Création de rapports inter-clients à l’aide de requêtes distribuées
S’applique à : ![]() Azure SQL Database
Azure SQL Database
Dans ce didacticiel, vous allez exécuter des requêtes distribuées sur l’ensemble des bases de données clientes pour la création de rapports. Ces requêtes peuvent extraire des analyses enfouies dans des données opérationnelles quotidiennes des clients SaaS Wingtip Tickets. Pour cela, déployez une base de données de création de rapports supplémentaire sur le serveur de catalogue et utilisez une demande élastique pour activer les requêtes distribuées.
Ce didacticiel vous apprend à effectuer les opérations suivantes :
- Comment déployer une base de données de création de rapports
- Exécuter des requêtes distribuées sur toutes les bases de données client
- Comment des vues globales de chaque base de données peuvent permettre des requêtes efficaces sur l’ensemble des clients
Pour suivre ce didacticiel, vérifiez que les prérequis suivants sont remplis :
- L’application de base de données Wingtip Tickets SaaS par client est déployée. Pour procéder à un déploiement en moins de cinq minutes, consultez la page Déployer et explorer l’application de base de données Wingtip Tickets SaaS par client
- Azure PowerShell est installé. Pour plus d’informations, voir Bien démarrer avec Azure PowerShell.
- SQL Server Management Studio (SSMS) est installé. Pour télécharger et installer SSMS, consultez la rubrique Téléchargement de SQL Server Management Studio (SSMS).
Modèle de création de rapports inter-clients
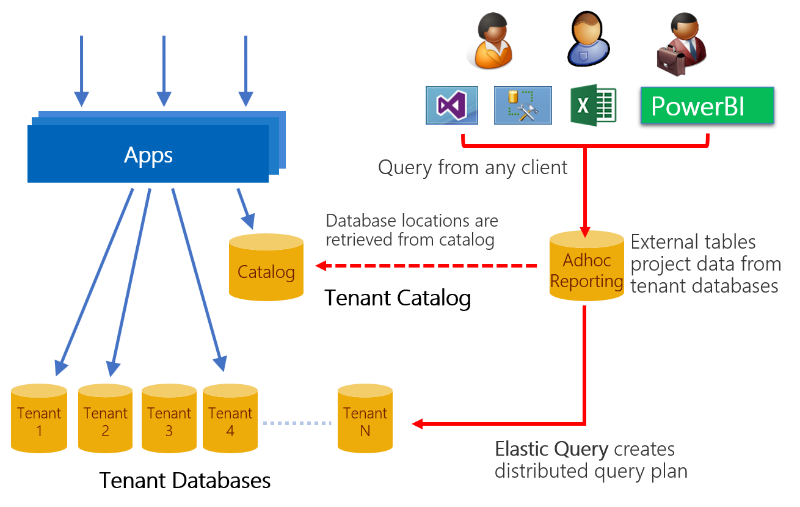
Une des grandes opportunités offertes par les applications SaaS est l’utilisation d’une vaste quantité de données client stockées dans le cloud pour obtenir des analyses du fonctionnement et de l’utilisation de votre application. Ces analyses peuvent guider le développement des fonctionnalités, les améliorations de convivialité et les autres investissements dans vos applications et services.
L’accès à ces données dans une base de données mutualisée est facile, mais pas si simple lors d’une distribution à grande échelle sur des milliers de bases de données. Une approche consiste à utiliser une requête élastique, permettant d’interroger un ensemble distribué de bases de données avec un schéma commun. Ces bases de données peuvent être distribuées sur différents abonnements et groupes de ressources, mais doivent partager la même connexion. Les requêtes élastiques utilisent une seule base de données principale dans laquelle sont définies des tables externes qui reflètent les tables ou les vues dans les bases de données distribuées (client). Les requêtes envoyées à cette base de données principale sont compilées pour produire un plan de requête distribué, avec des parties de la requête transmises aux bases de données client en fonction des besoins. Les requêtes élastiques utilisent la carte de partitions dans la base de données de catalogue pour déterminer l’emplacement de toutes les bases de données client. La configuration et les requêtes de la base de données de tête sont simples grâce à l’utilisation de Transact-SQL standard et les requêtes de support à partir des outils tels que Power BI et Excel.
En distribuant les requêtes sur toutes les bases de données client, les requêtes élastiques permettent d’obtenir immédiatement des informations pour les transformer en données de production actives. Étant donné qu’une demande élastique peut extraire des données provenant potentiellement de nombreuses bases de données, la latence de requête peut être supérieure à celle observée pour des requêtes équivalentes soumises à une seule base de données mutualisée. Concevez des requêtes qui permettent de réduire le nombre de données renvoyées à la base de données de tête. Une requête élastique est souvent plus adaptée lorsqu’il s’agit d’interroger de petites quantités de données en temps réel. En revanche, ce n’est pas le cas pour la construction de requêtes ou de rapports d’analyse fréquemment utilisés ou complexes. Si les requêtes ne sont pas assez efficaces, consultez le plan d’exécution pour voir quelle partie de la requête a été repoussée vers la base de données distante et le volume de données renvoyé. Les requêtes nécessitant une agrégation ou un traitement analytique complexe peuvent être mieux gérées par l’extraction des données client dans une base de données dédiée ou un entrepôt de données optimisé pour les requêtes d’analyse. Ce modèle est expliqué dans la didacticiel sur l’analyse des clients.
Obtenir les scripts de l'application Wingtip Tickets SaaS Database Per Tenant
Les scripts et le code de l’application de base de données multi-locataire SaaS Wingtip Tickets sont disponibles dans le dépôt GitHub WingtipTicketsSaaS-DbPerTenant. Consultez les conseils généraux avant de télécharger et de débloquer les scripts Wingtip Tickets SaaS.
Créer des données sur des ventes de tickets
Pour exécuter des requêtes sur un jeu de données plus concret, créez des données de ventes de tickets en exécutant le générateur de tickets.
- Dans PowerShell ISE, ouvrez le script ...\Learning Modules\Operational Analytics\Adhoc Reporting\Demo-AdhocReporting.ps1 et définissez la valeur suivante :
- $DemoScenario = 1, Acheter des tickets pour des événements dans tous les lieux.
- Appuyez sur F5 pour exécuter le script et générer des ventes de tickets. Pendant l’exécution du script, poursuivez les étapes de ce didacticiel. Les données de ticket font l’objet d’une requête dans la section Exécuter des requêtes distribuées ad hoc. Vous devez donc attendre que le générateur de tickets ait terminé.
Explorer les vues globales
Dans l’application Wingtip Tickets SaaS Database Per Tenant, chaque client est associé à une base de données. Ainsi, les données figurant dans les tables de base de données se limitent à la perspective d’un seul client. Toutefois, lorsque l’ensemble des bases de données sont interrogées, il est important que la requête élastique puisse traiter les données comme si elles faisaient partie d’une seule base de données logique partitionnée par le client.
Pour simuler ce modèle, un ensemble de vues globales est ajouté à la base de données locataire. Ces vues projettent alors un ID de locataire dans chacune des tables interrogées globalement. Par exemple, la vue VenueEvents ajoute un élément VenueId calculé dans les colonnes projetées à partir de la table Events. De même, les vues VenueTicketPurchases et VenueTickets ajoutent une colonne VenueId projetée à partir de leurs tables respectives. Ces affichages sont utilisés par une requête élastique pour paralléliser les requêtes et les transmettre à la bonne base de données client distante lorsqu'une colonne VenueId est présente. Cela réduit considérablement la quantité de données renvoyées et augmente nettement les performances pour de nombreuses requêtes. Ces vues globales ont été créées au préalable dans toutes les bases de données client.
Ouvrez SSMS et connectez-vous au serveur tenants1-<USER>.
Développez Bases de données, cliquez avec le bouton droit sur contosoconcerthall, puis sélectionnez Nouvelle requête.
Exécutez les requêtes suivantes pour découvrir la différence entre les tables de client unique et les vues globales :
-- The base Venue table, that has no VenueId associated. SELECT * FROM Venue -- Notice the plural name 'Venues'. This view projects a VenueId column. SELECT * FROM Venues -- The base Events table, which has no VenueId column. SELECT * FROM Events -- This view projects the VenueId retrieved from the Venues table. SELECT * FROM VenueEvents
Dans ces vues, l’élément VenueId est calculé en tant que hachage du nom de lieu, mais toute autre approche peut être utilisée pour introduire une valeur unique. Cette approche est semblable à la façon dont la clé de client est calculée pour être utilisée dans le catalogue.
Pour examiner la définition de la vue Venues :
Dans Explorateur d’objets, développez contosoconcerthall>Vues :
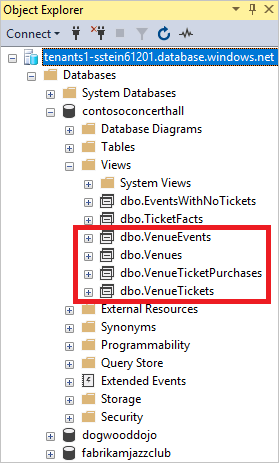
Cliquez avec le bouton droit sur dbo.Venues.
Sélectionnez Générer un script de la vue en tant que>CRÉER vers>Nouvelle fenêtre d’éditeur de requête
Script d’une autre vue Venue illustrant la méthode d’ajout de l’élément VenueId.
Déployer la base de données utilisée pour les requêtes distribuées
Cet exercice déploie la base de données adhocreporting. Cette base de données principale contient le schéma utilisé pour interroger toutes les bases de données locataires. La base de données est déployée sur le serveur de catalogue existant, qui est le serveur utilisé pour toutes les bases de données liées à la gestion dans l’exemple d’application.
Dans PowerShell ISE, ouvrez ...\Learning Modules\Operational Analytics\Adhoc Reporting\Demo-AdhocReporting.ps1.
Définissez $DemoScenario = 2, Déployer la base de données de génération d’états ad hoc.
Appuyez sur F5 pour exécuter le script et créer la base de données adhocreporting.
Dans la section suivante, vous allez ajouter un schéma à la base de données, permettant ainsi l’exécution de requêtes distribuées.
Configurer la base de données 'head' pour l’exécution de requêtes distribuées
Cet exercice ajoute le schéma (les définitions de la source de données externe et de la table externe) à la base de données adhocreporting pour permettre l’interrogation de toutes les bases de données client.
Ouvrez SQL Server Management Studio et connectez-vous à la base de données de rapport ad hoc créée à l’étape précédente. Le nom de la base de données est adhocreporting.
Ouvrez ...\Modules d’apprentissage\Operational Analytics\Adhoc Reporting\ Initialize-AdhocReportingDB.sql dans SSMS.
Passez en revue le script SQL et notez les points suivants :
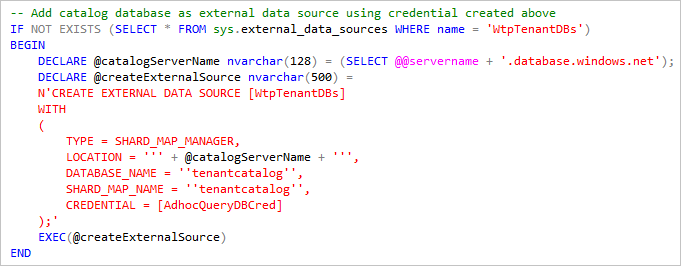
La requête élastique utilise des informations d’identification de niveau base de données pour accéder à chacune des bases de données client. Ces informations d’identification doivent être disponibles dans toutes les bases de données et doivent normalement bénéficier des droits minimaux nécessaires pour activer ces requêtes.

En utilisant la base de données de catalogues comme source de données externe, les requêtes sont distribuées sur toutes les bases de données inscrites dans le catalogue au moment de l’exécution de la requête. Étant donné que les noms de serveur sont différents pour chaque déploiement, ce script obtient l’emplacement de la base de données du catalogue à partir du serveur actuel (@@servername) dans lequel le script est exécuté.
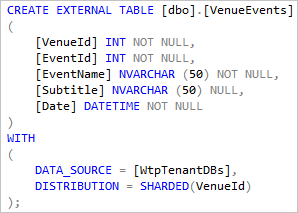
Les tables externes qui font référence aux vues globales décrites dans la section précédente et définies avec DISTRIBUTION = SHARDED(VenueId) . Étant donné que chaque élément VenueId correspond à une base de données individuelle, cela améliore les performances dans de nombreux scénarios, comme illustré dans la section suivante.
La table locale VenueTypes qui est créée et alimentée. Cette table de données de référence étant courante dans toutes les bases de données client, elle peut être représentée ici comme une table locale et renseignée avec les données courantes. Pour certaines requêtes, cette table définie dans la base de données de tête permet de réduire le volume de données devant être déplacé vers la base de données de tête.
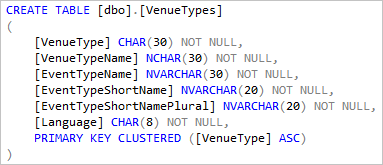
Si vous incluez des tables de référence de cette manière, veillez à mettre à jour le schéma et les données de la table lorsque vous mettez à jour les bases de données client.
Appuyez sur F5 pour exécuter le script et initialiser la base de données adhocreporting.
Vous pouvez à présent exécuter des requêtes distribuées et collecter des informations sur l’ensemble des clients !
Exécuter des requêtes distribuées
La base de données adhocreporting étant à présent configurée, exécutez quelques requêtes distribuées. Intégrez le plan d’exécution pour mieux appréhender le processus de requête.
Lors de l’inspection du plan d’exécution, passez la souris sur les icônes de plan pour plus d’informations.
Remarque importante : lorsque nous avons défini la source de données externe, le paramètre DISTRIBUTION = SHARDED(VenueId) améliore les performances dans de nombreux scénarios. Étant donné que chaque élément VenueId correspond à une base de données individuelle, le filtrage peut être effectué à distance facilement, renvoyant uniquement les données nécessaires.
Ouvrez ...\Learning Modules\Operational Analytics\Adhoc Reporting\Demo-AdhocReportingQueries.sql dans SSMS.
Assurez-vous que vous êtes connecté à la base de données adhocreporting.
Sélectionnez le menu Requête et cliquez sur Inclure le plan d’exécution réel
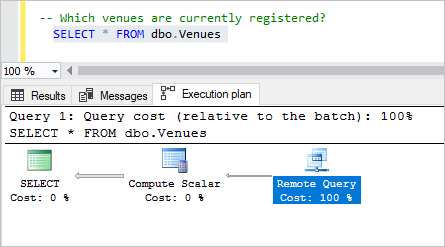
Mettez en surbrillance la requête Quels lieux sont actuellement inscrits ? , puis appuyez sur F5.
La requête renvoie la liste complète des lieux, montrant à quel point il est facile d’interroger l’ensemble des clients et de renvoyer des données provenant de chacun d’eux.
Inspectez le plan ; vous constaterez que la totalité des coûts correspond à la requête distante. Chaque base de données client exécute la requête à distance et renvoie ses informations de site à la base de données de tête.
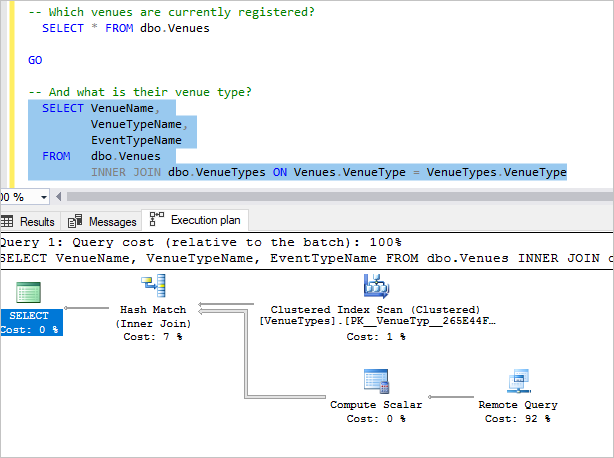
Sélectionnez la prochaine requête, puis appuyez sur F5.
Cette requête joint les données de bases de données client et la table VenueTypes table (elle est locale dans la mesure où elle figure dans la base de données adhocreporting).
Inspectez le plan ; vous constatez que la majorité des coûts s'applique à la requête distante. Chaque base de données client renvoie ses informations relatives aux lieux et effectue une jointure locale avec la table VenueTypes locale pour afficher le nom convivial.
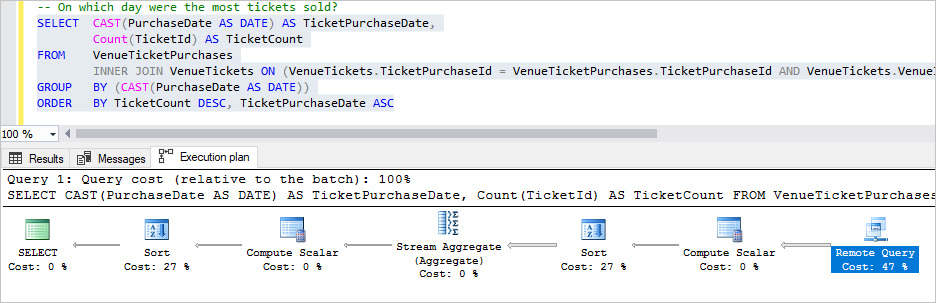
Sélectionnez à présent la requête Quel jour y a-t-il eu le plus de tickets vendus ? , puis appuyez sur F5.
Cette requête effectue une opération de jointure et d’agrégation un peu plus complexe. La plupart des traitements se produisent à distance. Seules les lignes uniques, contenant chacune le nombre de ventes de tickets par jour sur le lieu, sont renvoyées à la base de données de tête.
Étapes suivantes
Dans ce tutoriel, vous avez appris à effectuer les opérations suivantes :
- Exécuter des requêtes distribuées sur toutes les bases de données client
- Déployer une base de données de création de rapports et définir le schéma nécessaire pour exécuter des requêtes distribuées.
Essayez maintenant le Didacticiel sur l’analyse des clients pour explorer l’extraction de données dans une base de données d’analyse distincte pour un traitement d’analyse plus complexe.