Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Cet article explique l’agrégation des métriques dans la base de données de série chronologique où sont sauvegardées les métriques de plateforme et les métriques personnalisées d’Azure Monitor. Cet article s’applique également aux métriques d’Application Insights standard.
Les informations contenues dans cet article sont complexes et s’adressent à tous ceux qui souhaitent approfondir le système de métriques. La compréhension de ce système n’est pas nécessaire pour utiliser efficacement les métriques d’Azure Monitor.
Présentation et terminologie
Lorsque vous ajoutez une métrique à un graphique, Metrics Explorer présélectionne automatiquement son agrégation par défaut. La valeur par défaut convient aux scénarios de base. Toutefois, vous pouvez utiliser d’autres agrégations pour obtenir des insights supplémentaires sur la métrique. Pour afficher différentes agrégations sur un graphique, vous devez comprendre comment Metrics Explorer les gère.
Nous allons tout d’abord définir quelques termes :
- Valeur de métrique : valeur de mesure collectée pour une ressource spécifique.
- Base de données de série chronologique : base de données optimisée pour le stockage et la récupération de points de données contenant tous une valeur et un horodatage correspondant.
- Période : période de temps générique.
- Intervalle de temps : temps écoulé entre deux collectes de valeurs de métrique.
- Plage temporelle : période affichée sur un graphique. La valeur par défaut est généralement de 24 heures. Seules les plages précises sont disponibles.
- Granularité temporelle ou Fragment de temps : période utilisée pour agréger des valeurs en vue de leur affichage sur un graphique. Seules les plages précises sont disponibles. La valeur minimale est de 1 minute. Pour être utile, la valeur de granularité temporelle doit être inférieure à celle de la plage temporelle sélectionnée, sinon, une seule valeur sera affichée pour l’ensemble du graphique.
- Type d’agrégation : type de statistique calculé à partir de plusieurs valeurs de métriques.
- Agrégat : processus qui consiste à utiliser plusieurs valeurs d’entrée, puis à les utiliser pour produire une seule valeur de sortie via les règles définies par le type d’agrégation. Par exemple, en utilisant la moyenne de plusieurs valeurs.
Résumé du processus
Les métriques sont une série de valeurs stockées avec un horodatage. Dans Azure, la plupart des métriques sont stockées dans la base de données de série chronologique des métriques Azure. Lorsque vous tracez un graphique, les valeurs des métriques sélectionnées sont extraites de la base de données, puis agrégées séparément en fonction de la granularité temporelle choisie (également appelée fragment de temps). Vous sélectionnez la taille de la granularité temporelle à l’aide du sélecteur d’heure de l’explorateur de métriques. Si vous n’effectuez pas de sélection explicite, la granularité temporelle est automatiquement sélectionnée en fonction de l’intervalle de temps actuellement sélectionné. Une fois la sélection effectuée, les valeurs de métriques qui ont été capturées à chaque intervalle de granularité temporelle sont agrégées et placées sur le graphique (un point de données par intervalle).
Types d’agrégation
Cinq types d’agrégation de base sont disponibles dans Metrics Explorer : L’explorateur de métriques masque les agrégations non pertinentes et ne peut pas être utilisé pour une métrique donnée.
- Somme : somme de toutes les valeurs capturées au cours de l’intervalle d’agrégation. La somme est parfois appelée « agrégation totale ».
- Nombre : nombre de mesures capturées au cours de l’intervalle d’agrégation. La fonction "Count" ne prend pas en compte la valeur de la mesure, seulement le nombre d'enregistrements.
- Moyenne : moyenne des valeurs de métriques capturées au cours de l’intervalle d’agrégation. Pour la plupart des métriques, cette valeur correspond à celle de Somme ou de Nombre.
- Min : la plus petite valeur capturée au cours de l’intervalle d’agrégation.
- Max : la plus grande valeur capturée au cours de l’intervalle d’agrégation.
Supposons, par exemple, qu’un graphique montre la métrique Trafic réseau sortant total pour une machine virtuelle, en utilisant l’agrégation SUM sur les dernières 24 heures. La plage temporelle et la granularité peuvent être modifiées en haut à droite du graphique, comme le montre la capture d’écran suivante.
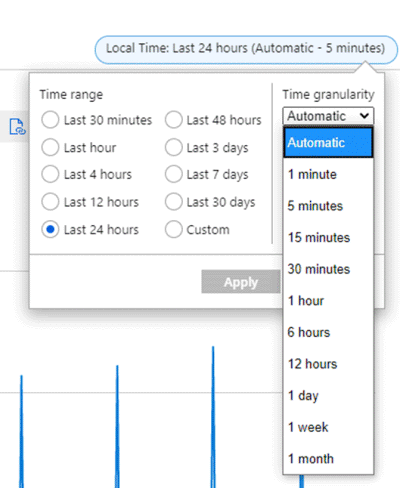
Pour la granularité temporelle = 30 minutes et pour la plage temporelle = 24 heures :
- Le graphique est dessiné à partir de 48 points de données se présentant sous la forme de points de données de 1 minute agrégés (24 heures x 2 points de données par heure (60 minutes/30 minutes)).
- Le graphique linéaire relie 48 points dans la zone de traçage du graphique.
- Chaque point de données représente la somme de tous les octets sortants réseau qui sont envoyés au cours de chaque période de 30 minutes.

Cliquez sur les images de cette section pour les afficher en plus grand.
Si vous configurez la granularité temporelle sur 15 minutes, le graphique sera dessiné à partir de 96 points de données agrégés. Autrement dit, 60 min/15 min = 4 points de données par heure x 24 heures.

Pour une granularité temporelle de 5 minutes, vous obtenez 24 x (60/5) = 288 points.
Pour une granularité temporelle de 1 minute (la plus petite possible sur le graphique), vous obtenez 24 x 60/1 = 1 440 points.

Comme vous pouvez le voir dans les captures d’écran précédentes, les graphiques ont une apparence différente selon les sommes. Remarquez que cette machine virtuelle dispose de nombreuses sorties pendant une courte période par rapport au reste de la fenêtre de temps.
La granularité temporelle vous permet d’ajuster le rapport signal/bruit sur un graphique. Les agrégations les plus élevées suppriment le bruit et aplanissent les pics. Remarquez les variations du graphique avec une granularité de 1 minute, ainsi que la façon dont elles s’aplanissent à mesure que les valeurs de granularité augmentent.
Ce comportement d’aplanissement est important lorsque vous envoyez ces données à d’autres systèmes, par exemple pour des alertes. En règle générale, vous ne souhaitez généralement pas être alerté par des pics courts en temps CPU dépassant 90 %. Toutefois, si le processeur reste à 90 % pendant 5 minutes, il s’agit probablement d’un problème important. Si vous configurez une règle d’alerte pour le processeur (ou pour n’importe quelle métrique), le fait d’augmenter la granularité temporelle pourra réduire le nombre de fausses alertes que vous recevez.
Il est important de savoir ce qui est « normal » pour votre charge de travail afin de déterminer l’intervalle de temps le mieux adapté. Cela fait partie des avantages des alertes dynamiques, qui ne seront pas abordées ici.
Comment le système collecte les métriques
La collecte des données varie selon la métrique.
Remarque
Les exemples ci-dessous sont simplifiés pour l’illustration et les métriques réelles incluses dans chaque agrégation sont affectées par les données disponibles à la survenue de l’évaluation.
Fréquence de collecte des mesures
Il existe deux types de périodes de collecte.
Régulier : la métrique est collectée à un intervalle de temps invariable.
D’après l’activité : la métrique est collectée en fonction du moment où se produit une transaction d’un certain type. Chaque transaction est associée à une entrée de métrique et à un horodatage. Elle n’est pas collectée à intervalles réguliers. Par conséquent, le nombre d’enregistrements varie sur une période donnée.
Granularité
La granularité temporelle minimale est de 1 minute, mais le système sous-jacent peut capturer des données plus rapidement en fonction de la métrique. Par exemple, le pourcentage de processeur pour une VM Azure est capturé selon un intervalle de temps de 15 secondes. Étant donné que les échecs HTTP sont capturés comme des transactions, ils peuvent dépasser largement 1 minute. D’autres métriques, telles que le stockage SQL, sont capturées selon un intervalle de temps de 20 minutes. Ce choix dépend du fournisseur et du type de ressources. La plupart tentent de fournir le plus petit intervalle de temps possible.
Dimensions, fractionnement et filtrage
Des métriques sont capturées pour chaque ressource. Toutefois, le niveau auquel les métriques sont collectées, stockées et représentées sous forme de graphique peut varier. Ce niveau est représenté par d’autres métriques disponibles dans les dimensions de métriques. Chaque fournisseur de ressources choisit le niveau de détail des données collectées. Azure Monitor définit uniquement la manière dont ces détails sont présentés et stockés.
Dans Metrics Explorer, lorsque vous représentez une métrique sous forme de graphique, vous avez la possibilité de « fractionner » le graphique en fonction d’une dimension. Le fractionnement d’un graphique vous permet d’examiner les données sous-jacentes pour obtenir plus de détails, mais également de voir que les données sont représentées sous forme graphique ou qu’elles sont filtrées dans l’explorateur de métriques.
Par exemple, pour Microsoft.ApiManagement/service, Emplacement est une dimension qui est définie pour de nombreuses métriques.
Capacité fait partie de ces métriques. L’utilisation de la dimension Emplacement signifie que le système sous-jacent va stocker un enregistrement de métrique pour la capacité de chaque emplacement, plutôt qu’un seul pour la quantité agrégée. Vous pouvez ensuite récupérer ou fractionner ces informations dans un graphique de métriques.
Lorsque vous regardez Durée globale des demandes de passerelle, vous voyez deux dimensions : Emplacement et Nom d’hôte. Celles-ci vous indiquent l’emplacement d’une durée, ainsi que le nom d’hôte dont elle provient.
L’une des métriques les plus flexibles, Demandes, comporte 7 dimensions.
Consultez les métriques prises en charge avec l’article Azure Monitor pour plus d’informations sur chaque métrique et les dimensions disponibles. De plus, la documentation de chaque type et chaque fournisseur de ressources peut fournir des informations supplémentaires sur les dimensions et sur ce qu’elles permettent de mesurer.
Vous pouvez utiliser à la fois le fractionnement et le filtrage des données pour examiner un problème. Vous trouverez ci-dessous un exemple de graphique présentant la métrique Moy. disque, octets/écriture pour un groupe de machines virtuelles au sein d’un groupe de ressources. Avec cette métrique, nous avons un récapitulatif pour toutes les machines virtuelles. Toutefois, nous pourrions vouloir connaître les machines responsables des pics survenus aux environs de 6 h 00. S’agit-il d’une seule et même machine ? Combien de machines sont impliquées ?

Cliquez sur les images de cette section pour les afficher en plus grand.
Lorsque nous appliquons le fractionnement, nous pouvons voir les données sous-jacentes. Toutefois, c'est un peu le bazar. Il se trouve que 20 machines virtuelles sont agrégées dans le graphique ci-dessus. Ici, nous avons utilisé notre souris pour pointer sur le pic de 6 h 00, qui nous indique que CH-DCVM11 est en cause. Toutefois, il est difficile de voir les autres données associées à cette machine virtuelle, car d’autres machines virtuelles encombrent le graphique.

L’utilisation du filtrage nous permet de nettoyer le graphique pour voir ce qu’il se passe vraiment. Vous pouvez cocher ou décocher les machines virtuelles que vous souhaitez afficher. Remarquez les lignes en pointillés. Celles-ci seront mentionnées dans une prochaine section.

Pour plus d’informations sur la façon d’afficher des données de dimension fractionnées sur un graphique Metric Explorer, consultez Utiliser des filtres de dimension et le fractionnement.
Valeurs NULL et égales à zéro
Lorsque le système s’attend à recevoir des données de métriques d’une ressource, mais ne les reçoit pas, il enregistre une valeur NULL. Une valeur NULL n’équivaut pas à une valeur de zéro, ce qu’il est très important de prendre en compte lors du calcul des agrégations et de la génération des graphiques. Les valeurs NUL ne sont pas comptabilisées comme des mesures valides.
Les valeurs NULL s’affichent différemment selon les graphiques. Les nuages de points ne montrent pas l’un des points sur le graphique. Les graphiques à barres ne montrent pas la barre. Sur les graphiques en courbes, les valeurs NULL peuvent s’afficher sous forme de lignes en traits ou en pointillés, comme celles que montre la capture d’écran de la section précédente. Lorsque vous calculez des moyennes comprenant des valeurs NULL, il y a moins de points de données desquels utiliser la moyenne. Ce comportement peut parfois entraîner une baisse inattendue des valeurs d’un graphique, même si, généralement, cela se produit plus lorsque la valeur a été convertie en un zéro, puis utilisée comme un point de données valide.
Les métriques personnalisées utilisent toujours des valeurs NULL lorsqu’elles ne reçoivent aucune donnée. Avec les métriques de plateforme, chaque fournisseur de ressources décide s’il faut utiliser des zéros ou des valeurs NULL en fonction de ce qui convient le mieux pour une métrique donnée.
Les alertes Azure Monitor utilisent les valeurs que le fournisseur de ressources écrit dans la base de données de métriques. Il est donc important de savoir comment le fournisseur de ressources gère les valeurs NULL en affichant d’abord les données.
Fonctionnement de l’agrégation
Les graphiques de métriques du système précédent affichent différents types de données agrégées. Le système pré-agrège les données afin que les graphiques demandés puissent s’afficher plus rapidement sans nécessiter plusieurs calculs répétés.
Dans cet exemple :
- Nous collectons une métrique transactionnelle fictive appelée Échecs HTTP
- La dimension Serveur est une dimension pour la métrique Échecs HTTP.
- Nous avons trois serveurs : les serveurs A, B et C.
Pour simplifier l’explication, nous commençons uniquement par le type d’agrégation SUM.
Agrégation allant de moins d’une minute à 1 minute
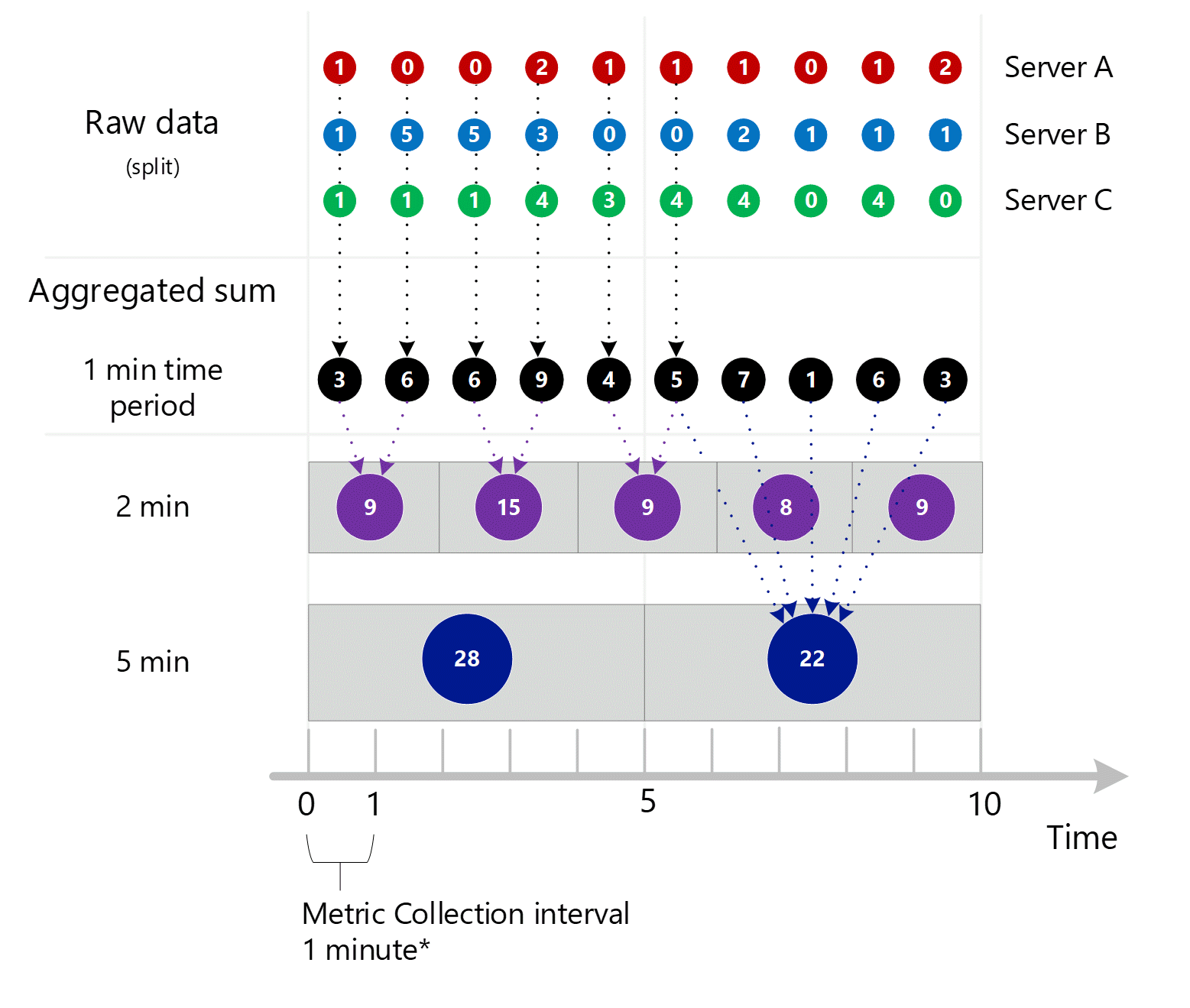
Les premières données de métriques brutes sont collectées et stockées dans la base de données de métriques Azure Monitor. Dans ce cas, chaque serveur stocke des enregistrements de transaction avec un horodatage, car Serveur est une dimension. Étant donné que la plus courte période que vous pouvez afficher en tant que client est égale à 1 minute, ces horodatages sont d’abord regroupés en valeurs de métriques d’une minute pour chacun des serveurs. Le processus d’agrégation pour le serveur B est indiqué dans le graphique ci-dessous. La configuration des serveurs A et C est effectuée de la même manière, et ceux-ci contiennent des données différentes.
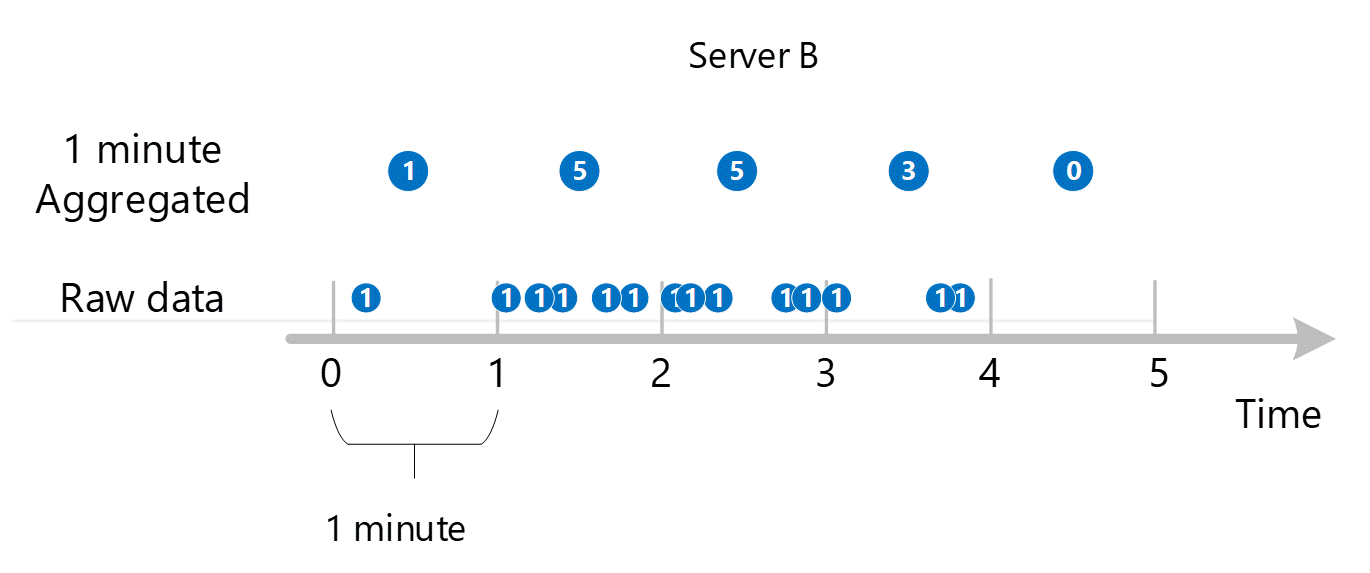
Les valeurs agrégées de 1 minute obtenues sont stockées en tant que nouvelles entrées dans la base de données de métriques, afin qu’elles puissent être collectées dans le cadre de prochains calculs.
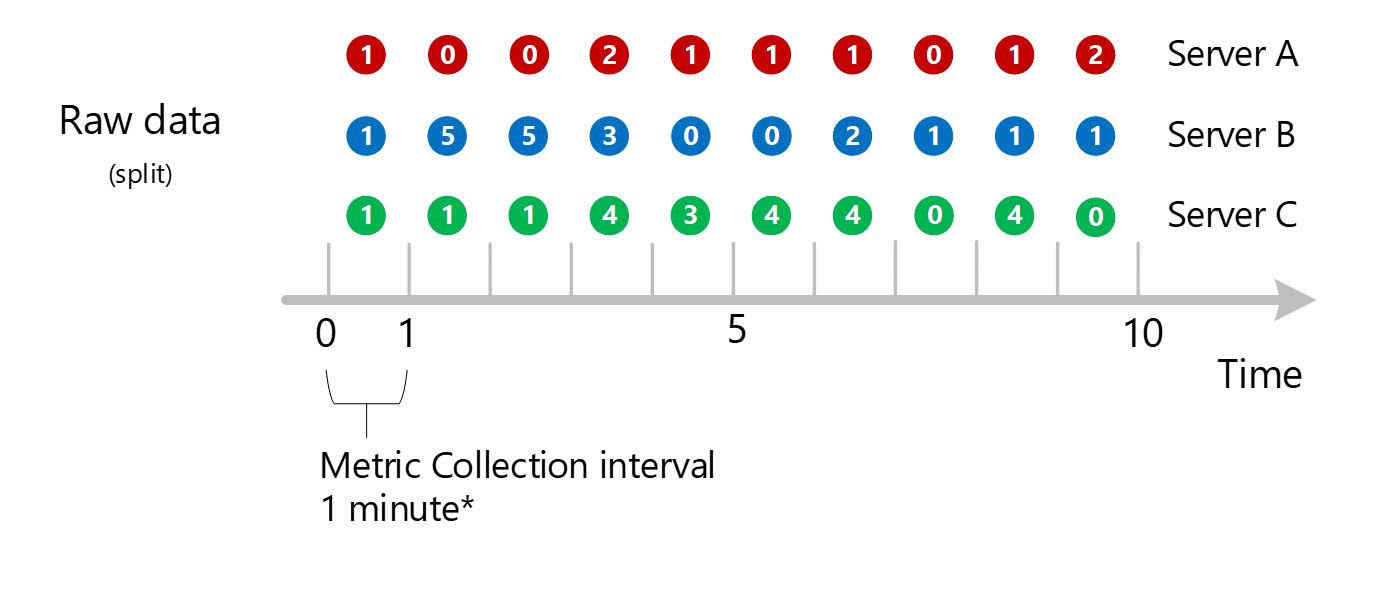
Agrégation des dimensions
Les calculs de 1 minute sont ensuite réduits par dimension et stockés à nouveau comme des enregistrements individuels. Dans ce cas, toutes les données de tous les serveurs sont agrégées dans une métrique d’intervalle de 1 minute, puis elles sont stockées dans la base de données de métriques en vue d’une utilisation dans de prochaines agrégations.
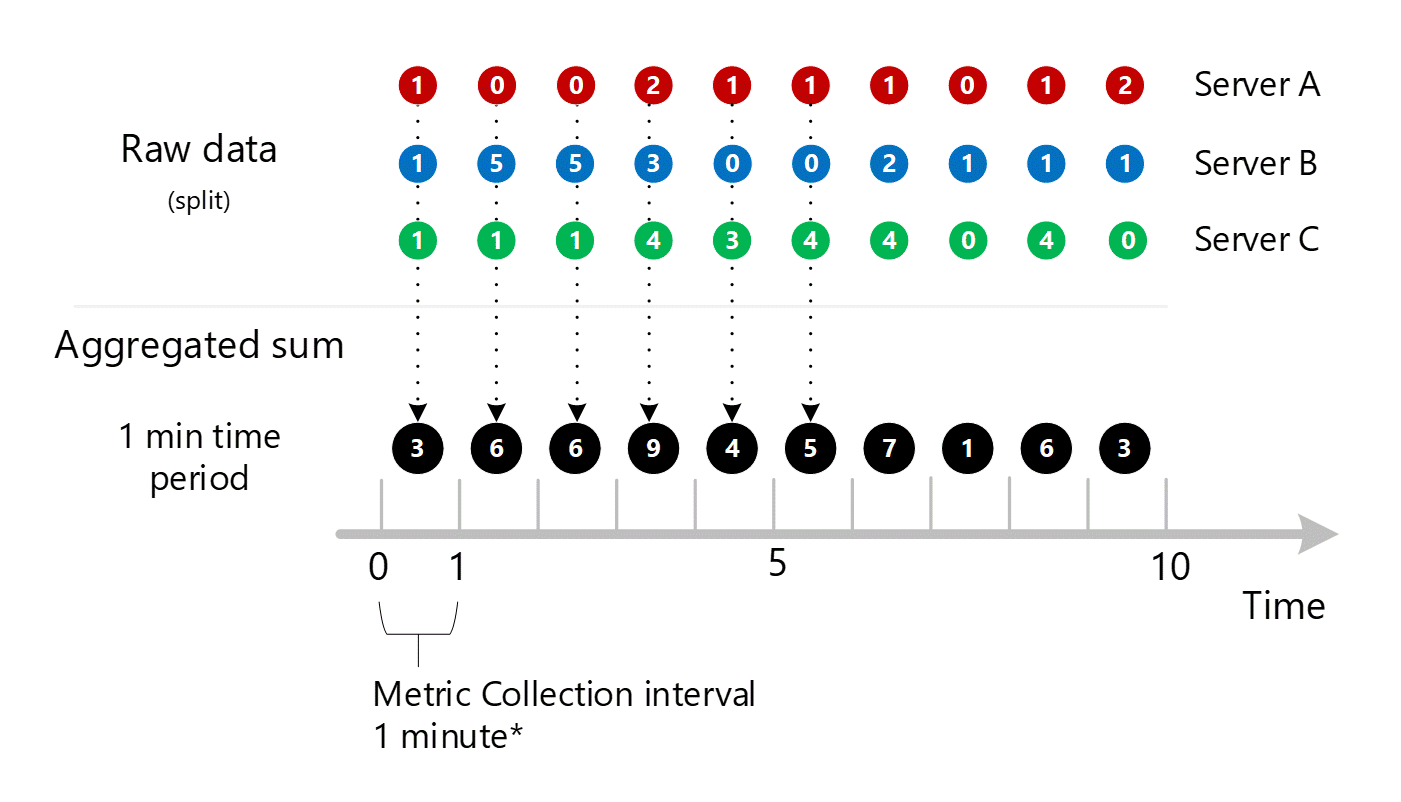
Par souci de clarté, le tableau suivant montre la méthode d’agrégation.
| Période | Serveur A | serveur B. | le serveur C. | Somme (A+B+C) |
|---|---|---|---|---|
| Minute 1 | 1 | 1 | 1 | 3 |
| Minute 2 | 0 | 5 | 1 | 6 |
| Troisième minute | 0 | 5 | 1 | 6 |
| 4ème Minute | 2 | 3 | 4 | 9 |
| Cinquième minute | 1 | 0 | 3 | 4 |
| Minute 6 | 1 | 0 | 4 | 5 |
| Minute 7 | 1 | 2 | 4 | 7 |
| Minute 8 | 0 | 1 | 0 | 1 |
| Minute 9 | 1 | 1 | 4 | 6 |
| Minute 10 | 2 | 1 | 0 | 3 |
Une seule dimension est présentée ci-dessus. Toutefois, le même processus d’agrégation et de stockage se produit pour toutes les dimensions qui sont prises en charge par une métrique.
- Collectez les valeurs dans un ensemble agrégé de 1 minute selon cette dimension. Stockez ces valeurs.
- Réduisez la dimension en une somme agrégée de 1 minute. Stockez ces valeurs.
Nous allons introduire une autre dimension des échecs HTTP : « NetworkAdapter ». Supposons que nous ayons un nombre variable d'adaptateurs par serveur.
- Le serveur A a 1 carte
- Le serveur B a 2 cartes
- Le serveur C a 3 cartes
Nous allons collecter les données des transactions suivantes séparément. Elles seraient marquées par :
- Un moment
- Une valeur
- Le serveur d’où provient la transaction
- L'adaptateur d'où provient la transaction
Ces flux inférieurs à 1 minute sont ensuite agrégés en valeurs de série chronologique de 1 minute, puis ils sont stockés dans la base de données de métriques Azure Monitor :
- Serveur A, Adaptateur 1
- Serveur B, Carte 1
- Serveur B, Carte 2
- Serveur C, Carte 1
- Serveur C, Adaptateur 2
- Serveur C, Carte 3
En outre, les agrégations réduites suivantes sont également stockées :
- Serveur A, Carte 1 (étant donné qu’il n’y a rien à réduire, les données sont à nouveau stockées)
- Serveur B, Adaptateur 1+2
- Serveur C, Adaptateurs 1+2+3
- Tous les serveurs et toutes les cartes
Cela montre que les métriques qui ont un grand nombre de dimensions comportent un plus grand nombre d’agrégations. Il n’est pas nécessaire de connaître toutes les permutations, mais simplement de comprendre le raisonnement. Le système souhaite que les données individuelles et les données agrégées soient stockées en vue d’être récupérées rapidement à partir de n’importe quel graphique. Le système sélectionne l’agrégation stockée ou les données brutes sous-jacentes les plus pertinentes en fonction de ce que vous choisissez d’afficher.
Agrégation sans dimension
Étant donné que cette métrique comporte une dimension Serveur, vous pouvez accéder aux données sous-jacentes des serveurs A, B et C ci-dessus via le fractionnement et le filtrage, comme expliqué plus haut dans cet article. Si la métrique n’avait pas la dimension Serveur, vous, en tant que client, pourriez uniquement accéder aux sommes agrégées de 1 minute qui s’affichent en noir sur le diagramme. Ce sont les valeurs 3, 6, 6, 9, etc. Le système ne va pas non plus effectuer le travail sous-jacent pour agréger les valeurs fractionnées, il ne va pas les utiliser dans Metrics Explorer, ni les envoyer par l’API REST pour les métriques.
Affichage des granularités temporelles supérieures à 1 minute
Si vous demandez des mesures avec une granularité plus large, le système utilise les sommes agrégées d'une minute pour calculer les sommes pour de plus grandes granularités temporelles. Les lignes en pointillés ci-dessous montrent la méthode de somme qui est employée pour les granularités temporelles de 2 et 5 minutes. Là encore, nous n’affichons que le type d’agrégation SUM pour des raisons de simplicité.
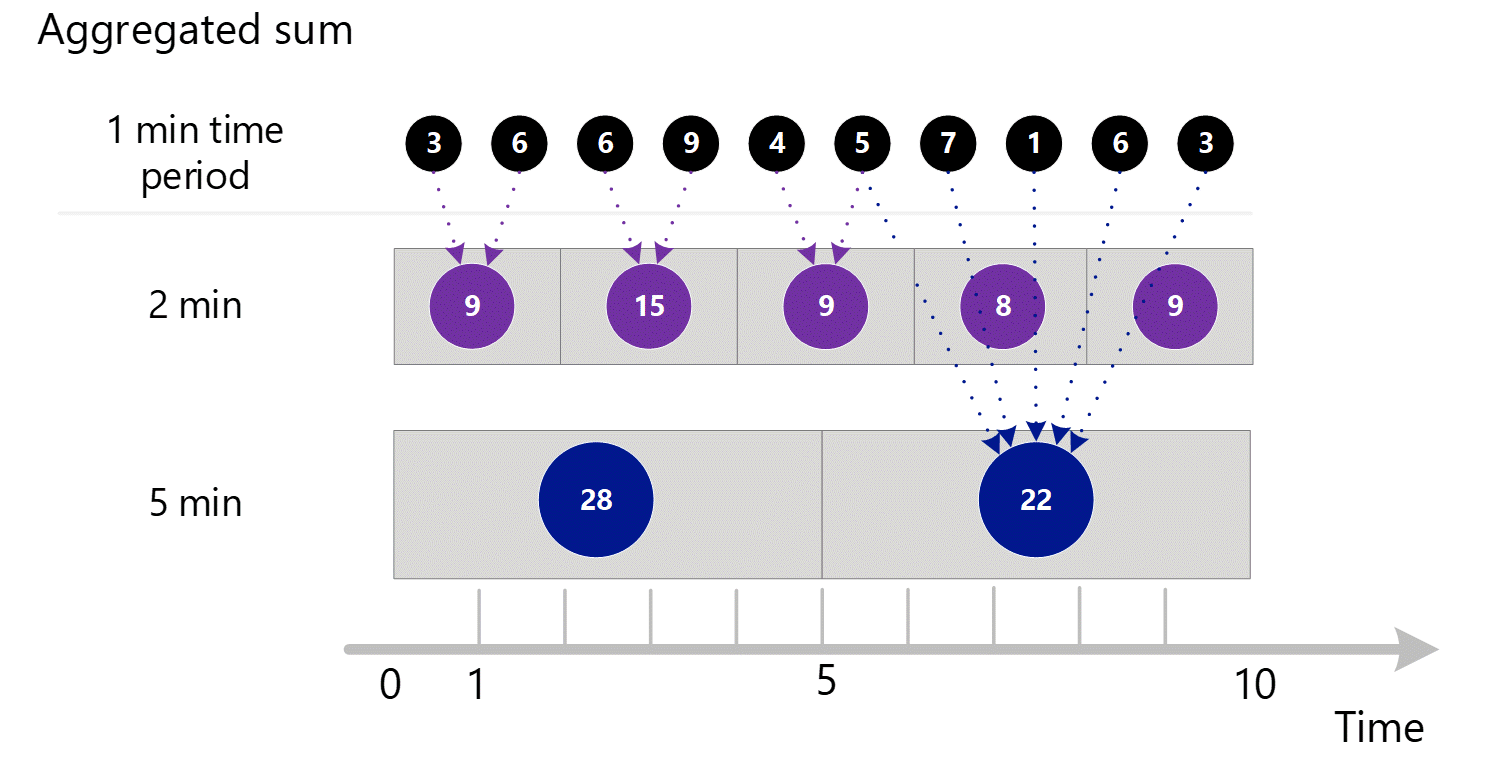
Pour la granularité temporelle de 2 minutes.
| Période | Sommes |
|---|---|
| Minutes 1 et 2 | (3 + 6) = 9 |
| Minutes 3 et 4 | (6 + 9) = 15 |
| Minutes 4 et 5 | (4 + 5) = 9 |
| Minutes 6 et 7 | (7 + 1) = 8 |
| Minutes 8 et 9 | (6 + 3) = 9 |
Pour la granularité temporelle de 5 minutes.
| Période | Sommes |
|---|---|
| Minutes de 1 à 5 | 3 + 6 + 6 + 9 + 4 = 28 |
| Minutes de 6 à 10 | 5 + 7 + 1 + 6 + 3 = 22 |
Le système utilise les données agrégées stockées qui offrent les meilleures performances.
Vous trouverez ci-dessous le diagramme plus grand pour le processus d'agrégation de 1 minute ci-dessus, auquel nous avons retiré certaines flèches pour améliorer la lisibilité.
Exemple plus complexe
Voici un exemple plus complexe qui utilise des valeurs pour une métrique fictive appelée « Temps de réponse HTTP en millisecondes ». Ici, nous utilisons d’autres niveaux de complexité.
- Nous affichons l’agrégation pour Somme, Nombre, Min et Max, et le calcul pour Moyenne.
- Nous montrons les valeurs NULL et la façon dont elles affectent les calculs.
Considérez l'exemple suivant. Les flèches et les données encadrées montrent comment les valeurs sont agrégées et calculées.
Le processus de préagrégation de 1 minute qui est décrit dans la section précédente se produit également pour Sommes, Nombre, Minimum et Maximum. Toutefois, la moyenne N’est PAS préagrégée. Cela est recalculé à l’aide de données agrégées pour éviter des erreurs de calcul.

Prenons la minute 6 pour l’agrégation de 1 minute qui est mise en évidence ci-dessus. Cette minute correspond au moment où le serveur B a été mis hors connexion et a arrêté les données de rapport, peut-être en raison d’un redémarrage.
À partir de la minute 6 ci-dessus, les types d’agrégation de 1 minute calculés sont les suivants :
| Type d’agrégation | Valeur | Remarques |
|---|---|---|
| Somme | 53+20=73 | |
| Nombre | 2 | Montre l’effet des valeurs NULL. Si le serveur avait été en ligne, la valeur aurait été de 3. |
| Minimum | 20 | |
| Maximale | 53 | |
| Moyenne | 73/2 | Toujours la somme divisée par le nombre. Elle n’est jamais stockée et toujours recalculée pour chaque granularité temporelle à l’aide des nombres agrégés pour cette granularité. Remarquez le recalcul pour les granularités temporelles de 5 minutes et 10 minutes qui est mis en évidence ci-dessus. |
Le texte en rouge indique les valeurs qui peuvent être considérées comme étant en dehors de la plage normale, et montre comment elles se propagent (ou échouent) à mesure que la granularité temporelle augmente. Remarquez que les valeurs Min et Max indiquent des anomalies sous-jacentes, et que Moyenne et Sommes perdent ces informations à mesure que la granularité temporelle augmente.
Vous pouvez également voir que les valeurs NULL offrent un meilleur calcul de moyenne que les zéros.
Remarque
Même si ce n’est pas le cas dans cet exemple, Nombre est égal à Somme lorsqu’une métrique est systématiquement capturée avec une valeur de 1. C’est courant lorsqu’une métrique effectue le suivi de l’occurrence d’un événement transactionnel (par exemple, le nombre d’échecs HTTP mentionnés dans un précédent exemple de cet article).