Vue d’ensemble des pools élastiques Hyperscale dans Azure SQL Database
S’applique à : ![]() Azure SQL Database
Azure SQL Database
Cet article fournit une vue d’ensemble des pools élastiques Hyperscale dans Azure SQL Database.
Un pool élastique Azure SQL Database permet aux développeurs software as a service (SaaS) d’optimiser le rendement pour un groupe de bases de données respectant un budget prévu tout en offrant une élasticité des performances pour chaque base de données. Les pools élastiques Azure SQL Database Hyperscale introduisent un modèle de ressources partagées pour les bases de données Hyperscale.
Pour obtenir des exemples de création, de mise à l’échelle ou de déplacement de bases de données dans un pool élastique Hyperscale à l’aide d’Azure CLI ou de PowerShell, consultez Utilisation de pools élastiques Hyperscale à l’aide d’outils en ligne de commande
Notes
Les pools élastiques pour Hyperscale sont actuellement en préversion.
Vue d’ensemble
Déployez votre base de données Hyperscale dans un pool élastique pour partager des ressources entre des bases de données au sein du pool et optimiser le coût d’avoir plusieurs bases de données avec différents modèles d’utilisation.
Scénarios d’utilisation d’un pool élastique avec vos bases de données Hyperscale :
- Lorsque vous devez mettre à l’échelle les ressources de calcul allouées au pool élastique vers le haut ou vers le bas dans un laps de temps prévisible, indépendamment de la quantité de stockage alloué.
- Lorsque vous souhaitez effectuer un scale-out des ressources de calcul allouées au pool élastique en ajoutant un ou plusieurs réplicas de mise à l’échelle en lecture.
- Si vous souhaitez utiliser un débit de journal des transactions élevé pour les charges de travail gourmandes en écriture, même avec des ressources de calcul inférieures.
L’ajout de bases de données non Hyperscale à un pool élastique Hyperscale convertit les bases de données vers le niveau de service Hyperscale.
Architecture
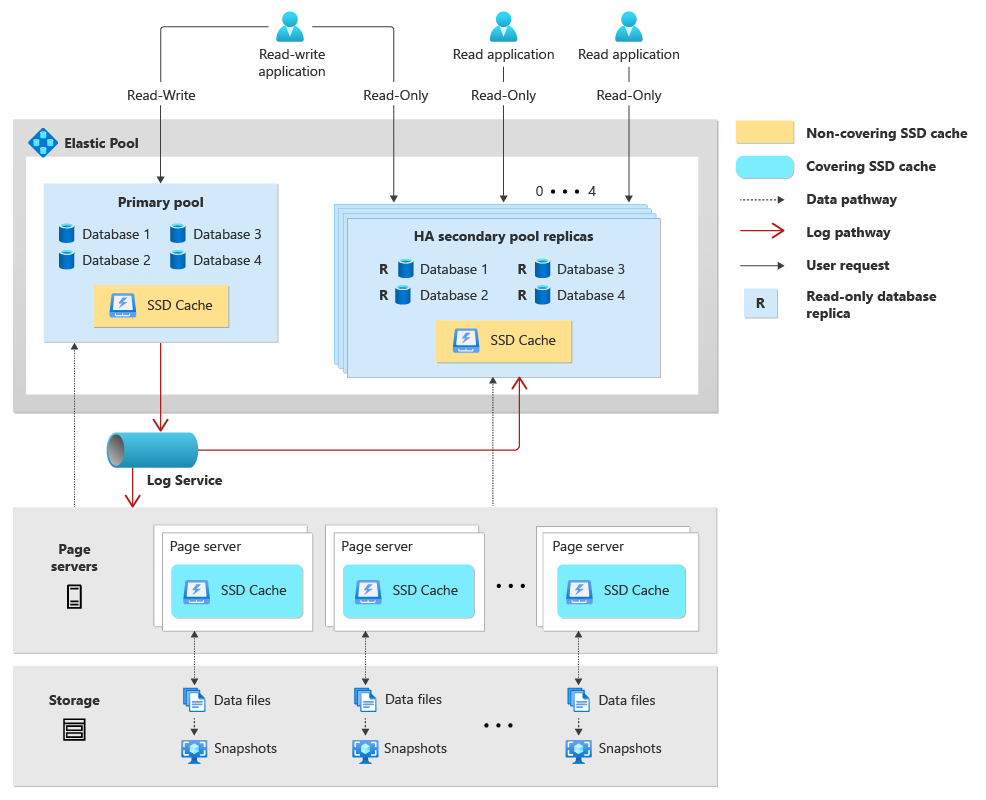
Traditionnellement, l’architecture d’une base de données Hyperscale autonome se compose de trois composants principaux indépendants : calcul, stockage (« serveurs de pages ») et journal (« service de journal »). Lorsque vous créez un pool élastique pour vos bases de données Hyperscale, les bases de données du pool partagent les ressources de calcul et de journalisation. En outre, si vous choisissez de configurer la haute disponibilité, chaque pool de haute disponibilité est créé avec un ensemble équivalent et indépendant de ressources de calcul et de journalisation.
Voici une description de l’architecture d’un pool élastique pour les bases de données Hyperscale :
- Un pool élastique Hyperscale se compose d’un pool principal qui héberge les bases de données Hyperscale primaires et, le cas échéant, jusqu’à quatre pools de haute disponibilité supplémentaires.
- Les bases de données Hyperscale principales hébergées dans le pool élastique principal partagent le processus de calcul du moteur de base de données SQL Server (sqlservr.exe), les vCores, la mémoire et le cache SSD.
- La configuration de la haute disponibilité pour le pool principal crée des pools de haute disponibilité supplémentaires qui contiennent des réplicas de base de données en lecture seule pour les bases de données du pool principal. Chaque pool principal peut avoir un maximum de quatre pools de réplicas haute disponibilité. Chaque pool de haute disponibilité partage des ressources de calcul, de cache SSD et de mémoire pour toutes les bases de données secondaires en lecture seule du pool.
- Les bases de données Hyperscale du pool élastique principal partagent toutes le même service de journalisation. Étant donné que les bases de données des pools à haute disponibilité n’ont pas de charge de travail en écriture, elles n’utilisent pas le service de journal.
- Chaque base de données Hyperscale possède son propre ensemble de serveurs de pages, et ces serveurs de pages sont partagés entre la base de données primaire du pool principal et toutes les bases de données réplica secondaires du pool à haute disponibilité.
- Les bases de données Hyperscale secondaires géorépliquées peuvent être placées dans un autre pool élastique.
- Spécifier
ApplicationIntent=ReadOnlydans votre chaîne de connexion de base de données vous achemine vers une base de données réplica en lecture seule dans l’un des pools à haute disponibilité.
Le diagramme suivant montre l’architecture d’un pool élastique pour les bases de données Hyperscale :
Gérer les bases de données de pool élastique Hyperscale
Vous pouvez utiliser les mêmes commandes pour gérer vos bases de données mises en pool Hyperscale que les bases de données mises en pool dans les autres niveaux de service. Veillez simplement à spécifier Hyperscale pour l’édition lors de la création de votre pool élastique Hyperscale.
La seule différence est la possibilité de modifier le nombre de réplicas haute disponibilité (H/A) pour un pool élastique Hyperscale existant. Pour ce faire :
- Utilisez le paramètre
HighAvailabilityReplicaCountde la commande Azure PowerShell Set-AzSqlElasticPool. - Utilisez le paramètre
--ha-replicasde la commande Azure CLI az sql elastic-pool update.
Vous pouvez utiliser les outils clients suivants pour gérer vos bases de données Hyperscale dans un pool élastique :
- Azure PowerShell : Az.Sql.3.11.0 ou version ultérieure. PowerShell AzureRM.Sql n’est pas pris en charge.
- Azure CLI : Az 2.40.0 ou version ultérieure.
- Transact-SQL (T-SQL) à compter de : SQL Server Management Studio (SSMS) v18.12.1 ou Azure Data Studio v1.39.1.
Convertir des bases de données non Hyperscale vers des pools élastiques Hyperscale
Lors de la conversion d’une base de données vers Hyperscale, vous pouvez ajouter la base de données à un pool élastique Hyperscale existant. Pour ces conversions, le pool élastique Hyperscale doit exister sur le même serveur logique que la base de données source.
Lorsque vous convertissez des bases de données vers des pools élastiques Hyperscale, tenez compte du nombre maximum de bases de données par pool élastique Hyperscale.
Convertir des bases de données non Hyperscale vers des pools élastiques Hyperscale à l’aide de T-SQL
Vous pouvez utiliser des commandes T-SQL pour convertir plusieurs bases de données à usage général et les ajouter à un pool élastique Hyperscale existant nommé hsep1 :
ALTER DATABASE gpepdb1 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb2 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb3 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb4 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
Dans cet exemple, vous demandez implicitement une conversion de l’usage général vers Hyperscale, en spécifiant que la cible SERVICE_OBJECTIVE est un pool élastique Hyperscale. Chacune des commandes ci-dessus lance la conversion de la base de données à usage général concernée vers Hyperscale. Ces commandes ALTER DATABASE retournent rapidement et n’attendent pas la fin de la conversion. Dans l’exemple présenté, quatre conversions de ce type, de l’usage général vers Hyperscale, s’exécutent en parallèle.
Vous pouvez interroger la vue de gestion dynamique sys.dm_operation_status pour surveiller l’état de ces opérations de conversion en arrière-plan.
Convertir des bases de données non Hyperscale vers des pools élastiques Hyperscale à l’aide de PowerShell
Vous pouvez utiliser des commandes PowerShell pour convertir plusieurs bases de données à usage général et les ajouter à un pool élastique Hyperscale existant nommé hsep1. Par exemple, l'exemple de script suivant exécute ces étapes :
- Utilisez le cmdlet Get-AzSqlElasticPoolDatabase pour répertorier toutes les bases de données du pool élastique usage général nommé
gpep1. - Le cmdlet
Where-Objectfiltre la liste uniquement sur ces noms de base de données commençant pargpepdb. - Pour chaque base de données, le cmdlet Set-AzSqlDatabase démarre une conversion. Dans ce cas, vous demandez implicitement une conversion vers le niveau de service Hyperscale en spécifiant le pool élastique Hyperscale cible nommé
hsep1.- Le paramètre
-AsJobpermet à chacune des requêtesSet-AzSqlDatabasede s’exécuter en parallèle. Si vous préférez exécuter les conversions une par une, vous pouvez supprimer le paramètre-AsJob.
- Le paramètre
$dbs = Get-AzSqlElasticPoolDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -ElasticPoolName "gpep1"
$dbs | Where-Object { $_.DatabaseName -like "gpepdb*" } | % { Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -DatabaseName ($_.DatabaseName) -ElasticPoolName "hsep1" -AsJob }
Outre la vue de gestion dynamique sys.dm_operation_status, vous pouvez utiliser la cmdlet PowerShell Get-AzSqlDatabaseActivity pour surveiller l’état de ces opérations de conversion en arrière-plan.
Limites des ressources
Voici les limites prises en charge pour l’utilisation des bases de données Hyperscale dans des pools élastiques :
- Génération de matériel prise en charge : mémoire optimisée de séries standard (Gen5) et Premium.
- vCore maximum par pool : 80 ou 128 vCores, selon l'objectif de niveau de service.
- Taille maximale des données prises en charge par base de données : 100 To.
- Taille totale maximale des données prises en charge pour l’ensemble des bases de données du pool : 100 To.
- Débit maximal du journal des transactions pris en charge par base de données : 100 Mo.
- Débit total maximal pris en charge pour le journal des transactions sur l'ensemble des bases de données du pool : 131,25 Mo/seconde.
- Chaque pool élastique Hyperscale peut avoir jusqu’à 25 bases de données.
Pour en savoir plus, reportez-vous aux limites de ressources des pools élastiques Hyperscale pour la mémoire optimisée de séries Standard et Premium.
Remarque
Les profils de performances, les fonctionnalités prises en charge et les limites publiées sont susceptibles d’être modifiés pendant que la fonctionnalité est en préversion. Par conséquent, il est préférable de valider votre cas d’usage avec des tests fonctionnels, de performances et de mise à l’échelle réguliers des charges de travail.
Limitations
Tenez compte des limitations suivantes :
- La modification d’un pool élastique non Hyperscale existant par l’édition Hyperscale n’est pas prise en charge. La section conversion fournit des alternatives que vous pouvez utiliser.
- La modification de l’édition d’un pool élastique Hyperscale en une édition non Hyperscale n’est pas prise en charge.
- Pour « inverser la migration » d’une base de données éligible qui se trouve dans un pool élastique Hyperscale, il faut d’abord la supprimer du pool élastique Hyperscale. La base de données Hyperscale autonome peut ensuite être « migrée de manière inversée » vers une base de données autonome à usage général.
- Pour le niveau de service Hyperscale, la prise en charge de la redondance de zone ne peut être spécifiée que lors de la création d’une base de données ou d’un pool élastique et ne peut pas être modifiée une fois la ressource approvisionnée. Pour plus d’informations, consultez l’article Migrer la base de données Azure SQL vers le support des zones de disponibilité.
- L’ajout d’un réplica nommé à l’intérieur d’un pool élastique Hyperscale n’est pas pris en charge. Toute tentative d’ajout d’un réplica nommé d’une base de données Hyperscale à un pool élastique Hyperscale génère une erreur
UnsupportedReplicationOperation. À la place, créez le réplica nommé en tant que base de données Hyperscale unique.
Considérations relatives aux pools élastiques redondants interzone
Voici quelques considérations relatives aux pools élastiques Hyperscale redondants interzone :
Remarque
Des pools élastiques hyperscale avec redondance de zone sont disponibles, actuellement en préversion. Pour plus d’informations, consultez le billet de blog : pools élastiques Hyperscale redondants interzone.
- Seules les bases de données avec redondance de stockage redondant interzone (ZRS ou GZRS) peuvent être ajoutées aux pools élastiques Hyperscale avec redondance de zone.
- Une base de données Hyperscale autonome doit être créée avec une redondance de zone et un stockage de sauvegarde redondant interzone (ZRS ou GZRS) afin de l’ajouter à un pool élastique Hyperscale redondant interzone. Pour les bases de données Hyperscale sans redondance de zone, effectuez un transfert de données vers une nouvelle base de données Hyperscale avec l’option de redondance de zone activée. Un clone doit être créé à l’aide d’une copie de base de données, d’un limite de restauration dans le temps ou d’un géoréplica. Pour plus d’informations, consultez Redéploiement (Hyperscale).
- Pour déplacer une base de données Hyperscale d’un pool élastique vers un autre, les paramètres de stockage de sauvegarde redondant interzone doivent correspondre.
- Pour convertir une base de données d’un autre niveau de service non Hyperscale vers un pool élastique Hyperscale avec redondance de zone :
- Via le Portail Azure, activez d’abord la redondance de zone et le stockage de sauvegarde redondant interzone (ZRS). Ensuite, vous pouvez ajouter la base de données au pool élastique Hyperscale redondant interzone.
- Via PowerShell, activez d’abord la redondance de zone. Ensuite, avec Set-AzSqlDatabase, vérifiez que le paramètre
-BackupStorageRedundancyest utilisé pour spécifier le stockage de sauvegarde redondant interzone (ZRS ou GZRS).
Problèmes connus
| Problème | Recommandation |
|---|---|
Lors de l’ajout de nombreuses bases de données non Hyperscale à un pool élastique Hyperscale, vous pouvez recevoir une erreur Could not perform the operation because server would exceed the allowed Database Throughput Unit quota of 54000. (Code: ServerDtuQuotaExceeded). Bien que le message fasse référence aux Database Throughput Units (DTU), il est lié au quota partagé DTU/vCore appliqué à chaque serveur logique. Ce problème est dû à une erreur de calcul des vCores au niveau de chaque base de données. |
Voici quelques options pour résoudre ce problème : • Ajoutez les bases de données une par une au pool élastique Hyperscale. • Convertissez la base de données vers une base de données Hyperscale autonome avant de l’ajouter au pool élastique Hyperscale. • Demandez une augmentation du quota au niveau du serveur comme décrit ici. |
La configuration de la géoréplication d’une base de données à partir d’un pool élastique Hyperscale redondant interzone vers un pool élastique Hyperscale non redondant interzone dans une autre région échoue avec l’erreur Provisioning of zone redundant Hyperscale database with local backup redundancy is not supported. Zone redundant Hyperscale databases must use either zone or geo zone backup redundancy. Cette erreur ne se produit pas si le deuxième pool élastique Hyperscale est redondant interzone ou se trouve dans la même région. |
Pour résoudre ce problème, vous pouvez utiliser Azure PowerShell et spécifier explicitement la non redondance de zone dans la ligne de commande New-AzSqlDatabaseSecondary -ResourceGroupName "primary-rg" -ServerName "primary-server" -DatabaseName "hsdb1" -PartnerResourceGroupName "secondary-rg" -PartnerServerName "secondary-server" -AllowConnections "All" -SecondaryElasticPoolName "secondary-nonzr-pool" -BackupStorageRedundancy Local -ZoneRedundant:$false |
| L’ajout d’une base de données à partir d’un pool élastique Hyperscale redondant interzone à un groupe de basculement avec un pool élastique Hyperscale non redondant interzone dans une autre région échouera en interne, mais l’opération peut sembler s’exécuter sans aucun progrès. Vous pouvez voir la base de données géosecondaire lorsque vous utilisez des outils tels que SSMS, mais vous ne pouvez pas vous connecter à la base de données géosecondaire ni l’utiliser. Le groupe de basculement peut afficher un état « Attribution de cote 0 % » pour la base de données géosecondaire. Ce problème ne se produit pas si le deuxième pool élastique Hyperscale est redondant interzone. | Pour résoudre ce problème, configurez la géoréplication en dehors du groupe de basculement à l’aide d’Azure PowerShell, en spécifiant explicitement la non redondance de zone dans la ligne de commande New-AzSqlDatabaseSecondary -ResourceGroupName "primary-rg" -ServerName "primary-server" -DatabaseName "hsdb1" -PartnerResourceGroupName "secondary-rg" -PartnerServerName "secondary-server" -AllowConnections "All" -SecondaryElasticPoolName "secondary-nonzr-pool" -BackupStorageRedundancy Local -ZoneRedundant:$false. Vous pouvez ensuite ajouter la base de données au groupe de basculement. |
Dans de rares cas, vous pouvez obtenir l’erreur 45122 - This Hyperscale database cannot be added into an elastic pool at this time. In case of any questions, please contact Microsoft support lors de la tentative de déplacement, de restauration ou de copie d’une base de données Hyperscale dans un pool élastique. |
Cette limitation est due à des détails spécifiques à l’implémentation. Si cette erreur vous bloque, déclenchez un incident de support et demandez de l’aide. |
Contenu connexe
- Utilisation de pools élastiques Hyperscale à l’aide d’outils en ligne de commande
- Tarification du pool élastique
- Mettre à l’échelle un pool élastique dans Azure SQL Database
- Utiliser PowerShell pour surveiller et mettre à l’échelle un pool élastique dans Azure SQL Database
- Modèles de client de base de données SaaS multilocataires
- Présentation d’une application SaaS mutualisée qui utilise le modèle de base de données par locataire avec Azure SQL Database
- Gestion des ressources dans les pools élastiques denses
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour