Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Vous pouvez ingérer, traiter, afficher et analyser des données de streaming en temps réel dans une table directement à partir d’une base de données dans Azure SQL Database à l’aide d’Azure Stream Analytics. Azure Stream Analytics fournit un large éventail de scénarios tels que la voiture connectée, la supervision à distance, la détection des fraudes, etc.
Dans le portail Azure, vous pouvez sélectionner une source d’événements (Event Hub/IoT Hub), afficher les événements entrants en temps réel et sélectionner une table pour stocker des événements. Vous pouvez également écrire des requêtes du langage de requête Azure Stream Analytics dans le portail pour transformer les événements entrants et les stocker dans la table sélectionnée. Ce point d’entrée est en plus des expériences de création et de configuration qui existent déjà dans Stream Analytics. Cette expérience commence à partir du contexte de votre base de données, ce qui vous permet de configurer rapidement un travail Stream Analytics et de naviguer en toute transparence entre la base de données dans Azure SQL Database et les expériences Stream Analytics.

Principaux avantages
- Basculement de contexte minimal : vous pouvez commencer à partir d’une base de données dans Azure SQL Database dans le portail et commencer à ingérer des données en temps réel dans une table sans passer à un autre service.
- Nombre réduit d’étapes : le contexte de votre base de données et de votre table est utilisé pour préconfigurer un travail Stream Analytics.
- Facilité d’utilisation supplémentaire avec les données en préversion : préversion des données entrantes à partir de la source d’événements (Event Hub/IoT Hub) dans le contexte de la table sélectionnée.
Importante
Un travail Azure Stream Analytics peut générer une sortie vers Azure SQL Database, Azure SQL Managed Instance ou Azure Synapse Analytics. Pour plus d’informations, consultez la section Sorties.
Conditions préalables
Pour effectuer les étapes de cet article, vous avez besoin des ressources suivantes :
- Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit.
- Base de données dans Azure SQL Database. Pour plus d’informations, consultez Démarrage rapide : Créer une base de données unique - Azure SQL Database.
- Règle de pare-feu permettant à votre ordinateur de se connecter au serveur. Pour plus d’informations, consultez Démarrage rapide : Créer une règle de pare-feu au niveau du serveur dans le portail Azure.
Configurer l’intégration de Stream Analytics
Connectez-vous au portail Azure.
Accédez à la base de données dans laquelle vous souhaitez ingérer vos données de streaming. Sous Intégrations, sélectionnez Stream Analytics (préversion).
Pour commencer à ingérer vos données de diffusion en continu dans cette base de données, sélectionnez Créer et donnez un nom à votre travail de diffusion en continu, puis sélectionnez Suivant : Entrée.
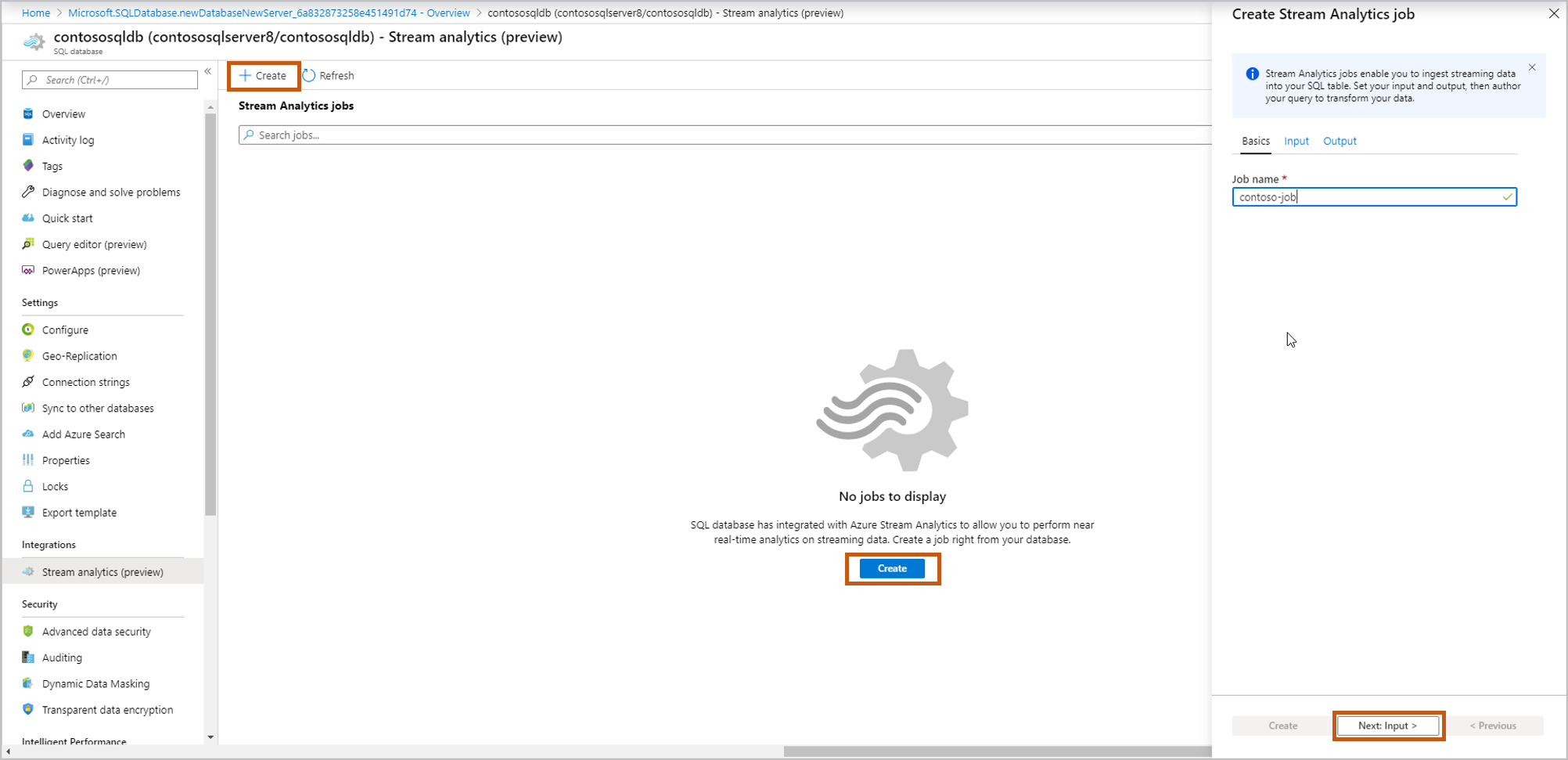
Entrez les détails de la source de vos événements, puis sélectionnez Suivant : Sortie.
Type d’entrée : Event Hub/IoT Hub
Alias d’entrée : entrez un nom pour identifier votre source d’événements
Abonnement : identique à l’abonnement Azure SQL Database
Espace de noms Event Hub : Nom de l’espace de noms
Nom du hub d’événements : nom du hub d’événements dans l’espace de noms sélectionné
Nom de la stratégie Event Hub (valeur par défaut pour créer) : donnez un nom de stratégie
Groupe de consommateurs Event Hub (par défaut pour créer) : donnez un nom de groupe de consommateurs
Nous vous recommandons de créer un groupe de consommateurs et une stratégie pour chaque nouvelle tâche Azure Stream Analytics que vous créez ici. Les groupes de consommateurs autorisent uniquement cinq lecteurs simultanés et dès lors, fournir un groupe de consommateurs dédié pour chaque travail permet d’éviter les erreurs liées à un dépassement de cette limite. Une stratégie dédiée vous permet de faire pivoter votre clé ou de révoquer des autorisations sans affecter d’autres ressources.
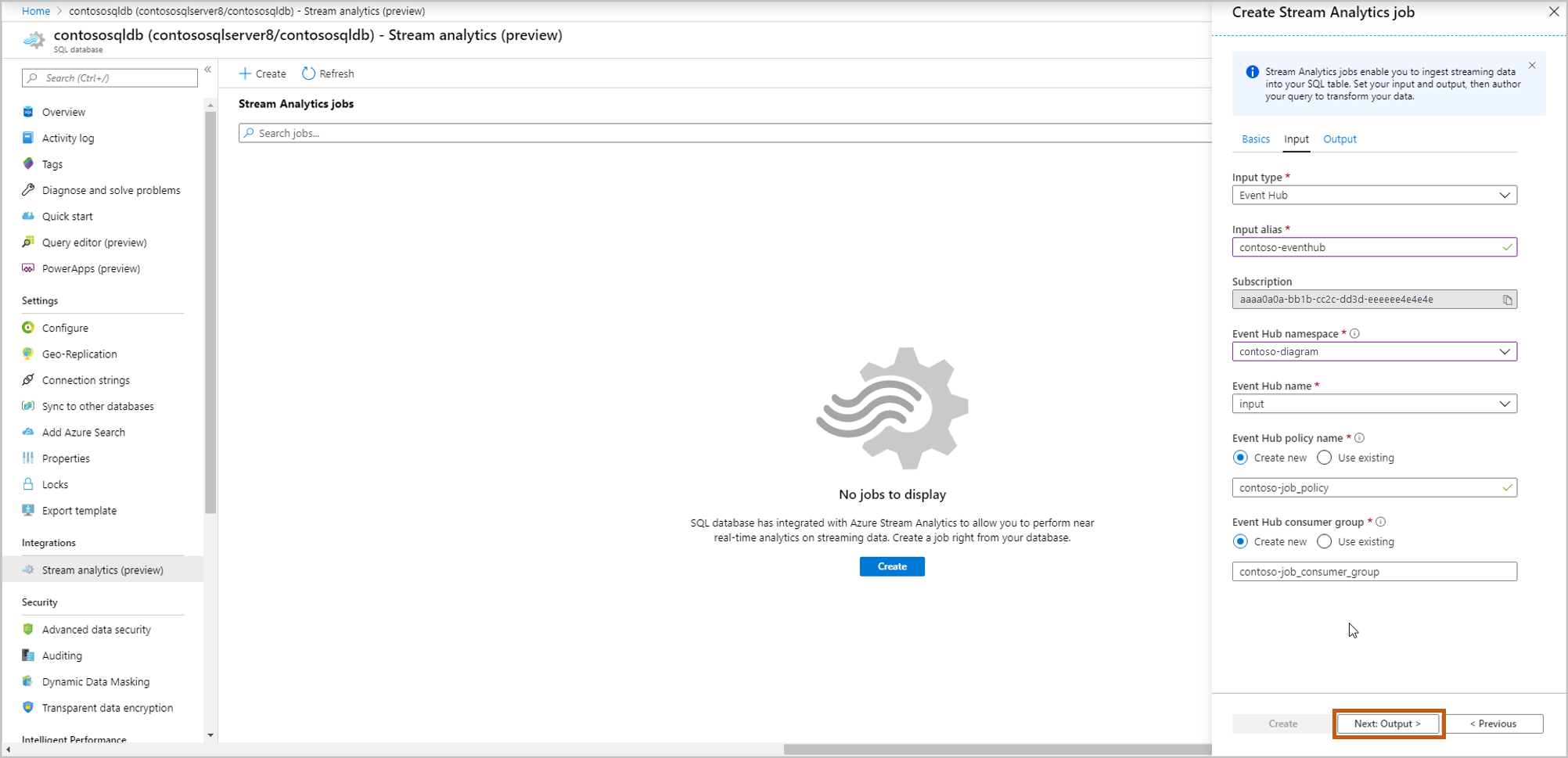
Sélectionnez la table dans laquelle vous souhaitez ingérer vos données de streaming. Une fois l’opération terminée, sélectionnez Créer.
Nom d’utilisateur, mot de passe : entrez vos informations d’identification pour l’authentification SQL Server. Sélectionnez Valider.
Tableau : sélectionnez Créer nouveau ou Utiliser existant. Dans ce flux, nous allons sélectionner Créer. Cela créera une nouvelle table lorsque vous démarrez la tâche Stream Analytics.
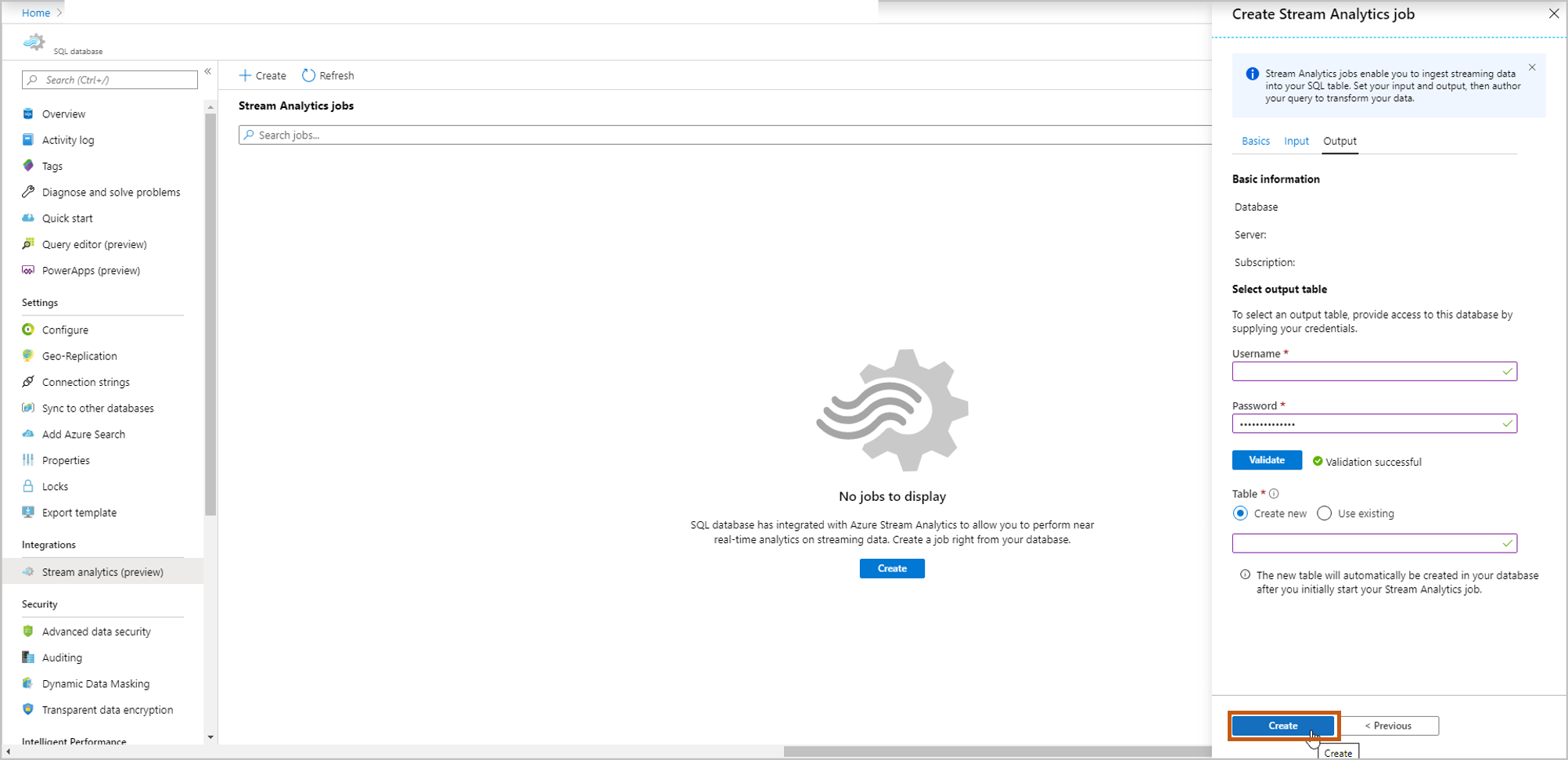
Une page de requête s’ouvre avec les détails suivants :
Votre entrée (source d’événements d’entrée) à partir de laquelle vous allez ingérer des données
Votre sortie (table de sortie) qui stocke les données transformées
Exemple de requête SAQL avec l’instruction SELECT.
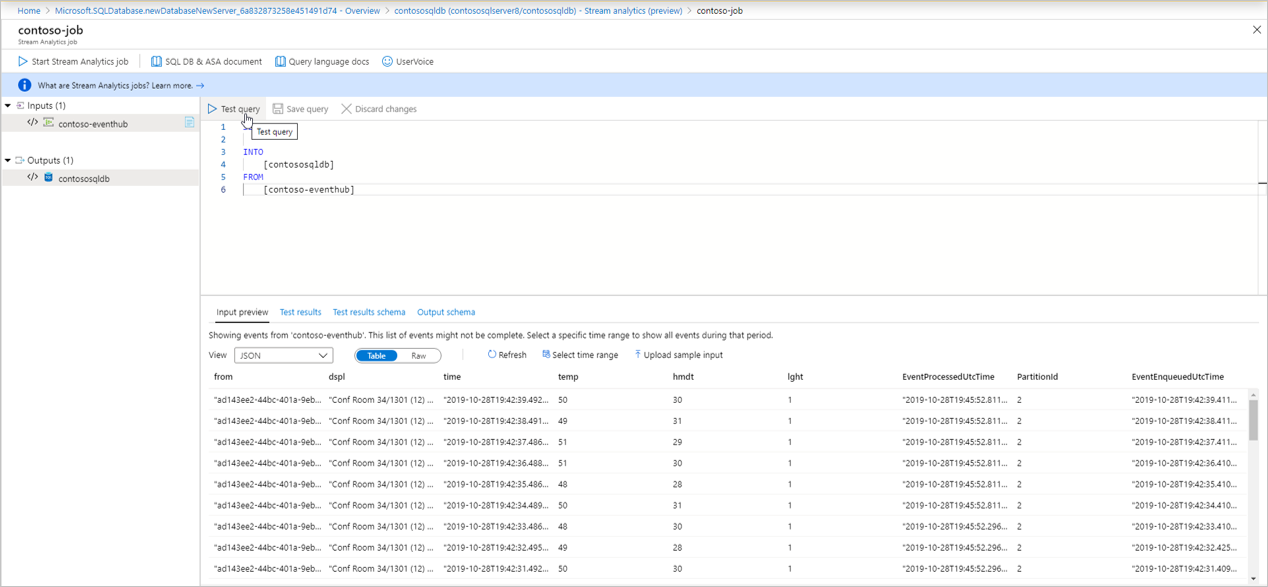
Prévisualisation d’entrée : montre un aperçu des dernières données entrantes provenant de la source d’événements d’entrée.
- Le type de sérialisation de vos données est automatiquement détecté (JSON ou CSV). Vous pouvez le remplacer manuellement par JSON/CSV/AVRO.
- Vous pouvez afficher un aperçu des données entrantes au format Table ou Au format Brut.
- Si les données qui apparaissent ne sont pas à jour, sélectionnez Actualiser pour afficher les événements les plus récents.
- Sélectionnez Sélectionner un intervalle de temps pour tester votre requête par rapport à un intervalle de temps spécifique d’événements entrants.
- Sélectionnez Charger un exemple d’entrée pour tester votre requête en chargeant un exemple de fichier JSON/CSV. Pour plus d’informations sur le test d’une requête SAQL, consultez Tester un travail Azure Stream Analytics avec des exemples de données.
Résultats des tests : sélectionnez une requête de test et vous pouvez voir les résultats de votre requête de diffusion en continu
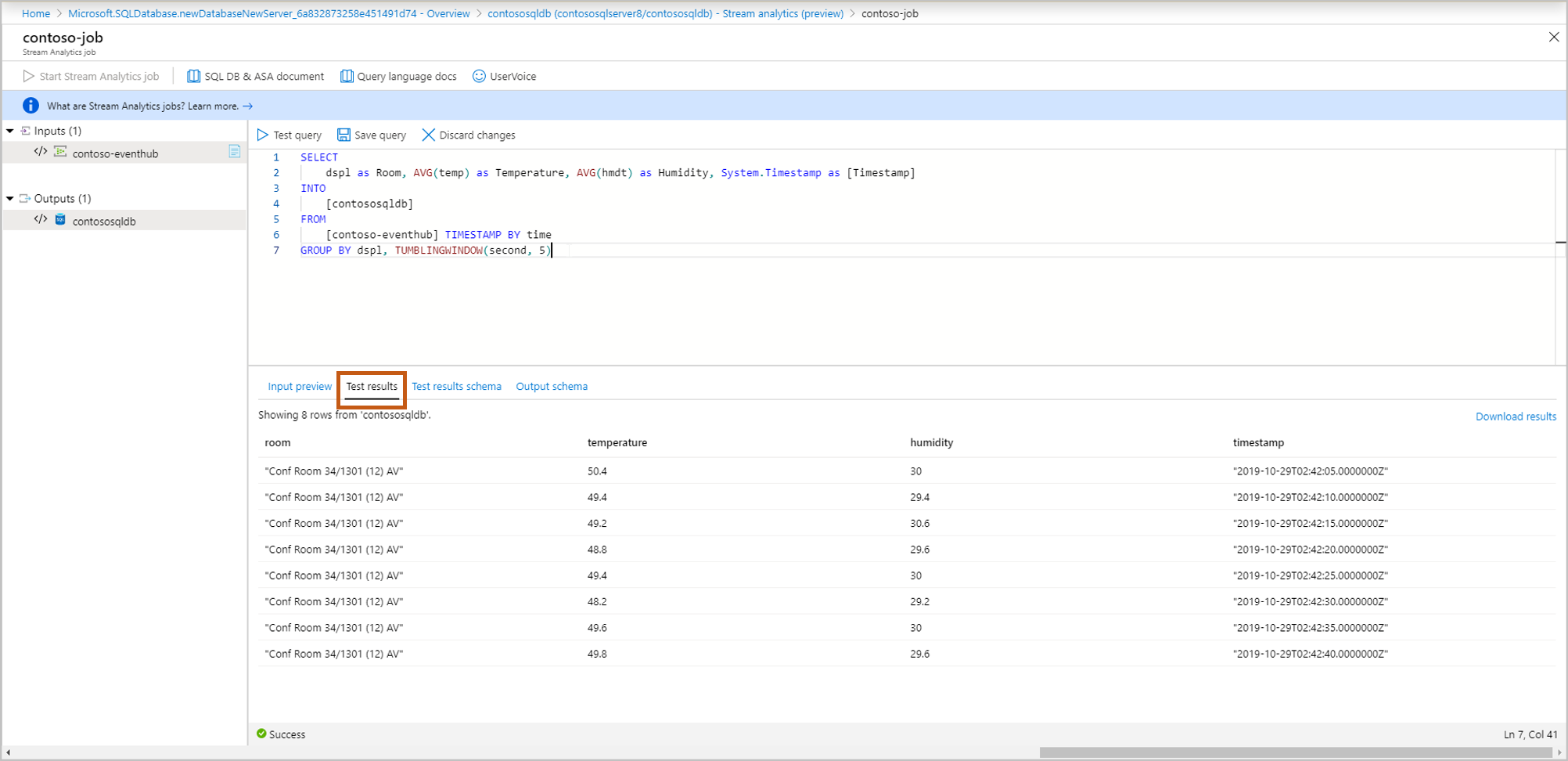
Schéma des résultats de test : affiche le schéma des résultats de votre requête de streaming après le test. Vérifiez que le schéma de résultats de test correspond à votre schéma de sortie.
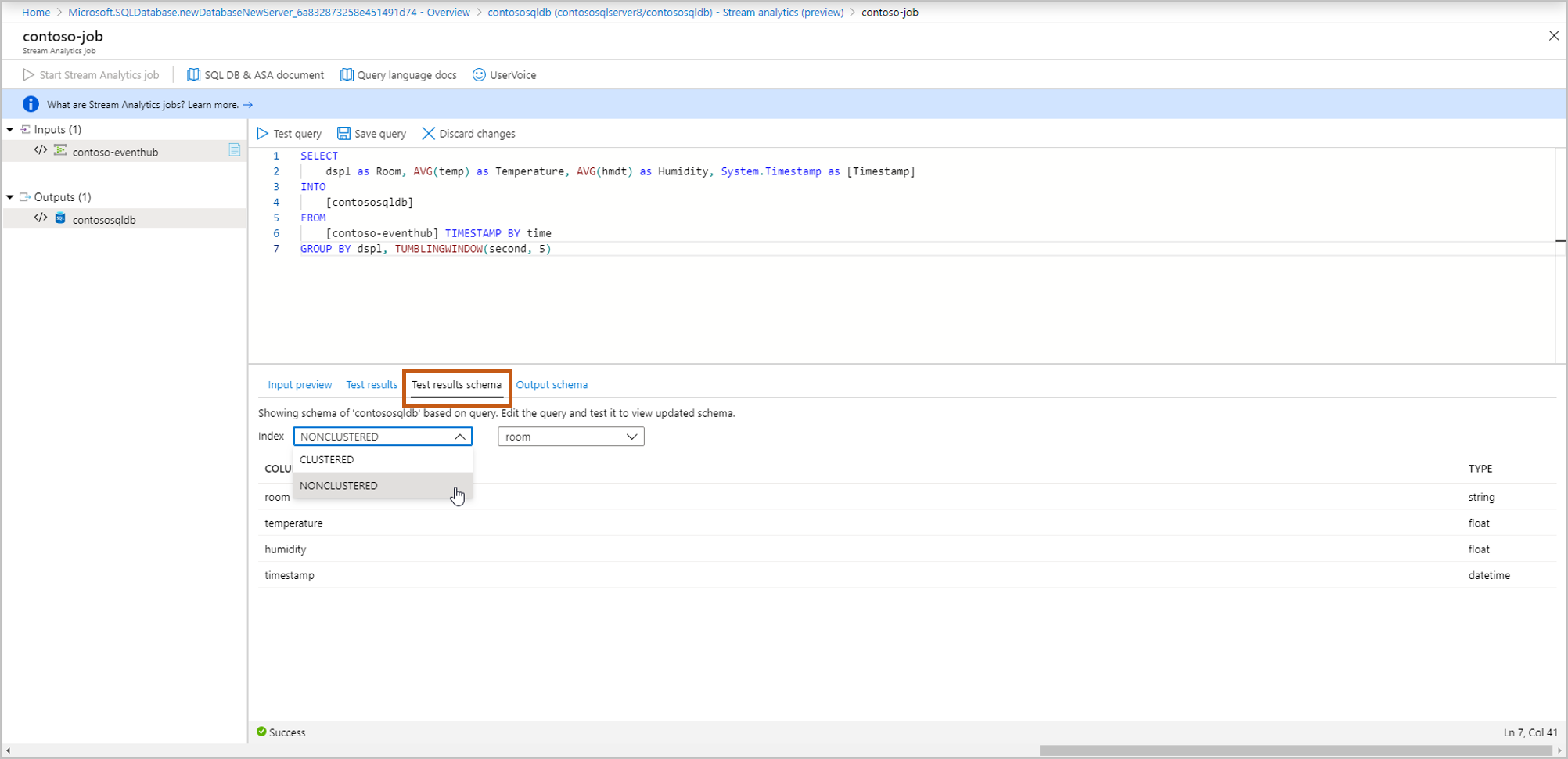
Schéma de sortie : il contient le schéma de la table que vous avez sélectionnée à l’étape 5 (nouvelle ou existante).
- Créer : si vous avez sélectionné cette option à l’étape 5, vous ne verrez pas encore le schéma tant que vous n’avez pas démarré la tâche de diffusion en continu. Lors de la création d’une table, sélectionnez l’index de table approprié. Pour plus d’informations sur l’indexation de tables, consultez Explication des index clusterisés et non clusterisés.
- Utilisez existant : si vous avez sélectionné cette option à l’étape 5, vous verrez le schéma de la table sélectionnée.
Après avoir terminé la création et le test de la requête, sélectionnez Enregistrer la requête. Sélectionnez Démarrer le travail Stream Analytics pour commencer à ingérer des données transformées dans la table SQL. Une fois que vous avez finalisé les champs suivants, démarrez le travail.
Heure de début de sortie : définit l’heure de la première sortie du travail.
- Maintenant : le travail démarre maintenant et traite les nouvelles données entrantes.
- Personnalisé : le travail démarre maintenant, mais traite les données à partir d’un point spécifique dans le temps (qui peuvent être dans le passé ou à l’avenir). Pour plus d’informations, consultez Guide pratique pour démarrer un travail Azure Stream Analytics.
Unités de streaming : Azure Stream Analytics est facturé par le nombre d’unités de streaming requises pour traiter les données via le service. Pour plus d’informations, consultez la tarification d’Azure Stream Analytics.
Gestion des erreurs de données de sortie :
- Nouvelle tentative : lorsqu’une erreur se produit, Azure Stream Analytics réessaye d’écrire l’événement indéfiniment jusqu’à ce que l’écriture réussisse. Il n’y a pas de délai d’attente pour les nouvelles tentatives. Au final, le traitement de tous les événements suivants est bloqué par l’événement qui fait l’objet des nouvelles tentatives. Cette option est la stratégie de gestion des erreurs de sortie par défaut.
- Drop : Azure Stream Analytics supprime tous les événements de sortie qui entraînent une erreur de conversion de données. Les événements supprimés ne peuvent pas être récupérés pour un retraitement ultérieur. Toutes les erreurs temporaires (par exemple, les erreurs réseau) sont retentées indépendamment de la configuration de la stratégie de gestion des erreurs de sortie.
Paramètres de sortie SQL Database : une option pour hériter du schéma de partitionnement de votre étape de requête précédente, afin d'activer une topologie entièrement parallèle avec plusieurs écrivains vers la table. Pour plus d'informations, consultez Sortie d'Azure Stream Analytics dans Azure SQL Database.
Nombre maximal de lots : limite supérieure recommandée pour le nombre d’enregistrements envoyés avec chaque transaction d’insertion en bloc.
Pour plus d’informations sur la gestion des erreurs de sortie, consultez Stratégies d’erreur de sortie dans Azure Stream Analytics.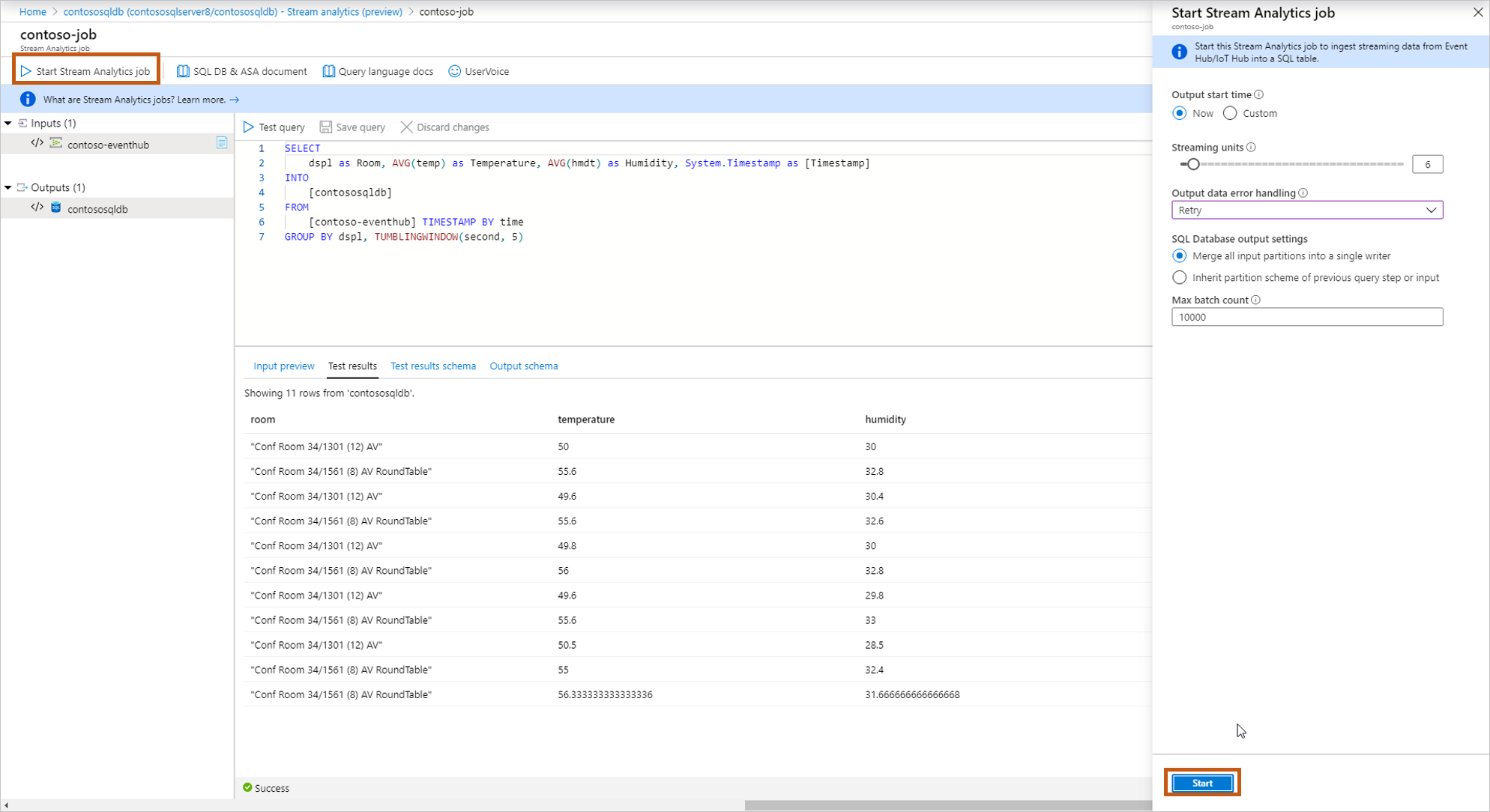
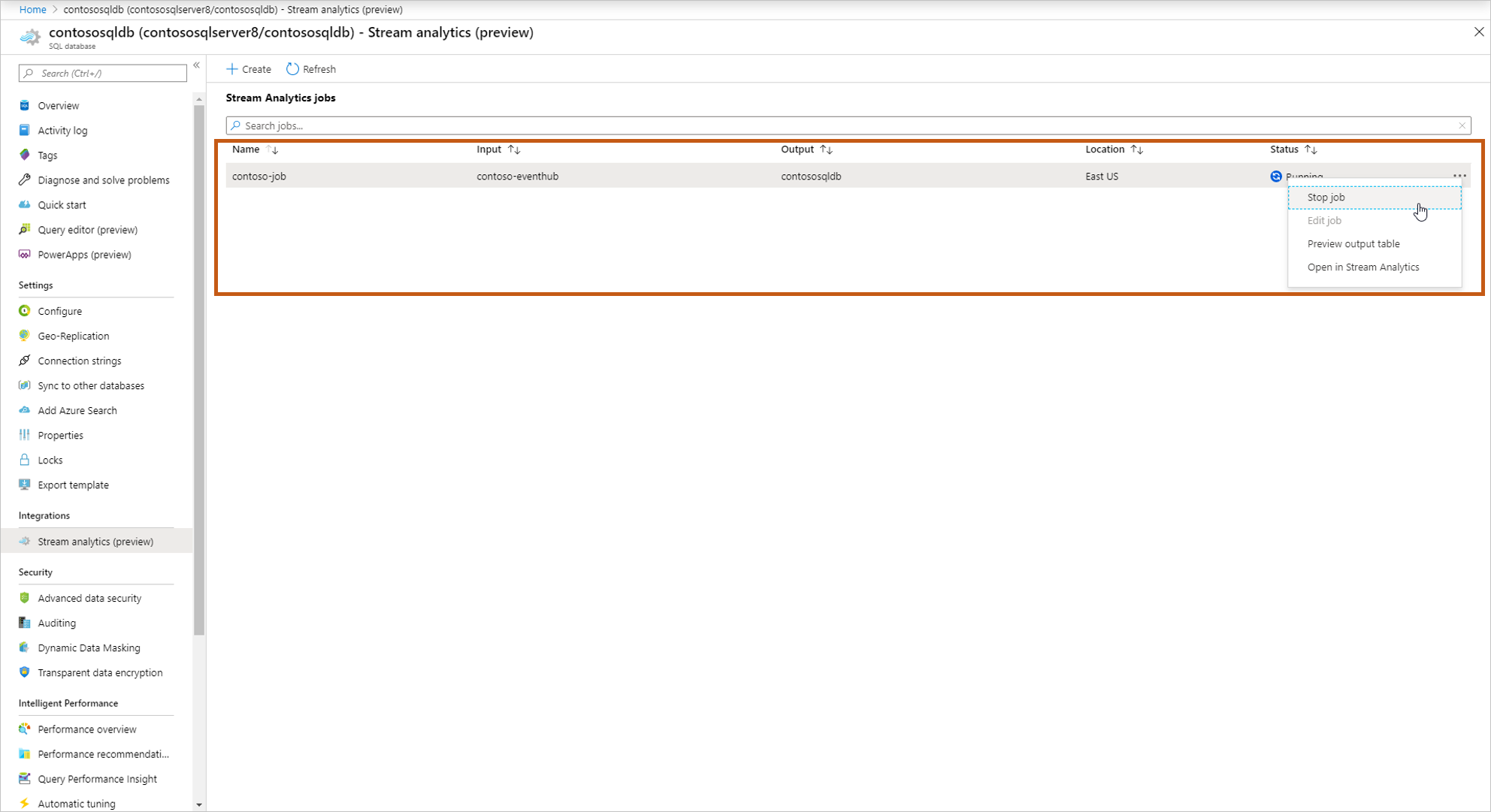
Une fois que vous démarrez le travail, vous verrez le travail en cours d’exécution dans la liste et vous pouvez effectuer les actions suivantes :
Démarrer/arrêter le travail : si le travail est en cours d’exécution, vous pouvez arrêter le travail. Si le travail est arrêté, vous pouvez le démarrer.
Modifier le travail : vous pouvez modifier la requête. Si vous souhaitez apporter davantage de modifications au modèle de tâche, ajouter davantage d'entrées/sorties, puis ouvrez la tâche dans Stream Analytics. L’option Modifier est désactivée lorsque le travail est en cours d’exécution.
Table de sortie d’aperçu : vous pouvez afficher un aperçu de la table dans l’éditeur de requête SQL.
Ouvrir dans Stream Analytics : ouvrez la tâche dans Stream Analytics pour afficher les détails de surveillance et de débogage de la tâche.