Récupération d’urgence et géodistribution dans Azure Durable Functions
Microsoft s’efforce de faire en sorte que les services Azure soient toujours disponibles. Toutefois, des interruptions de service non planifiées peuvent se produire. Si votre application a besoin de résilience, Microsoft recommande de configurer votre application pour la géoredondance. De plus, les clients doivent disposer d’un plan de reprise d’activité après sinistre afin de gérer toute interruption de service régionale. La préparation du basculement vers le réplica secondaire de votre application et de votre stockage au cas où le réplica principal deviendrait indisponible compte pour part importante du plan de reprise d’activité.
Dans Durable Functions, tous les états sont conservés par défaut dans Stockage Azure. Un hub de tâches est un conteneur logique réservé aux ressources Stockage Azure utilisées pour les orchestrations et les entités. Les fonctions d’orchestrateur, d’activité et d’entité ne peuvent interagir que si elles appartiennent au même hub de tâches. Ce document fait référence aux hubs de tâches pour la description de scénarios visant à assurer une haute disponibilité de ces ressources Stockage Azure.
Notes
Les instructions de cet article supposent que vous utilisez le fournisseur Stockage Azure par défaut pour stocker l’état du runtime Durable Functions. Toutefois, il est possible de configurer d’autres fournisseurs de stockage qui stockent l’état ailleurs, par exemple une base de données SQL Server. Différentes stratégies de récupération d’urgence et de géo-distribution peuvent être requises pour les autres fournisseurs de stockage. Pour plus d’informations sur les autres fournisseurs de stockage, consultez la documentation sur les fournisseurs de stockage Durable Functions.
Les orchestrations et les entités peuvent être déclenchées à l’aide de fonctions clientes qui sont elles-mêmes déclenchées via HTTP ou l’un des autres types de déclencheurs Azure Functions pris en charge. Ils peuvent aussi être déclenchés à l’aide des API HTTP intégrées. Par souci de simplicité, cet article porte essentiellement sur les scénarios impliquant des déclencheurs de fonctions basées sur Stockage Azure et HTTP ainsi que sur les options permettant d’accroître la disponibilité et de limiter les temps d’arrêt pendant les opérations de reprise d’activité. D’autres types de déclencheurs, tels que les déclencheurs Service Bus ou Azure Cosmos DB, ne sont pas explicitement abordés.
Les scénarios suivants sont basés sur des configurations de type actif/passif, car ils sont inspirés par l’utilisation de Stockage Azure. Ce modèle consiste à déployer une application de fonction de secours (passive) vers une autre région. Traffic Manager supervise la disponibilité HTTP de l’application de fonction principale (active). Il bascule vers l’application de fonction de secours si l’application principale échoue. Pour plus d’informations, consultez Méthode de routage du trafic basé sur la priorité d’Azure Traffic Manager.
Notes
- Grâce à la configuration actif/passif proposée, un client est toujours en mesure de déclencher de nouvelles orchestrations via HTTP. Mais comme deux applications de fonction partagent le même hub de tâches dans le stockage, des transactions de stockage en arrière-plan sont distribuées entre les deux. Cette configuration entraîne donc des coûts de sortie supplémentaires pour l’application de fonction secondaire.
- Le compte de stockage et le hub de tâches sous-jacents sont créés dans la région principale et sont partagés par les deux applications de fonction.
- Toutes les applications de fonction qui sont déployés de manière redondante doivent partager les mêmes clés d’accès de fonction si elles sont activées via le protocole HTTP. Le Functions Runtime expose une API de gestion qui permet aux consommateurs d’ajouter, supprimer et mettre à jour des clés de fonction par programmation. La gestion des clés est également possible en utilisant les API Azure Resource Manager.
Scénario 1 : calcul avec équilibrage de charge et stockage partagé
En cas de problème au niveau de l’infrastructure de calcul dans Azure, l’application de fonction peut devenir indisponible. Pour réduire l’éventualité de ce type de temps d’arrêt, ce scénario utilise deux applications de fonction déployées dans des régions différentes. Traffic Manager est configuré pour détecter les problèmes dans l’application de fonction principale et pour rediriger automatiquement le trafic vers l’application de fonction dans la région secondaire. Cette application de fonction partage le même compte de stockage Azure et le même hub de tâches. Il n’y a donc aucune perte de l’état des applications de fonction et le travail peut reprendre normalement. Une fois que la région principale est de nouveau opérationnelle, Azure Traffic Manager commence automatiquement à acheminer les demandes vers cette application de fonction.
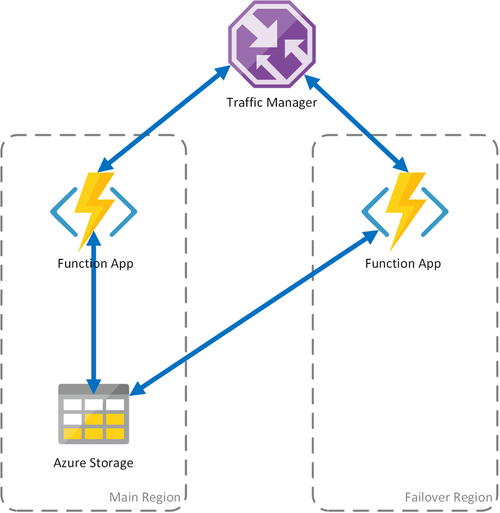
L’utilisation de ce scénario de déploiement présente plusieurs avantages :
- En cas de panne de l’infrastructure de calcul, le travail peut reprendre dans la région de basculement sans perte de données.
- Traffic Manager se charge du basculement automatique vers l’application de fonction saine.
- Traffic Manager rétablit automatiquement le trafic vers l’application de fonction principale une fois la panne résolue.
Si vous utilisez ce scénario, tenez cependant compte des remarques suivantes :
- Si l’application de fonction est déployée selon un plan App Service dédié, la réplication de l’infrastructure de calcul dans le centre de données de basculement entraîne des coûts supplémentaires.
- Ce scénario décrit des pannes au niveau de l’infrastructure de calcul, mais le compte de stockage demeure le point de défaillance unique pour l’application de fonction. En cas de panne de Stockage, l’application subit un temps d’arrêt.
- Un basculement de l’application de fonction augmentera la latence car celle-ci accèdera à son compte de stockage d’une région à une autre.
- L’accès au service de stockage à partir d’une autre région implique un coût plus élevé lié au trafic de sortie du réseau.
- Ce scénario dépend de Traffic Manager. Compte tenu du mode de fonctionnement de Traffic Manager, il peut être nécessaire d’attendre un certain temps avant qu’une application cliente qui utilise une fonction durable ait besoin de redemander à Traffic Manager l’adresse de l’application de fonction.
Notes
À partir de la version 2.3.0 de l’extension Durable Functions, deux applications de fonction peuvent être exécutées simultanément de manière sécurisée avec le même compte de stockage et la même configuration de hub de tâches. La première application à démarrer obtient un bail d’objet blob au niveau de l’application qui empêche d’autres applications de subtiliser des messages dans les files d’attente du hub de tâches. Si cette première application cesse de s’exécuter, son bail expire et peut être acquis par une deuxième application, qui procède alors au traitement des messages du hub de tâches.
Avant la version 2.3.0, les applications de fonction configurées pour utiliser le même compte de stockage traitent les messages et mettent à jour les artefacts de stockage simultanément, ce qui entraîne des latences globales et des coûts de sortie bien plus élevés. Si le code déployé dans les applications principale et de réplication est différent, même temporairement, il se peut que les orchestrations ne puissent pas s’exécuter correctement en raison d’incohérences des fonctions d’orchestrateur entre les deux applications. Il est donc recommandé pour toutes les applications qui ont besoin de la géodistribution pour la reprise d’activité d’utiliser la version 2.3.0 ou une version ultérieure de l’extension Durable.
Scénario 2 : calcul avec équilibrage de charge et stockage régional
Le scénario précédent s’appliquait uniquement à une situation de panne au niveau de l’infrastructure de calcul. Un échec du service de stockage entraîne donc un arrêt de l’application de fonction. Pour garantir un fonctionnement continu des fonctions durables, ce scénario utilise un compte de stockage local dans chaque région où les applications de fonction sont déployées.
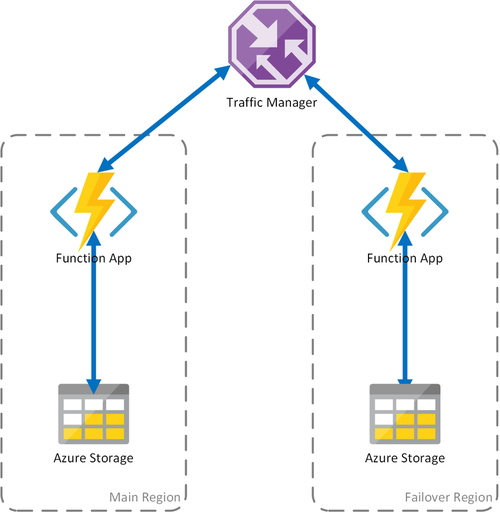
Cette approche apporte certaines améliorations au scénario précédent :
- En cas d’échec de l’application de fonction, Traffic Manager assure le basculement vers la région secondaire. Mais puisque l’application de fonction repose sur son propre compte de stockage, les fonctions durables continuent de fonctionner.
- Pendant un basculement, aucune latence supplémentaire n’est observée dans la région de basculement, car l’application de fonction se trouve au même emplacement que le compte de stockage.
- Un problème au niveau de la couche de stockage entraînera l’échec des fonctions durables, qui déclenchera à son tour une redirection du trafic vers la région de basculement. Là encore, dans la mesure où l’application de fonction et le compte de stockage sont isolés par région, les fonctions durables continueront de fonctionner.
Points importants à prendre en compte pour ce scénario :
- Si l’application de fonction est déployée selon un plan App Service dédié, la réplication de l’infrastructure de calcul dans le centre de données de basculement entraîne des coûts supplémentaires.
- L’état actuel ne bascule pas, ce qui signifie que les orchestrations et les entités existantes sont en réalité suspendues et indisponibles tant que la région primaire n’est pas récupérée.
Pour résumer, la différence entre le premier et le deuxième scénario est que la latence est préservée et que les coûts de sortie sont contenus, mais les orchestrations et les entités existantes ne sont pas disponibles pendant le temps d’arrêt. L’acceptation de cette différence dépend des exigences de l’application.
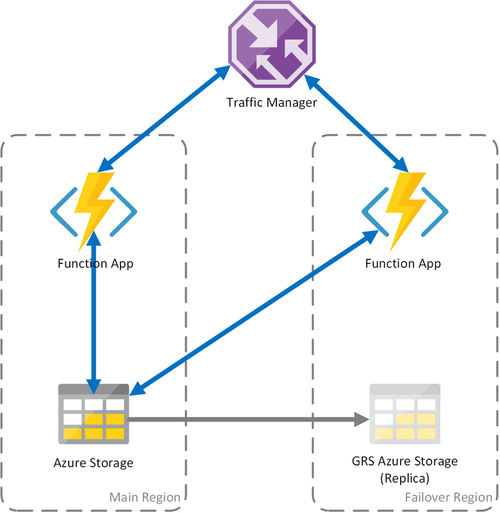
Scénario 3 : calcul avec équilibrage de charge et stockage GRS partagé
Ce scénario modifie le premier scénario en implémentant un compte de stockage partagé. La principale différence réside dans l’activation de la géoréplication au moment de la création du compte de stockage. D’un point de vue fonctionnel, ce scénario offre les mêmes avantages que le premier scénario, mais introduit d’autres avantages sur le plan de la récupération des données :
- Le stockage géoredondant (GRS) et le GRS avec accès en lecture (RA-GRS) optimisent la disponibilité de votre compte de stockage.
- En cas de panne régionale du service de stockage, vous pouvez déclencher manuellement un basculement vers le réplica secondaire. Dans des circonstances extrêmes où une région est perdue suite à un sinistre majeur, Microsoft peut lancer un basculement régional. Dans ce cas, aucune action n’est requise de votre part.
- Quand un basculement se produit, l’état des fonctions durables est conservé jusqu’à la dernière réplication du compte de stockage, qui intervient généralement à intervalles de quelques minutes.
Comme pour les autres scénarios, quelques aspects sont à prendre en compte :
- Un basculement vers le réplica peut prendre un certain temps. Tant que le basculement n’est pas terminé et que les enregistrements DNS de Stockage Azure n’ont pas été mis à jour, l’application de fonction est interrompue.
- L’utilisation de comptes de stockage géorépliqués entraîne des coûts supplémentaires.
- La réplication GRS copie vos données de manière asynchrone. La latence de la réplication peut provoquer la perte de certaines transactions plus récentes.
Remarque
Comme indiqué dans le scénario 1, il est fortement recommandé pour les applications de fonction déployées avec cette stratégie d’utiliser la version 2.3.0 ou une version ultérieure de l’extension Durable Functions.
Pour plus d'informations, consultez la documentation Reprise d’activité et basculement de compte de stockage dans Stockage Azure.