Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Le service géré pour Prometheus Azure Monitor collecte des métriques auprès des clusters Azure Kubernetes et les stocke dans un espace de travail Azure Monitor. PromQL (langage de requête Prometheus) est un langage de requête fonctionnel qui vous permet d’interroger et d’agréger des données de série chronologique. Utilisez PromQL pour interroger et agréger les métriques stockées dans un espace de travail Azure Monitor.
Cet article explique comment interroger un espace de travail Azure Monitor à l’aide de PromQL via l’API REST. Pour plus d’informations sur PromQL, consultez Requêtes Prometheus.
Conditions préalables
Pour interroger un espace de travail Azure Monitor à l’aide de PromQL, vous avez besoin des prérequis suivants :
- Un cluster Azure Kubernetes ou un cluster Kubernetes distant.
- Scraping des métriques d’un service géré pour Prometheus Azure Monitor à partir d’un cluster Kubernetes.
- Un espace de travail Azure Monitor dans lequel les métriques Prometheus sont stockées.
Authentification
Pour interroger votre espace de travail Azure Monitor, authentifiez-vous avec Microsoft Entra ID. L’API prend en charge l’authentification Microsoft Entra en utilisant les informations d’identification du client. Inscrivez une application cliente auprès de Microsoft Entra ID et demandez un jeton.
Pour configurer l’authentification Microsoft Entra, suivez les étapes ci-dessous :
- Inscrivez une application auprès de Microsoft Entra ID.
- Accordez l’accès à l’application à votre espace de travail Azure Monitor.
- Demandez un jeton.
Inscrire une application à Microsoft Entra ID
- Pour inscrire une application, suivez les étapes de l’inscription d’une application pour demander des jetons d’autorisation et utiliser des API.
Autoriser votre application à accéder à votre espace de travail
Attribuez le rôle Lecteur de données de supervision à votre application pour qu’elle puisse interroger des données à partir de votre espace de travail Azure Monitor.
Ouvrez votre espace de travail Azure Monitor dans le portail Azure.
Dans la page de présentation, notez le point de terminaison de votre requête à utiliser dans votre requête REST.
Sélectionnez Contrôle d’accès (IAM) .
Sélectionnez Ajouter, puis Ajouter une attribution de rôle dans la page Access Control (IAM).
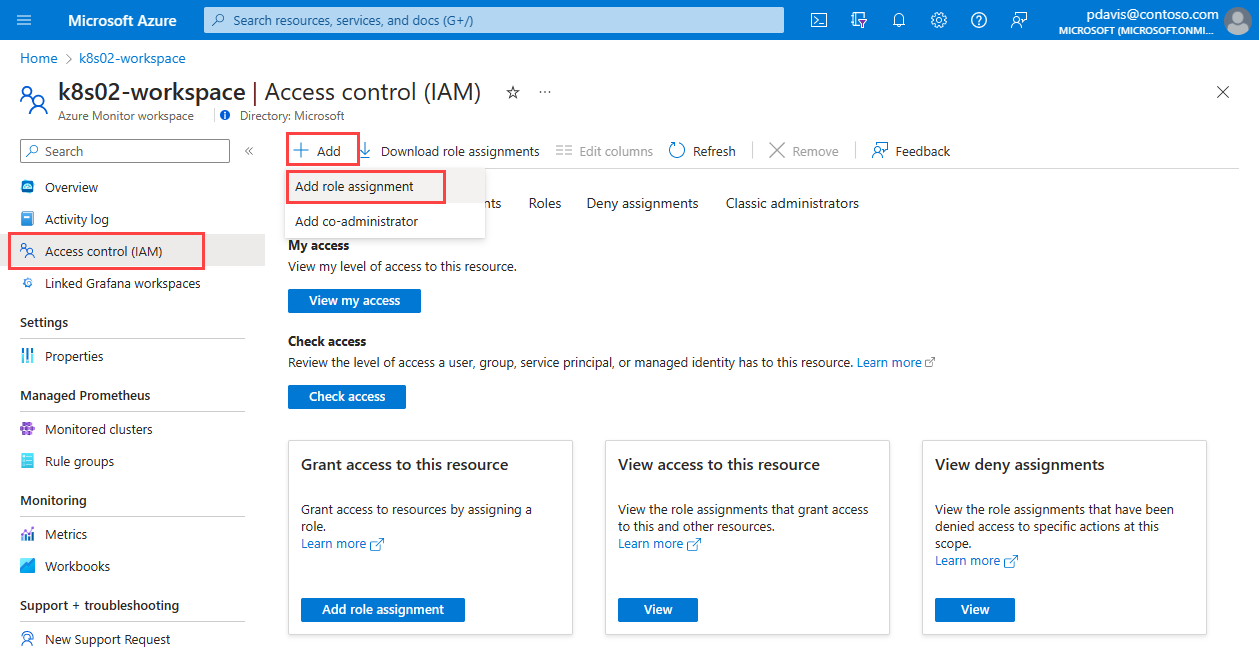
Dans la Page d'ajout d'une attribution de rôle, recherchez Monitoring.
Sélectionnez Lecteur de données d’analyse, puis sélectionnez l’onglet Membres.
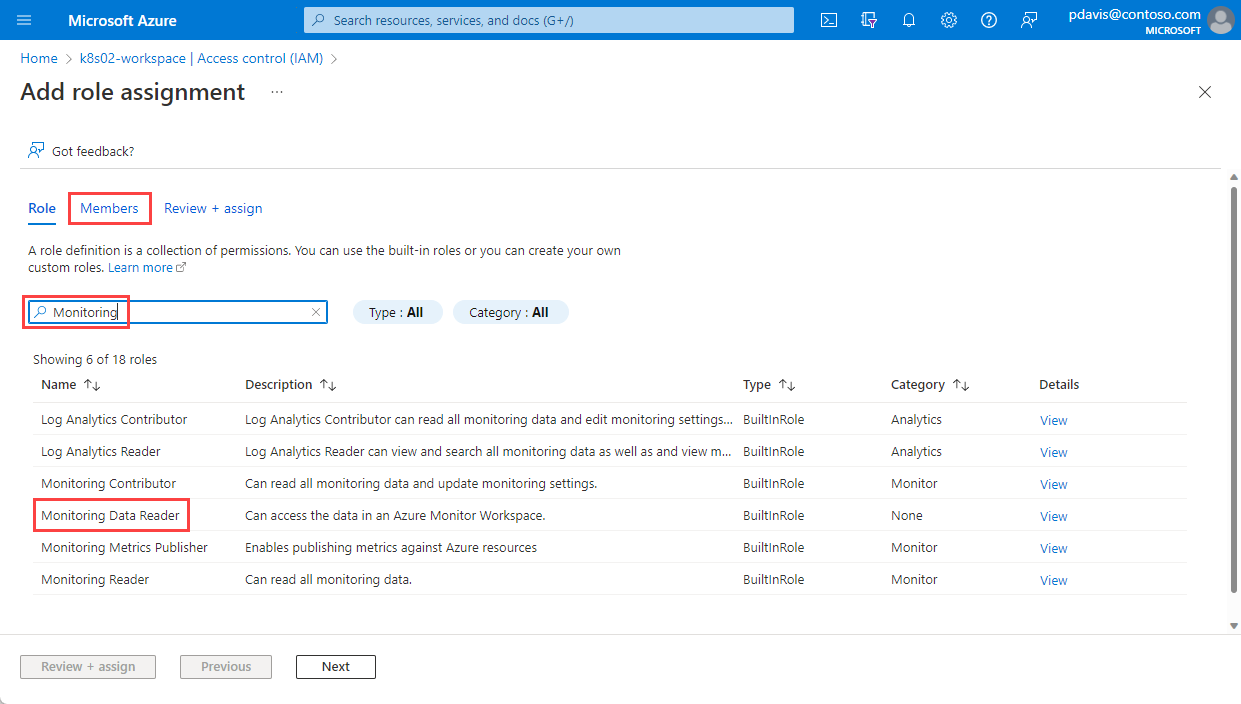
Sélectionnez Sélectionner des membres.
Recherchez et sélectionnez l’application enregistrée.
Choisissez Sélectionner.
Sélectionnez Examiner + Attribuer.
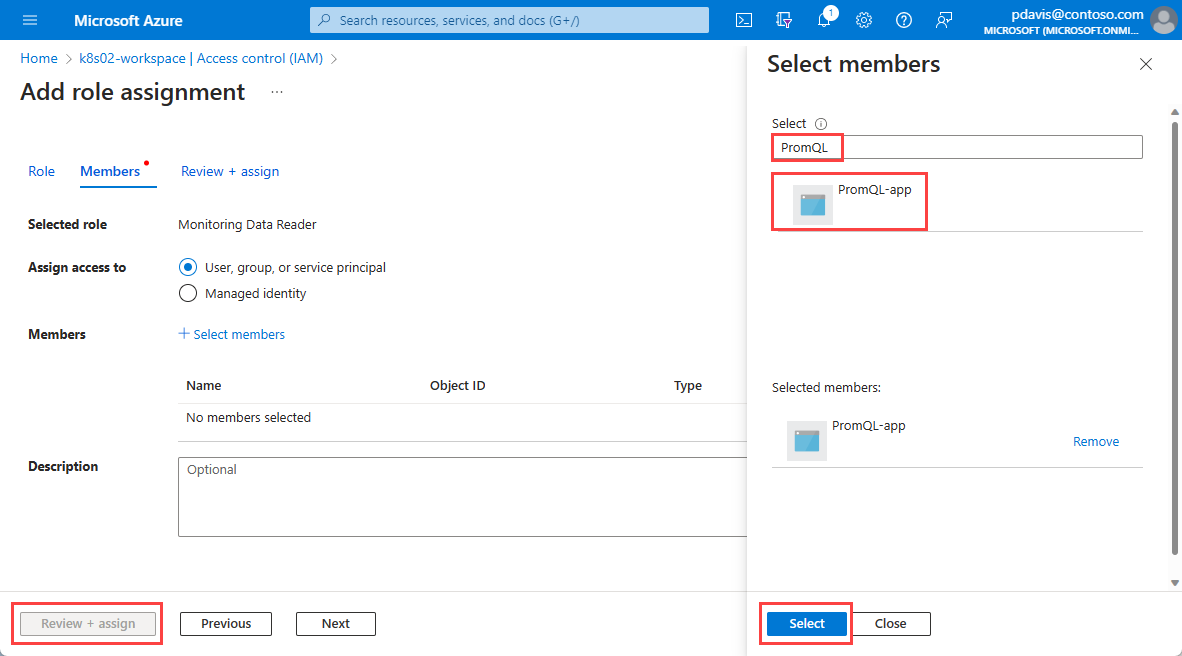



Vous avez créé votre inscription d’application et vous lui avez attribué l’accès aux données de requête à partir de votre espace de travail Azure Monitor. Vous pouvez maintenant générer un jeton et l’utiliser dans une requête.
Demander un jeton
Envoyez la requête suivante dans l’invite de commandes ou à l’aide d’un client tel qu’Insomnia ou Invoke-RestMethod de PowerShell.
curl -X POST 'https://login.microsoftonline.com/<tenant ID>/oauth2/token' \
-H 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'grant_type=client_credentials' \
--data-urlencode 'client_id=<your apps client ID>' \
--data-urlencode 'client_secret=<your apps client secret>' \
--data-urlencode 'resource=https://prometheus.monitor.azure.com'
Exemple de corps de réponse :
{
"token_type": "Bearer",
"expires_in": "86399",
"ext_expires_in": "86399",
"expires_on": "1672826207",
"not_before": "1672739507",
"resource": "https:/prometheus.monitor.azure.com",
"access_token": "eyJ0eXAiOiJKV1Qi....gpHWoRzeDdVQd2OE3dNsLIvUIxQ"
}
Enregistrez le jeton d’accès à partir de la réponse pour l’utiliser dans les requêtes HTTP suivantes.
Point de terminaison de requête
Recherchez le point de terminaison de requête de votre espace de travail Azure Monitor dans la page de présentation de l’espace de travail Azure Monitor.

API prises en charge
Les requêtes suivantes sont prises en charge :
Requêtes instantanées
Pour plus d’informations, consultez Requêtes instantanées.
Chemin d'accès : /api/v1/query
Exemples :
POST https://k8s-02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/query
--header 'Authorization: Bearer <access token>'
--header 'Content-Type: application/x-www-form-urlencoded'
--data-urlencode 'query=sum( \
container_memory_working_set_bytes \
* on(namespace,pod) \
group_left(workload, workload_type) \
namespace_workload_pod:kube_pod_owner:relabel{ workload_type="deployment"}) by (pod)'
GET 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/query?query=container_memory_working_set_bytes'
--header 'Authorization: Bearer <access token>'
Requêtes de plage
Pour plus d’informations, consultez Requêtes de plage
Chemin d'accès : /api/v1/query_range
Exemples :
GET 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/query_range?query=container_memory_working_set_bytes&start=2023-03-01T00:00:00.000Z&end=2023-03-20T00:00:00.000Z&step=6h'
--header 'Authorization: Bearer <access token>
POST 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/query_range'
--header 'Authorization: Bearer <access token>'
--header 'Content-Type: application/x-www-form-urlencoded'
--data-urlencode 'query=up'
--data-urlencode 'start=2023-03-01T20:10:30.781Z'
--data-urlencode 'end=2023-03-20T20:10:30.781Z'
--data-urlencode 'step=6h'
Série
Pour plus d’informations, consultez Series.
Chemin d'accès : /api/v1/series
Exemples :
POST 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/series'
--header 'Authorization: Bearer <access token>
--header 'Content-Type: application/x-www-form-urlencoded'
--data-urlencode 'match[]=kube_pod_info{pod="bestapp-123abc456d-4nmfm"}'
GET 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/series?match[]=container_network_receive_bytes_total{namespace="default-1669648428598"}'
Étiquettes
Pour plus d’informations, consultez Étiquettes.
Chemin d'accès : /api/v1/labels
Exemples :
GET 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/labels'
POST 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/labels'
Valeurs des étiquettes
Pour plus d’informations, consultez Valeurs d’étiquette.
Chemin d'accès : /api/v1/label/__name__/values.
Remarque
__name__ est la seule version prise en charge de cette API et retourne tous les noms de métriques. Aucune autre /api/v1/label/<label_name>/values n’est prise en charge.
Exemple :
GET 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/label/__name__/values'
Pour obtenir la spécification complète des API de promotion OSS, consultez API HTTP Prometheus.
Limitations de l’API
Les limitations suivantes s’ajoutent à celles détaillées dans la spécification Prometheus.
La requête doit être limitée à une métrique.
Toutes les requêtes d’extraction de séries chronologiques (/series ou /query ou /query_range) doivent contenir un label matcher __name__. Autrement dit, chaque requête doit être limitée à une métrique. Il ne peut y avoir qu'un seul correspondant d'étiquette __name__ dans une requête.
La requête /series ne prend pas en charge le filtre d’expression régulière
Intervalle de temps pris en charge
- L’API /query_range prend en charge un intervalle de temps de 32 jours. Il s’agit de l’intervalle de temps maximal autorisé, y compris les sélecteurs de plage spécifiés dans la requête elle-même. Par exemple, la requête
rate(http_requests_total[1h]des dernières 24 heures signifie que les données sont interrogées pendant 25 heures. En effet, cela correspond à la plage de 24 heures plus l’heure spécifiée dans la requête elle-même. - L’API /series extrait les données pendant un intervalle de temps maximal de 12 heures. Si
endTimen’est pas fourni, endTime = time.now(). Si la plage de temps est supérieure à 12 heures, la valeurstartTimeest définie àendTime – 12h.
- L’API /query_range prend en charge un intervalle de temps de 32 jours. Il s’agit de l’intervalle de temps maximal autorisé, y compris les sélecteurs de plage spécifiés dans la requête elle-même. Par exemple, la requête
Intervalle de temps ignoré
L’heure de début et l’heure de fin fournies avec
/labelset/label/__name__/valuessont ignorées, et toutes les données conservées dans l’espace de travail Azure Monitor sont interrogées.Fonctionnalités expérimentales
Les fonctionnalités expérimentales, telles que les exemples, ne sont pas prises en charge.
Pour plus d’informations sur les limites des métriques Prometheus, consultez les métriques Prometheus.
Respect de la casse
Le service géré Azure Monitor pour Prometheus est un système qui n’est pas sensible à la casse. Il traite des chaînes (telles que des noms de métriques, des noms d’étiquettes ou des valeurs d’étiquettes) comme étant la même série chronologique si elles ne se distinguent pas d’une autre série chronologique par autre chose que la casse de la chaîne de caractères.
Remarque
Ce comportement est différent de celui du système open source natif Prometheus, qui est sensible à la casse. Les instances Prometheus autogérées exécutées dans des machines virtuelles Azure, des jeux d’échelle de machines virtuelles ou des clusters Azure Kubernetes Service sont des systèmes sensibles à la casse.
Dans le service géré pour Prometheus, les séries chronologiques suivantes sont considérées comme étant identiques :
diskSize(cluster="eastus", node="node1", filesystem="usr_mnt")
diskSize(cluster="eastus", node="node1", filesystem="usr_MNT")
Les exemples précédents concernent une seule série chronologique dans une base de données de séries chronologiques. Les considérations suivantes s'appliquent :
- Tous les échantillons qui y sont ingérés sont stockés comme s’ils étaient extraits ou ingérés dans le cadre d’une série chronologique unique.
- Si les exemples précédents sont ingérés avec le même horodatage, l’un d’entre eux est éliminé de manière aléatoire.
- La casse stockée dans la base de données de série chronologique et retournée par une requête est imprévisible. Une même série chronologique peut retourner des casses différentes à des moments différents.
- Tout nom de métrique ou nom d’étiquette/valeur présent dans la requête est extrait de la base de données des séries chronologiques par une comparaison qui n’est pas sensible à la casse. Si une requête contient un sélecteur sensible à la casse, il est automatiquement traité comme un sélecteur non sensible à la casse dans les comparaisons de chaînes.
La meilleure pratique consiste à utiliser un cas unique et cohérent pour produire ou extraire une série chronologique.
Prometheus open source traite les exemples précédents comme deux séries chronologiques différentes. Tous les échantillons qui y sont prélevés ou ingérés sont conservés séparément.
Questions fréquentes
Cette section fournit des réponses aux questions courantes.
Il me manque tout ou partie de mes métriques. Comment puis-je résoudre ce problème ?
Vous pouvez utiliser le guide de résolution des problèmes pour ingérer des métriques Prometheus à partir de l’agent managé.
Pourquoi des métriques qui ont deux étiquettes portant le même nom, mais dont la casse est différente sont manquantes ?
Prometheus managé par Azure est un système qui ne respecte pas la casse. Il traite les chaînes, telles que les noms de métriques, les noms d’étiquettes ou les valeurs d’étiquette, comme les mêmes séries chronologiques si elles diffèrent d’une autre série chronologique uniquement par le cas de la chaîne. Pour plus d’informations, consultez Vue d’ensemble des métriques Prometheus.
Je vois des lacunes dans les données de métrique, pourquoi cela se produit-il ?
Lors des mises à jour des nœuds, vous pourriez remarquer une interruption de 1 à 2 minutes dans les métriques recueillies par nos collecteurs au niveau du cluster. Cet écart se produit car le nœud sur lequel les données s'exécutent est mis à jour dans le cadre d'un processus de mise à jour normal. Ce processus de mise à jour affecte les cibles à l'échelle du cluster telles que les métriques kube-state-metrics et les cibles d'application personnalisées spécifiées. Cela se produit lorsque votre cluster est mis à jour manuellement ou via une mise à jour automatique. Ce comportement est attendu et se produit en raison de la mise à jour du nœud sur lequel il s'exécute. Ce comportement n’affecte aucune de nos règles d’alerte recommandées.
Étapes suivantes
Vue d’ensemble de l’espace de travail Azure MonitorGérer un espace de travail Azure MonitorVue d’ensemble du service géré Azure Monitor pour PrometheusInterroger des métriques Prometheus en utilisant les classeurs Azure