Configurer la collecte de journaux dans Container Insights
Cet article fournit des détails sur la façon de configurer la collecte de données dans Container insights pour votre cluster Kubernetes une fois celui-ci intégré. Pour obtenir des conseils sur l’activation de Container Insights sur votre cluster, consultez Activer la surveillance pour les clusters Kubernetes.
Méthodes de configuration
Il existe deux méthodes pour configurer et filtrer les données collectées dans Container Insights. Selon le contexte, vous pourrez peut-être choisir entre les deux méthodes ou vous devrez peut-être utiliser l'une ou l'autre. Les deux méthodes sont décrites dans le tableau ci-dessous avec des informations détaillées dans les sections suivantes.
| Méthode | Description |
|---|---|
| Règle de collecte de données (DCR) | Les règles de collecte de données sont des ensembles d'instructions prenant en charge la collecte de données à l'aide du pipeline Azure Monitor. Un DCR est créé lorsque vous activez Container Insights et vous pouvez modifier les paramètres de ce DCR à l’aide du Portail Microsoft Azure ou d’autres méthodes. |
| ConfigMap | Les ConfigMaps sont un mécanisme Kubernetes qui vous permet de stocker des données non confidentielles telles qu'un fichier de configuration ou des variables d'environnement. Container Insights recherche un ConfigMap sur chaque cluster avec des paramètres particuliers qui définissent les données qu'il doit collecter. |
Configurer la collecte de données à l'aide de DCR
Le DCR créé par Container insights s'appelle MSCI-<cluster-region>-<cluster-name>. Vous pouvez afficher ce DCR avec d’autres dans votre abonnement, et vous pouvez le modifier à l’aide des méthodes décrites dans Créer et modifier des règles de collecte de données (DCR) dans Azure Monitor. Bien que vous puissiez modifier directement le DCR pour des personnalisations particulières, vous pouvez effectuer la plupart des configurations requises à l'aide des méthodes décrites ci-dessous. Consultez Transformations de données dans Container Insights pour plus de détails sur la modification directe du DCR pour des configurations plus avancées.
Important
Les clusters AKS doivent utiliser une identité managée attribuée par le système ou par l’utilisateur. Si le cluster utilise un principal de service, vous devez mettre à jour le cluster pour utiliser une identité managée affectée par le système ou une identité managée affectée par l’utilisateur .
Configurer DCR avec le Portail Microsoft Azure
À l’aide du Portail Microsoft Azure, vous pouvez choisir parmi plusieurs configurations prédéfinies pour la collecte de données dans Container Insights. Ces configurations incluent différents ensembles de tables et fréquences de collecte en fonction de vos priorités particulières. Vous pouvez également personnaliser les paramètres pour collecter uniquement les données dont vous avez besoin. Vous pouvez utiliser le Portail Microsoft Azure pour personnaliser la configuration de votre cluster existant une fois Container Insights activé, ou vous pouvez effectuer cette configuration lorsque vous activez Container Insights sur votre cluster.
Sélectionnez le cluster dans le Portail Azure.
Sélectionnez l’option Insights dans la section Monitoring du menu.
Si Container Insights a déjà été activé sur le cluster, sélectionnez le bouton Paramètres d’analyse. Si ce n’est pas le cas, sélectionnez Configurer Azure Monitor et consultez Activer l’analyse sur votre cluster Kubernetes avec Azure Monitor pour plus d’informations sur l’activation de l’analyse.
Pour Kubernetes avec AKS et Arc, sélectionnez Utiliser l’identité managée si vous n’avez pas encore migré le cluster vers l’authentification d’identité managée.
Sélectionnez l’un des préréglages de coûts.
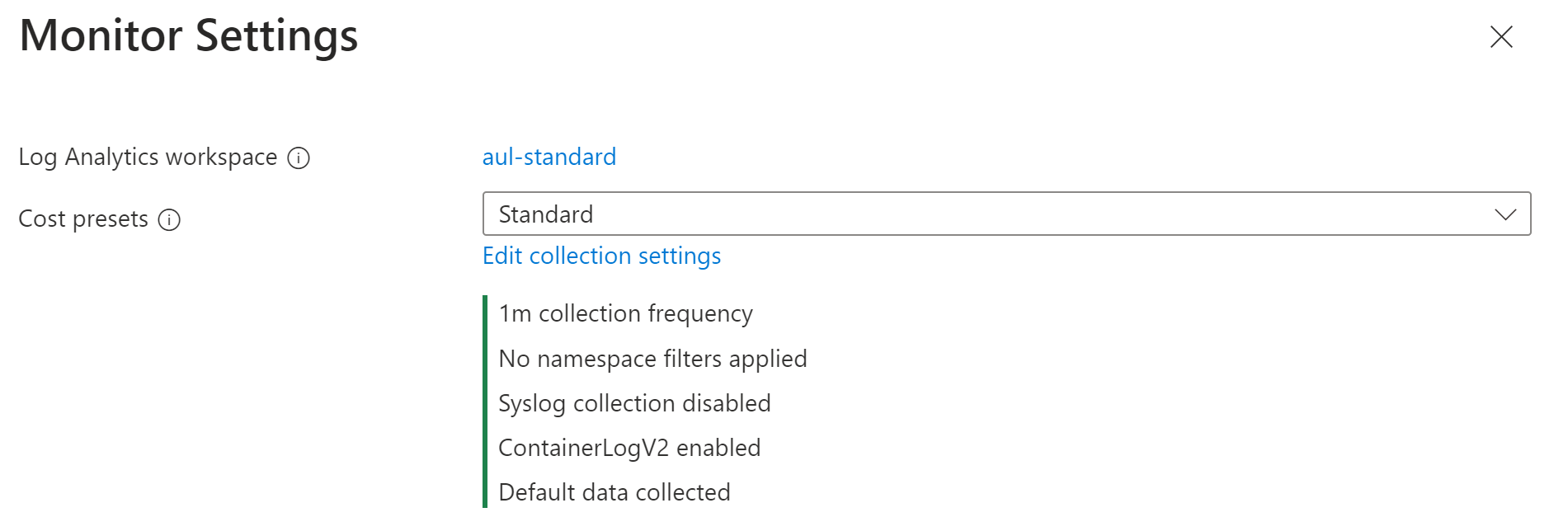
Présélection des coûts Fréquence de collecte Filtres d’espace de noms Collecte de messages Syslog Données collectées Standard 1 m Aucun Non activé Toutes les tables standard des insights de conteneur Optimisation des coûts 5 m Exclut kube-system, gatekeeper-system, azure-arc Non activé Toutes les tables standard des insights de conteneur syslog 1 m Aucun Activée par défaut Toutes les tables standard des insights de conteneur Journaux et événements 1 m Aucun Non activé ContainerLog/ContainerLogV2
KubeEvents
KubePodInventorySi vous souhaitez personnaliser les paramètres, sélectionnez Modifier les paramètres de collection.
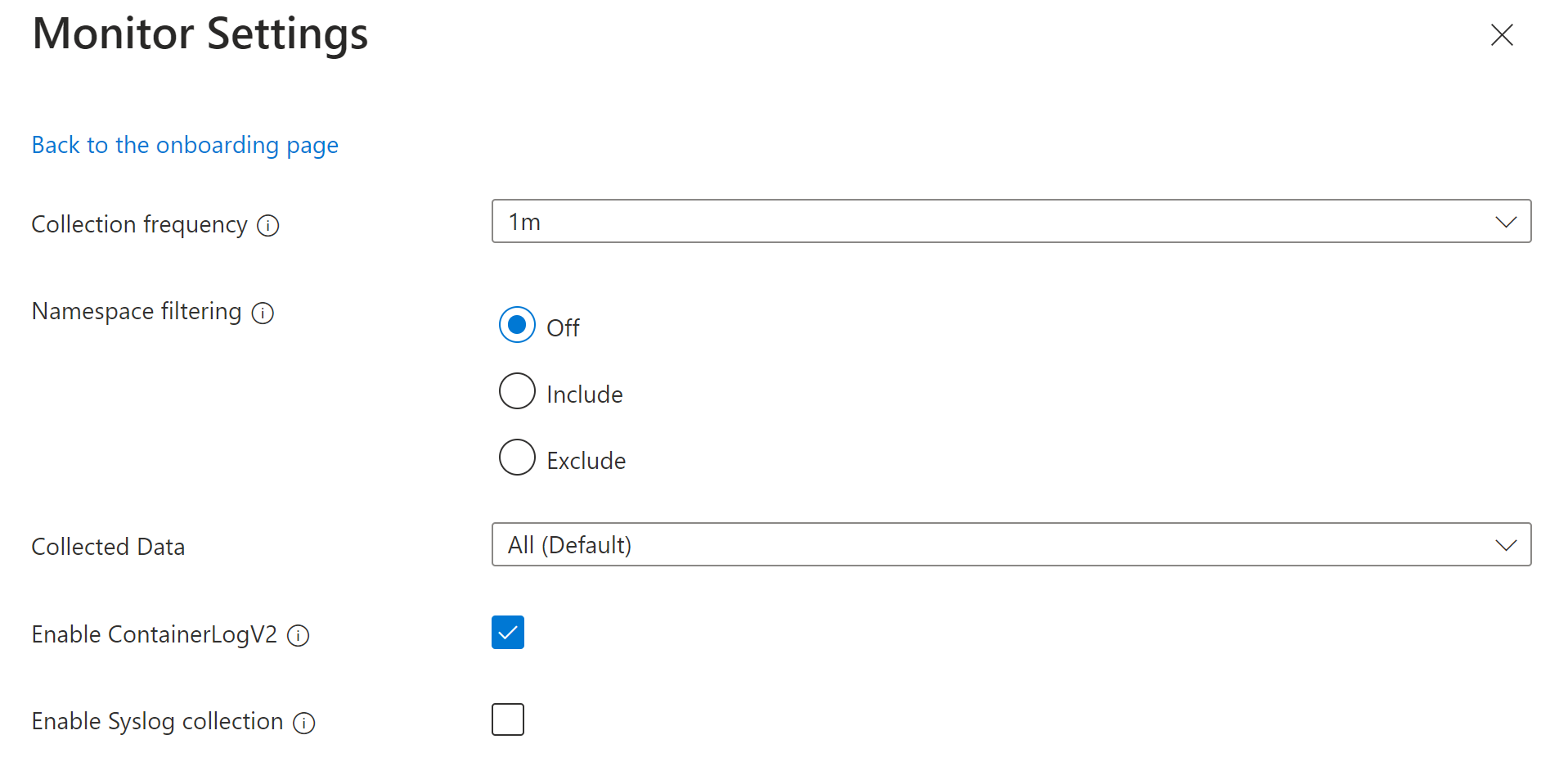
Nom Description Fréquence de collecte Détermine la fréquence à laquelle l’agent collecte les données. Les valeurs valides sont 1 m à 30 m dans les intervalles de 1 m. La valeur par défaut est de 1 m. Filtrage des espaces de noms Désactivé : Collecte des données sur tous les espaces de noms.
Inclure : collecte uniquement les données des valeurs du champ espaces de noms.
Exclure : collecte les données de tous les espaces de noms, à l’exception des valeurs du champ espaces de noms.
Tableau d’espaces de noms Kubernetes séparés par des virgules pour collecter des données d’inventaire et de performances en fonction de namespaceFilteringMode. Par exemple, espaces de noms = ["kube-system », « default"] avec un paramètre Inclure collecte uniquement ces deux espaces de noms. Avec un paramètre Exclure, l’agent collecte des données de tous les autres espaces de noms à l’exception de kube-system et par défaut.Données collectées Définit les tables Container Insights à collecter. Voir ci-dessous pour une description de chaque groupe. Activer ContainerLogV2 Drapeau booléen pour activer le schéma ContainerLogV2. Si la valeur est true, les journaux stdout/stderr sont ingérés à la table ContainerLogV2. Si ce n’est pas le cas, les journaux de conteneur sont ingérés à la table ContainerLog, sauf indication contraire dans ConfigMap. Lorsque vous spécifiez les flux individuels, vous devez inclure la table correspondante pour ContainerLog ou ContainerLogV2. Activer la collecte Syslog Active la collecte Syslog à partir du cluster. L’option Données collectées vous permet de sélectionner les tables remplies pour le cluster. Les tableaux sont regroupés selon les scénarios les plus courants. Pour spécifier des tables individuelles, vous devez modifier le DCR à l’aide d’une autre méthode.
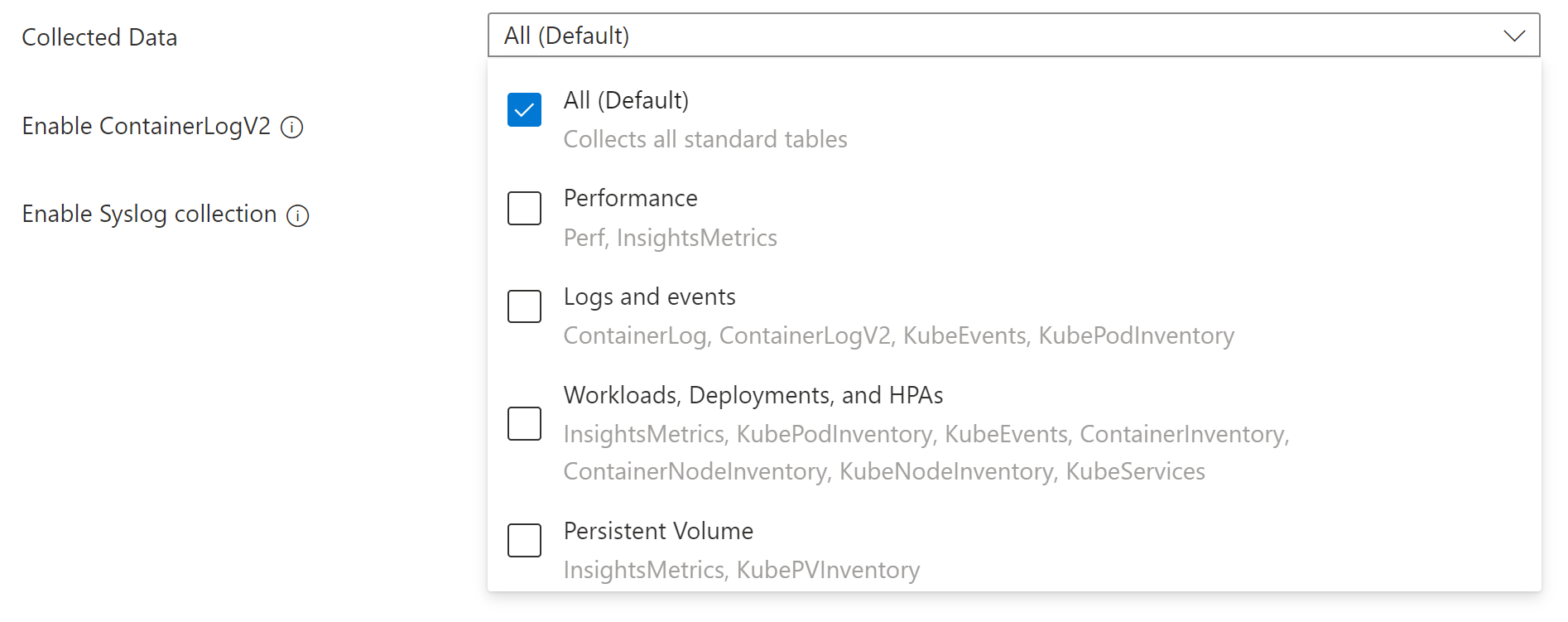
Regroupement Tableaux Notes Tous (valeur par défaut) Toutes les tables standard des insights de conteneur Requis pour activer les visualisations de Container Insights par défaut Performances Niveau de performance, InsightsMetrics Journaux et événements ContainerLog ou ContainerLogV2, KubeEvents, KubePodInventory Recommandé si vous avez activé les métriques Prometheus managées Charges de travail, déploiements et HPA InsightsMetrics, KubePodInventory, KubeEvents, ContainerInventory, ContainerNodeInventory, KubeNodeInventory, KubeServices Volumes persistants InsightsMetrics, KubePVInventory Cliquez sur Configurer pour enregistrer les paramètres.




Tableaux et mesures applicables pour DCR
Les paramètres de fréquence de collecte et de filtrage de l'espace de noms dans le DCR ne s'appliquent pas à toutes les données Container Insights. Les tableaux suivants répertorient les tableaux de l’espace de travail Log Analytics utilisés par Container Insights et les métriques qu’il collecte, ainsi que les paramètres qui s’appliquent à chacun d’eux.
| Nom de table | Intervalle | Espaces de noms | Notes |
|---|---|---|---|
| ContainerInventory | Oui | Oui | |
| ContainerNodeInventory | Oui | Non | Le paramètre de collecte de données pour les espaces de noms n’est pas applicable, car le nœud Kubernetes n’est pas une ressource délimitée à l’espace de noms |
| KubeNodeInventory | Oui | Non | Le paramètre de collecte de données pour les espaces de noms n’est pas applicable, car le nœud Kubernetes n’est pas une ressource délimitée à l’espace de noms |
| KubePodInventory | Oui | Oui | |
| KubePVInventory | Oui | Oui | |
| KubeServices | Oui | Oui | |
| KubeEvents | Non | Oui | Le paramètre de collecte de données pour intervalle n’est pas applicable aux événements Kubernetes |
| Perf | Oui | Oui | Le paramètre de collecte de données pour les espaces de noms n’est pas applicable aux métriques liées au nœud Kubernetes, car le nœud Kubernetes n’est pas un objet délimité à l’espace de noms. |
| InsightsMetrics | Oui | Oui | Les paramètres de collecte de données s’appliquent uniquement aux métriques qui collectent les espaces de noms suivants : container.azm.ms/kubestate, container.azm.ms/pv et container.azm.ms/gpu |
| Espace de noms de la métrique | Intervalle | Espaces de noms | Notes |
|---|---|---|---|
| Insights.container/nodes | Oui | Non | Node (nœud) n’est pas une ressource délimitée à l’espace de noms |
| Insights.container/pods | Oui | Oui | |
| Insights.container/containers | Oui | Oui | |
| Insights. Container/persistentvolumes | Oui | Oui |
Valeurs de flux dans DCR
Lorsque vous spécifiez les tables à collecter à l’aide de l’interface CLI ou ARM, vous spécifiez un nom de flux qui correspond à une table spécifique dans l’espace de travail Log Analytics. Le tableau suivant répertorie le nom de flux pour chaque table.
Remarque
Si vous connaissez la structure d’une règle de collecte de données, les noms de flux de cette table sont spécifiés dans la section dataFlows de la DCR.
| STREAM | Table d’insights de conteneur |
|---|---|
| Microsoft-ContainerInventory | ContainerInventory |
| Microsoft-ContainerLog | ContainerLog |
| Microsoft-ContainerLogV2 | ContainerLogV2 |
| Microsoft-ContainerLogV2-HighScale | ContainerLogV2 (mode à grande échelle)1 |
| Microsoft-ContainerNodeInventory | ContainerNodeInventory |
| Microsoft-InsightsMetrics | InsightsMetrics |
| Microsoft-KubeEvents | KubeEvents |
| Microsoft-KubeMonAgentEvents | KubeMonAgentEvents |
| Microsoft-KubeNodeInventory | KubeNodeInventory |
| Microsoft-KubePodInventory | KubePodInventory |
| Microsoft-KubePVInventory | KubePVInventory |
| Microsoft-KubeServices | KubeServices |
| Microsoft-Perf | Perf |
1 Vous ne devez pas utiliser Microsoft-ContainerLogV2 et Microsoft-ContainerLogV2-HighScale dans le même DCR. Des données seront alors dupliquées.
Partager DCR avec plusieurs clusters
Lorsque vous activez Container Insights sur un cluster Kubernetes, un nouveau DCR est créé pour ce cluster et le DCR de chaque cluster peut être modifié indépendamment. Si vous disposez de plusieurs clusters avec des configurations de surveillance personnalisées, vous souhaiterez peut-être partager un seul DCR avec plusieurs clusters. Vous pouvez ensuite apporter des modifications à un seul DCR qui sont automatiquement implémentées pour tous les clusters qui lui sont associés.
Un DCR est associé à un cluster avec une règle de collecte de données associée (DCRA). Utilisez l’expérience DCR d’aperçu pour afficher et supprimer les associations DCR existantes pour chaque cluster. Vous pouvez ensuite utiliser cette fonctionnalité pour ajouter une association à un seul DCR pour plusieurs clusters.
Configurer la collecte de données à l'aide de ConfigMap
ConfigMaps sont un mécanisme Kubernetes qui vous permet de stocker des données non confidentielles telles qu'un fichier de configuration ou des variables d'environnement. Container Insights recherche un ConfigMap sur chaque cluster avec des paramètres particuliers qui définissent les données qu'il doit collecter.
Important
ConfigMap est une liste globale et il ne peut y avoir qu’un seul ConfigMap appliqué à l’agent pour Container Insights. L’application d’un autre ConfigMap remplace les paramètres de collection ConfigMap précédents.
Prérequis
- La version minimale de l’agent prise en charge pour collecter des variables stdout, stderr et d’environnement à partir de charges de travail de conteneur est ciprod06142019 ou une version ultérieure.
Configurer et déployer ConfigMap
Utilisez la procédure suivante pour configurer et déployer votre fichier de configuration ConfigMap sur votre cluster :
Si vous ne disposez pas encore d'un ConfigMap pour Container Insights, téléchargez le fichier YAML modèle ConfigMap et ouvrez-le dans un éditeur.
Modifiez le fichier YAML ConfigMap avec vos personnalisations. Le modèle comprend tous les paramètres valides avec des descriptions. Pour activer un paramètre, supprimez le caractère de commentaire (#) et définissez sa valeur.
Créez une ConfigMap en exécutant la commande kubectl suivante :
kubectl config set-context <cluster-name> kubectl apply -f <configmap_yaml_file.yaml> # Example: kubectl config set-context my-cluster kubectl apply -f container-azm-ms-agentconfig.yamlQuelques minutes peuvent être nécessaires pour que la modification de configuration soit effective. Alors tous les pods de l’agent Azure Monitor dans le cluster vont redémarrer. Le redémarrage s’effectue de façon progressive pour tous les pods de l’agent Azure Monitor. Tous les pods ne redémarrent pas en même temps. Une fois les redémarrages terminés, vous recevrez un message similaire au résultat suivant :
configmap "container-azm-ms-agentconfig" created`.
Vérifier la configuration
Pour vérifier que la configuration a été correctement appliquée à un cluster, utilisez la commande suivante pour passer en revue les journaux d’activité d’un pod d’agent.
kubectl logs ama-logs-fdf58 -n kube-system -c ama-logs
S’il y a des erreurs de configuration au niveau des pods de l’agent Azure Monitor, la sortie affiche des erreurs similaires à celles-ci :
***************Start Config Processing********************
config::unsupported/missing config schema version - 'v21' , using defaults
Utilisez les options suivantes pour effectuer davantage de dépannage des modifications de configuration :
Utilisez la même commande
kubectl logsà partir d’un pod d’agent.Consultez les journaux en direct pour détecter d’éventuelles erreurs similaires aux suivantes :
config::error::Exception while parsing config map for log collection/env variable settings: \nparse error on value \"$\" ($end), using defaults, please check config map for errorsLes données sont envoyées à la table
KubeMonAgentEventsde votre espace de travail Log Analytics toutes les heures avec la gravité des erreurs de configuration. S’il n’y a pas d’erreur, l’entrée de la table contient des données avec des informations de gravité ne signalant aucune erreur. La colonneTagscontient plus d'informations sur le pod et l'identification du conteneur sur lesquels l'erreur s'est produite, ainsi que la première occurrence, la dernière occurrence et le nombre au cours de la dernière heure.
Vérifier la version du schéma
Les versions de schéma de configuration prises en charge sont fournies sous forme d’annotation de pod (schema-versions) sur le pod de l’agent Azure Monitor. Vous pouvez les voir avec la commande kubectl suivante.
kubectl describe pod ama-logs-fdf58 -n=kube-system.
Paramètres ConfigMap
Le tableau suivant décrit les paramètres que vous pouvez configurer pour contrôler la collecte de données avec ConfigMap.
| Setting | Type de données | Valeur | Description |
|---|---|---|---|
schema-version |
Chaîne (respecte la casse) | v1 | Utilisé par l’agent lors de l’analyse de ce ConfigMap. Actuellement, la version prise en charge est v1. Modifier cette valeur n’est pas pris en charge et est rejeté lors de l’évaluation de l’élément ConfigMap. |
config-version |
Chaîne | Vous permet de suivre la version de ce fichier de configuration dans votre système/référentiel de contrôle de code source. Le nombre maximal de caractères autorisé est 10 et tous les autres caractères sont tronqués. | |
| [log_collection_settings] | |||
[stdout]enabled |
Boolean | true false |
Contrôle si la collecte de journaux de conteneur stdout est activée. Lorsqu’ils sont définis sur true et qu’aucun espace de noms n’est exclu pour la collecte de journaux stdout, les journaux stdout sont collectés à partir de tous les conteneurs sur tous les pods et nœuds du cluster. Si elle n’est pas spécifiée dans la ConfigMap, la valeur par défaut esttrue. |
[stdout]exclude_namespaces |
Chaîne | Tableau séparé par des virgules | Tableau d’espaces de noms Kubernetes pour lesquels aucun journal stdout n’est collecté. Ce paramètre est effectif uniquement si enabled est défini sur true. Si elle n’est pas spécifiée dans la ConfigMap, la valeur par défaut est["kube-system","gatekeeper-system"]. |
[stderr]enabled |
Boolean | true false |
Contrôle si la collecte de journaux de conteneur stderr est activée. Lorsqu’ils sont définis sur true et qu’aucun espace de noms n’est exclu pour la collecte de journaux stderr, les journaux stderr sont collectés à partir de tous les conteneurs sur tous les pods et nœuds du cluster. Si elle n’est pas spécifiée dans la ConfigMap, la valeur par défaut esttrue. |
[stderr]exclude_namespaces |
Chaîne | Tableau séparé par des virgules | Tableau d’espaces de noms Kubernetes pour lesquels aucun journal stderr n’est collecté. Ce paramètre est effectif uniquement si enabled est défini sur true. Si elle n’est pas spécifiée dans la ConfigMap, la valeur par défaut est["kube-system","gatekeeper-system"]. |
[env_var]enabled |
Boolean | true false |
Contrôle la collecte des variables d’environnement sur tous les pods et nœuds du cluster. Si elle n’est pas spécifiée dans la ConfigMap, la valeur par défaut esttrue. |
[enrich_container_logs]enabled |
Boolean | true false |
Contrôle l’enrichissement du journal des conteneurs pour remplir les valeurs de propriété Name et Image pour chaque enregistrement de journal écrit dans la table ContainerLog pour tous les journaux de conteneur du cluster. Si elle n’est pas spécifiée dans la ConfigMap, la valeur par défaut estfalse. |
[collect_all_kube_events]enabled |
Boolean | true false |
Contrôle si les événements Kube de tous les types sont collectés. Par défaut, les événements Kube de type Normal ne sont pas collectés. Lorsque ce paramètre est true, les événements normal ne sont plus filtrés et tous les événements sont collectés. Si elle n’est pas spécifiée dans la ConfigMap, la valeur par défaut estfalse. |
[schema]containerlog_schema_version |
Chaîne (respecte la casse) | v2 v1 |
Définit le format d’ingestion du journal. Si v2, la table ContainerLogV2 est utilisée. Si v1, la table ContainerLog est utilisée (cette table a été déconseillée). Pour les clusters activant Container Insights à l’aide d’Azure CLI version 2.54.0 ou ultérieure, le paramètre par défaut est v2. Pour plus d’informations, consultez schéma de journal Container Insights . |
[enable_multiline_logs]enabled |
Boolean | true false |
Contrôle si les journaux de conteneurs multilignes sont activés. Pour plus d’informations, consultez journalisation multiligne dans Container Insights. Si elle n’est pas spécifiée dans la ConfigMap, la valeur par défaut estfalse. Cela nécessite que le paramètre schema soit v2. |
[metadata_collection]enabled |
Boolean | true false |
Contrôle si les métadonnées sont collectées dans la colonne KubernetesMetadata du tableau ContainerLogV2. |
[metadata_collection]include_fields |
Chaîne | Tableau séparé par des virgules | Liste des champs de métadonnées à inclure. Si le paramètre n'est pas utilisé, tous les champs sont collectés. Les valeurs valides sont ["podLabels","podAnnotations","podUid","image","imageID","imageRepo","imageTag"] |
| [metric_collection_settings] | |||
[collect_kube_system_pv_metrics]enabled |
Boolean | true false |
Autorise la collecte des métriques d’utilisation de volume persistant (PV) dans l’espace de noms kube-system. Par défaut, les métriques d’utilisation des volumes persistants ayant des revendications de volume persistant dans l’espace de noms kube-system ne sont pas collectées. Lorsque ce paramètre est défini sur true, les métriques d’utilisation de volume persistant sont collectées pour tous les espaces de noms. Si elle n’est pas spécifiée dans la ConfigMap, la valeur par défaut estfalse. |
| [agent_settings] | |||
[proxy_config]ignore_proxy_settings |
Boolean | true false |
Quand true, les paramètres du proxy sont ignorés. Pour les environnements Kubernetes compatibles AKS et Arc, si votre cluster est configuré avec le proxy de transfert, les paramètres de proxy sont automatiquement appliqués et utilisés pour l’agent. Pour certaines configurations, comme avec AMPLS + Proxy, vous souhaiterez peut-être que la configuration du proxy soit ignorée. Si elle n’est pas spécifiée dans la ConfigMap, la valeur par défaut estfalse. |
Étapes suivantes
- Consultez Filtrer la collecte de journaux dans Container Insights pour plus de détails sur la réduction des coûts en configurant Container Insights pour filtrer les données dont vous n'avez pas besoin.