Vue d’ensemble de la continuité d’activité avec Azure SQL Managed Instance
S’applique à :![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Cet article fournit une vue d’ensemble des capacités de continuité d’activité et reprise d’activité d’Azure SQL Managed Instance, en décrivant les options et les recommandations pour récupérer des événements perturbateurs qui pourraient conduire à une perte de données ou rendre votre instance et votre application indisponibles. Découvrez la procédure à suivre lorsqu’une erreur d’un utilisateur ou d’une application affecte l’intégrité des données, lorsqu’une zone de disponibilité Azure subit une panne ou que votre application nécessite une maintenance.
Vue d’ensemble
La continuité d’activité dans Azure SQL Managed Instance fait référence aux mécanismes, stratégies et procédures qui permettent à votre entreprise de continuer à fonctionner en cas de perturbation en fournissant disponibilité, haute disponibilité et récupération d’urgence.
Dans la plupart des cas, SQL Managed Instance gère des événements perturbateurs qui peuvent se produire dans un environnement cloud et préserve l’exécution de vos applications et processus métier. Toutefois, il existe certains événements perturbants où la prévention peut prendre un certain temps, comme :
- Un utilisateur supprime ou met à jour accidentellement une ligne dans une table.
- Un attaquant a réussi à supprimer des données ou à éliminer une base de données.
- Un événement catastrophique naturel neutralise un centre de données ou une zone de disponibilité ou une région.
- Une rare panne de centre de données, de zone de disponibilité ou de région causée par un changement de configuration, un bogue logiciel ou une défaillance de composant matériel.
Disponibilité
Azure SQL Managed Instance est fourni avec une résilience de base et une promesse de fiabilité qui les protège contre les défaillances logicielles ou matérielles. Les sauvegardes de base de données sont automatisées pour protéger vos données contre la corruption ou la suppression accidentelle. En tant que paaS (Platform-as-a-service), le service Azure SQL Managed Instance fournit une disponibilité en tant que fonctionnalité hors service avec un contrat SLA de disponibilité de 99,99 %.
Haute disponibilité
Pour obtenir une haute disponibilité dans l’environnement cloud Azure, activez la redondance de zone afin que l’instance utilise des zones de disponibilité pour garantir la résilience aux défaillances zonales. De nombreuses régions Azure fournissent des zones de disponibilité, qui sont des groupes séparés de centres de données au sein d’une région qui dispose d’une alimentation indépendante, d’un refroidissement et d’une infrastructure réseau. Les zones de disponibilité sont conçues pour fournir des services régionaux, une capacité et une haute disponibilité dans les zones restantes si une zone rencontre une panne. En activant la redondance de zone, l’instance est résiliente aux défaillances matérielles et logicielles zonales et la récupération est transparente pour les applications. Lorsque la haute disponibilité est activée, le service Azure SQL Managed Instance est en mesure de fournir un contrat SLA de disponibilité plus élevé de 99,995 %.
Récupération d’urgence
Pour obtenir une disponibilité et une redondance plus élevées entre les régions, vous pouvez activer les fonctionnalités de récupération d’urgence pour récupérer rapidement l’instance à partir d’une défaillance régionale catastrophique. Les options de récupération d’urgence avec Azure SQL Managed Instance sont :
- Les groupes de basculement activent la synchronisation continue entre une instance principale et secondaire. Les groupes de basculement fournissent des points de terminaison de l’écouteur en lecture seule et en lecture seule qui restent inchangés afin de mettre à jour les chaîne de connexion d’application après le basculement n’est pas nécessaire.
- La géorestauration vous permet de récupérer à partir d’une panne régionale en effectuant une restauration à partir de sauvegardes géorépliquées lorsque vous ne pouvez pas accéder à votre base de données dans la région primaire en créant une base de données sur n’importe quelle instance existante dans n’importe quelle région Azure.
Fonctionnalités garantissant la continuité d’activité
Par exemple, il existe quatre grands scénarios de perturbation potentielle. Le tableau suivant répertorie les fonctionnalités de continuité d’activité SQL Managed Instance que vous pouvez utiliser pour atténuer un scénario de perturbation potentielle d’activité :
| Scénario d’interruption d’activité | Fonctionnalité de continuité des activités |
|---|---|
| Des défaillances matérielles ou logicielles locales affectant le nœud de base de données. | Pour pallier les défaillances matérielles et logicielles locales, SQL Managed Instance inclut une architecture de disponibilité, qui garantit la récupération automatique de ces défaillances avec jusqu’à 99,99 % de disponibilité SLA. |
| Une suppression ou une altération des données se produit, généralement à la suite d’un bogue d’application ou d’une erreur humaine. Ces défaillances sont spécifiques à l’application et ne peuvent généralement pas être détectées par le service. | Pour protéger votre entreprise contre la perte de données, SQL Managed Instance crée automatiquement des sauvegardes de bases de données complètes (toutes les semaines), des sauvegardes de bases de données différentielles (toutes les 12 ou 24 heures) des sauvegardes du journal des transactions (toutes les 5 à 10 minutes). Par défaut, les sauvegardes sont stockées dans un stockage géoredondant pendant sept jours et prennent en charge une période de rétention de sauvegarde configurable pour une restauration à un instant dans le passé pouvant aller jusqu’à 35 jours. Vous pouvez restaurer une base de données supprimée au point où elle a été supprimée si l’instance n’a pas été supprimée ou si vous avez configuré la conservation à long terme. |
| Une panne rare de centre de données ou de zone de disponibilité, peut-être causée par un événement d’urgence naturelle, une modification de configuration, un bogue logiciel ou une défaillance de composant matériel. | Pour atténuer la panne au niveau du centre de données ou de la zone de disponibilité, activez la redondance de zone pour SQL Managed Instance afin d’utiliser les Zones de disponibilité Azure et de fournir une redondance entre plusieurs zones physiques au sein d’une région Azure. L’activation de la redondance de zone garantit que la managed instance est résiliente aux défaillances zonales avec jusqu’à 99,995 % de contrat SLA de haute disponibilité. |
| Une panne de région rare impactant toutes les zones de disponibilité et les centres de données qui le composent, peut-être causées par un événement catastrophique naturel. | Pour atténuer une panne à l’échelle de la région, activez la récupération d’urgence à l’aide de l’une des options suivantes : - Synchronisation de données continue avec des groupes de basculement vers des réplicas dans une région secondaire utilisée pour le basculement. - Configuration de l’option de redondance du stockage de sauvegarde sur stockage de sauvegarde géoredondant pour utiliser la géorestauration. |
RTO et RPO
Lorsque vous élaborez votre plan de continuité d’activité, comprenez le délai maximum acceptable avant que l’application ne se rétablisse complètement après l’événement perturbateur. Le délai de récupération complète d’une application s’appelle l’objectif de délai de récupération (RTO, Recovery Time Objective). Comprenez également la période maximale de mise à jour des données récentes (intervalle de temps) que l’application peut tolérer de perdre lorsqu’elle se remet d’un événement perturbateur non planifié. La perte de données potentielle est appelée l’objectif de point de récupération (RPO, Recovery Point Objective).
Le tableau suivant compare l’objectif de point de récupération (RPO) et l’objectif de délai de récupération (RTO) de chaque option de continuité d’activité :
| Options de continuité d’activité | RTO (temps d’arrêt) | RPO (perte de données) |
|---|---|---|
| Haute disponibilité (activation de la redondance de zone) |
En général, moins de 30 secondes | 0 |
| Récupération d’urgence (activation des groupes de basculement) |
1 heure | 5 secondes (Dépend des modifications de données avant l’événement perturbant qui n’a pas été répliqué) |
| Récupération d’urgence (en utilisant la géo-restauration) |
12 heures | 1 heure |
Récupérer une base de données dans la même région Azure
Vous pouvez utiliser des sauvegardes de base de données automatiques pour restaurer une base de données à un point dans le temps passé. Vous pouvez ainsi récupérer suite à des altérations de données dues à des erreurs humaines. La restauration à un instant dans le passé (PITR) vous permet de créer une nouvelle base de données sur la même instance, ou une instance différente, qui représente l’état des données avant l’événement de corruption. L’opération de restauration est une opération de données dont la taille dépend également de la charge de travail actuelle de l’instance cible. La récupération d’une base de données très volumineuse ou très active peut prendre plus de temps. Pour plus d’informations sur le temps de récupération, voir Temps de récupération de la base de données.
Si la période de rétention maximale de la base de données prise en charge associée à la restauration à un instant dans le passé (PITR, Point In Time Restore) n’est pas suffisante pour votre application, vous pouvez la rallonger en configurant une stratégie de conservation à long terme (LTR) pour la ou les bases de données. Pour plus d’informations, consultez Conservation des sauvegardes à long terme.
Récupérer une base de données sur une instance existante
Bien que le fait soit rare, un centre de données Azure peut subir une panne. En cas de panne, il entraîne une interruption de service qui peut durer de quelques minutes à plusieurs heures.
- Vous pouvez attendre que votre instance redevienne disponible une fois la panne réparée au niveau du centre de données. Cette méthode fonctionne pour les applications qui peuvent se permettre d’avoir leur base de données déconnectée. C’est le cas, par exemple, d’un projet de développement ou d’une version d’évaluation gratuite sur lesquels vous n’avez pas à travailler en permanence. Quand une interruption survient dans un centre de données, il n’est pas possible de savoir combien de temps elle va durer. Cette solution est donc valable uniquement si vous n’avez pas besoin de votre base de données pendant un certain temps.
- Si vous utilisez un stockage géoredondant (GRS) ou géoredondant interzone (GZRS), une autre option consiste à restaurer une base de données dans l’instance managée SQL de votre choix dans n’importe quelle région Azure à l’aide de sauvegardes de base de données géoredondantes (géorestauration). La géorestauration utilise une sauvegarde géoredondante en tant que source et permet de récupérer une base de données à l’instant dans le passé le plus récent disponible, même si la base de données ou le centre de données est inaccessible en raison d’une interruption. La sauvegarde disponible se trouve dans la région jumelée.
- Enfin, vous pouvez récupérer rapidement après une interruption si vous avez configuré une zone géo-secondaire avec un groupe de basculement pour votre instance, à l’aide d’un basculement client (conseillé) ou géré par Microsoft. Le basculement lui-même ne prend que quelques secondes. Toutefois, l’activation d’un géobasculement géré par Microsoft dure au moins une heure le cas échéant. Cela est nécessaire pour s’assurer que le basculement est justifié par l’étendue de la panne. En outre, le basculement peut entraîner la perte de données récemment modifiées en raison de la nature de la réplication asynchrone entre les régions jumelées.
Au moment d’élaborer votre plan de continuité d’activité, vous devez comprendre le délai maximal acceptable nécessaire à la récupération complète de l’application après l’événement d’interruption. Le délai de récupération complète d’une application s’appelle l’objectif de délai de récupération (RTO, Recovery Time Objective). Vous devez également comprendre sur quelle période maximale l’application peut accepter de perdre les mises à jour de données récentes (intervalle de temps) lors de la récupération suite à un événement d’interruption. La perte de données potentielle est appelée l’objectif de point de récupération (RPO, Recovery Point Objective).
Différentes méthodes de récupération offrent différents niveaux de RPO et RTO. Vous pouvez choisir une méthode de récupération spécifique ou utiliser une combinaison de méthodes pour effectuer une récupération complète de l’application.
Utilisez des groupes de basculement si votre application répond à l’un des critères suivants :
- Est essentielle.
- Présente un contrat de niveau de service (SLA) qui n’autorise pas plus de 12 heures d’interruption de service.
- Toute interruption de service peut engager la responsabilité financière.
- Affiche un taux élevé de données modifiées et la perte d’une heure de données n’est pas acceptable.
- Le coût supplémentaire lié à l'utilisation de la géoréplication est plus faible que la responsabilité financière potentielle et la perte d'activité associée.
Vous pouvez combiner des sauvegardes de bases de données et des groupes de basculement en fonction des besoins de votre application.
Les sections suivantes fournissent une vue d’ensemble des étapes de la récupération à l’aide des sauvegardes de bases de données ou des groupes de basculement.
Se préparer à une panne
Quelle que soit la fonctionnalité de continuité d’activité que vous utilisez, vous devez :
- Identifier et préparer l’instance cible, notamment les règles de pare-feu IP du réseau, les connexions et les autorisations au niveau de la base de données
master. - Déterminer comment rediriger les clients et les applications clientes vers la nouvelle instance
- Documenter les autres dépendances, notamment les paramètres d’audit et les alertes
Si la préparation n’est pas effectuée correctement, la mise en ligne de vos applications après un basculement ou une récupération de base de données dure plus longtemps et nécessite probablement de résoudre certains problèmes dans une situation de stress, ce qui constitue une combinaison très risquée.
Basculer vers une instance secondaire géo-répliquée
Si vous utilisez des groupes de basculement comme mécanisme de récupération, vous pouvez configurer une stratégie de basculement automatique. Une fois le basculement lancé, l’instance secondaire est promue comme la nouvelle primaire. Elle peut alors enregistrer de nouvelles transactions et répondre aux requêtes, avec des pertes de données minimes pour les données qui n’ont pas encore été répliquées.
Remarque
Quand le centre de données est de nouveau en ligne, l’ancienne instance primaire se reconnecte automatiquement à la nouvelle instance primaire et devient l’instance secondaire. Si vous devez replacer la base de données primaire dans sa région d’origine, vous pouvez initier un basculement programmé de manière manuelle (restauration automatique).
Effectuer une restauration géographique
Si vous utilisez des sauvegardes automatisées avec un stockage géoredondant (il s’agit de l’option de stockage par défaut quand vous créez votre instance), vous pouvez récupérer la base de données à l’aide de la géorestauration. Dans la plupart des cas, la récupération intervient sous 12 heures, avec une perte de données de 1 heure maximum, selon le moment où la dernière sauvegarde de fichier journal a été effectuée et répliquée. Tant que la récupération n’est pas terminée, la base de données ne peut pas enregistrer de transactions ou répondre à des requêtes. Remarquez que la géo-restauration permet uniquement de restaurer la base de données au dernier point disponible dans le temps.
Notes
Si le centre de données redevient disponible avant que vous ne transfériez votre application vers la base de données récupérée, vous pouvez annuler la récupération.
Exécution de tâches de post-basculement/récupération
Après la récupération à l’aide d’un de ces mécanismes de récupération, vous devez effectuer les tâches supplémentaires suivantes afin que les utilisateurs et les applications soient de nouveau opérationnels :
- Rediriger les clients et les applications clientes vers la nouvelle instance et la base de données restaurée.
- Assurez-vous que les règles de pare-feu IP du réseau appropriées sont en place pour permettre aux utilisateurs de se connecter.
- Assurez-vous que les connexions et les autorisations appropriées au niveau de la base de données
mastersont en place (ou utilisez des utilisateurs contenus). - Configurer l’audit, selon les besoins.
- Configurer les alertes, selon les besoins.
Remarque
Si vous utilisez un groupe de basculement et que vous vous connectez à l’instance à l’aide de l’écouteur en lecture-écriture, la redirection après le basculement se produit automatiquement et en toute transparence pour l’application.
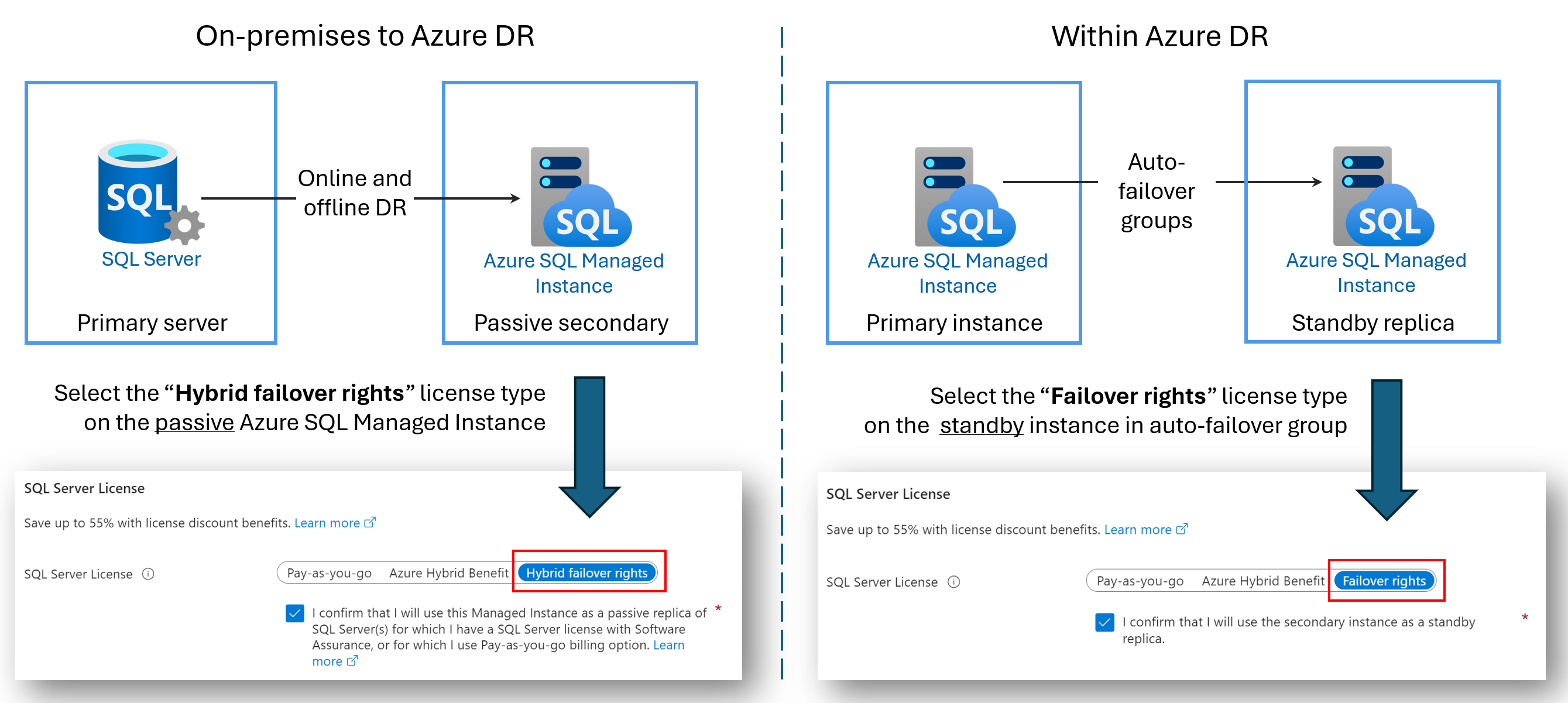
Réplicas de DR sans licence
Vous pouvez faire des économies sur les coûts de licence en configurant votre Azure SQL Managed Instance en récupération d’urgence (DR) uniquement. Cet avantage est disponible si vous utilisez un groupe de basculement entre deux SQL Managed Instances, ou si vous avez configuré une liaison hybride entre SQL Server et Azure SQL Managed Instance. Tant que l’instance secondaire n’a pas de charges de travail de lecture ou d’écriture et qu’elle n’est qu’un secours de DR passif, vous n’êtes pas facturé pour les coûts de licence vCore utilisés par l’instance secondaire.
Quand vous désignez une instance secondaire pour la récupération d'urgence uniquement, et qu'aucune charge de travail de lecture ou d'écriture ne s'exécute sur l'instance, Microsoft vous fournit le nombre de vCores qui sont concédés sous licence à l'instance principale sans frais supplémentaires dans le cadre de l'avantage des droits de basculement défini. Vous êtes toujours facturé pour le calcul et le stockage qu’utilise l’instance secondaire. Pour connaître les conditions générales précises relatives aux droits de basculement hybride, consultez les termes du contrat de licence de SQL Server en ligne dans la section « SQL Server : Droits de basculement ».
Le nom de l’avantage dépend de votre scénario :
- Droits de basculement hybride pour un réplica passif : lorsque vous configurez une liaison entre SQL Server et Azure SQL Managed Instance, vous pouvez utiliser l'avantage des droits de basculement hybride pour réduire les coûts de licence vCore pour le réplica secondaire passif.
- Droits de basculement pour un réplica en attente : lorsque vous configurez un groupe de basculement entre deux Managed Instances, vous pouvez utiliser l’avantage des droits de basculement pour réduire les coûts de licence vCore pour le réplica secondaire en attente.
Le diagramme suivant illustre l’avantage pour chaque scénario :
Étapes suivantes
Pour en savoir plus sur les fonctionnalités de continuité d’activité, consultez Sauvegardes automatisées et Groupes de basculement. En cas de sinistre, consultez Récupérer une base de données.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour