enregistrements au service Azure Cosmos DB. Celui-ci écrit correctement 2 000 enregistrements et en rejette 8 000.
- Vous renvoyez les 8 000 enregistrements restants au service Azure Cosmos DB. Celui-ci écrit correctement 2 000 enregistrements et en rejette 6 000.
- Vous renvoyez les 6 000 enregistrements restants au service Azure Cosmos DB. Celui-ci écrit correctement 2 000 enregistrements et en rejette 4 000.
- Vous renvoyez les 4 000 enregistrements restants au service Azure Cosmos DB. Celui-ci écrit correctement 2 000 enregistrements et en rejette 2 000.
- Vous renvoyez les 2 000 enregistrements restants au service Azure Cosmos DB. Celui-ci les écrit tous correctement.
Le travail d’ingestion s’est terminé avec succès, mais après l’envoi de 30 000 enregistrements à Azure Cosmos DB alors que le jeu de données entier n’en compte que 10 000.
Il existe des facteurs supplémentaires à prendre en compte dans l’exemple ci-dessus :
- Un grand nombre d’erreurs peut entraîner un surcroît de travail pour journaliser les erreurs et traiter les données de journalisation ainsi obtenues. Cette approche naïve a géré 20 000 erreurs, et la journalisation de celles-ci peut occasionner un coût lié au traitement, à la mémoire ou au stockage.
- Ignorant les seuils de limitation du service d’ingestion, l’approche naïve n’a aucun moyen de fixer des attentes quant au temps que prendra le traitement des données. Une limitation de débit peut vous permettre de calculer le temps requis pour l’ingestion.
Solution
Une limitation de débit peut réduire votre trafic, voire améliorer le débit en réduisant le nombre d’enregistrements envoyés à un service sur une période donnée.
Un service peut être limité en fonction de différentes métriques au fil du temps, par exemple :
- Nombre d’opérations (par exemple, 20 requêtes par seconde).
- Quantité de données (par exemple, 2 Gio par minute).
- Coût relatif des opérations (par exemple, 20 000 unités de requête par seconde).
Quelle que soit la mesure utilisée pour la limitation, l’implémentation de votre limitation de débit implique le contrôle du nombre et/ou de la taille des opérations envoyées au service sur une période spécifique, ce qui optimise l’utilisation du service sans dépasser sa capacité de limitation.
Dans des scénarios où vos API peuvent gérer des requêtes plus rapidement que n’importe quel service d’ingestion limité, vous devez gérer la cadence avec laquelle vous pouvez utiliser le service. Toutefois, il est risqué de se contenter de traiter la limitation comme un problème de discordance de débit de données et de mettre en mémoire tampon les requêtes d’ingestion jusqu’à ce que le service limité puisse rattraper le retard. Si votre application tombe en panne dans ce scénario, vous risquez de perdre toutes les données mises en mémoire tampon.
Pour éviter ce risque, envisagez d’envoyer vos enregistrements à un système de messagerie durable qui peut gérer votre débit d’ingestion complet (des services tels qu’Azure Event Hubs peuvent gérer des millions d’opérations par seconde). Vous pouvez ensuite utiliser un ou plusieurs processeurs de tâches pour lire les enregistrements à partir du système de messagerie à une cadence contrôlée s’inscrivant dans les limites du service limité. L’envoi d’enregistrements au système de messagerie permet d’économiser de la mémoire interne ne vous permettant d’extraire de la file d’attente que les enregistrements qui peuvent être traités pendant un intervalle de temps donné.
Azure fournit quelques services de messagerie durables que vous pouvez utiliser avec ce modèle, savoir :
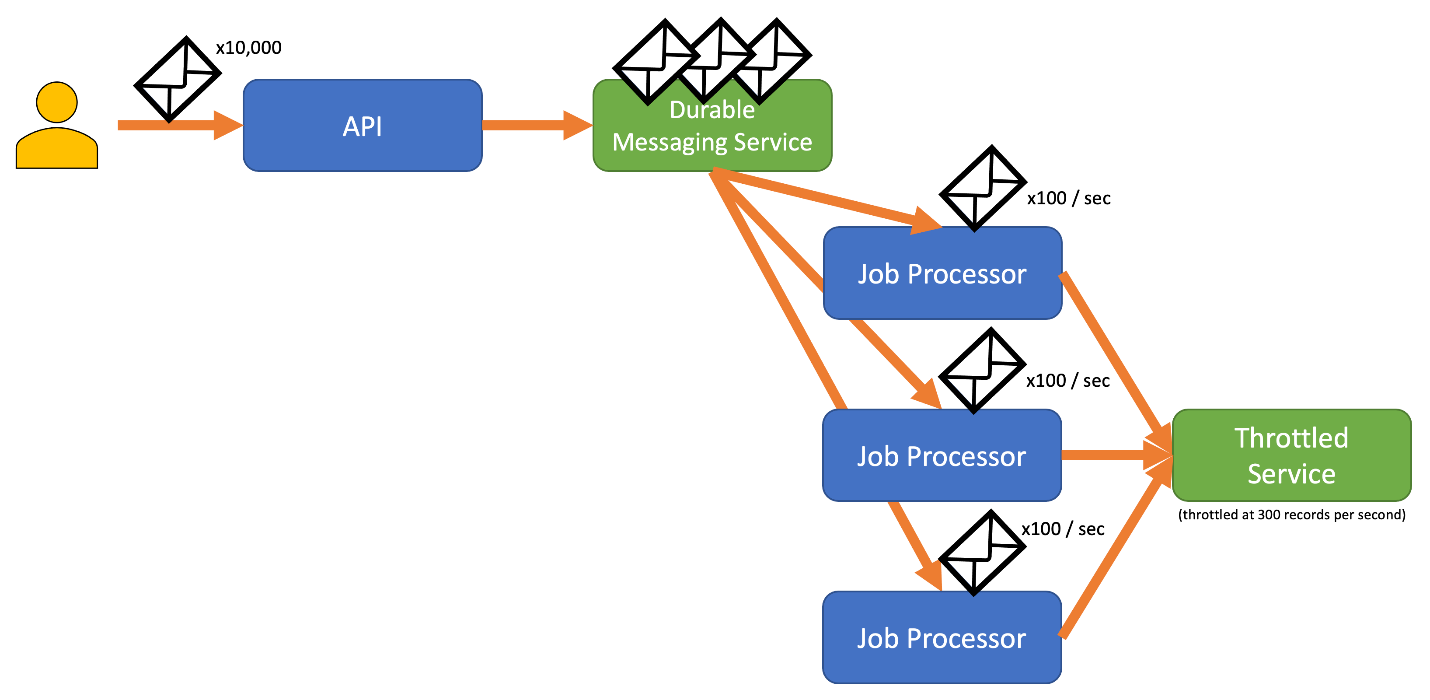
Quand vous envoyez des enregistrements, il se peut que la période de temps que vous utilisez pour libérer des enregistrements soit plus précise que la période sur laquelle le service est limité. Les systèmes définissent souvent des limitations basées sur des intervalles de temps que vous pouvez facilement comprendre et utiliser. Toutefois, pour l’ordinateur qui exécute un service, ces intervalles peuvent être très longs par rapport à la vitesse à laquelle il peut traiter les informations. Par exemple, un système peut appliquer une limitation par seconde ou par minute, alors que la vitesse d’exécution du code est généralement de l’ordre de quelques nanosecondes ou millisecondes.
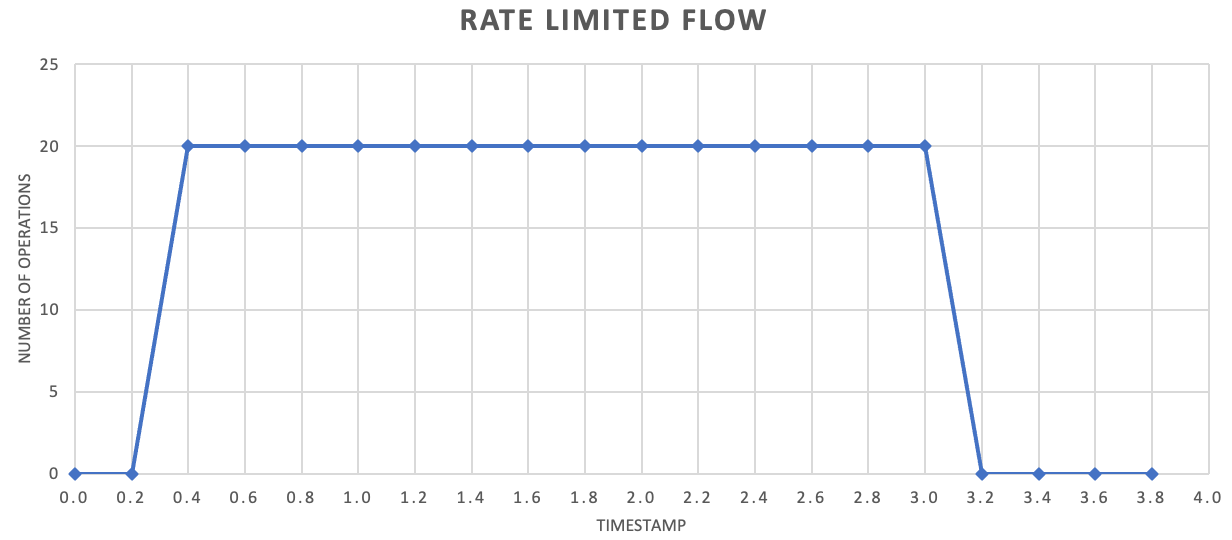
Même si ce n’est pas obligatoire, il est souvent recommandé d’envoyer plus souvent de plus petites quantités d’enregistrements pour améliorer le débit. Ainsi, au lieu d’essayer de libérer un lot par seconde ou par minute, vous pouvez être plus granulaire que cela, afin de maintenir un flux de consommation de vos ressources (mémoire, processeur, réseau, etc.) plus régulier, ce qui permet d’éviter la formation d’éventuels goulets d’étranglement résultant de rafales soudaines de requêtes. Par exemple, si un service autorise 100 opérations par seconde, l’implémentation d’un limiteur de débit peut égaliser les requêtes en soumettant 20 opérations toutes les 200 millisecondes, comme illustré dans le graphique suivant.
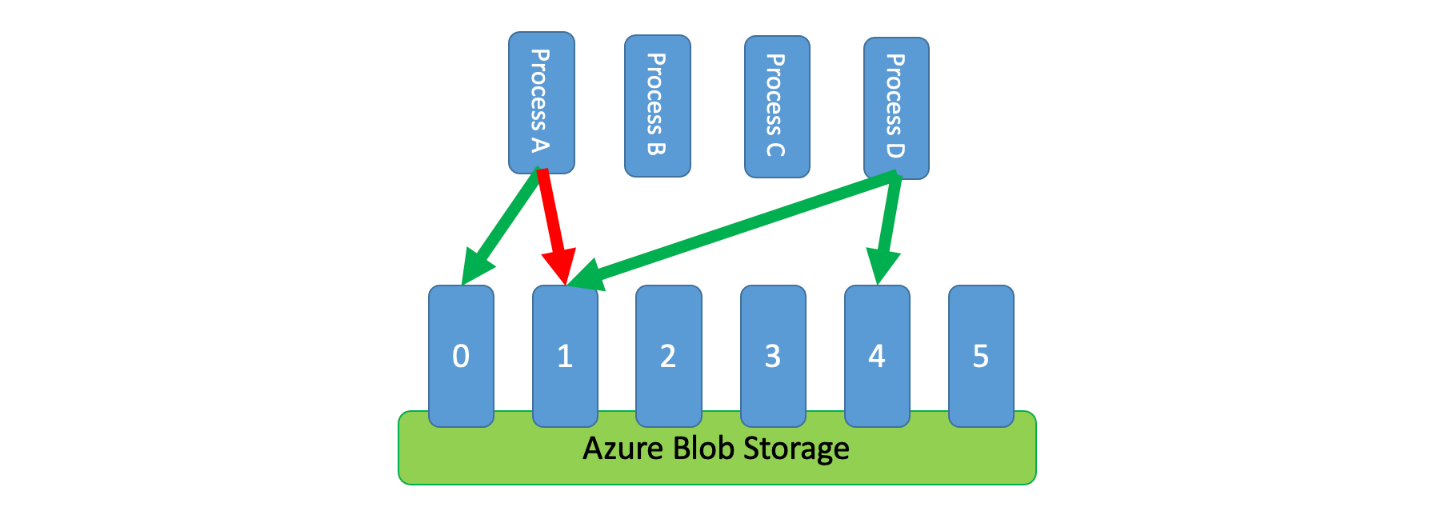
Par ailleurs, il est parfois nécessaire que plusieurs processus non coordonnés partagent un service limité. Pour implémenter une limitation de débit dans ce scénario, vous pouvez partitionner logiquement la capacité du service, puis utiliser un système d’exclusion mutuelle distribuée pour gérer les verrous exclusifs sur ces partitions. Les processus non coordonnés peuvent alors rivaliser pour les verrous de ces partitions quand ils ont besoin de capacité. Une certaine capacité est allouée à chaque partition pour laquelle un processus détient un verrou.
Par exemple, si le système limité autorise 500 requêtes par seconde, vous pouvez créer 20 partitions pour 25 requêtes par seconde chacune. Si un processus doit émettre 100 requêtes, il peut demander quatre partitions au système d’exclusion mutuelle distribuée. Le système peut accorder deux partitions pendant 10 secondes. Le processus limite alors le débit à 50 requêtes par seconde, accomplit la tâche en deux secondes, puis libère le verrou.
L’une des façons d’implémenter ce modèle consiste à utiliser le service Stockage Azure. Dans ce scénario, vous créez un blob de 0 octet par partition logique dans un conteneur. Vos applications peuvent alors obtenir des baux exclusifs directement sur ces blobs pendant une brève période de temps (par exemple, 15 secondes). Pour chaque bail accordé à une application, celle-ci peut utiliser la capacité de cette partition. L’application doit alors effectuer le suivi de la durée du bail afin qu’à l’expiration de celui-ci elle puisse cesser d’utiliser la capacité qui lui a été accordée. Lors de l’implémentation de ce modèle, il peut être souhaitable que chaque processus tente de louer une partition aléatoire quand il en a besoin.
Pour réduire encore davantage la latence, vous pouvez allouer une petite quantité de capacité exclusive à chaque processus. Un processus ne cherche alors à obtenir un bail sur une capacité partagée que s’il a besoin de dépasser sa capacité réservée.
En guise d’alternative au service Stockage Azure, vous pouvez implémenter ce type de système de gestion de bail à l’aide de technologies telles que Zookeeper, Consul, etcd, Redis/Redsync, etc.
Problèmes et considérations
Au moment de choisir comment implémenter ce modèle, prenez en compte les points suivants :
- Bien que le modèle de limitation de débit puisse réduire le nombre d’erreurs de limitation, votre application doit toujours gérer correctement les erreurs de limitation susceptibles de se produire.
- Si votre application contient plusieurs flux de travail qui accèdent au même service limité, vous devez les intégrer à votre stratégie de limitation de débit. Par exemple, vous pouvez prendre en charge des enregistrements de chargement en masse dans une base de données, ainsi que l’interrogation des enregistrements dans cette même base de données. Vous pouvez gérer la capacité en veillant à ce que tous les flux de flux soient contrôlés via le même mécanisme de limitation de débit. Vous pouvez également réserver des pools de capacité distincts pour chaque flux de travail.
- Le service limité peut être utilisé dans plusieurs applications. Dans certains, il est possible de coordonner cette utilisation (comme ci-dessus). Si vous voyez un nombre d’erreurs de limitation plus élevé que prévu, cela peut indiquer un conflit entre les applications qui accèdent à un service. Dans ce cas, vous devez peut-être envisager de réduire temporairement le débit imposé par votre mécanisme de limitation de débit jusqu’à ce que l’utilisation d’autres applications diminue.
Quand utiliser ce modèle
Utilisez ce modèle pour :
- Réduire les erreurs de limitation déclenchées par un service limité par un seuil.
- Réduire le trafic par rapport à une approche naïve de nouvelle tentative en cas d’erreur.
- Réduire la consommation de mémoire ne laissant des enregistrements sortir de la file d’attente que s’il existe une capacité suffisante pour les traiter.
Conception de la charge de travail
Un architecte doit évaluer comment le modèle de Limitation de taux (Rate limiting) peut être utilisé dans la conception de leur charge de travail pour répondre aux objectifs et principes couverts par les piliers d’Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| Les décisions relatives à la fiabilité contribuent à rendre votre charge de travail résiliente aux dysfonctionnements et à s’assurer qu’elle retrouve un état de fonctionnement optimal après une défaillance. | Cette tactique protège le client en reconnaissant et en respectant les limitations et les coûts de communication avec un service lorsque le service souhaite éviter une utilisation excessive. - RE :07 Auto-conservation |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Exemple
L’exemple d’application suivant permet aux utilisateurs d’envoyer des enregistrements de divers types à une API. Il existe un processeur de tâches unique pour chaque type d’enregistrement, qui accomplit les étapes suivantes :
- Validation
- Enrichissement
- Insertion de l’enregistrement dans la base de données
Tous les composants de l’application (API, processeur de tâches A et processeur de tâches B) sont des processus distincts qui peuvent être mis à l’échelle indépendamment. Les processus ne communiquent pas directement entre eux.
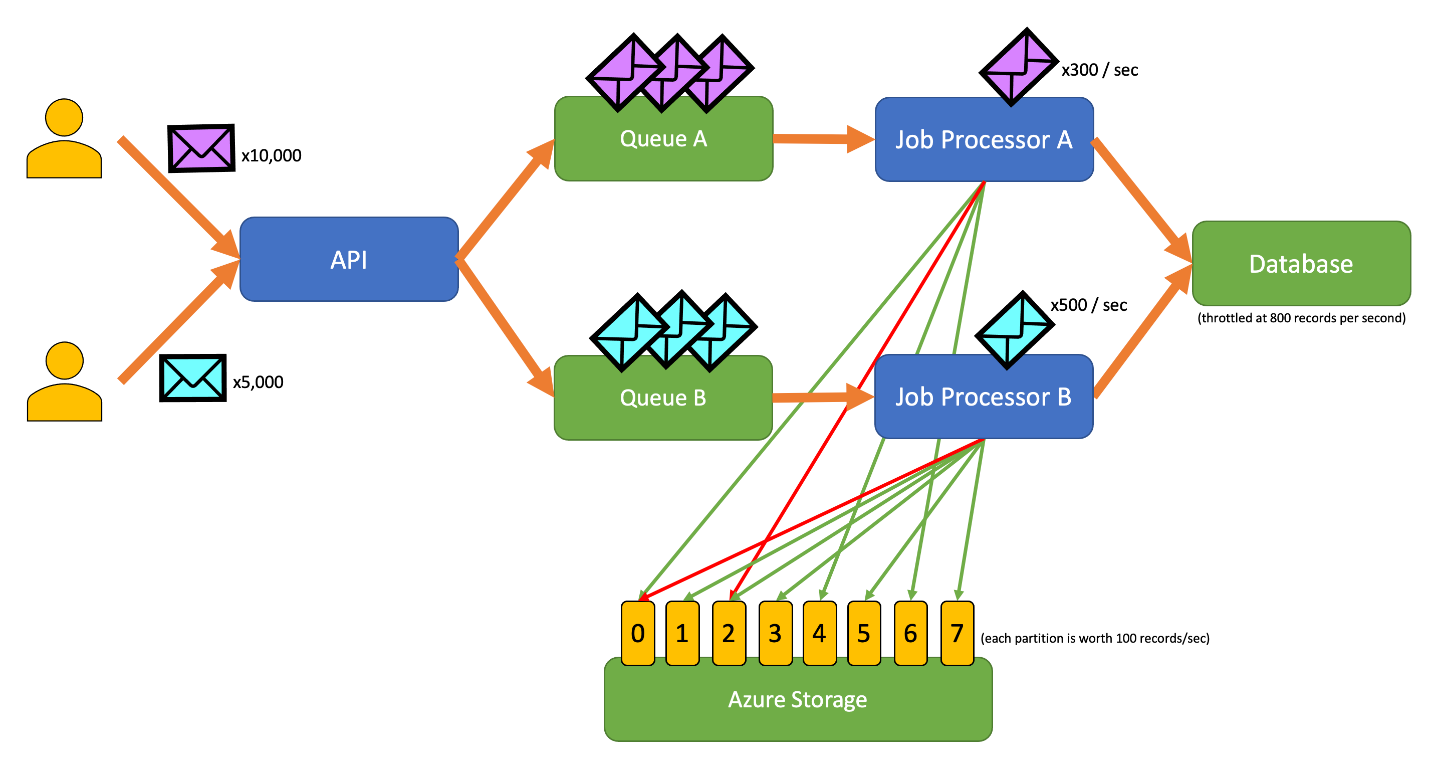
Ce diagramme incorpore le flux de travail suivant :
- Un utilisateur envoie 10 000 enregistrements de type A à l’API.
- L’API met en file d’attente ces 10 000 enregistrements dans la File d’attente A.
- Un utilisateur envoie 5 000 enregistrements de type B à l’API.
- L’API met en file d’attente ces 5 000 enregistrements dans la File d’attente B.
- Le Processeur de tâches A voit que la File d’attente A contient des enregistrements, et tente d’obtenir un bail exclusif sur le blob 2.
- Le Processeur de tâches B voit que la File d’attente B contient des enregistrements, et tente d’obtenir un bail exclusif sur le blob 2.
- Le Processeur de tâches A ne parvient pas à obtenir le bail.
- Le Processeur de tâches B obtient le bail sur le blob 2 pendant 15 secondes. Il peut à présent limiter le débit des requêtes adressées à la base de données, à 100 requêtes par seconde.
- Le Processeur de tâches B extrait 100 enregistrements de la file d’attente B et les écrit.
- Une seconde passe.
- Le Processeur de tâches A voit que la File d’attente A contient davantage d’enregistrements, et tente d’obtenir un bail exclusif sur le blob 6.
- Le Processeur de tâches B voit que la File d’attente B contient davantage d’enregistrements, et tente d’obtenir un bail exclusif sur le blob 3.
- Le Processeur de tâches B obtient le bail sur le blob 6 pendant 15 secondes. Il peut à présent limiter le débit des requêtes adressées à la base de données, à 100 requêtes par seconde.
- Le Processeur de tâches B obtient le bail sur le blob 3 pendant 15 secondes. Il peut à présent limiter le débit des requêtes adressées à la base de données, à 200 requêtes par seconde. (Il conserve également le bail pour le blob 2.)
- Le Processeur de tâches A extrait 100 enregistrements de la file d’attente A et les écrit.
- Le Processeur de tâches B extrait 200 enregistrements de la file d’attente B et les écrit.
- Une seconde passe.
- Le Processeur de tâches A voit que la File d’attente A contient davantage d’enregistrements, et tente d’obtenir un bail exclusif sur le blob 0.
- Le Processeur de tâches B voit que la File d’attente B contient davantage d’enregistrements, et tente d’obtenir un bail exclusif sur le blob 1.
- Le Processeur de tâches B obtient le bail sur le blob 0 pendant 15 secondes. Il peut à présent limiter le débit des requêtes adressées à la base de données, à 200 requêtes par seconde. (Il conserve également le bail pour le blob 6.)
- Le Processeur de tâches B obtient le bail sur le blob 1 pendant 15 secondes. Il peut à présent limiter le débit des requêtes adressées à la base de données, à 300 requêtes par seconde. (Il conserve également le bail pour les blobs 2 et 3.)
- Le Processeur de tâches A extrait 200 enregistrements de la file d’attente A et les écrit.
- Le Processeur de tâches B extrait 300 enregistrements de la file d’attente B et les écrit.
- Et ainsi de suite...
Au bout de 15 secondes, l’un des travaux ou les deux ne sont pas encore terminés. À mesure que les baux expirent, un processeur doit également réduire le nombre de requêtes qu’il extrait et écrit.
 Les implémentations de ce modèle sont disponibles dans différents langages de programmation :
Les implémentations de ce modèle sont disponibles dans différents langages de programmation :
Ressources associées
Les modèles et les conseils suivants peuvent aussi présenter un intérêt quand il s’agit d’implémenter ce modèle :
- Limitation. Le modèle de limitation de débit abordé ici est généralement implémenté en réponse à un service limité.
- Nouvelle tentative. Quand des requêtes adressées à un service limité entraînent des erreurs de limitation, il convient généralement de les réessayer après un intervalle approprié.
Le nivellement de charge basé sur les files d’attente est similaire au modèle de limitation de débit, mais en diffère sur plusieurs points essentiels :
- Une limitation de débit n’a pas nécessairement besoin d’utiliser des files d’attente pour gérer la charge, mais elle a besoin d’utiliser un service de messagerie durable. Par exemple, un modèle de limitation de débit peut utiliser des services tels qu’Apache Kafka ou Azure Event Hubs.
- Le modèle de limitation de débit introduit le concept de système d’exclusion mutuelle distribuée sur les partitions, qui vous permet de gérer la capacité de plusieurs processus non coordonnés qui communiquent avec le même service limité.
- Un modèle de nivellement de charge basé sur les files d’attente est applicable à chaque fois qu’il existe une discordance de performances entre des services ou pour améliorer la résilience. Il s’agit donc d’un modèle plus large que la limitation de débit, qui concerne plus spécifiquement l’accès efficace à un service limité.