Surveillez les machines virtuelles avec Azure Monitor : Alertes
Cet article fait partie du guide Analyse des machines virtuelles et de leurs charges de travail dans Azure Monitor. Les alertes dans Azure Monitor vous informent de façon proactive des données et des modèles intéressants dans vos données de surveillance. Il n'existe pas de règles d'alerte préconfigurées pour les machines virtuelles, mais vous pouvez créer les vôtres en fonction des données collectées par l'agent Azure Monitor. Cet article présente les concepts d’alerte spécifiques aux machines virtuelles et les règles d’alerte courantes utilisées par d’autres clients Azure Monitor.
Ce scénario décrit comment mettre en œuvre l'analyse complète de votre environnement Azure et de votre machine virtuelle hybride.
Pour commencer à surveiller votre première machine virtuelle Azure, consultez Surveiller des machines virtuelles Azure.
Pour activer rapidement un ensemble d'alertes recommandé, consultez Activer les règles d'alerte recommandées pour la machine virtuelle Azure.
Important
La plupart des règles d’alerte ont un coût qui dépend du type de règle, du nombre de dimensions incluses et de la fréquence d’exécution. Avant de créer des règles d'alerte, consultez la section Règles d'alerte dans Tarification d'Azure Monitor.
Collecte de données
Les règles d’alerte inspectent les données qui ont déjà été collectées dans Azure Monitor. Vous devez vous assurer que les données sont collectées pour un scénario particulier avant de pouvoir créer une règle d’alerte. Consultez Analyse des machines virtuelles avec Azure Monitor : Collecter des données pour obtenir des conseils sur la configuration de la collecte de données pour divers scénarios, y compris toutes les règles d'alerte mentionnées dans cet article.
Règles d’alerte recommandées
Azure Monitor fournit un ensemble de règles d’alerte recommandées que vous pouvez activer rapidement pour n’importe quelle machine virtuelle Azure. Ces règles constituent un excellent point de départ pour la surveillance de base. Mais à elles seules, elles ne fournissent pas suffisamment d'alertes pour la plupart des implémentations d'entreprise, et ce pour les raisons suivantes :
- Les alertes recommandées s’appliquent uniquement aux machines virtuelles Azure et non aux machines hybrides.
- Les alertes recommandées incluent uniquement les métriques de l’hôte et non les métriques ou journaux d’activité invités. Ces métriques sont utiles pour surveiller l'intégrité de la machine elle-même. Mais elles ne vous donnent qu'une visibilité minimale sur les charges de travail et les applications qui s'exécutent sur la machine.
- Les alertes recommandées sont associées à des machines individuelles qui génèrent un nombre excessif de règles d'alerte. Au lieu de s’appuyer sur cette méthode pour chaque machine, consultez Mise à l’échelle des règles d’alerte pour connaître les stratégies d’utilisation d’un nombre minimal de règles d’alerte pour plusieurs machines.
Types d’alertes
Les types de règles d’alerte les plus courants dans Azure Monitor sont les alertes de métriques et les alertes de recherche dans les journaux. Le type de règle d’alerte que vous créez pour un scénario particulier dépend de l’emplacement des données sur lesquelles vous souhaitez générer des alertes.
Dans certains cas, les données d'un scénario d'alerte particulier sont disponibles dans les métriques et les journaux. Le cas échéant, vous devez déterminer le type de règle à utiliser. Vous pouvez également disposer d’une certaine flexibilité dans la façon dont vous recueillez certaines données et laisser votre décision du type de règle d’alerte prendre votre décision en matière de méthode de collecte des données.
Alertes de métrique
Exemples d'utilisation fréquents des alertes de métrique :
- Alerte lorsqu’une métrique particulière dépasse un seuil. C’est le cas, par exemple, lorsque l’UC d’un ordinateur est très longue.
Sources de données des alertes de métrique :
- Les métriques de l'hôte pour les machines virtuelles Azure, qui sont collectées automatiquement.
- Les métriques collectées par l'agent Azure Monitor à partir du système d'exploitation invité.
Alertes de recherche dans les journaux
Exemples d’utilisation fréquents des alertes de recherche dans les journaux :
- Alerte lorsqu'un événement ou un modèle particulier d'événements du journal des événements Windows ou de Syslog sont trouvés. Ces règles d'alerte mesurent généralement les lignes de table retournées par la requête.
- Alerte basée sur un calcul de données numériques sur plusieurs machines. Ces règles d'alerte mesurent généralement le calcul d'une colonne numérique dans les résultats de la requête.
Sources de données pour les alertes de recherche dans les journaux :
- Toutes les données collectées dans un espace de travail Log Analytics.
Mise à l’échelle des règles d’alerte
Étant donné que vous pouvez avoir de nombreuses machines virtuelles qui nécessitent la même surveillance, vous ne souhaitez pas avoir à créer des règles d'alerte individuelles pour chacune d'elles. Vous pouvez également vous assurer qu'il existe différentes stratégies pour limiter le nombre de règles d'alerte à gérer, en fonction du type de règle. Chacune de ces stratégies dépend de la compréhension de la ressource cible de la règle d’alerte.
Règles d’alerte de métrique
Les machines virtuelles prennent en charge plusieurs règles d’alerte de métrique de ressources, comme décrit dans Superviser plusieurs ressources. Cela vous permet de créer une règle d'alerte de métrique unique qui s'applique à toutes les machines virtuelles d'un groupe de ressources ou d'un abonnement dans la même région.
Commencez par les alertes recommandées et créez une règle correspondante pour toutes celles qui utilisent votre abonnement ou un groupe de ressources comme ressource cible. Vous devez créer des règles en double pour chaque région si vous avez des machines dans plusieurs régions.
Lorsque vous identifiez les exigences pour plus de règles d'alerte de métrique, suivez cette même stratégie en utilisant un abonnement ou un groupe de ressources comme ressource cible pour :
- Réduisez le nombre de règles d'alerte que vous devez gérer.
- Assurez-vous qu'elles sont automatiquement appliquées à toutes les nouvelles machines.
Règles d’alerte de recherche dans les journaux
Si vous définissez la ressource cible d’une règle d’alerte de recherche dans les journaux sur un ordinateur spécifique, les requêtes sont limitées aux données associées à cet ordinateur, ce qui vous permet d’obtenir des alertes individuelles pour celui-ci. Cela nécessite une règle d'alerte distincte pour chaque machine.
Si vous définissez la ressource cible d’une règle d’alerte de recherche dans les journaux sur un espace de travail Log Analytics, vous avez accès à toutes les données de cet espace de travail. Pour cette raison, vous pouvez alerter sur les données de toutes les machines du groupe de travail avec une seule règle. Cela vous permet de créer une alerte unique pour toutes les machines. Vous pouvez ensuite utiliser des dimensions pour créer une alerte distincte pour chaque machine.
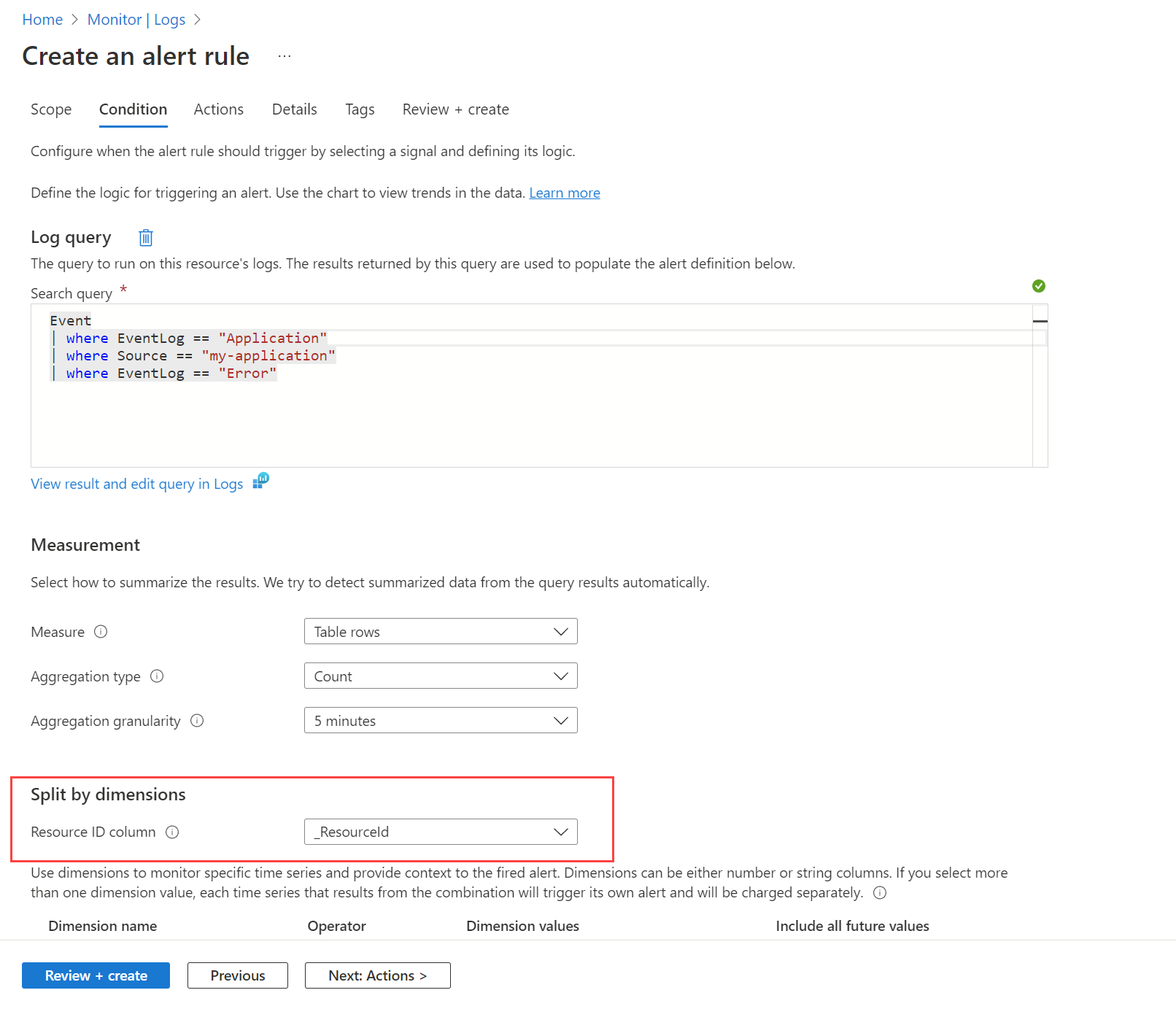
Par exemple, vous pouvez émettre une alerte lorsqu'un événement d'erreur est créé dans le journal des événements Windows par n'importe quelle machine. Vous devez d'abord créer une règle de collecte de données comme décrit dans Collecter des données avec l'agent Azure Monitor pour envoyer ces événements à la table Event dans l'espace de travail Log Analytics. Vous pouvez ensuite créer une règle d'alerte qui interroge cette table à l'aide de l'espace de travail comme ressource cible et de la condition indiquée dans l'image ci-dessous.
La requête retourne un enregistrement pour tous les messages d'erreur sur n'importe quelle machine. Utilisez l’option Fractionner par dimensions et spécifiez _ResourceId pour indiquer à la règle de créer une alerte pour chaque machine si plusieurs machines sont retournées dans les résultats.
Dimensions
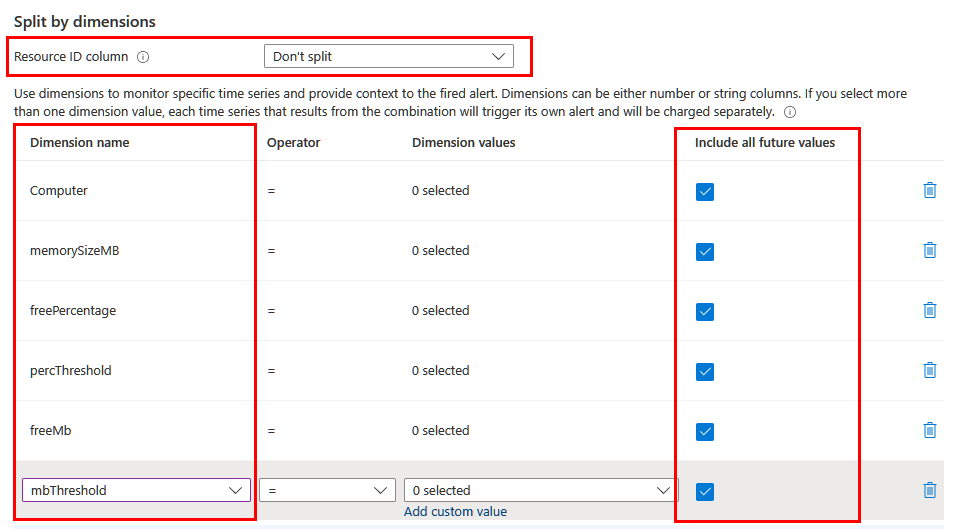
Selon les informations que vous souhaitez inclure dans l'alerte, vous devrez peut-être fractionner à l'aide de différentes dimensions. Dans ce cas, vérifiez que les dimensions nécessaires sont projetées dans la requête à l'aide de l'opérateur de projet ou d'extension. Définissez le champ Colonne ID de la ressource sur Ne pas fractionner et incluez toutes les dimensions significatives dans la liste. Assurez-vous que l'option Inclure toutes les valeurs futures est sélectionnée, afin que toutes les valeurs retournées par la requête soient incluses.
Seuils dynamiques
Un autre avantage de l’utilisation de règles d’alerte pour la recherche dans les journaux est la possibilité d’inclure une logique complexe dans la requête pour déterminer la valeur de seuil. Vous pouvez coder en dur le seuil, l'appliquer à toutes les ressources ou le calculer dynamiquement en fonction d'un champ ou d'une valeur calculée. Le seuil est appliqué aux ressources uniquement en fonction de conditions spécifiques. Par exemple, vous pouvez créer une alerte en fonction de la mémoire disponible, mais uniquement pour les machines avec une quantité particulière de mémoire totale.
Règles d’alerte courantes
La section suivante répertorie les règles d’alerte courantes pour les machines virtuelles dans Azure Monitor. Des détails sur les alertes métriques et les alertes de recherche dans les journaux sont fournis pour chacune d’entre elles. Pour obtenir des conseils sur le type d’alerte à utiliser, consultez Types d’alerte. Si vous n’êtes pas familiarisé avec le processus de création de règles d’alerte dans Azure Monitor, consultez les instructions pour créer une règle d’alerte.
Remarque
Les détails des alertes de recherche dans les journaux fournis ici utilisent les données collectées à l’aide de VM Insights, qui fournit un ensemble de compteurs de performances communs pour le système d’exploitation client. Ce nom est indépendant du type de système d’exploitation.
Disponibilité de la machine
L’une des exigences de surveillance les plus courantes pour une machine virtuelle consiste à créer une alerte si elle cesse de s’exécuter. La meilleure méthode consiste à créer une règle d’alerte de métrique dans Azure Monitor à l’aide de la métrique de disponibilité des machines virtuelles actuellement en préversion publique. Pour connaître la procédure complète de cette métrique, consultez Créer une règle d'alerte de disponibilité pour une machine virtuelle Azure.
Une règle d’alerte est limitée à un signal de journal d’activité. Par conséquent, pour chaque condition, une règle d’alerte doit être créée. Par exemple, « démarre ou arrête la machine virtuelle » nécessite deux règles d’alerte. Toutefois, pour être alerté lorsque la machine virtuelle est redémarrée, une seule règle d’alerte est nécessaire.
Comme décrit dans Mise à l'échelle des règles d'alerte, créez une règle d'alerte de disponibilité à l'aide d'un abonnement ou d'un groupe de ressources comme ressource cible. La règle s'applique à plusieurs machines virtuelles, y compris les nouvelles machines que vous créez après la règle d'alerte.
Pulsation de l'agent
La pulsation de l'agent est légèrement différente de l'alerte d'indisponibilité de la machine, car elle s'appuie sur l'agent Azure Monitor pour envoyer une pulsation. La pulsation de l'agent peut vous alerter si la machine est en cours d'exécution, mais que l'agent ne répond pas.
Règles d’alerte de métrique
Une métrique appelée Heartbeat est incluse dans chaque espace de travail Log Analytics. Chaque ordinateur virtuel connecté à cet espace de travail envoie une valeur de métrique de pulsation chaque minute. Étant donné que l’ordinateur est une dimension de la mesure, vous pouvez déclencher une alerte quand un ordinateur ne parvient pas à envoyer une pulsation. Définissez le type d'agrégation sur Compte et la valeur de Seuil pour correspondre à la granularité de l'évaluation.
Règles d’alerte de recherche dans les journaux
Les alertes de recherche dans les journaux utilisent la table Heartbeat (Pulsation), qui doit contenir un enregistrement de pulsations toutes les minutes pour chaque machine.
Utilisez une règle avec la requête suivante.
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
Alertes de l’UC
Cette section décrit les alertes du processeur.
Règles d’alerte de métrique
| Cible | Métrique |
|---|---|
| Hôte | Pourcentage d’UC (inclus dans les alertes recommandées) |
| Invité Windows | \Processor Information(_Total)% Processor Time |
| Invité Linux | cpu/usage_active |
Règles d’alerte de recherche dans les journaux
Utilisation du processeur
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Alertes de mémoire
Cette section décrit les alertes de mémoire.
Règles d’alerte de métrique
| Cible | Métrique |
|---|---|
| Hôte | Octets de mémoire disponibles (préversion) (inclus dans les alertes recommandées) |
| Invité Windows | \Memory% Committed Bytes in Use \Memory\Octets disponibles |
| Invité Linux | mem/disponible mem/available_percent |
Règles d’alerte de recherche dans les journaux
Remarque
Si vous devez spécifier l’alerte sur un disque, vous pouvez l’ajouter à la requête : | where parse_json(Tags).["vm.azm.ms/mountId"] == "C:"Mémoire disponible en Mo
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Mémoire disponible en pourcentage
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
Alertes du disque
Cette section décrit les alertes de disque.
Règles d’alerte de métrique
| Cible | Métrique |
|---|---|
| Invité Windows | \Logical Disk(_Total)% Espace libre \Logical Disk(_Total)\Mégaoctets libres |
| Invité Linux | disque/gratuit disque/free_percent |
Règles d’alerte de recherche dans les journaux
Disque logique utilisé : tous les disques sur chaque ordinateur
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Disque logique utilisé : disques individuels
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
IOPS des disques logiques
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Débit de données du disque logique
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Alertes réseau
Règles d’alerte de métrique
| Cible | Métrique |
|---|---|
| Hôte | Network In Total, Network Out Total (inclus dans les alertes recommandées) |
| Invité Windows | \N- Interface réseau \N- Octets envoyés par seconde \Logical Disk(_Total)\Mégaoctets libres |
| Invité Linux | disque/gratuit disque/free_percent |
Règles d’alerte de recherche dans les journaux
Octets reçus sur les interfaces réseau : toutes les interfaces
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Octets reçus sur les interfaces réseau : interfaces individuelles
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Octets envoyés sur les interfaces réseau : toutes les interfaces
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Octets envoyés sur les interfaces réseau : interfaces individuelles
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Événements Windows et Linux
L’exemple suivant crée une alerte lorsqu’un événement Windows spécifique est créé. Il utilise une règle d’alerte de mesure de métrique pour créer une alerte distincte pour chaque ordinateur.
Créez une règle d’alerte sur un événement Windows spécifique. Cet exemple montre un événement dans le journal des applications. Spécifiez un seuil de 0 et un nombre de violations consécutives supérieur à 0.
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)Créez une règle d’alerte sur les événements Syslog présentant une gravité particulière. L’exemple suivant montre des événements d’autorisation ayant rencontré une erreur. Spécifiez un seuil de 0 et un nombre de violations consécutives supérieur à 0.
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
Compteurs de performances personnalisés
Créez une alerte sur la valeur maximale d’un compteur.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by ComputerCréez une alerte sur la valeur moyenne d’un compteur.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer
Étapes suivantes
Analyser les données de surveillance collectées pour les machines virtuelles