Idées de solution
Cet article présente une idée de solution. Si vous souhaitez que nous développions le contenu avec d’autres informations, telles que des cas d’usage potentiels, d’autres services, des considérations d’implémentation ou un guide des prix, adressez-nous vos commentaires GitHub.
Implémentez une solution de traitement du langage naturel (NLP) personnalisé dans Azure. Utilisez Spark NLP pour les tâches telles que la détection et l’analyse des thèmes et des sentiments.
Apache®, Apache Spark et le logo représentant une flamme sont soit des marques déposées, soit des marques commerciales d’Apache Software Foundation aux États-Unis et/ou dans d’autres pays. L’utilisation de ces marques n’implique aucune approbation de l’Apache Software Foundation.
Architecture

Téléchargez un fichier Visio de cette architecture.
Workflow
- Le service Azure Event Hubs, le service Azure Data Factory, ou les deux, reçoivent des documents ou des données de texte non structurées.
- Event Hubs et Data Factory stockent les données au format de fichier dans Azure Data Lake Storage. Nous vous recommandons de configurer une structure de répertoire conforme aux besoins métier.
- L’API Azure Vision par ordinateur utilise sa fonctionnalité de reconnaissance optique de caractères (OCR) pour consommer les données. L’API écrit ensuite les données dans la couche Bronze. Cette plateforme de consommation utilise une architecture Lakehouse.
- Dans la couche Bronze, diverses fonctionnalités Spark NLP prétraitent le texte. Les exemples incluent le fractionnement, la correction de l’orthographe, le nettoyage et la compréhension de la grammaire. Nous vous recommandons d’exécuter la classification des documents au niveau de la couche Bronze, puis d’écrire les résultats dans la couche Argent.
- Dans la couche Argent, les fonctionnalités Spark NLP avancées effectuent des tâches d’analyse de document telles que la reconnaissance d’entité nommée, la synthèse et la récupération d’informations. Dans certaines architectures, le résultat est écrit dans la couche Or.
- Dans la couche Or, Spark NLP exécute différentes analyses visuelles linguistiques sur les données de texte. Ces analyses fournissent des insights sur les dépendances de langue et aident à visualiser les étiquettes NER.
- Les utilisateurs interrogent les données de texte de la couche Or en tant que trame de données et affichent les résultats dans Power BI ou des applications web.
Au cours des étapes de traitement, Azure Databricks, Azure Synapse Analytics et Azure HDInsight sont utilisés avec Spark NLP pour fournir des fonctionnalités NLP.
Composants
- Data Lake Storage est un système de fichiers compatible Hadoop qui a un espace de noms hiérarchique intégré, ainsi que la grande échelle et l’économie massives du Stockage Blob Azure.
- Azure Synapse Analytics est un service d’analytique conçu pour les entrepôts de données et les systèmes de Big Data.
- Azure Databricks est un service d’analytique du Big Data facile à utiliser, basé sur Apache Spark, qui favorise la collaboration. Azure Databricks est conçu pour la science des données et l’ingénierie des données.
- Event Hubs ingère des flux de données générés par les applications clientes. Event Hubs stocke les données de streaming et conserve la séquence d’événements reçus. Les consommateurs peuvent se connecter aux points de terminaison de hub pour extraire des messages à traiter. Event Hubs s’intègre à Data Lake Storage, comme le montre cette solution.
- Azure HDInsight est un service cloud d’analyse managé, complet et open source pour les entreprises. Vous pouvez utiliser des infrastructures open source avec Azure HDInsight, comme Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm et R.
- Data Factory déplace automatiquement les données entre des comptes de stockage de différents niveaux de sécurité pour garantir la séparation des tâches.
- La Vision par ordinateur utilise des API de reconnaissance de texte pour reconnaître du texte dans des images et extraire ces informations. L’API Lire utilise les modèles de reconnaissance les plus récents et est optimisée pour les documents contenant beaucoup de texte et les images bruyantes. L’API OCR n’est pas optimisée pour les documents volumineux, mais prend en charge plus de langues que l’API Lire. Cette solution utilise l’OCR pour produire des données au format hOCR.
Détails du scénario
Le traitement du langage naturel (NLP) présente de nombreux usages : l’analyse des sentiments, la détection des thèmes, la détection de la langue, l’extraction de phrases clés et la classification des documents.
Apache Spark est une infrastructure de traitement parallèle qui prend en charge le traitement en mémoire pour améliorer les performances des applications d’analytique du Big Data comme le NLP. Azure Synapse Analytics, Azure HDInsight et Azure Databricks offrent un accès à Spark et tirent parti de sa puissance de traitement.
Pour les charges de travail NLP personnalisées, la bibliothèque open source Spark NLP sert d’infrastructure efficace pour le traitement d’une grande quantité de texte. Cet article présente une solution pour le traitement du langage naturel (NLP) personnalisé à grande échelle dans Azure. La solution utilise des fonctionnalités Spark NLP pour traiter et analyser du texte. Pour plus d’informations sur Spark NLP, consultez Fonctionnalités et pipelines Spark NLP, plus loin dans cet article.
Cas d’usage potentiels
Classification des documents : Spark NLP offre plusieurs options pour la classification de texte :
- Prétraitement de texte dans Spark NLP et les algorithmes de Machine Learning basés sur Spark ML
- Prétraitement de texte et incorporation de mots dans Spark NLP et les algorithmes de Machine Learning tels que GloVe, BERT et ELMo
- Prétraitement de texte et incorporation de phrases dans Spark NLP et les algorithmes de Machine Learning tels que l’encodeur Universal Sentence Encoder
- Prétraitement et classification de texte dans Spark NLP qui utilise l’annotateur ClassifierDL et est basé sur TensorFlow
Extraction d’entité de nom (NER, Name Entity Extraction) : dans Spark NLP, avec quelques lignes de code, vous pouvez entraîner un modèle NER qui utilise BERT, et vous pouvez obtenir une justesse de pointe. NER est une sous-tâche d’extraction d’informations. NER recherche des entités nommées dans du texte non structuré et les classifie en catégories prédéfinies telles que les noms de personnes, les organisations, les emplacements, les codes médicaux, les expressions temporelles, les quantités, les valeurs monétaires et les pourcentages. Spark NLP utilise un modèle NER de pointe avec BERT. Le modèle est inspiré d’un ancien modèle NER : LSTM-CNN bidirectionnel. Cet ancien modèle utilise une nouvelle architecture de réseau neuronal qui détecte automatiquement les fonctionnalités au niveau des mots et au niveau des caractères. À cet effet, le modèle utilise une architecture bidirectionnelle LSTM et CNN bidirectionnelle hybride. Ainsi, la plus grande partie de l’ingénierie des caractéristiques n’est plus nécessaire.
Détection des sentiments et des émotions : Spark NLP peut détecter automatiquement les aspects positifs, négatifs et neutres du langage.
Éléments morphosyntaxiques (POS, Part of speech) : cette fonctionnalité affecte une étiquette grammaticale à chaque jeton dans le texte d’entrée.
Détection des phrases (SD, Sentence detection) : SD est basé sur un modèle de réseau neuronal à usage général pour la détection des limites d’une phrase qui identifie les phrases au sein d’un texte. De nombreuses tâches NLP considèrent une phrase comme une unité d’entrée. Parmi ces tâches figurent le balisage morphosyntaxique (POS), l’analyse des dépendances, la reconnaissance d’entité nommée et la traduction automatique.
Fonctionnalités et pipelines Spark NLP
Spark NLP fournit des bibliothèques Python, Java et Scala qui offrent toutes les fonctionnalités des bibliothèques NLP traditionnelles telles que spaCy, NLTK, Stanford CoreNLP et Open NLP. Spark NLP propose également des fonctionnalités telles que la vérification orthographique, l’analyse des sentiments et la classification des documents. Spark NLP améliore les efforts précédents en fournissant une justesse, une vitesse et une scalabilité de pointe.
Spark NLP est de loin la bibliothèque NLP open source la plus rapide. Les points de référence publics récents montrent que Spark NLP est 38 et 80 fois plus rapide que spaCy, avec une justesse comparable pour l’entraînement de modèles personnalisés. Spark NLP est la seule bibliothèque open source qui peut utiliser un cluster Spark distribué. Spark NLP est une extension native de Spark ML qui fonctionne directement sur des dataframes. Par conséquent, les accélérations sur un cluster entraînent un autre ordre de grandeur du gain en performances. Comme chaque pipeline Spark NLP est un pipeline Spark ML, Spark NLP est adapté pour la création de pipelines NLP et de machine learning unifiés, comme la classification de documents, la prédiction des risques et les pipelines de recommandation.
Outre d’excellentes performances, Spark NLP offre également une justesse de pointe pour un nombre croissant de tâches NLP. L’équipe Spark NLP lit régulièrement les derniers documents universitaires pertinents et produit les modèles les plus précis.
Pour l’ordre d’exécution d’un pipeline NLP, Spark NLP suit le même concept de développement que les modèles Machine Learning Spark ML traditionnels. Mais Spark NLP applique des techniques NLP. Le diagramme suivant montre les composants principaux d’un pipeline Spark NLP.
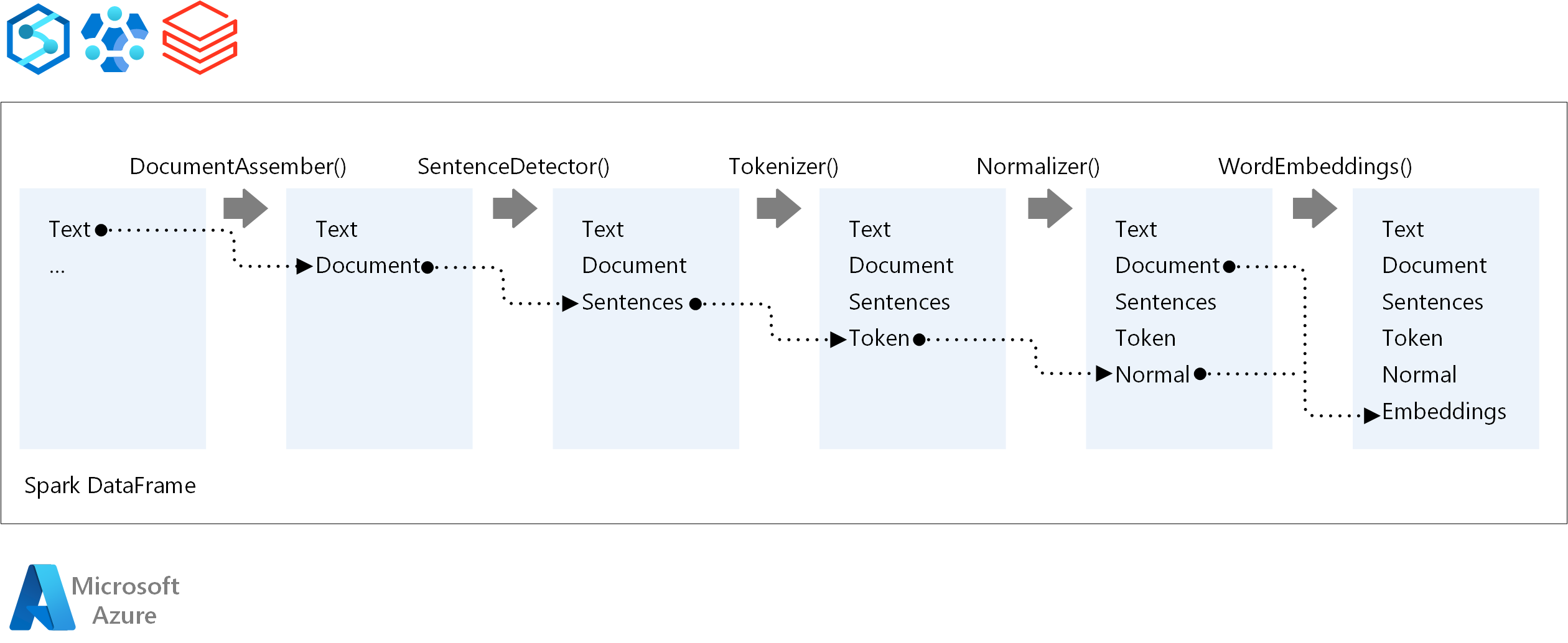
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Moritz Steller | Architecte de solution cloud senior
Étapes suivantes
Documentation de Spark NLP :
Composants Azure :
Ressources associées
- Technologie de traitement du langage naturel
- Enrichissement par IA avec traitement des images et du langage naturel dans la Recherche cognitive Azure
- Analyser les flux d’actualités avec l’analytique en quasi-temps réel à l’aide du traitement des images et du langage naturel
- Suggérer des étiquettes de contenu avec NLP à l’aide du deep learning