Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() Azure SQL Managed Instance
Azure SQL Managed Instance
La réplication transactionnelle est une fonctionnalité d’Azure SQL Managed Instance et de SQL Server qui vous permet de répliquer les données d’une table dans Azure SQL Managed Instance ou d’une instance SQL Server dans des tables placées dans des bases de données distantes. Cette fonctionnalité vous permet de synchroniser plusieurs tables dans différentes bases de données.
Vue d’ensemble
Vous pouvez utiliser la réplication transactionnelle pour transmettre les modifications apportées à une instance gérée Azure SQL à :
- Une base de données SQL Server (locale ou sur une machine virtuelle Azure)
- Une base de données dans Azure SQL Database
- Une base de données dans Azure SQL Managed Instance
Notes
Pour bénéficier de toutes les fonctionnalités d’Azure SQL Managed Instance, vous devez utiliser les dernières versions de SQL Server Management Studio (SSMS) et de SQL Server Data Tools (SSDT).
Composants
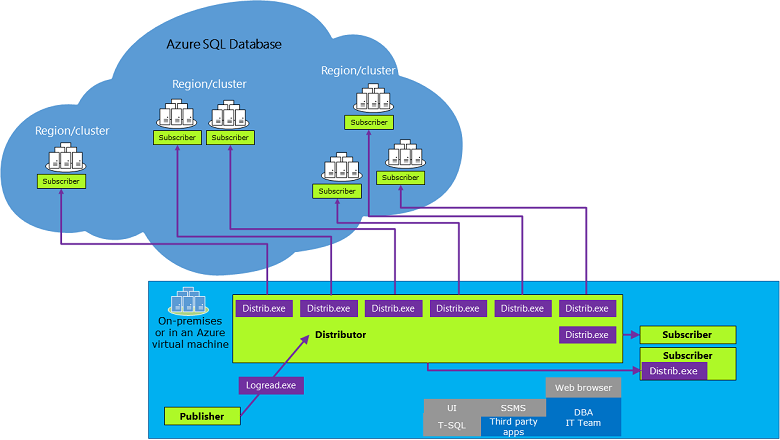
Les principaux composants de la réplication transactionnelle sont la base de données du serveur de publication, la base de données du serveur de distribution et l’abonné, comme indiqué dans l’image suivante :
| Rôle | Azure SQL Database | Azure SQL Managed Instance (Instance gérée Azure SQL) |
|---|---|---|
| Éditeur | Non | Oui |
| Serveur de distribution | Non | Oui |
| Abonné de type pull | Non | Oui |
| Abonné de type push | Oui | Oui |
La base de données du serveur de publication publie les changements apportés à certaines tables (articles) en envoyant les mises à jour à la base de données du serveur de distribution. La base de données du serveur de publication peut être une instance gérée Azure SQL ou une instance SQL Server.
La base de données du serveur de distribution collecte les changements apportés aux articles à partir d’une base de données du serveur de publication et les distribue aux Abonnés. Le Distributeur peut être une instance gérée par Azure SQL ou une instance de SQL Server (n'importe quelle version pourvu qu'elle soit égale ou supérieure à la version de l'Éditeur).
L’abonné reçoit les modifications apportées sur la base de données du serveur de publication. Une instance SQL Server et une instance gérée Azure SQL peuvent être des abonnés d’envoi (push) et d’extraction (pull), bien qu’un abonnement par extraction ne soit pas pris en charge quand la base de données du serveur de distribution est une instance gérée Azure SQL et que l’abonné n’en est pas une. Une base de données dans Azure SQL Database peut uniquement être un abonné par envoi.
Azure SQL Managed Instance peut prendre en charge le fait d’être un abonné des versions suivantes de SQL Server :
- SQL Server 2016 et versions ultérieures
- SQL Server 2014 RTM CU10 (12.0.4427.24) ou SP1 CU3 (12.0.2556.4)
- SQL Server 2012 SP2 CU8 (11.0.5634.1), SP3 (11.0.6020.0) ou SP4 (11.0.7001.0)
Notes
Pour les autres versions de SQL Server qui ne prennent pas en charge la publication sur des objets dans Azure, vous pouvez utiliser la méthode de republication des données pour déplacer des données vers des versions plus récentes de SQL Server.
Si vous configurez la réplication avec une version antérieure, les erreurs suivantes peuvent se produire : MSSQL_REPL20084 (Le processus n’a pas pu se connecter à l’abonné) et MSSQL_REPL40532 (Impossible d’ouvrir le serveur <nom> demandé par la connexion. Échec de la connexion).
Types de réplication
Il existe différents types de réplications :
| Réplication | Azure SQL Database | Azure SQL Managed Instance (Instance gérée Azure SQL) |
|---|---|---|
| Transactionnelle standard | Oui (uniquement en tant qu’Abonné) | Oui |
| Capture instantanée | Oui (uniquement en tant qu’Abonné) | Oui |
| Réplication de fusion | Non | Non |
| Pair à pair | Non | Non |
| Bidirectionnelle | Non | Oui |
| Abonnements pouvant être mis à jour | Non | Non |
Matrice de prise en charge
La matrice de prise en charge de la réplication transactionnelle et d’instantané pour Azure SQL Managed Instance est identique à celle de SQL Server :
| Éditeur | Serveur de distribution | Abonné |
|---|---|---|
| Azure SQL Managed InstanceAUTD | Azure SQL Managed InstanceAUTD | Base de données Azure SQL Azure SQL Managed InstanceAUTD Azure SQL Managed Instance2022 SQL Server 2022 (16.x) SQL Server 2019 (15.x) |
| Azure SQL Managed Instance2022 | Azure SQL Managed InstanceAUTD Azure SQL Managed Instance2022 |
Base de données Azure SQL Azure SQL Managed InstanceAUTD Azure SQL Managed Instance2022 SQL Server 2022 (16.x) SQL Server 2019 (15.x) SQL Server 2017 (14.x) |
| SQL Server 2022 (16.x) | SQL Server 2022 (16.x) | Base de données Azure SQL Base de données SQL dans Microsoft Fabric1 Azure SQL Managed InstanceAUTD Azure SQL Managed Instance2022 SQL Server 2022 (16.x) SQL Server 2019 (15.x) SQL Server 2017 (14.x) |
| SQL Server 2019 (15.x) | SQL Server 2022 (16.x) SQL Server 2019 (15.x) |
Azure SQL Database Azure SQL Managed InstanceAUTD Azure SQL Managed Instance2022 SQL Server 2022 (16.x) SQL Server 2019 (15.x) SQL Server 2017 (14.x) SQL Server 2016 (13.x) |
| SQL Server 2017 (14.x) | SQL Server 2022 (16.x) SQL Server 2019 (15.x) SQL Server 2017 (14.x) |
Azure SQL Managed Instance2022 SQL Server 2022 (16.x) SQL Server 2019 (15.x) SQL Server 2017 (14.x) SQL Server 2016 (13.x) SQL Server 2014 (12.x) |
| SQL Server 2016 (13.x) | SQL Server 2022 (16.x) SQL Server 2019 (15.x) SQL Server 2017 (14.x) SQL Server 2016 (13.x) |
SQL Server 2019 (15.x) SQL Server 2017 (14.x) SQL Server 2016 (13.x) SQL Server 2014 (12.x) SQL Server 2012 (11.x) |
| SQL Server 2014 (12.x) | SQL Server 2022 (16.x) SQL Server 2019 (15.x) SQL Server 2017 (14.x) SQL Server 2016 (13.x) SQL Server 2014 (12.x) |
SQL Server 2017 (14.x) SQL Server 2016 (13.x) SQL Server 2014 (12.x) SQL Server 2012 (11.x) SQL Server 2008 R2 (10.50.x) SQL Server 2008 (10.0.x) |
| SQL Server 2012 (11.x) | SQL Server 2022 (16.x) SQL Server 2019 (15.x) SQL Server 2017 (14.x) SQL Server 2016 (13.x) SQL Server 2014 (12.x) SQL Server 2012 (11.x) |
SQL Server 2016 (13.x) SQL Server 2014 (12.x) SQL Server 2012 (11.x) SQL Server 2008 R2 (10.50.x) SQL Server 2008 (10.0.x) |
| SQL Server 2008 R2 (10.50.x) SQL Server 2008 (10.0.x) |
SQL Server 2022 (16.x) SQL Server 2019 (15.x) SQL Server 2017 (14.x) SQL Server 2016 (13.x) SQL Server 2014 (12.x) SQL Server 2012 (11.x) SQL Server 2008 R2 (10.50.x) SQL Server 2008 (10.0.x) |
SQL Server 2014 (12.x) SQL Server 2012 (11.x) SQL Server 2008 R2 (10.50.x) SQL Server 2008 (10.0.x) |
2022 s'applique à Azure SQL Managed Instance configurée avec la stratégie de mise à jour SQL Server 2022.
AUTD s’applique à Azure SQL Managed Instance configuré avec la stratégie de mise à jour Always-up-to-date (Mise à jour automatique).
1 S’applique en fonction des exigences des configurations prises en charge pour la base de données SQL dans Microsoft Fabric.
Quand l’utiliser
La réplication transactionnelle est utile dans les scénarios suivants :
- Publier les changements apportés dans une ou plusieurs tables d’une base de données et les distribuer à une ou plusieurs bases de données dans une instance de SQL Server ou Azure SQL Database abonnées aux changements.
- Maintenir plusieurs bases de données distribuées dans un état synchronisé.
- Migrer des bases de données d’une instance de SQL Server ou d’une instance managée Azure SQL vers une autre base de données en publiant les modifications en continu.
Comparaison entre Data Sync et la réplication transactionnelle
| Catégorie | Synchronisation des données | Réplication transactionnelle |
|---|---|---|
| Avantages | - Support actif/actif - Synchronisation bidirectionnelle entre la base de données Azure SQL et locale |
- Latence réduite - Cohérence transactionnelle - Réutilisation de la topologie existante après la migration |
| Inconvénients | - Pas de cohérence transactionnelle - Impact plus important sur les performances |
- Impossible de publier à partir d’Azure SQL Database - Coût de maintenance élevé |
Configurations courantes
En règle générale, le serveur de publication et le serveur de distribution doivent se trouver dans le cloud ou en local. Les configurations suivantes sont prises en charge :
Base de données du serveur de publication avec une base de données du serveur de distribution locale sur SQL Managed Instance
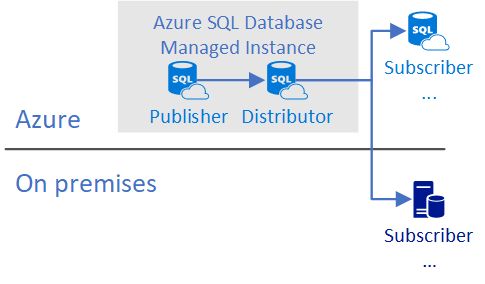
La base de données du serveur de publication et la base de données du serveur de distribution sont configurées dans une même instance gérée SQL, et les changements sont distribués à une autre instance gérée SQL, base de données SQL ou instance SQL Server.
Base de données du serveur de publication avec base de données du serveur de distribution distante sur SQL Managed Instance
Dans cette configuration, une instance gérée SQL publie les changements dans une base de données du serveur de distribution placée sur une autre instance gérée SQL qui peut servir plusieurs instances gérées SQL sources et distribuer les changements à une ou plusieurs cibles sur Azure SQL Database, Azure SQL Managed Instance ou SQL Server.
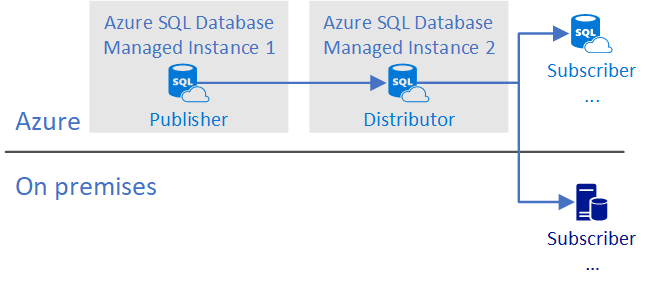
Le serveur de publication et le serveur de distribution sont configurés sur deux instances managées. Il existe des contraintes avec cette configuration :
- Les deux instances managées sont sur le même réseau virtuel.
- Les deux instances managées se trouvent au même emplacement.
Base de données du serveur de publication/distribution locale avec abonné distant
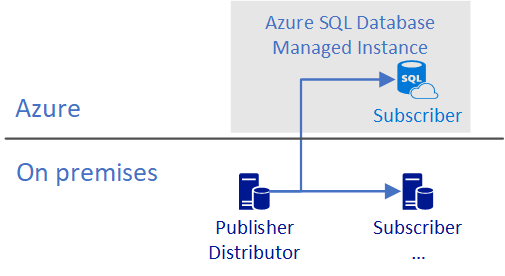
Dans cette configuration, une base de données dans Azure SQL Database ou Azure SQL Managed Instance est un abonné. Cette configuration prend en charge la migration de données locales vers Azure. Si un abonné est une base de données dans Azure SQL Database, il doit être en mode push.
Spécifications
- Utiliser l’authentification SQL pour la connectivité entre les participants de la réplication
- Utiliser un partage de compte Stockage Azure pour le répertoire de travail utilisé par la réplication
- Ouvrir le port TCP 445 sortant dans les règles de sécurité de sous-réseau pour accéder au partage de fichiers Azure
- Ouvrez le port TCP 1433 sortant quand la base de données du serveur de publication/distribution est une instance gérée SQL et que l’abonné n’en est pas une. Il vous faudra peut-être aussi modifier la règle de sécurité de trafic sortant du groupe de sécurité réseau de l’instance gérée SQL pour
allow_linkedserver_outboundpour l’Étiquette Service de destination du port 1433 en remplaçantvirtualnetworkparinternet. - Placer les bases de données du serveur de publication et de distribution dans le cloud, ou toutes les deux localement
- Configurer le peering VPN entre les réseaux virtuels des participants de réplication si les réseaux virtuels sont différents
Notes
Vous pouvez rencontrer l’erreur 53 lors de la connexion à un fichier Stockage Azure si le port 445 du groupe de sécurité réseau sortant est bloqué quand la base de données du serveur de distribution est une base de données Azure SQL Managed Instance et que l’abonné est local. Pour résoudre ce problème, mettez à jour le NSG vNet.
Sécurité
Prise en charge du protocole TLS 1.3
Azure SQL Managed Instance prend en charge TLS 1.3 pour les connexions de réplication initialisées par les agents configurés pour s’exécuter sur une instance managée SQL. Cela s’applique à une topologie de réplication entre deux instances managées SQL, ainsi qu’à n’importe quelle version de SQL Server en tant qu’abonné à partir d’un serveur de publication et d’un serveur de distribution d’instance managée SQL.
Si vous utilisez TLS 1.3 pour sécuriser les connexions entre les instances d’une topologie de réplication, spécifiez la valeur 3 ou 4 pour le paramètre -EncryptionLevel de chaque agent de réplication :
Une valeur de 3 impose des connexions TLS 1.3 entre les instances managées SQL, mais n’a aucun impact sur les connexions entre SQL Server et les instances managées SQL. Une valeur de 4 impose les connexions TLS 1.3 entre les instances managées SQL, ainsi que depuis une instance managée SQL vers SQL Server, et nécessite que vous installiez le certificat sur l’hôte SQL Server.
Connectez-vous à l’adresse replAgentUser
À des fins de réplication transactionnelle, une SQL Managed Instance a une ou plusieurs connexions précréées avec le nom replAgentUser. Cette connexion est membre du rôle serveur sysadmin et est utilisée par les agents de réplication qui doivent se connecter à une SQL Managed Instance participant à l’installation de la réplication transactionnelle.
Si la réplication transactionnelle n’est pas utilisée, la connexion replAgentUser peut être désactivée. Elle peut être réactivée ultérieurement si vous décidez de commencer à utiliser la réplication transactionnelle.
Limites
La réplication transactionnelle présente certaines limitations spécifiques à Azure SQL Managed Instance. Pour en savoir plus sur ces limitations, consultez cette section.
Les fichiers d’instantanés ne sont pas supprimés du compte de stockage Azure
Azure SQL Managed Instance utilise un compte de stockage Azure configuré par l’utilisateur pour les fichiers d’instantanés utilisés pour la réplication transactionnelle. Contrairement à SQL Server dans l’environnement local, Azure SQL Managed Instance ne supprime pas les fichiers d’instantanés du compte de stockage Azure. Une fois que les fichiers ne sont plus nécessaires, vous devez les supprimer. Pour ce faire, utilisez l’interface du stockage Azure sur le portail Azure, Explorateur Stockage Microsoft Azure, ou des clients de ligne de commande (Azure PowerShell ou CLI) ou l’API REST de gestion du stockage Azure.
Voici un exemple de la façon dont vous pouvez supprimer un fichier et comment supprimer un dossier vide.
az storage file delete-batch --source <file_path> --account-key <account_key> --account-name <account_name>
az storage directory delete --name <directory_name> --share-name <share_name> --account-key <account_key> --account-name <account_name>
Nombre d’agents de distribution en cours d’exécution continue
Le nombre d’agents de distribution configurés pour s’exécuter en continu est limité à 30 sur Azure SQL Managed Instance. Pour avoir plus d’agents de distribution, ils doivent être exécutés à la demande ou avec une planification définie. La planification peut être définie avec une fréquence et une occurrence quotidiennes toutes les 10 secondes (ou plus), par conséquent, même si elle n’est pas continue, vous pouvez toujours avoir un serveur de distribution qui introduit une latence de quelques secondes seulement. Lorsqu’un grand nombre de bases de données du serveur de distribution est nécessaire, il est recommandé d’utiliser une configuration planifiée et non continue.
Avec les groupes de basculement
L’utilisation de la réplication transactionnelle avec des instances qui se trouvent dans un groupe de basculement est prise en charge. Toutefois, si vous configurez la réplication avant d’ajouter votre instance gérée SQL dans un groupe de basculement, la réplication s’interrompt lorsque vous commencez à créer votre groupe de basculement, et le moniteur de réplication affiche l’état Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. La réplication reprend une fois le groupe de basculement créé.
Si une instance gérée SQL de publication ou de distribution se trouve dans un groupe de basculement, l’administrateur de l’instance gérée SQL doit nettoyer toutes les publications de l’ancienne instance principale et les reconfigurer sur la nouvelle instance principale après un basculement. Les activités suivantes sont nécessaires dans ce scénario :
Arrêtez tous les travaux de réplication en cours d’exécution sur la base de données, le cas échéant.
Supprimez les métadonnées d’abonnement du serveur de publication en exécutant le script suivant sur la base de données du serveur de publication. Remplacez les valeurs de
<name of publication>et<name of subscriber>:EXEC sp_dropsubscription @publication = '<name of publication>', @article = 'all', @subscriber = '<name of subscriber>'Supprimez les métadonnées d’abonnement de l’abonné. Exécutez le script suivant sur la base de données d’abonnement sur l’instance gérée SQL de l’abonné. Remplacez la valeur de
<full DNS of publisher>. Par exemple,example.ac2d23028af5.database.windows.net:EXEC sp_subscription_cleanup @publisher = N'<full DNS of publisher>', @publisher_db = N'<publisher database>', @publication = N'<name of publication>';Supprimez définitivement tous les objets de réplication du serveur de publication en exécutant le script suivant dans la base de données publiée :
EXEC sp_removedbreplication;Supprimez définitivement l’ancienne base de données du serveur de distribution de l’instance gérée SQL principale d’origine (en cas de basculement vers une ancienne instance principale qui utilisait une base de données du serveur de distribution). Exécutez le script suivant sur la base de données
mastersur l’ancienne instance gérée SQL de la base de données du serveur de distribution :EXEC sp_dropdistributor 1, 1;
Si une instance gérée SQL abonnée fait partie d’un groupe de basculement, la publication doit être configurée pour se connecter au point de terminaison de l’écouteur du groupe de basculement pour l’instance gérée SQL abonnée. En cas de basculement, l’action suivante de l’administrateur de l’instance gérée SQL dépend du type de basculement qui s’est produit :
- Pour un basculement sans perte de données, la réplication continue de fonctionner après le basculement.
- Pour un basculement avec perte de données, la réplication fonctionne également. Elle réplique à nouveau les modifications perdues.
- Pour un basculement avec perte de données, mais où la perte de données est en dehors de la période de conservation de la base de données de distribution, l’administrateur de l’instance gérée SQL doit réinitialiser la base de données d’abonnement.
Résoudre des problèmes courants
Journal des transactions et réplication transactionnelle
Dans des circonstances habituelles, le journal des transactions est utilisé pour enregistrer les modifications des données dans une base de données. Les modifications sont enregistrées dans le journal des transactions, ce qui fait augmenter la consommation de stockage des journaux. Il existe également un processus automatique qui permet un tronquage sécurisée du journal des transactions, et ce processus réduit l’espace de stockage utilisé pour le journal. Lorsque la publication pour la réplication transactionnelle est configurée, le tronquage du journal des transactions est empêchée jusqu'à ce que les modifications du journal soient traitées par le travail de lecture du journal. Dans certaines circonstances, le traitement du journal des transactions est effectivement bloqué et cet état peut entraîner le remplissage de l’intégralité du stockage réservé pour le journal des transactions. Lorsqu'il n'y a plus d'espace libre pour le journal des transactions et qu'il n'y a plus d'espace pour que le journal des transactions se développe, le journal des transactions devient complet. Dans cet état, la base de données ne peut plus traiter de charge de travail d’écriture et devient une base de données en lecture seule.
Agent de lecture du journal désactivé
Parfois, la publication de réplication transactionnelle est configurée pour une base de données, mais l’agent de lecture du journal n’est pas configuré pour s’exécuter. Dans ce cas, les modifications s’accumulent dans le journal des transactions et ne sont pas traitées. Cela conduit à une croissance constante du journal des transactions, et finalement au journal des transactions complet. L’utilisateur doit s’assurer que le travail de lecteur de journal existe et qu’il est actif. L’alternative consiste à désactiver la réplication transactionnelle, si elle n’est pas nécessaire.
Délais d’expiration des requêtes de l’agent de lecture du journal
Parfois, le travail du lecteur de journal ne peut pas progresser efficacement en raison de délais d’attente de requête répétés. Un moyen de corriger les délais d’expiration des requêtes consiste à augmenter le paramètre de délai d’expiration de requête pour le travail de l’agent de lecture du journal.
L’augmentation du délai d’expiration des requêtes pour le projet de lecteur de journaux d’activité peut être effectuée avec SSMS. Dans l’Explorateur d’objets, sous SQL Server Agent, recherchez le projet que vous souhaitez modifier. Commencez par l’arrêter, puis ouvrez ses propriétés. Recherchez step 2 et modifiez-le. Ajoutez la valeur de commande avec -QueryTimeout <timeout_in_seconds>. Pour la valeur de délai d’expiration de la requête, essayez 21600 ou version ultérieure. Enfin, recommencez le projet.
La taille de stockage des journaux d’activité a atteint la limite maximale de 2 To
Lorsque la taille de stockage du journal des transactions atteint la limite maximale, qui est de 2 To, le journal ne peut pas augmenter physiquement plus que cela. Dans ce cas, la seule prévention disponible consiste à marquer toutes les transactions qui doivent être répliquées comme traitées, afin d’autoriser la troncation du journal des transactions. Cela signifie efficacement que les transactions restantes dans le journal d’activité ne seront pas répliquées et que vous devez réinitialiser la réplication.
Notes
Après avoir effectué une prévention, vous devez réinitialiser la réplication, ce qui signifie que la réplication complète du jeu de données est réinitialisé. Il s’agit d’une taille d’opération de données, qui peut être longue, en fonction de la quantité de données qui doivent être répliquées.
Pour effectuer la prévention, vous devez d’abord arrêter l’agent de lecture de journaux d’activité sur le distributeur. Ensuite, vous devez exécuter la procédure stockée sp_repldone avec l’indicateur reset défini sur 1 sur la base de données du serveur de publication pour autoriser la troncation du journal des transactions. Cette commande doit ressembler à EXEC sp_repldone @xactid = NULL, @xact_seqno = NULL, @numtrans = 0, @time = 0, @reset = 1. Après cela, vous devez réinitialiser la réplication.
Étapes suivantes
Pour plus d’informations sur la configuration de la réplication transactionnelle, consultez les tutoriels suivants :
- Configurer la réplication entre un éditeur et un abonné SQL Managed Instance
- Configurer la réplication entre un éditeur SQL Managed Instance, un distributeur SQL Managed Instance et un abonné SQL Server.
- Créer une publication.
-
Créer un abonnement par émission de données en utilisant le nom du serveur en tant qu’abonné (par exemple
N'azuresqldbdns.database.windows.net) et le nom de la base de données Azure SQL Database comme base de données de destination (par exempleAdventureworks).