Coordonnez un ensemble d’actions distribuées en une seule opération. Si une des actions échoue, essayez de gérer les échecs de façon transparente ou annulez le travail qui était effectué, de sorte que l’intégralité de l’opération réussisse ou échoue. Cela peut doter un système distribué de capacités de résilience en lui permettant de récupérer et de réessayer des actions qui échouent en raison d’exceptions temporaires, d’erreurs de longue durée et d’échecs de processus.
Contexte et problème
Une application effectue des tâches comprenant plusieurs étapes, dont certaines nécessitent l’utilisation de services distants ou l’accès à des ressources distantes. Les étapes peuvent être indépendantes les unes des autres, mais elles restent orchestrées par la logique d’application qui implémente la tâche.
Dès que possible, l’application doit s’assurer que la tâche s’exécute jusqu’au bout et résoudre les échecs susceptibles de se produire lors de l’accès à des ressources ou des services distants. Les échecs peuvent avoir de nombreuses causes. Par exemple, le réseau peut être hors service, les communications peuvent être interrompues, un service distant peut ne pas répondre ou se trouver dans un état instable, ou une ressource distante peut être temporairement inaccessible, notamment en raison de contraintes de ressources. Dans de nombreux cas, les échecs sont temporaires et peuvent être gérés à l’aide du modèle Nouvelle tentative.
Si l’application détecte une erreur plus permanente de laquelle elle ne peut pas récupérer facilement, elle doit être en mesure de restaurer le système à un état cohérent et de garantir l’intégrité de l’ensemble de l’opération.
Solution
Le modèle de superviseur de l’agent du planificateur définit les acteurs suivants. Ces acteurs orchestrent les étapes à effectuer dans le cadre de la tâche globale.
Le planificateur fait en sorte que les étapes qui composent la tâche soient exécutées et orchestre leur opération. Ces étapes peuvent être combinées dans un pipeline ou un flux de travail. Le planificateur est chargé de s’assurer que les étapes de ce flux de travail sont effectuées dans le bon ordre. À mesure que chaque étape est effectuée, le planificateur enregistre l’état du workflow, par exemple « étape pas encore démarrée », « étape en cours d’exécution » ou « étape terminée ». Les informations d’état doivent également inclure une limite maximale de temps pour l’exécution de l’étape, appelée heure limite d’achèvement. Si une étape doit pouvoir accéder à une ressource ou un service distant, le planificateur appelle l’agent approprié, en lui transmettant les détails du travail à accomplir. Le planificateur s’appuie généralement sur une messagerie requête/réponse asynchrone pour communiquer avec un agent. Celle-ci peut être implémentée à l’aide de files d’attente, mais aussi à l’aide des autres technologies de messagerie distribuée.
Le planificateur exécute une fonction similaire à celle du gestionnaire de processus dans le modèle de gestionnaire de processus. Le flux de travail proprement dit est généralement défini et implémenté par un moteur de flux de travail contrôlé par le planificateur. Cette approche permet de dissocier du planificateur la logique métier incluse dans le flux de travail.
L’agent contient une logique qui encapsule un appel à un service distant ou l’accès à une ressource distante référencée par une étape d’une tâche. Chaque agent inclut généralement dans un wrapper les appels à un service ou une ressource unique, en implémentant la logique de gestion des erreurs ou de nouvelle tentative appropriée (soumise à un délai d’attente limite, comme décrit plus loin dans cet article). Quand vous implémentez une logique de nouvelle tentative, passez un identificateur stable sur toutes les tentatives afin que le service distant puisse l’utiliser pour les logiques de déduplication éventuelles. Si les étapes du flux de travail exécuté par le planificateur utilisent plusieurs services et ressources pour les différentes étapes, chaque étape peut référencer un autre agent (il s’agit d’un détail d’implémentation du modèle).
Le superviseur surveille l’état des étapes de la tâche exécutée par le planificateur. Il s’exécute régulièrement (la fréquence est propre au système) et examine l’état des étapes gérées par le Scheduler. S’il détecte des étapes dont le délai d’attente a expiré ou qui ont échoué, il fait en sorte que l’agent approprié récupère l’étape ou mette en œuvre la mesure corrective appropriée (cela peut impliquer la modification de l’état d’une étape). Notez que les mesures de récupération ou correctives sont implémentées par le planificateur et les agents. Le superviseur doit simplement demander que ces mesures soient mises en œuvre.
Le planificateur, l’agent et le superviseur sont des composants logiques dont l’implémentation physique dépend de la technologie utilisée. Par exemple, plusieurs agents logiques peuvent être implémentés dans un même service web.
Le planificateur conserve les informations sur la progression de la tâche et l’état de chaque étape dans un magasin de données durable, appelé magasin d’état. Le superviseur peut utiliser ces informations pour déterminer si une étape a échoué. La figure suivante illustre la relation entre le planificateur, les agents, le superviseur et le magasin d’état.
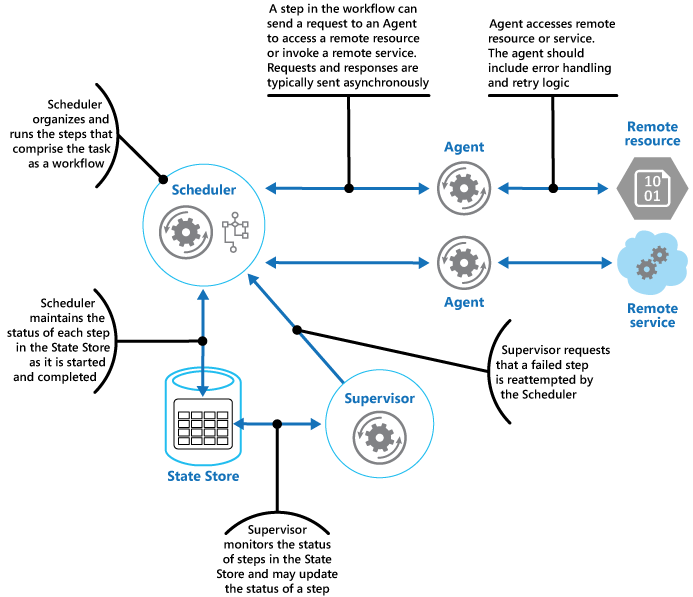
Notes
Ce diagramme présente une version simplifiée du modèle. Dans une implémentation réelle, plusieurs instances du planificateur peuvent s’exécuter simultanément, chacune constituée d’un sous-ensemble de tâches. De même, le système peut exécuter plusieurs instances de chaque agent, voire plusieurs superviseurs. Dans ce cas, les superviseurs doivent coordonner soigneusement leur travail entre eux pour s’assurer qu’ils ne cherchent pas à récupérer les mêmes étapes et tâches ayant échoué. Le modèle d’élection du responsable offre une solution possible à ce problème.
Quand l’application est prête à exécuter une tâche, elle soumet une requête au planificateur. Le planificateur enregistre les informations d’état initiales sur la tâche et ses étapes (par exemple, « step not yet started » (étape pas encore démarrée)) dans le magasin d’état, puis commence à exécuter les opérations définies par le flux de travail. Quand le planificateur commence chaque étape, il met à jour les informations sur l’état de l’étape en question dans le magasin d’état (par exemple, « step running » (étape en cours d’exécution)).
Si une étape référence une ressource ou un service distant, le planificateur envoie un message à l’agent approprié. Le message contient les informations que l’agent doit transmettre au service ou dont il a besoin pour accéder à la ressource, ainsi que l’heure limite d’achèvement de l’opération. Si l’agent accomplit son opération avec succès, il renvoie une réponse au planificateur. Le planificateur peut alors mettre à jour les informations d’état dans le magasin d’état (par exemple, « step completed » (étape terminée)) et effectuer l’étape suivante. Ce processus se poursuit jusqu’à ce que la tâche entière soit terminée.
Un agent peut implémenter n’importe quelle logique de nouvelle tentative nécessaire pour accomplir son travail. Cependant, si l’agent ne termine son travail avant le dépassement de l’heure limite d’achèvement, le planificateur suppose que l’opération a échoué. Dans ce cas, l’agent doit arrêter son travail et ne doit pas essayer de renvoyer quoi que ce soit au planificateur (pas même un message d’erreur) ou tenter de mettre en œuvre une forme quelconque de récupération. En effet, après que le délai d’attente d’une étape a expiré ou que celle-ci a échoué, une autre instance de l’agent peut être programmée pour exécuter l’étape ayant échoué (ce processus est décrit plus loin).
Si l’agent échoue, le planificateur ne reçoit pas de réponse. Le modèle ne fait pas de distinction entre une étape dont le délai d’attente a expiré et une étape qui a réellement échoué.
Si le délai d’attente d’une étape expire ou si celle-ci échoue, le magasin d’état contiendra un enregistrement indiquant que l’étape est en cours d’exécution, mais l’heure limite d’achèvement sera dépassée. Le superviseur recherche les étapes dans cette situation et essaie de les récupérer. Une stratégie possible pour le superviseur consiste à mettre à jour la valeur de l’heure limite d’achèvement afin d’augmenter le temps disponible pour terminer l’étape, puis à envoyer au planificateur un message identifiant l’étape dont le délai d’attente a expiré. Le planificateur peut alors tenter de répéter cette étape. Cependant, cette conception requiert que les tâches soient idempotentes. Le système doit contenir une infrastructure à des fins de maintien de la cohérence. Pour plus d’informations, consultez Infrastructure reproductible, Intégrer la résilience et la disponibilité à l’architecture des applications Azure, et Guide de décision pour la cohérence des ressources.
Le superviseur peut avoir besoin d’empêcher que la même étape fasse l’objet de nouvelles tentatives si elle échoue ou si son délai d’attente expire continuellement. Pour ce faire, le superviseur peut conserver un compteur du nombre de nouvelles tentatives pour chaque étape, en plus des informations d’état, dans le magasin d’état. Si ce nombre dépasse un seuil prédéfini, le superviseur peut adopter une stratégie consistant à attendre plus longtemps avant de signaler au planificateur qu’il doit réessayer cette étape, en partant du principe que l’erreur pourra être résolue pendant cette période. Le superviseur peut également envoyer un message au planificateur pour demander l’annulation de la tâche entière en implémentant un modèle de transaction de compensation. Cette approche implique que le planificateur et les agents fournissent les informations nécessaires afin d’implémenter les opérations de compensation pour chaque étape qui s’est terminée correctement.
Le superviseur n’a pas pour rôle de surveiller le planificateur et les agents, et de les redémarrer s’ils venaient à échouer. Cet aspect du système doit être géré par l’infrastructure dans laquelle ces composants sont exécutés. De même, le superviseur ne doit pas avoir connaissance des opérations métier exécutées par les tâches accomplies par le planificateur (y compris le mode de compensation en cas d’échec de ces tâches). C’est le rôle de la logique de flux de travail implémentée par le planificateur. La seule responsabilité du superviseur consiste à déterminer si une étape a échoué et à faire en sorte qu’elle soit répétée ou que l’intégralité de la tâche contenant l’étape qui a échoué soit annulée.
Si le planificateur est redémarré après un échec ou si le flux de travail exécuté par le planificateur s’arrête de manière inattendue, le planificateur doit être en mesure de déterminer l’état des tâches en cours au moment de l’échec et être prêt à reprendre cette tâche à partir de ce point. Les détails d’implémentation de ce processus sont le plus souvent propres au système. Si la tâche ne peut pas être récupérée, il peut être nécessaire d’annuler le travail déjà effectué par la tâche. L’implémentation d’une transaction de compensation peut également être requise.
Le principal avantage de ce modèle est que le système est résilient en cas d’échec temporaire ou irrécupérable inattendu. Le système peut être construit de manière à être doté d’une capacité d’auto-réparation. Par exemple, si un agent ou le planificateur échoue, un nouvel agent peut être démarré et le superviseur peut faire en sorte que l’exécution d’une tâche reprenne. Si le superviseur échoue, une autre instance peut être démarrée et peut reprendre là où l’échec s’est produit. Si le superviseur est programmé pour s’exécuter périodiquement, une nouvelle instance peut être démarrée automatiquement après un intervalle prédéfini. Le magasin d’état peut être répliqué afin d’augmenter encore plus le degré de résilience.
Problèmes et considérations
Prenez en compte les points suivants quand vous choisissez comment implémenter ce modèle :
Ce modèle peut être difficile à implémenter et nécessite des tests approfondis de chaque mode d’échec possible du système.
La logique de récupération/nouvelle tentative implémentée par le planificateur est complexe et dépend des informations d’état stockées dans le magasin d’état. Il peut également être nécessaire d’enregistrer les informations requises pour implémenter une transaction de compensation dans un magasin de données durable. Une transaction de compensation peut également échouer.
La fréquence d’exécution du superviseur a de l’importance. Il doit s’exécuter assez souvent pour empêcher des étapes ayant échoué de bloquer une application pendant une période prolongée, mais pas non plus trop souvent, sous peine de devenir une surcharge.
Les étapes effectuées par un agent peuvent être exécutées plusieurs fois. La logique qui implémente ces étapes doit être idempotente.
Quand utiliser ce modèle
Utilisez ce modèle si un processus qui s’exécute dans un environnement distribué, tel que le cloud, doit être résistant aux échecs de communication ou opérationnels.
Ce modèle peut ne pas être adapté aux tâches qui n’appellent pas de services distants ou qui n’accèdent pas à des ressources distantes.
Conception de la charge de travail
Un architecte devrait évaluer de quelle manière le modèle Superviseur d’Agent Planificateur peut être utilisé dans la conception de sa charge de travail pour répondre aux objectifs et principes couverts par les piliers du piliers d’Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| Les décisions relatives à la fiabilité contribuent à rendre votre charge de travail résiliente aux dysfonctionnements et à s’assurer qu’elle retrouve un état de fonctionnement optimal après une défaillance. | Ce modèle utilise des métriques d’intégrité pour détecter les défaillances et réacheminer les tâches vers un agent sain afin de limiter les effets d’un dysfonctionnement. - RE :05 Redondance - RE:07 Auto-réparation |
| L’efficacité des performances permet à votre charge de travail de répondre efficacement aux demandes grâce à des optimisations de la mise à l’échelle, des données, du code. | Ce modèle utilise des métriques de performance et de capacité pour détecter l’utilisation actuelle et acheminer les tâches vers un agent qui a de la capacité. Vous pouvez également l’utiliser pour prioriser l’exécution des travaux de plus haute priorité sur les travaux de moindre priorité. - PE :05 Mise à l’échelle et partitionnement - PE :09 Flux critiques |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Exemple
Une application web qui implémente un système de commerce électronique a été déployée sur Microsoft Azure. Les utilisateurs peuvent exécuter cette application pour parcourir les produits disponibles et passer des commandes. L’interface utilisateur s’exécute comme un rôle Web, et les éléments de traitement des commandes de l’application sont implémentés comme un ensemble de rôles de travail. Une partie de cette logique de traitement des commandes implique l’accès à un service distant, et cet aspect du système peut être sujet à des erreurs temporaires ou de longue durée. Par conséquent, les concepteurs ont utilisé le modèle de superviseur de l’agent du planificateur pour implémenter les éléments de traitement des commandes du système.
Quand un client passe une commande, l’application construit un message qui décrit la commande et publie ce message dans une file d’attente. Un processus de soumission distinct, s’exécutant dans un rôle de travail, récupère le message, insère les détails de la commande dans la base de données de commandes et crée un enregistrement pour le processus de commande dans le magasin d’état. Notez que les insertions dans la base de données de commandes et le magasin d’état sont effectuées dans le cadre de la même opération. Le processus de soumission est conçu pour garantir que les deux insertions se terminent ensemble.
Les informations d’état créées pour la commande par le processus de soumission incluent :
OrderID. ID de la commande dans la base de données de commandes.
LockedBy. ID d’instance du rôle de travail gérant la commande. Il peut y avoir plusieurs instances actuelles du rôle de travail qui exécutent le planificateur, mais chaque commande doit être gérée par une instance unique.
CompleteBy. Heure avant laquelle la commande doit être traitée.
ProcessState. État actuel de la tâche gérant la commande. Les états possibles sont :
- En attente. La commande a été créée, mais le traitement n’a pas encore commencé.
- Processing. La commande est en cours de traitement.
- Processed. La commande a été traitée avec succès.
- Error. Le traitement de la commande a échoué.
FailureCount. Nombre de fois que le traitement a été tenté pour la commande.
Dans ces informations d’état, le champ OrderID est copié à partir de l’ID de commande de la nouvelle commande. Les champs LockedBy et CompleteBy sont définis sur null, le champ ProcessState sur Pending et le champ FailureCount sur 0.
Notes
Dans cet exemple, la logique de traitement des commandes est relativement simple et ne comprend qu’une seule étape qui appelle un service distant. Dans un scénario à plusieurs étapes plus complexe, le processus d’envoi impliquerait probablement plusieurs étapes et plusieurs enregistrements seraient donc créés dans le magasin d’état, chacun d’entre eux décrivant l’état d’une étape individuelle.
Le planificateur s’exécute également dans le cadre d’un rôle de travail et implémente la logique métier qui gère la commande. Une instance du planificateur cherchant à déterminer s’il existe de nouvelles commandes examine le magasin d’état pour détecter des enregistrements dont le champ LockedBy présente la valeur « null » et le champ ProcessState la valeur « Pending ». Quand le planificateur trouve une nouvelle commande, il renseigne immédiatement le champ LockedBy avec son propre ID d’instance, définit le champ CompleteBy sur une heure appropriée et définit le champ ProcessState sur « Processing ». Le code est conçu pour être exclusif et atomique afin de garantir que deux instances simultanées du planificateur ne peuvent pas essayer de gérer la même commande en même temps.
Le planificateur exécute ensuite le flux de travail métier pour traiter la commande de façon asynchrone, en lui transmettant la valeur du champ OrderID à partir du magasin d’état. Le flux de travail gérant la commande récupère les détails de la commande à partir de la base de données de commandes et accomplit son travail. Quand une étape du flux de travail de traitement des commandes doit appeler le service distant, elle utilise un agent. L’étape du flux de travail communique avec l’agent à l’aide de deux files d’attente de messages Azure Service Bus qui jouent le rôle de canal de requête/réponse. La figure suivante présente une vue d’ensemble de la solution.
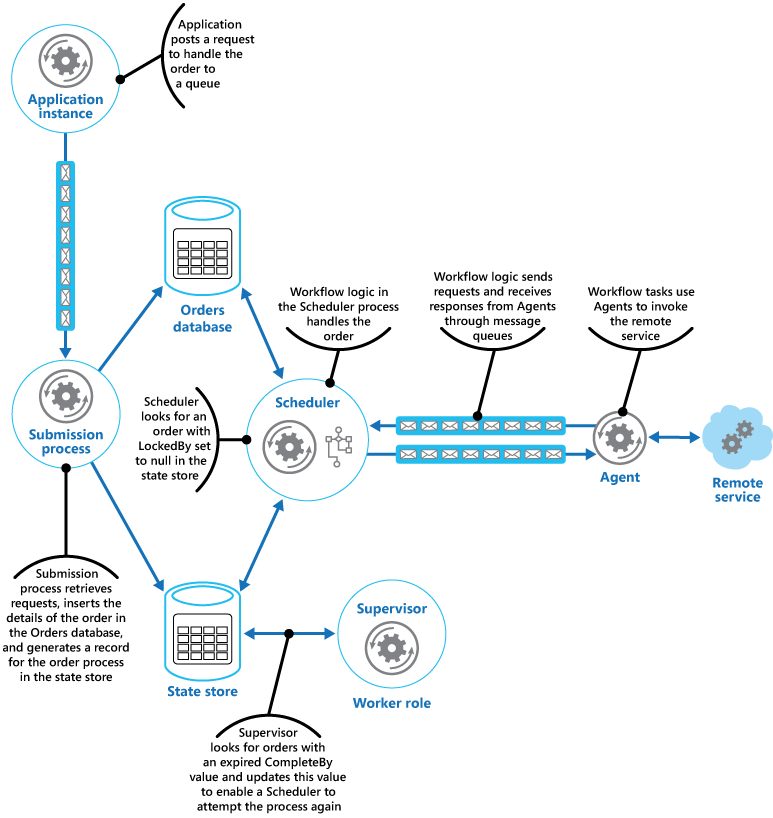
Le message envoyé à l’agent par une étape du flux de travail décrit la commande et inclut l’heure limite d’achèvement. Si l’agent reçoit une réponse du service distant avant l’heure limite d’achèvement, il publie un message de réponse dans la file d’attente Service Bus sur laquelle le flux de travail écoute. Quand l’étape du flux de travail reçoit le message de réponse valide, il termine son traitement et le Scheduler définit le champ ProcessState de l’état de la commande sur « Traité ». Le traitement de la commande est alors terminé.
Si l’heure limite d’achèvement est dépassée avant que l’agent reçoive une réponse du service distant, l’agent cesse simplement son traitement et arrête de gérer la commande. De même, si le flux de travail qui gère la commande dépasse l’heure limite d’achèvement, il s’arrête également. Dans les deux cas, l’état de la commande dans le magasin d’état reste défini sur « Processing », mais l’heure limite d’achèvement indique que le délai autorisé pour le traitement de la commande a été dépassé et le processus est considéré comme ayant échoué. Notez que si l’agent qui accède au service distant ou le flux de travail qui gère la commande (ou les deux) s’arrête de manière inattendue, les informations contenues dans le magasin d’état resteront aussi définies sur « Processing » et finiront par présenter une valeur d’heure limite d’achèvement dépassée.
Si l’agent détecte une erreur irrécupérable et non temporaire pendant qu’il tente de contacter le service distant, il peut renvoyer une réponse d’erreur au flux de travail. Le planificateur peut définir l’état de la commande sur « Error » et déclencher un événement qui alerte un opérateur. L’opérateur peut ensuite tenter d’éliminer manuellement la cause de l’échec, puis soumettre à nouveau l’étape de traitement ayant échoué.
Le superviseur examine régulièrement le magasin d’état à la recherche de commandes présentant une valeur d’heure limite d’achèvement dépassée. Si le superviseur trouve un tel enregistrement, il incrémente le champ FailureCount. Si le nombre d’échecs est inférieur à un seuil spécifié, le superviseur réinitialise le champ LockedBy sur « null », met à jour le champ CompleteBy avec une nouvelle heure d’expiration et définit le champ ProcessState sur « pending ». Une instance du planificateur peut récupérer cette commande et effectuer son traitement comme avant. Si le nombre d’échecs dépasse un seuil spécifié, la cause de l’échec est considérée comme non temporaire. Le superviseur définit l’état de la commande sur « Error » et déclenche un événement qui alerte un opérateur.
Dans cet exemple, le superviseur est implémenté dans un rôle de travail distinct. Vous pouvez utiliser diverses stratégies pour faire en sorte que la tâche du superviseur soit exécutée, notamment en recourant au service Azure Scheduler. Pour plus d’informations sur le service Azure Scheduler, rendez-vous sur la page Scheduler.
Bien que cela ne soit pas illustré dans cet exemple, le planificateur peut avoir besoin de tenir informée de la progression et de l’état de la commande l’application qui a soumis la commande. L’application et le planificateur sont isolés l’un de l’autre afin d’éliminer les dépendances entre eux. L’application ignore quelle instance du planificateur gère la commande, et le planificateur ne sait pas quelle instance d’application spécifique a publié la commande.
Pour permettre le signalement de l’état de la commande, l’application peut utiliser sa propre file de réponse privée. Les détails de cette file de réponse sont alors inclus dans la requête envoyée au processus de soumission, qui inclut ces informations dans le magasin d’état. Le planificateur publie ensuite dans cette file des messages indiquant l’état de la commande (requête reçue, commande terminée, échec de la commande, etc.). L’ID de commande doit être inclus dans ces messages afin qu’ils puissent être corrélés avec la requête d’origine envoyée par l’application.
Étapes suivantes
Les recommandations suivantes peuvent aussi s’avérer utiles pendant l’implémentation de ce modèle :
Primer de messagerie asynchrone. En général, les composants du modèle de superviseur de l’agent du planificateur s’exécutent indépendamment les uns des autres et communiquent de manière asynchrone. Cet article décrit quelques-unes des approches qui peuvent être utilisées pour implémenter une communication asynchrone basée sur les files d’attente de messages.
Reference 6: A Saga on Sagas (Référence 6 : une saga des sagas). Exemple illustrant la manière dont le modèle CQRS utilise un gestionnaire de processus (partie de la documentation relative au projet CQRS Journey).
Ressources associées
Les modèles suivants peuvent également être pertinents lors de l’implémentation de ce modèle :
Modèle Nouvelle tentative. Un agent peut utiliser ce modèle pour réessayer de manière transparente une opération qui accède à une ressource ou un service distant ayant échoué précédemment. À utiliser quand la cause de l’échec est considérée comme temporaire et pouvant être corrigée.
Modèle Disjoncteur. Un agent peut utiliser ce modèle pour gérer les erreurs dont la correction prend un certain temps lors de la connexion à une ressource ou à un service distant.
Modèle de transaction de compensation. Si le flux de travail exécuté par un planificateur ne peut pas être mené à bien, il peut être nécessaire d’annuler tout le travail qu’il a déjà effectué. Le modèle de transaction de compensation décrit comment le faire pour les opérations qui suivent le modèle de cohérence éventuelle. Ces types d’opérations sont généralement implémentées par un planificateur qui exécute des flux de travail et des processus métier complexes.
Modèle d’élection du responsable. Il peut être nécessaire de coordonner les actions de plusieurs instances d’un superviseur pour empêcher ces instances de tenter de récupérer le même processus ayant échoué. Le modèle d’élection du responsable décrit comment faire cela.
Architecture cloud : le modèle Planificateur-Agent-Superviseur sur le blog de Clemens Vasters