Règles d’alerte recommandées pour les clusters Kubernetes
Les alertes dans Azure Monitor identifient de manière proactive les problèmes liés à l’intégrité et aux performances de vos ressources Azure. Cet article explique comment activer et modifier un ensemble de règles d’alerte de métrique recommandées prédéfinies pour vos clusters Kubernetes.
Activer les règles d’alerte recommandées
Utilisez l’une des méthodes suivantes pour activer les règles d’alerte recommandées pour votre cluster. Vous pouvez activer à la fois Prometheus et les règles d'alerte métriques de la plateforme pour le même cluster.
Remarque
Les modèles ARM sont la seule méthode prise en charge pour activer les alertes recommandées sur les clusters Kubernetes compatibles avec Arc.
À l’aide du portail Azure, le groupe de règles Prometheus sera créé dans la même région que le cluster.
Dans le menu Alertes de votre cluster, sélectionnez Configurer des recommandations.
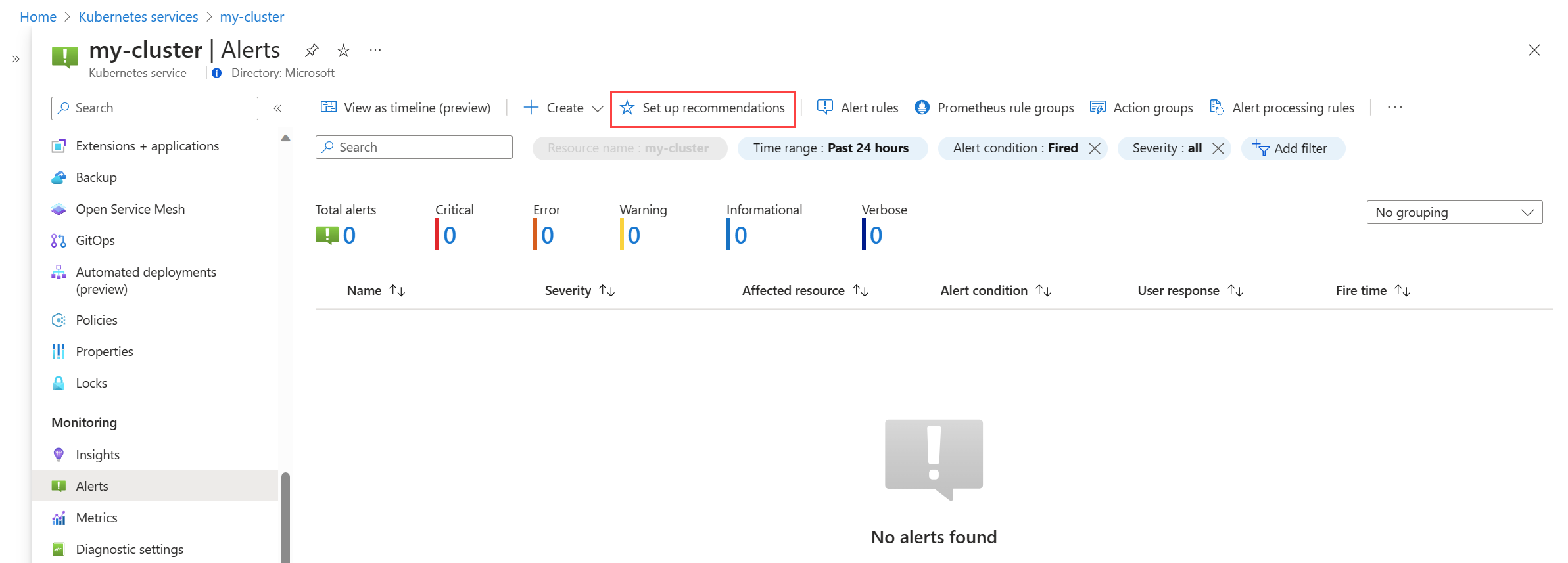
Les règles d'alerte Prometheus et de la plateforme disponibles sont affichées avec les règles Prometheus organisées par niveau de pod, de cluster et de nœud. Basculez un groupe de règles Prometheus pour activer cet ensemble de règles. Développez le groupe pour afficher les règles individuelles. Vous pouvez conserver les valeurs par défaut ou désactiver des règles individuelles et modifier leur nom et leur gravité.
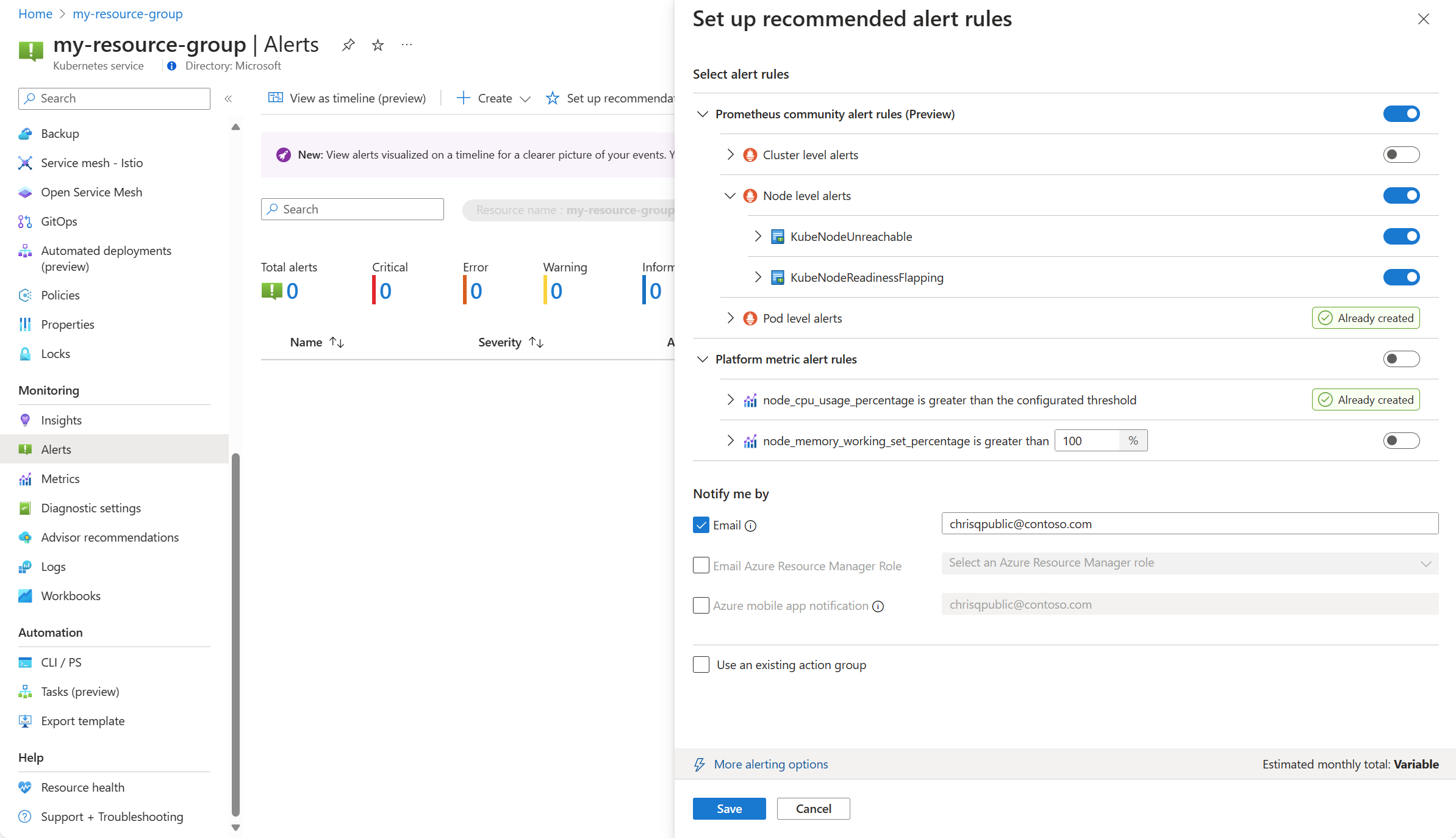
Basculez une règle de métrique de plateforme pour activer cette règle. Vous pouvez développer la règle pour modifier ses détails, tels que le nom, la gravité et le seuil.
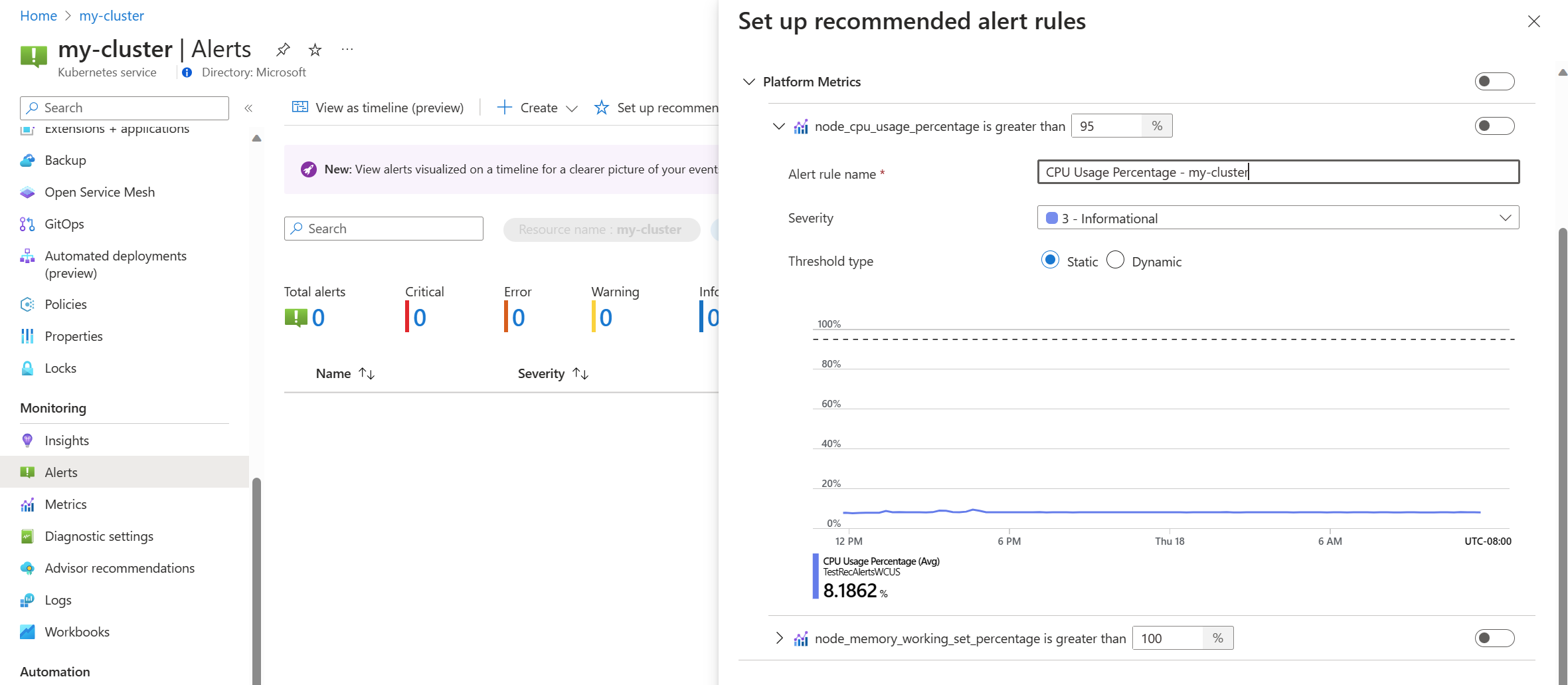
Sélectionnez une ou plusieurs méthodes de notification pour créer un groupe d’actions, ou sélectionnez un groupe d’actions existant avec les détails de notification pour cet ensemble de règles d’alerte.
Cliquez sur Enregistrer pour enregistrer le groupe de règles.



Modifier les règles d’alerte recommandées
Une fois le groupe de règles créé, vous ne pouvez pas utiliser la même page dans le portail pour modifier les règles. Pour les métriques Prometheus, vous devez modifier le groupe de règles pour modifier les règles qui y sont incluses, y compris pour activer les règles qui n'étaient pas déjà activées. Pour les métriques de plateforme, vous pouvez modifier chaque règle d’alerte.
Dans le menu Alertes de votre cluster, sélectionnez Configurer des recommandations. Toutes les règles ou groupes de règles qui ont déjà été créés seront étiquetés comme Déjà créés.
Développez la règle ou le groupe de règles. Cliquez sur Afficher le groupe de règles pour Prometheus et Afficher a règle d'alerte pour les métriques de plateforme.
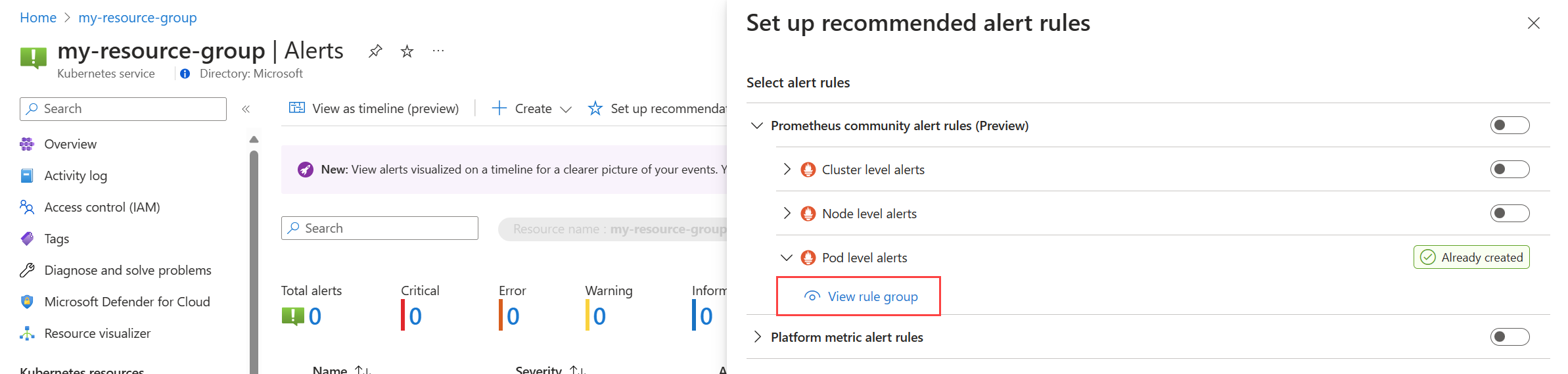
Pour les groupes de règles Prometheus :
Sélectionnez Règles pour afficher les règles d’alerte dans le groupe.
Cliquez sur l’icône Modifier en regard d’une règle que vous souhaitez modifier. Utilisez les instructions de Créer une règle d’alerte pour modifier la règle.

Lorsque vous avez terminé de modifier des règles dans le groupe, cliquez sur Enregistrer pour enregistrer le groupe de règles.
Pour les métriques de plateforme :
Cliquez sur Modifier pour ouvrir les détails de la règle d’alerte. Utilisez les instructions de Créer une règle d’alerte pour modifier la règle.



Désactiver le groupe de règles d’alerte
Désactivez le groupe de règles pour arrêter la réception d’alertes à partir des règles qu’il contient.
Affichez le groupe de règles d’alerte Prometheus ou la règle d’alerte de métrique de plateforme, comme décrit dans Modifier les règles d’alerte recommandées.
Dans le menu Vue d’ensemble, sélectionnez Désactiver.

Détails de la règle d’alerte recommandée
Les tableaux suivants répertorient les détails de chaque règle d’alerte recommandée. Le code source pour chacun d’eux est disponible dans GitHub ainsi que des guides de résolution des problèmes de la communauté Prometheus.
Règles d’alerte de la communauté Prometheus
Alertes au niveau du cluster
| Nom de l’alerte | Description | Seuil par défaut | Délai d’exécution (minutes) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | Le quota de ressources du processeur alloué aux espaces de noms a dépassé les ressources de processeur disponibles sur les nœuds du cluster de plus de 50 % au cours des 5 dernières minutes. | >1.5 | 5 |
| KubeMemoryQuotaOvercommit | Le quota de ressources de mémoire alloué aux espaces de noms a dépassé les ressources de mémoire disponibles sur les nœuds du cluster de plus de 50 % au cours des 5 dernières minutes. | >1.5 | 5 |
| KubeContainerOOMKilledCount | Un ou plusieurs conteneurs dans les pods ont été tués en raison d’événements de mémoire insuffisante (OOM) au cours des 5 dernières minutes. | >0 | 5 |
| KubeClientErrors | Le taux d’erreurs client (codes d’état HTTP commençant par 5xx) dans les requêtes d’API Kubernetes a dépassé 1 % du taux total de requêtes d’API au cours des 15 dernières minutes. | >0.01 | 15 |
| KubePersistentVolumeFillingUp | Le volume persistant a été saturé et devrait manquer d’espace disponible évalué sur le ratio d’espace disponible, l’espace utilisé et la tendance linéaire prédite de l’espace disponible au cours des 6 dernières heures. Ces conditions sont évaluées au cours des 60 dernières minutes. | S/O | 60 |
| KubePersistentVolumeInodesFillingUp | Moins de 3 % des inodes dans un volume persistant ont été disponibles au cours des 15 dernières minutes. | <0.03 | 15 |
| KubePersistentVolumeErrors | Un ou plusieurs volumes persistants ont été en phase d’échec ou d’attente au cours des 5 dernières minutes. | >0 | 5 |
| KubeContainerWaiting | Un ou plusieurs conteneurs dans les pods Kubernetes ont été dans un état d’attente au cours des 60 dernières minutes. | >0 | 60 |
| KubeDaemonSetNotScheduled | Un ou plusieurs pods n’ont pas été planifiés sur un nœud au cours des 15 dernières minutes. | >0 | 15 |
| KubeDaemonSetMisScheduled | Un ou plusieurs pods ont été mal planifiés dans le cluster au cours des 15 dernières minutes. | >0 | 15 |
| KubeQuotaAlmostFull | L’utilisation des quotas de ressources Kubernetes a été comprise entre 90 et 100 % des limites dures au cours des 15 dernières minutes. | >0.9 <1 | 15 |
Alertes au niveau du nœud
| Nom de l’alerte | Description | Seuil par défaut | Délai d’exécution (minutes) |
|---|---|---|---|
| KubeNodeUnreachable | Un nœud est resté inaccessible au cours des 15 dernières minutes. | 1 | 15 |
| KubeNodeReadinessFlapping | L’état de préparation d’un nœud a changé plus de 2 fois au cours des 15 dernières minutes. | 2 | 15 |
Alertes au niveau du pod
| Nom de l’alerte | Description | Seuil par défaut | Délai d’exécution (minutes) |
|---|---|---|---|
| KubePVUsageHigh | L’utilisation moyenne des volumes persistants sur le pod a dépassé 80 % au cours des 15 dernières minutes. | >0.8 | 15 |
| KubeDeploymentReplicasMismatch | Il existe une incompatibilité entre le nombre souhaité de réplicas et le nombre de réplicas disponibles au cours des 10 dernières minutes. | S/O | 10 |
| KubeStatefulSetReplicasMismatch | Le nombre de réplicas prêts dans StatefulSet ne correspond pas au nombre total de réplicas dans StatefulSet pour les 15 dernières minutes. | S/O | 15 |
| KubeHpaReplicasMismatch | L’Autoscaler de pod horizontal dans le cluster n’a pas mis en correspondance le nombre souhaité de réplicas au cours des 15 dernières minutes. | S/O | 15 |
| KubeHpaMaxedOut | L’Autoscaler de pod horizontal (HPA) dans le cluster s’est exécuté au maximum des réplicas au cours des 15 dernières minutes. | S/O | 15 |
| KubePodCrashLooping | Un ou plusieurs pods se sont trouvés dans un état CrashLoopBackOff, où le pod se bloque en permanence après le démarrage et ne parvient pas à récupérer correctement, au cours des 15 dernières minutes. | >=1 | 15 |
| KubeJobStale | Au moins une instance de travail n’a pas réussi au cours des 6 dernières heures. | >0 | 360 |
| KubePodContainerRestart | Un ou plusieurs conteneurs au sein des pods du cluster Kubernetes ont été redémarrés au moins une fois au cours de la dernière heure. | >0 | 15 |
| KubePodReadyStateLow | Le pourcentage de pods dans un état prêt est inférieur à 80 % pour tout déploiement ou ensemble de démons dans le cluster Kubernetes au cours des 5 dernières minutes. | <0.8 | 5 |
| KubePodFailedState | Un ou plusieurs pods ont été dans un état d’échec au cours des 5 dernières minutes. | >0 | 5 |
| KubePodNotReadyByController | Un ou plusieurs pods ont été dans un état prêt (c’est-à-dire dans la phase « En attente » ou « Inconnu ») au cours des 15 dernières minutes. | >0 | 15 |
| KubeStatefulSetGenerationMismatch | La génération observée d’un StatefulSet Kubernetes n’a pas correspondu à sa génération de métadonnées au cours des 15 dernières minutes. | S/O | 15 |
| KubeJobFailed | Un ou plusieurs travaux Kubernetes ont échoué au cours des 15 dernières minutes. | >0 | 15 |
| KubeContainerAverageCPUHigh | L’utilisation moyenne du processeur par conteneur a dépassé 95 % au cours des 5 dernières minutes. | >0.95 | 5 |
| KubeContainerAverageMemoryHigh | L’utilisation moyenne de la mémoire par conteneur a dépassé 95 % au cours des 5 dernières minutes. | >0.95 | 10 |
| KubeletPodStartUpLatencyHigh | Le 99e centile de la latence de démarrage du pod a dépassé 60 secondes au cours des 10 dernières minutes. | >60 | 10 |
Règles d’alerte de métrique de plateforme
| Nom de l’alerte | Description | Seuil par défaut | Délai d’exécution (minutes) |
|---|---|---|---|
| Le pourcentage de processeur du nœud est supérieur à 95 % | Le pourcentage de processeur du nœud a été supérieur à 95 % au cours des 5 dernières minutes. | 95 | 5 |
| Le pourcentage de jeu de travail de mémoire du nœud est supérieur à 100 % | Le pourcentage de jeu de travail de mémoire du nœud est supérieur à 100 % pour les 5 dernières minutes. | 100 | 5 |
Alertes de métrique Container Insights héritées (préversion)
Les règles de métrique dans Container Insights ont été supprimées le 31 mai 2024. Ces règles étaient en préversion publique, mais sont supprimées sans atteindre la disponibilité générale, car les nouvelles alertes de métrique recommandées décrites dans cet article sont désormais disponibles.
Si vous avez déjà activé ces règles d’alerte héritées, vous devez les désactiver et activer la nouvelle expérience.
Désactiver les règles d’alerte de métrique
- Dans le menu Insights de votre cluster, sélectionnez Alertes recommandées (préversion).
- Remplacez l’état de chaque règle d’alerte par Désactivé.
Mappage des alertes héritées
Le tableau suivant mappe chacune des alertes de métrique Container Insights héritées à ses alertes de métrique Prometheus recommandées équivalentes.
| Alerte recommandée pour les métriques personnalisées | Alerte équivalente Prometheus/Platform recommandée | Condition |
|---|---|---|
| Nombre de travaux terminés | KubeJobStale (alertes au niveau du pod) | Au moins une instance de travail n’a pas réussi au cours des 6 dernières heures. |
| % du processeur du conteneur | KubeContainerAverageCPUHigh (alertes au niveau du pod) | L’utilisation moyenne du processeur par conteneur a dépassé 95 % au cours des 5 dernières minutes. |
| Pourcentage de mémoire de la plage de travail du conteneur | KubeContainerAverageMemoryHigh (alertes au niveau du pod) | L’utilisation moyenne de la mémoire par conteneur a dépassé 95 % au cours des 5 dernières minutes. |
| Nombre de pods en échec | KubePodFailedState (alertes au niveau du pod) | Un ou plusieurs pods ont été dans un état d’échec au cours des 5 dernières minutes. |
| % du processeur du nœud | Le pourcentage de processeur de nœud est supérieur à 95 % (Métrique de plateforme) | Le pourcentage de processeur du nœud a été supérieur à 95 % au cours des 5 dernières minutes. |
| % d'utilisation du disque du nœud | S/O | L’utilisation moyenne du disque pour un nœud est supérieure à 80 %. |
| État NotReady du nœud | KubeNodeUnreachable (alertes au niveau du nœud) | Un nœud est resté inaccessible au cours des 15 dernières minutes. |
| % de mémoire de la plage de travail du nœud | Le pourcentage de jeu de travail de mémoire du nœud est supérieur à 100 % | Le pourcentage de jeu de travail de mémoire du nœud est supérieur à 100 % pour les 5 dernières minutes. |
| Conteneurs arrêtés OOM | KubeContainerOOMKilledCount (alertes au niveau du cluster) | Un ou plusieurs conteneurs dans les pods ont été tués en raison d’événements de mémoire insuffisante (OOM) au cours des 5 dernières minutes. |
| % d'utilisation de volume persistant | KubePVUsageHigh (alertes au niveau du pod) | L’utilisation moyenne des volumes persistants sur le pod a dépassé 80 % au cours des 15 dernières minutes. |
| Pourcentage de pods prêts | KubePodReadyStateLow (alertes au niveau du pod) | Le pourcentage de pods dans un état prêt est inférieur à 80 % pour tout déploiement ou ensemble de démons dans le cluster Kubernetes au cours des 5 dernières minutes. |
| Nombre de conteneurs en cours de redémarrage | KubePodContainerRestart (alertes au niveau du pod) | Un ou plusieurs conteneurs au sein des pods du cluster Kubernetes ont été redémarrés au moins une fois au cours de la dernière heure. |