Création de rapports sur des bases de données cloud mises à l’échelle (version préliminaire)
S’applique à : ![]() Azure SQL Database
Azure SQL Database
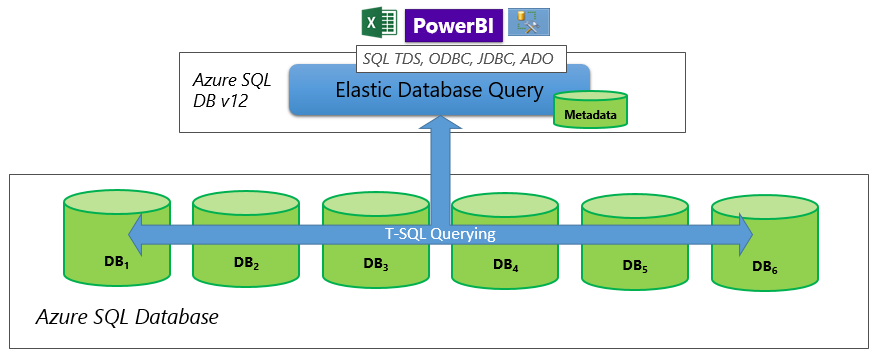
Les bases de données partitionnées répartissent des lignes sur une mise à l’échelle vers la couche données. Le schéma est identique sur toutes les bases de données participantes, également connu sous le terme partitionnement horizontal. En utilisant une requête élastique, vous pouvez créer des rapports qui couvrent toutes les bases de données d’une base de données partitionnée.
Pour un démarrage rapide, consultez Créer des rapports sur des bases de données cloud avec scale-out.
Pour les bases de données non partitionnées, consultez Interroger plusieurs bases de données cloud avec différents schémas.
Prérequis
- Créez une carte de partitions à l’aide d’une bibliothèque de base de données élastique cliente. Consultez la rubrique Gestion des cartes de partitions. Ou utilisez l’exemple d’application de la rubrique Prise en main des outils de base de données élastiques.
- Vous pouvez également consulter la rubrique Migrer des bases de données existantes vers des bases de données mises à l’échelle.
- L’utilisateur doit posséder l’autorisation ALTER ANY EXTERNAL DATA SOURCE. Cette autorisation est incluse dans l’autorisation ALTER DATABASE.
- Les autorisations ALTER ANY EXTERNAL DATA SOURCE sont nécessaires pour faire référence à la source de données sous-jacente.
Vue d’ensemble
Ces instructions créent une représentation des métadonnées de votre couche de données partitionnées dans la base de données de requête élastique.
- CREATE MASTER KEY
- CREATE DATABASE SCOPED CREDENTIAL
- CREATE EXTERNAL DATA SOURCE
- CREATE EXTERNAL TABLE
1.1 Créer la clé principale et les informations d’identification de la base de données
Les informations d'identification sont utilisées par la requête élastique pour se connecter à vos bases de données distantes.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
CREATE DATABASE SCOPED CREDENTIAL [<credential_name>] WITH IDENTITY = '<username>',
SECRET = '<password>';
Notes
Vérifiez que "<username>" ne contient pas le suffixe "@servername".
1.2 Créer des sources de données externes
Syntaxe :
<External_Data_Source> ::=
CREATE EXTERNAL DATA SOURCE <data_source_name> WITH
(TYPE = SHARD_MAP_MANAGER,
LOCATION = '<fully_qualified_server_name>',
DATABASE_NAME = '<shardmap_database_name>',
CREDENTIAL = <credential_name>,
SHARD_MAP_NAME = '<shardmapname>'
) [;]
Exemple
CREATE EXTERNAL DATA SOURCE MyExtSrc
WITH
(
TYPE=SHARD_MAP_MANAGER,
LOCATION='myserver.database.windows.net',
DATABASE_NAME='ShardMapDatabase',
CREDENTIAL= SMMUser,
SHARD_MAP_NAME='ShardMap'
);
Récupérez la liste des sources de données externes actuelles :
select * from sys.external_data_sources;
La source de données externe fait référence au mappage de partitions. Une requête élastique utilise ensuite la source de données externe et le mappage de la partition sous-jacents pour énumérer les bases de données qui interviennent dans les couches de données. Les mêmes informations d’identification sont utilisées pour lire la carte de partitions et accéder aux données présentes sur les partitions pendant le traitement d’une requête élastique.
1.3 Créer des tables externes
Syntaxe :
CREATE EXTERNAL TABLE [ database_name . [ schema_name ] . | schema_name. ] table_name
( { <column_definition> } [ ,...n ])
{ WITH ( <sharded_external_table_options> ) }
) [;]
<sharded_external_table_options> ::=
DATA_SOURCE = <External_Data_Source>,
[ SCHEMA_NAME = N'nonescaped_schema_name',]
[ OBJECT_NAME = N'nonescaped_object_name',]
DISTRIBUTION = SHARDED(<sharding_column_name>) | REPLICATED |ROUND_ROBIN
Exemple
CREATE EXTERNAL TABLE [dbo].[order_line](
[ol_o_id] int NOT NULL,
[ol_d_id] tinyint NOT NULL,
[ol_w_id] int NOT NULL,
[ol_number] tinyint NOT NULL,
[ol_i_id] int NOT NULL,
[ol_delivery_d] datetime NOT NULL,
[ol_amount] smallmoney NOT NULL,
[ol_supply_w_id] int NOT NULL,
[ol_quantity] smallint NOT NULL,
[ol_dist_info] char(24) NOT NULL
)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'orders',
OBJECT_NAME = 'order_details',
DISTRIBUTION=SHARDED(ol_w_id)
);
Récupérer la liste des tables externes à partir de la base de données en cours :
SELECT * from sys.external_tables;
Pour supprimer des bases de données externes :
DROP EXTERNAL TABLE [ database_name . [ schema_name ] . | schema_name. ] table_name[;]
Notes
La clause DATA_SOURCE définit la source de données externe (une carte de partitions) utilisée pour la table externe.
Les clauses SCHEMA_NAME et OBJECT_NAME mappent la définition de table externe à une table dans un schéma différent. S’il n’est pas spécifié, le schéma de l’objet distant est considéré comme étant dbo et son nom est censé être identique au nom de la table externe en cours de définition. Ceci est particulièrement utile si le nom de votre table distante est déjà utilisé dans la base de données dans laquelle vous souhaitez créer la table externe. Par exemple, vous souhaitez définir une table externe pour obtenir une vue agrégée des affichages de catalogue ou de vues de gestion dynamiques sur la couche des données mise à l’échelle. Dans la mesure où les affichages catalogue et les vues de gestion dynamique existent déjà localement, vous ne pouvez pas utiliser leur nom pour la définition de la table externe. Vous devez utiliser un autre nom ainsi que le nom de la vue de catalogue ou de la vue de gestion dynamique dans les clauses SCHEMA_NAME et/ou OBJECT_NAME. (Voir l’exemple ci-dessous.)
La clause DISTRIBUTION spécifie la distribution des données utilisée pour cette table. Le processeur de requêtes utilise les informations fournies dans la clause DISTRIBUTION pour créer les plans de requête les plus efficaces.
- SHARDED signifie que les données sont partitionnées horizontalement entre les bases de données. La clé de partitionnement pour la distribution des données figure dans le paramètre <nom_colonne_partitionnement>.
- REPLICATED signifie que des copies identiques de la table sont présentes sur chaque base de données. La responsabilité de vous assurer que les réplicas sont identiques d’une base de données à l’autre vous incombe.
- ROUND_ROBIN signifie que la table est partitionnée horizontalement à l’aide d’une méthode de distribution liée à l’application.
Référence de la couche Données : le DDL de table externe fait référence à une source de données externe. La source de données externe spécifie une carte de partitions qui fournit à la table externe les informations nécessaires à la localisation de toutes les bases de données de votre couche de données.
Considérations relatives à la sécurité
Les utilisateurs ayant accès à la table externe acquièrent un accès automatique aux tables distantes sous-jacentes avec les informations d’identification fournies dans la définition de source de données externe. Évitez une élévation de privilèges non souhaitée par le biais d’informations d'identification de la source de données externe. Utilisez GRANT ou REVOKE pour une table externe, comme s’il s’agissait d’une table standard.
Une fois votre table externe et votre source de données externe définies, vous pouvez utiliser l’ensemble T-SQL complet sur vos tables externes.
Exemple : interrogation de bases de données partitionnées horizontales
La requête suivante effectue une jonction tridirectionnelle entre les entrepôts, les commandes et les lignes de commande, et utilise plusieurs agrégats et un filtre sélectif. Elle suppose (1) un partitionnement horizontal (sharding) et (2) que les entrepôts, les commandes et lignes de commande sont partitionnées par la colonne d’ID de l’entrepôt et que la requête élastique peut placer des jointures sur les partitions et traiter la partie coûteuse de la requête sur les partitions en parallèle.
select
w_id as warehouse,
o_c_id as customer,
count(*) as cnt_orderline,
max(ol_quantity) as max_quantity,
avg(ol_amount) as avg_amount,
min(ol_delivery_d) as min_deliv_date
from warehouse
join orders
on w_id = o_w_id
join order_line
on o_id = ol_o_id and o_w_id = ol_w_id
where w_id > 100 and w_id < 200
group by w_id, o_c_id
Procédure stockée pour l’exécution de T-SQL à distance : sp_execute_remote
La requête élastique introduit également une procédure stockée qui offre un accès direct aux partitions. La procédure stockée est appelée sp_execute_remote et peut être utilisée pour exécuter le code T-SQL ou les procédures stockées distantes sur des bases de données distantes. Les paramètres suivants sont pris en compte :
- Nom de la source de données (nvarchar) : nom de la source de données externe de type SGBDR.
- Requête (nvarchar) : requête T-SQL à exécuter sur chaque partition.
- Déclaration de paramètre (nvarchar) - facultatif : chaîne contenant des définitions de type de données pour les paramètres utilisés dans le paramètre de requête (comme sp_executesql).
- Liste de valeurs de paramètre - facultatif : liste de valeurs de paramètre séparées par des virgules (comme sp_executesql).
sp_execute_remote utilise la source de données externe fournie dans les paramètres d’appel pour exécuter l’instruction T-SQL donnée sur toutes les bases de données distantes. Il utilise les informations d’identification de la source de données externe pour se connecter à la base de données shardmap et aux bases de données distantes.
Exemple :
EXEC sp_execute_remote
N'MyExtSrc',
N'select count(w_id) as foo from warehouse'
Connectivité des outils
Utilisez des chaînes de connexion SQL Server standard pour connecter votre application, votre décisionnel et vos outils d’intégration des données à la base de données avec vos définitions de table externe. Assurez-vous que SQL Server est pris en charge comme source de données pour votre outil. Référencez la base de données de requête élastique comme n’importe quelle autre base de données SQL Server connectée à l’outil et utilisez des tables externes à partir de votre outil ou votre application comme s’il s’agissait de tables locales.
Meilleures pratiques
- Vérifiez que la base de données du point de terminaison de requête élastique est autorisée à accéder à la base de données de carte de partitions et à toutes les partitions via les pare-feu de base de données SQL.
- Validez ou appliquez la distribution de données définie par la table externe. Si la distribution réelle des données est différente de la distribution spécifiée dans la définition de votre table, vos requêtes peuvent donner des résultats inattendus.
- La requête élastique n’effectue pas d’élimination de partition lorsque les prédicats de clé de partitionnement permettent d’exclure en toute sécurité certaines partitions du traitement.
- Une requête élastique est mieux adaptée aux requêtes dont la plus grande partie du calcul peut être effectuée sur les partitions. De manière générale, vous obtenez les meilleures performances de requête avec des prédicats de filtres sélectifs pouvant être évalués sur des partitions ou des jonctions via les clés de partitionnement qui peuvent être effectuées de manière alignée sur toutes les partitions. D’autres modèles de requête peuvent nécessiter le chargement de grandes quantités de données dans le nœud principal, à partir des partitions, ce qui peut nuire aux performances.
Étapes suivantes
- Pour une présentation des requêtes élastiques, consultez Présentation des requêtes élastiques.
- Pour le didacticiel sur le partitionnement vertical, consultez Prise en main des requêtes de bases de données croisées (partitionnement vertical).
- Pour la syntaxe et des exemples de requêtes pour des données partitionnées verticalement, consultez Requêtes sur des données partitionnées verticalement
- Pour commencer le didacticiel sur le partitionnement horizontal (sharding), consultez Prise en main des requêtes élastiques pour le partitionnement horizontal (sharding).
- Consultez sp_execute _remote pour une procédure stockée qui exécute une instruction Transact-SQL sur une seule base de données Azure SQL distante ou un ensemble de bases de données servant de partitions dans un schéma de partitionnement horizontal.