Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Cet article explique comment surveiller et gérer des fichiers dans des bases de données dans Azure SQL Managed Instance. Il explique comment surveiller la taille du fichier de base de données, réduire le journal des transactions, agrandir un fichier journal des transactions et contrôler la croissance d’un fichier journal des transactions.
Cet article s’applique à Azure SQL Managed Instance. Pour plus d’informations sur la gestion de la taille des fichiers journaux de transactions dans SQL Server, consultez Gérer la taille du fichier journal des transactions.
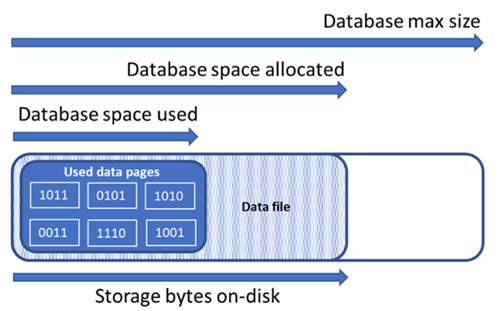
Appréhender les types d’espace de stockage d’une base de données
Comprendre les quantités d’espace de stockage suivantes est importante pour gérer l’espace de fichier d’une base de données.
| Quantité pour une base de données | Définition | Commentaires |
|---|---|---|
| Espace de données utilisé | Quantité d’espace utilisée pour stocker les données de la base de données. | En général, l’espace utilisé augmente (diminue) lors des insertions (suppressions). Dans certains cas, l’espace utilisé ne change pas sur les insertions ou les suppressions en fonction de la quantité et du modèle de données impliqués dans l’opération et toute fragmentation. Par exemple, la suppression d’une ligne dans chaque page de données ne diminue pas forcément l’espace utilisé. |
| Espace de données alloué | La quantité d’espace de fichiers formatés mise à disposition pour stocker les données de la base de données. | La quantité d’espace allouée augmente automatiquement, mais ne diminue jamais après les suppressions. Ce comportement garantit que les insertions futures sont plus rapides, car l’espace n’a pas besoin d’être reformaté. |
| Espace de données alloué mais non utilisé | La différence entre la quantité d’espace de données allouée et la quantité d’espace de données utilisée. | Cette quantité représente la quantité maximale d’espace libre qui peut être récupérée par la réduction des fichiers de données de la base de données. |
| Taille maximale des données | La quantité maximale d’espace qui peut être utilisée pour le stockage des données de la base de données. | La quantité d’espace de données allouée ne peut pas croître au-delà de la taille maximale des données. |
Le schéma suivant illustre la relation entre les différents types d’espace de stockage d’une base de données.
Interroger une base de données unique pour des informations relatives à l’espace de stockage des fichiers
Utilisez la requête suivante sur sys.database_files pour retourner la quantité d’espace de données allouée de la base de données et la quantité d’espace alloué non utilisé. Le résultat de la requête est exprimé en Mo.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Surveiller l’utilisation de l’espace pour le journal
Surveillez l’utilisation de l’espace pour le journal à l’aide de sys.dm_db_log_space_usage. Cette vue de gestion dynamique retourne des informations sur la quantité d’espace journal utilisée et indique à quel moment le journal des transactions a besoin d’être tronqué.
Pour plus d’informations sur la taille actuelle du fichier journal, sa taille maximale et l’option de croissance automatique pour le fichier, utilisez les colonnes et growth les sizemax_sizecolonnes de ce fichier journal dans sys.database_files.
Les mesures d’espace de stockage affichées dans les API de mesures basées sur Azure Resource Manager ne mesurent que la taille des pages de données utilisées. Pour obtenir des exemples, consultez PowerShell Get-AZMetric.
Réduire la taille du fichier journal
Pour réduire la taille physique d’un fichier journal physique en supprimant de l’espace inutilisé, vous devez réduire le fichier journal. Une réduction ne fait une différence que lorsqu’un fichier journal de transactions contient un espace inutilisé. Si le fichier journal est plein, probablement en raison de transactions ouvertes, examinez les causes du blocage de la troncation du journal des transactions.
Attention
Les opérations de réduction ne doivent pas être considérées comme une opération de maintenance régulière. Les fichiers de données et de journaux qui augmentent en raison d’opérations métier régulières et récurrentes ne nécessitent pas d’opérations de réduction. Les commandes de réduction ont un impact sur les performances de la base de données pendant l’exécution et, si possible, doivent être exécutées pendant les périodes de faible utilisation. La réduction des fichiers de données n’est pas recommandée si la charge de travail de l’application régulière entraîne la croissance des fichiers vers la même taille allouée.
Tenez compte de l’impact potentiel sur les performances négatives de la réduction des fichiers de base de données. Pour plus d’informations, consultez maintenance d’index après réduction. Dans de rares cas, les sauvegardes de base de données automatisées peuvent affecter les opérations de réduction. Si nécessaire, réessayez l’opération de réduction.
Avant de réduire le journal des transactions, gardez à l’esprit les facteurs qui peuvent retarder la troncation du journal. Si l’espace de stockage est de nouveau nécessaire après une réduction du journal, le journal des transactions augmente à nouveau et, en procédant ainsi, introduit une surcharge de performances pendant les opérations de croissance des journaux. Pour plus d’informations, consultez la section recommandations .
Vous pouvez réduire un fichier journal uniquement quand la base de données est en ligne, et qu’au moins un fichier journal virtuel est libre. Dans certains cas, la réduction du journal peut n'être possible qu'après la troncation de journal suivante.
Certains facteurs (par exemple, une transaction longue) peuvent maintenir les fichiers journaux virtuels actifs pendant une période de temps prolongée, et peuvent limiter, voire empêcher, la réduction du journal. Pour plus d’informations, consultez Facteurs pouvant retarder la troncation du journal.
La réduction d’un fichier journal supprime un ou plusieurs fichiers journaux virtuels qui ne contiennent aucune partie du journal logique (autrement dit, des fichiers journaux virtuels inactifs). Quand vous réduisez un fichier journal de transactions, les fichiers journaux virtuels inactifs sont supprimés de la fin du fichier journal pour réduire le journal et le ramener à une taille proche de la taille cible.
Pour plus d’informations sur les opérations de réduction, consultez la documentation suivante :
Réduire un fichier journal (sans réduire les fichiers de base de données)
Surveiller les événements de réduction du fichier journal
Contrôler l’espace pour le journal
sys.database_files (Transact-SQL) (reportez-vous aux colonnes
size,max_size, etgrowthdu fichier journal ou des fichiers journaux.)
Maintenance des index après réduction
Une fois que l’opération de réduction est effectuée sur les fichiers de données, les index peuvent devenir fragmentés. La fragmentation réduit l’efficacité de l’optimisation des performances d’un index pour certaines charges de travail, telles que les requêtes utilisant des analyses volumineuses. Si la dégradation des performances se produit une fois l’opération de réduction terminée, envisagez la maintenance des index pour reconstruire les index. N’oubliez pas que les reconstructions d’index demandent de l’espace libre dans la base de données, ce qui peut entraîner une augmentation de l’espace alloué et donc un affaiblissement de l’effet de réduction.
Pour plus d’informations sur la maintenance des index, consultez Optimiser la maintenance des index pour améliorer les performances des requêtes et réduire la consommation des ressources.
Évaluer la densité des pages d’index
Si la troncation des fichiers de données n’entraîne pas une réduction suffisante de l’espace alloué, vous pouvez décider de réduire les fichiers de données de base de données pour récupérer de l’espace inutilisé à partir de ces fichiers. Toutefois, à titre d’étape facultative mais recommandée, vous devez d’abord déterminer la densité moyenne des pages des index dans la base de données. Pour la même quantité de données, la réduction se termine plus rapidement si la densité de page est élevée, car elle déplace moins de pages. Si la densité des pages est faible pour certains index, effectuez une maintenance sur ces index pour augmenter la densité des pages avant de réduire les fichiers de données. Cette étape permet de réduire davantage l’espace de stockage alloué.
Pour déterminer la densité des pages de tous les index de la base de données, utilisez la requête suivante. La densité des pages est signalée dans la colonne avg_page_space_used_in_percent.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Si vous avez des index avec un nombre de pages élevé et avec une densité de page inférieure à 60-70 %, prévoyez de reconstruire ou de réorganiser ces index avant de réduire les fichiers de données.
Remarque
Pour les grandes bases de données, la requête pour déterminer la densité de page peut prendre un certain temps (plusieurs heures). De plus, la reconstruction ou la réorganisation de grands index demandent aussi un temps et une utilisation des ressources considérables. Il y a un compromis entre passer du temps supplémentaire sur l’augmentation de la densité de page d’une part, et réduire la durée de réduction et réaliser des économies d’espace plus élevées sur une autre.
Si vous avez plusieurs index avec une faible densité de page, vous pourrez peut-être les reconstruire en parallèle sur plusieurs sessions de base de données pour accélérer le processus. Toutefois, assurez-vous que vous n’approchez pas des limites de ressources de base de données et laissez suffisamment de ressources dans les charges de travail d’application. Surveillez la consommation des ressources (PROCESSEUR, E/S de données, E/S de journal) dans le portail Azure ou à l’aide de la vue sys.dm_db_resource_stats . Démarrez d’autres reconstructions parallèles uniquement si l’utilisation des ressources sur chacune de ces dimensions reste sensiblement inférieure à 100%. Si l’utilisation du processeur, des E/S de données ou des E/S de journal est de 100%, vous pouvez effectuer un scale-up de la base de données pour avoir plus de cœurs d’UC et augmenter le débit d’E/S, ce qui permet d’effectuer plus rapidement des reconstructions parallèles.
Exemple de commande de reconstruction d’index
Voici un exemple de commande pour reconstruire un index et augmenter la densité de ses pages, en utilisant l’instruction ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Cette commande lance une reconstruction d’index en ligne et reprenable. Ce type de reconstruction permet aux charges de travail simultanées de continuer à utiliser la table pendant que la reconstruction est en cours et vous permet de reprendre la reconstruction si elle est interrompue pour une raison quelconque. Toutefois, ce type de reconstruction est plus lent qu’une reconstruction hors connexion, qui bloque l’accès à la table. Si aucune autre charge de travail n’a besoin d’accéder à la table pendant la reconstruction, définissez les options ONLINE et RESUMABLE sur OFF pour supprimer la clause WAIT_AT_LOW_PRIORITY.
Pour en savoir plus sur la maintenance des index, consultez Optimiser la maintenance des index pour améliorer les performances des requêtes et réduire la consommation des ressources.
Réduire plusieurs fichiers de données
Comme indiqué précédemment, une réduction avec un déplacement des données est un processus de longue haleine. Si la base de données contient plusieurs fichiers de données, vous pouvez accélérer le processus en réduisant plusieurs fichiers de données en parallèle. Vous effectuez cette opération en ouvrant plusieurs sessions de base de données et en utilisant DBCC SHRINKFILE sur chaque session avec une valeur différente file_id . Tout comme avec la reconstruction des index vue précédemment, assurez-vous d’avoir suffisamment de marge de ressources (processeur, E/S de données, E/S de journal) avant de commencer chaque nouvelle commande de réduction parallèle.
L’exemple de commande suivant réduit le fichier de données avec file_id 4, en tentant de réduire la taille allouée à 52 000 Mo en déplaçant les pages au sein du fichier :
DBCC SHRINKFILE (4, 52000);
Si vous voulez réduire au minimum possible l’espace alloué au fichier, exécutez l’instruction sans spécifier la taille cible :
DBCC SHRINKFILE (4);
Si une charge de travail s’exécute en même temps qu’une réduction, elle peut commencer à utiliser l’espace de stockage libéré par la réduction avant que la réduction ne se termine et tronque le fichier. Dans ce cas, la réduction ne peut pas réduire l’espace alloué à la cible spécifiée.
Vous pouvez atténuer ce problème en réduisant chaque fichier en étapes plus petites. Cela signifie que dans la commande DBCC SHRINKFILE, vous définissez une cible légèrement plus petite que l’espace actuellement alloué au fichier. Par exemple, si l’espace alloué à un fichier avec file_id 4 est de 200 000 Mo et que vous voulez le réduire à 100 000 Mo, vous pouvez d’abord définir la cible sur 170 000 Mo :
DBCC SHRINKFILE (4, 170000);
Une fois cette commande terminée, elle tronque le fichier et réduit sa taille allouée à 170 000 Mo. Vous pouvez ensuite répéter cette commande, définir la cible d’abord sur 140 000 Mo, puis atteindre 110 000 Mo, et ainsi de suite, jusqu’à ce que le fichier soit réduit à la taille souhaitée. Si la commande se termine mais que le fichier n’est pas tronqué, utilisez des étapes plus petites, par exemple 15 000 Mo plutôt que 30 000 Mo.
Pour surveiller la progression de la réduction de toutes les sessions de réduction exécutées en simultané, vous pouvez utiliser la requête suivante :
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Remarque
La progression de la réduction peut être non linéaire et la valeur de la percent_complete colonne peut rester inchangée pendant de longues périodes, même si la réduction est toujours en cours.
Une fois la réduction terminée pour tous les fichiers de données, utilisez la requête d’utilisation de l’espace pour déterminer la réduction résultante de la taille de stockage allouée. S’il existe toujours une grande différence entre l’espace utilisé et l’espace alloué, vous pouvez reconstruire des index. La reconstruction peut augmenter temporairement davantage l’espace alloué, mais la réduction des fichiers de données après la reconstruction des index doit entraîner une réduction plus profonde de l’espace alloué.
Agrandir un fichier journal
Dans Azure SQL Managed Instance, vous pouvez ajouter de l’espace à un fichier journal en agrandissant le fichier journal existant, si l’espace disque le permet. L’ajout d’un fichier journal à la base de données n’est pas pris en charge. Un fichier journal des transactions suffit, sauf si l’espace journal est insuffisant et que l’espace disque est également insuffisant sur le volume qui contient le fichier journal.
Pour agrandir le fichier journal, utilisez la MODIFY FILE clause de l’instruction ALTER DATABASE et spécifiez la syntaxe et MAXSIZE la SIZE syntaxe. Pour plus d’informations, consultez Options de fichiers et de groupes de fichiers ALTER DATABASE (Transact-SQL).
Pour plus d’informations, consultez les Recommandations.
Contrôler la croissance d’un fichier journal de transactions
Pour gérer la croissance d’un fichier journal des transactions, utilisez l’instruction ALTER DATABASE (Transact-SQL) File and Filegroup options . Notez les options suivantes :
- Utilisez l’option
SIZEpour modifier la taille de fichier actuelle en unités Ko, Mo, Go et To. - Utilisez l’option pour modifier l’incrément
FILEGROWTHde croissance. Une valeur 0 indique que la croissance automatique est désactivée et qu'aucun espace supplémentaire n'est autorisé. - Utilisez l’option
MAXSIZEpour contrôler la taille maximale d’un fichier journal en unités Ko, Mo, Go et To ou pour définir la croissanceUNLIMITEDsur .
Recommandations
Lorsque vous utilisez des fichiers journaux des transactions, tenez compte des recommandations suivantes :
Définissez l’incrément de croissance automatique (croissance automatique) du journal des transactions, tel que configuré par l’option
FILEGROWTH, pour être suffisamment volumineux pour répondre aux besoins de vos transactions de charge de travail. Augmentez la croissance du fichier sur un fichier journal suffisamment volumineux pour éviter une expansion fréquente. Vous pouvez correctement dimensionner un journal des transactions en surveillant la quantité de journaux occupé pendant :- Temps nécessaire pour exécuter une sauvegarde complète, car les sauvegardes de journaux ne peuvent pas se produire tant qu’elles ne sont pas terminées.
- Le temps nécessaire pour les opérations de maintenance des index les plus volumineux
- Le temps nécessaire pour exécuter le lot le plus volumineux dans une base de données
Définissez la croissance automatique pour les fichiers de données et de journaux à l’aide de l’option
FILEGROWTHausizelieu depercentage, pour permettre un meilleur contrôle du ratio de croissance, car le pourcentage est une quantité toujours croissante.- Dans Azure SQL Managed Instance, l’initialisation instantanée de fichiers peut bénéficier d’événements de croissance du journal des transactions allant jusqu’à 64 Mo. L’incrément de taille de croissance automatique par défaut pour les nouvelles bases de données est de 64 Mo. Les événements de croissance automatique du fichier journal de transactions d'une taille supérieure à 64 Mo ne peuvent pas bénéficier de l'initialisation instantanée de fichier.
- En guise de bonne pratique, ne définissez pas la
FILEGROWTHvaleur d’option supérieure à 1 024 Mo pour les journaux des transactions.
Évitez de définir un petit incrément de croissance automatique, car il peut générer trop de petites VLF et réduire les performances. Pour déterminer la distribution optimale des fichiers journaux virtuels pour la taille actuelle du journal des transactions de toutes les bases de données dans une instance donnée, ainsi que les incréments de croissance pour atteindre la taille nécessaire, consultez ce script pour analyser et corriger les fichiers journaux virtuels, fourni par la SQL Tiger Team.
Évitez de définir un incrément de croissance automatique volumineuse, car il peut entraîner deux problèmes :
- La base de données peut s’interrompre pendant que le nouvel espace est alloué, ce qui peut entraîner des délais d’attente de requête.
- Il peut générer trop peu et trop grand VLF et peut également affecter les performances. Pour déterminer la distribution optimale des fichiers journaux virtuels pour la taille actuelle du journal des transactions de toutes les bases de données dans une instance donnée, ainsi que les incréments de croissance pour atteindre la taille nécessaire, consultez ce script pour analyser et corriger les fichiers journaux virtuels, fourni par la SQL Tiger Team.
Même si la croissance automatique est activée, vous pouvez recevoir un message indiquant que le journal des transactions est plein s’il ne peut pas croître suffisamment rapidement pour répondre aux besoins de votre requête. Pour plus d’informations sur le changement de l’incrément de croissance, consultez Options de fichiers et de groupes de fichiers ALTER DATABASE (Transact-SQL).
Vous pouvez définir les fichiers journaux pour réduire automatiquement. Toutefois, cette pratique n’est pas recommandée et la propriété de base de données auto_shrink a la valeur FALSE par défaut. Si vous définissez auto_shrink sur TRUE, la réduction automatique réduit la taille d’un fichier uniquement lorsque plus de 25 % de son espace n’est pas utilisé.
- Le fichier est réduit à la taille à laquelle seulement 25 % du fichier n’est pas utilisé ou réduit à la taille d’origine du fichier, selon la taille la plus grande.
- Pour plus d’informations sur la modification du paramètre de la propriété auto_shrink, consultez Afficher ou modifier les propriétés d’une base de données et Options ALTER DATABASE SET (Transact-SQL).