Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à : ![]() SQL Server sur la machine virtuelle Azure
SQL Server sur la machine virtuelle Azure
Conseil
Il existe de nombreuses méthodes pour déployer un groupe de disponibilité. Simplifiez votre déploiement pour éviter d’utiliser un équilibreur de charge Azure ou un nom de réseau distribué (DNN) pour votre groupe de disponibilité Always On, et créez vos machines virtuelles SQL Server dans plusieurs sous-réseaux au sein du même réseau virtuel Azure. Si vous avez déjà créé votre groupe de disponibilité dans un seul sous-réseau, vous pouvez le migrer vers un environnement multi-sous-réseau.
Ce tutoriel explique comment créer un groupe de disponibilité Always On pour SQL Server sur des machines virtuelles Azure dans un même sous-réseau. Il crée un groupe de disponibilité avec un réplica de base de données sur deux instances SQL Server.
Cet article configure manuellement l’environnement du groupe de disponibilité. Il est également possible d’automatiser les étapes en utilisant le portail Azure, PowerShell ou Azure CLI ou encore des modèles de démarrage rapide Azure.
Durée estimée : ce tutoriel prend environ 30 minutes une fois les prérequis remplis.
Prérequis
Le tutoriel suppose que vous avez des notions de base des groupes de disponibilité Always On SQL Server. Pour plus d’informations, consultez Vue d’ensemble des groupes de disponibilité AlwaysOn (SQL Server).
Avant de commencer les procédures de ce tutoriel, vous devez remplir les prérequis relatifs à la création de groupes de disponibilité Always On dans des machines virtuelles Azure. Si ces prérequis sont déjà remplis, vous pouvez passer à l’étape Créer le cluster.
Le tableau suivant récapitule les prérequis dont vous devez disposer avant de pouvoir suivre ce tutoriel :
| Condition requise | Description |
|---|---|
 Deux instances SQL Server Deux instances SQL Server |
- Dans un groupe à haute disponibilité Azure - Dans un domaine - Avec le clustering de basculement installé |
| Windows Server |
Partage de fichiers pour un témoin de cluster |
| Compte de service SQL Server |
Compte du domaine |
| Compte du service SQL Server Agent |
Compte du domaine |
| Ports du pare-feu ouverts |
- SQL Server : 1433 pour une instance par défaut - Point de terminaison de mise en miroir de bases de données : 5022 ou n’importe quel port disponible - Sonde d’intégrité d’adresse IP d’équilibreur de charge pour un groupe de disponibilité : 59999 ou n’importe quel port disponible - Sonde d’intégrité d’adresse IP d’équilibreur de charge pour le cluster principal : 58888 ou n’importe quel port disponible |
| Clustering de basculement |
Obligatoire pour les deux instances SQL Server |
| Compte du domaine d’installation |
- Administrateur local sur chaque instance SQL Server - Membre du rôle serveur fixe sysadmin pour chaque instance SQL Server |
| Groupes de sécurité réseau (NSG) |
Si l’environnement utilise des groupes de sécurité réseau, vérifiez que la configuration actuelle autorise le trafic réseau via les ports décrits dans la section Configurer le pare-feu. |
Créer le cluster
La première tâche consiste à créer un cluster de basculement Windows Server avec des machines virtuelles SQL Server et un serveur témoin :
Utilisez le protocole RDP (Remote Desktop Protocol) pour vous connecter à la première machine virtuelle SQL Server. Utilisez un compte de domaine administrateur sur les machines virtuelles SQL Server et le serveur témoin.
Conseil
Dans les prérequis, vous avez créé un compte appelé CORP\Install. Utilisez ce compte.
Dans le tableau de bord Gestionnaire de serveur, sélectionnez Outils, puis Gestionnaire du cluster de basculement.
Dans le volet gauche, cliquez-droit sur Gestionnaire du cluster de basculement, puis sélectionnez sur Créer un cluster.
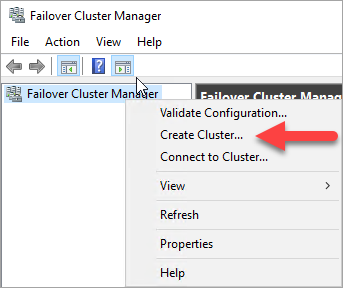
Dans l’Assistant Création d’un cluster, créez un cluster mononœud en renseignant les pages avec les paramètres contenus dans le tableau suivant :
Page Paramètre Avant de commencer Utilisez les valeurs par défaut. Sélection des serveurs Entrez le nom de la première machine virtuelle SQL Server dans Entrer le nom du serveur, puis sélectionnez Ajouter. Avertissement de validation Cliquez sur Non. Je n’ai pas besoin de l’assistance de Microsoft pour ce cluster, et par conséquent, je ne souhaite pas exécuter les tests de validation. Lorsque je clique sur Suivant, la création du cluster continue. Point d'accès pour l'administration du cluster Dans Nom du cluster, entrez un nom de cluster (par exemple, SQLAGCluster1). Confirmation Utilisez les valeurs par défaut, sauf si vous utilisez des espaces de stockage.
Définir l’adresse IP du cluster de basculement Windows Server
Notes
Sur Windows Server 2019, le cluster crée une valeur Nom du serveur distribué au lieu de la valeur Nom réseau du cluster. Si vous utilisez Windows Server 2019, ignorez les étapes qui font référence au nom de base du cluster dans ce tutoriel. Vous pouvez créer un nom réseau de cluster avec PowerShell. Pour plus d’informations, consultez le billet de blog Failover Cluster: Cluster Network Object.
Dans Gestionnaire du cluster de basculement, accédez à Principales ressources du cluster et développez les détails du cluster. Les ressources Nom et Adresse IP doivent se trouver dans l’état Échec.
La ressource d’adresse IP ne peut pas être mise en ligne, car le cluster se voit affecter la même adresse IP que la machine elle-même. Il s’agit d’une adresse en double.
Cliquez-droit sur la ressource Adresse IP en échec, puis sélectionnez Propriétés.
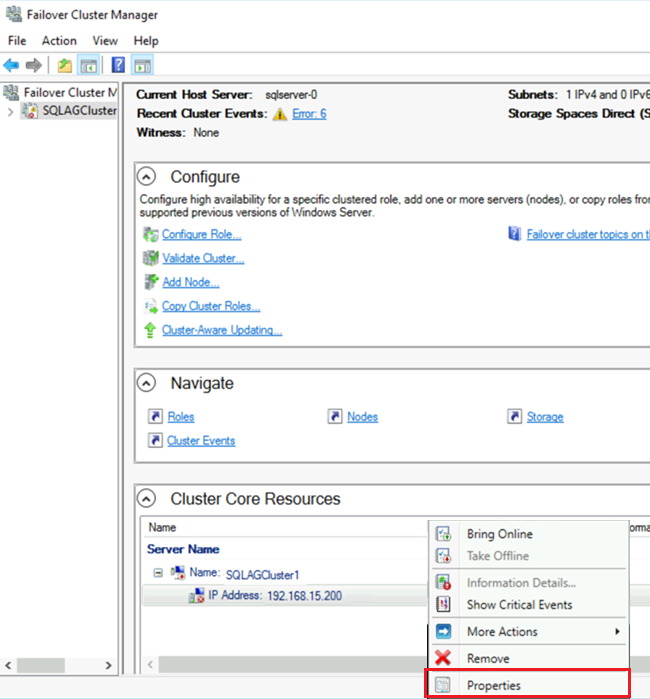
Sélectionnez Adresse IP statique. Spécifiez une adresse disponible du même sous-réseau que vos machines virtuelles.
Dans la section Principales ressources du cluster, cliquez avec le bouton droit sur le nom du cluster et sélectionnez Mettre en ligne. Attendez que les deux ressources soient en ligne.
Quand la ressource de nom de cluster apparaît en ligne, elle met à jour le serveur du contrôleur de domaine avec un nouveau compte d’ordinateur Active Directory. Utilisez ce compte Active Directory pour exécuter ultérieurement le service en cluster du groupe de disponibilité.
Ajouter l’autre instance SQL Server au cluster
Dans l’arborescence du navigateur, cliquez-droit sur le cluster, puis sélectionnez Ajouter un nœud.
Dans l’Assistant d’ajout de nœud, sélectionnez Suivant.
Dans la page Sélectionner des serveurs, ajoutez la deuxième machine virtuelle SQL Server. Entrez le nom de la machine virtuelle dans Entrer le nom du serveur, puis sélectionnez Ajouter>Suivant.
Dans la page Avertissement de validation, sélectionnez Non. (Dans un scénario de production, vous devez effectuer les tests de validation.) Ensuite, sélectionnez Suivant.
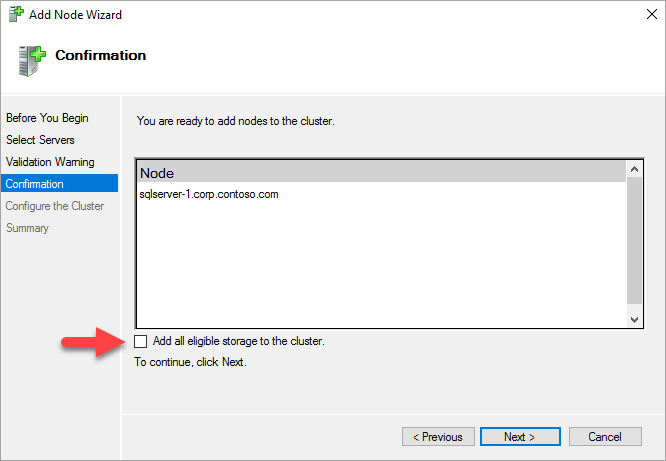
Dans la page Confirmation, si vous utilisez des espaces de stockage, décochez la case Ajouter la totalité du stockage disponible au cluster.
Avertissement
Si vous ne décochez pas Ajouter la totalité du stockage disponible au cluster, Windows détache les disques virtuels pendant le processus de clustering. Ils n’apparaissent donc pas dans le Gestionnaire de disques ou l’Explorateur d’objets tant que le stockage n’est pas supprimé du cluster et rattaché avec PowerShell.
Sélectionnez Suivant.
Sélectionnez Terminer.
Le Gestionnaire du cluster de basculement indique que votre cluster a un nouveau nœud et l’affiche dans le conteneur Nœuds.
Déconnectez-vous de la session Bureau à distance.
Ajouter un partage de fichiers pour un quorum de cluster
Dans cet exemple, le cluster Windows utilise un partage de fichiers pour créer un quorum de cluster. Ce tutoriel utilise un quorum NodeAndFileShareMajority. Pour plus d’informations, consultez Configurer et gérer un quorum.
Connectez-vous à la machine virtuelle du serveur témoin de partage de fichiers à l’aide d’une session Bureau à distance.
Dans Gestionnaire de serveur, sélectionnez Outils. Ouvrez Gestion de l’ordinateur.
Sélectionnez Dossiers partagés.
Cliquez avec le bouton droit sur Partages, puis sélectionnez Nouveau partage.
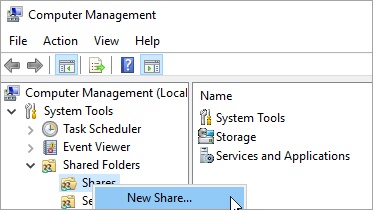
Utilisez Assistant Création d’un dossier partagé pour créer un partage.
Dans la page Chemin du dossier, sélectionnez Parcourir. Recherchez ou créez un chemin pour le dossier partagé, puis sélectionnez Suivant.
Dans la page Nom, description et paramètres, vérifiez le nom et le chemin du partage. Sélectionnez Suivant.
Dans la page Autorisations de dossier partagé, définissez Personnaliser les autorisations. Sélectionnez Personnalisé.
Dans la boîte de dialogue Personnaliser les autorisations, sélectionnez Ajouter.
Vérifiez que le compte utilisé pour créer le cluster a le contrôle total.
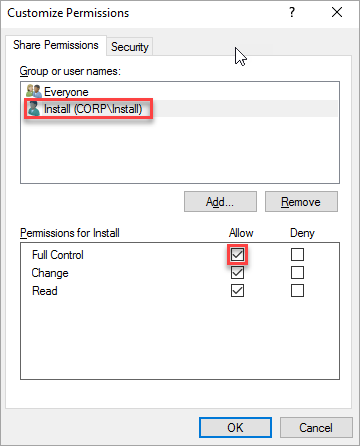
Cliquez sur OK.
Dans la page Autorisations de dossier partagé, sélectionnez Terminer. Ensuite, resélectionnez Terminer.
Déconnectez-vous du serveur.
Configurer le quorum du cluster
Notes
Selon la configuration de votre groupe de disponibilité, il peut être nécessaire de modifier le vote avec quorum d’un nœud participant au cluster de basculement Windows Server. Pour plus d’informations, consultez Configurer le quorum d’un cluster pour SQL Server sur des machines virtuelles Azure.
Connectez-vous au premier nœud de cluster à l’aide d’une session Bureau à distance.
Dans Gestionnaire du cluster de basculement, cliquez-droit sur le cluster, pointez sur Autres Actions, puis sélectionnez Configurer les paramètres de quorum du cluster.
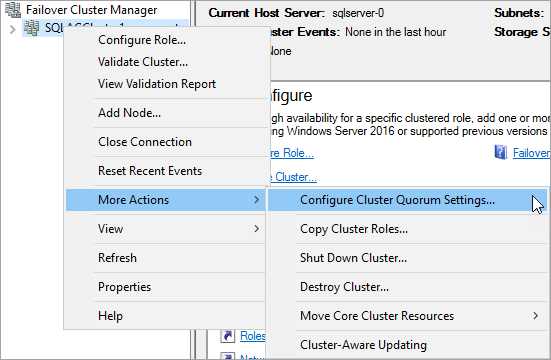
Dans l’Assistant Configuration des paramètres de quorum du cluster, sélectionnez Suivant.
Dans la page Sélectionner l’option de configuration du quorum, choisissez Sélectionner le témoin de quorum, puis sélectionnez Suivant.
Sur la page Sélectionner le témoin de quorum, sélectionnez Configurer un témoin de partage de fichiers.
Conseil
Windows Server 2016 prend en charge un témoin cloud. Si vous choisissez ce type de témoin, un témoin de partage de fichiers est inutile. Pour plus d’informations, consultez Déployer un témoin de cloud pour un cluster de basculement. Ce tutoriel utilise un témoin de partage de fichiers pris en charge par les systèmes d’exploitation antérieurs.
Dans Configurer le témoin de partage de fichiers, tapez le chemin du partage que vous avez créé. Sélectionnez ensuite Suivant.
Dans la page Confirmation, vérifiez les paramètres. Sélectionnez ensuite Suivant.
Sélectionnez Terminer.
Les principales ressources de cluster sont configurées avec un témoin de partage de fichiers.
Activer des groupes de disponibilité
Ensuite, activez les groupes de disponibilité Always On. Effectuez ces étapes sur les deux machines virtuelles SQL Server.
À partir de l’écran Démarrer, ouvrez le Gestionnaire de configuration SQL Server.
Dans l’arborescence du navigateur, sélectionnez Services SQL Server. Cliquez ensuite avec le bouton droit sur le service SQL Server (MSSQLSERVER) et sélectionnez Propriétés.
Sélectionnez l’onglet Haute disponibilité Always On, puis sélectionnez Activer les groupes de disponibilité Always On.
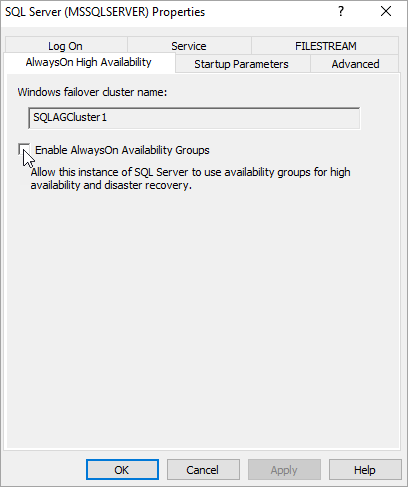
Sélectionnez Appliquer. Sélectionnez OK dans la boîte de dialogue de la fenêtre contextuelle.
Redémarrez le service SQL Server.
Activer la fonctionnalité FILESTREAM
Si vous n’utilisez pas FILESTREAM pour votre base de données dans le groupe de disponibilité, ignorez cette étape et passez à l’étape suivante : Créer une base de données.
Si vous prévoyez d’ajouter une base de données à votre groupe de disponibilité qui utilise FILESTREAM, alors FILESTREAM doit être activé, car cette fonctionnalité est désactivée par défaut. Utilisez le Gestionnaire de configuration SQL Server pour activer la fonctionnalité sur les deux instances SQL Server.
Pour activer la fonctionnalité FILESTREAM, suivez les étapes ci-dessous :
Lancez le fichier RDP sur la première machine virtuelle SQL Server (SQL-VM-1) avec un compte de domaine membre du rôle serveur fixe sysadmin, par exemple, le compte de domaine CORP\Install créé dans le document de prérequis
Dans l’écran Démarrer de l’une de vos machines virtuelles SQL Server, lancez le Gestionnaire de configuration SQL Server.
Dans l’arborescence du navigateur, sélectionnez Services SQL Server, cliquez avec le bouton droit sur le service SQL Server (MSSQLSERVER) et sélectionnez Propriétés.
Sélectionnez l’onglet FILESTREAM, puis cochez la case Activer FILESTREAM pour l’accès Transact-SQL :
Sélectionnez Appliquer. Sélectionnez OK dans la boîte de dialogue de la fenêtre contextuelle.
Dans SQL Server Management Studio, sélectionnez Nouvelle requête pour afficher l’Éditeur de requête.
Dans l'Éditeur de requête, entrez le code Transact-SQL suivant :
EXEC sp_configure filestream_access_level, 2 RECONFIGURESélectionnez Exécuter.
Redémarrez le service SQL Server.
Répétez ces étapes pour l’autre instance SQL Server.
Créer une base de données sur la première instance SQL Server
- Ouvrez le fichier RDP pour la première machine virtuelle SQL Server avec un compte de domaine membre du rôle serveur fixe sysadmin.
- Ouvrez SQL Server Management Studio (SSMS) et connectez-vous à la première instance SQL Server.
- Dans l’Explorateur d’objets, cliquez-droit sur Bases de données, puis cliquez sur Nouvelle base de données.
- Dans Nom de la base de données, entrez MyDB1, puis sélectionnez OK.
Créer un partage de sauvegarde
Sur la première machine virtuelle SQL Server, dans le Gestionnaire de serveur, sélectionnez Outils. Ouvrez Gestion de l’ordinateur.
Sélectionnez Dossiers partagés.
Cliquez avec le bouton droit sur Partages, puis sélectionnez Nouveau partage.
Utilisez Assistant Création d’un dossier partagé pour créer un partage.
Dans la page Chemin du dossier, sélectionnez Parcourir. Recherchez ou créez un chemin pour le dossier partagé de la sauvegarde de la base de données, puis sélectionnez Suivant.
Dans la page Nom, description et paramètres, vérifiez le nom et le chemin du partage. Sélectionnez ensuite Suivant.
Dans la page Autorisations de dossier partagé, définissez Personnaliser les autorisations. Sélectionnez ensuite Personnalisé.
Dans la boîte de dialogue Personnaliser les autorisations, sélectionnez Ajouter.
Cochez Contrôle total pour donner un accès complet au compte de service SQL Server (
Corp\SQLSvc):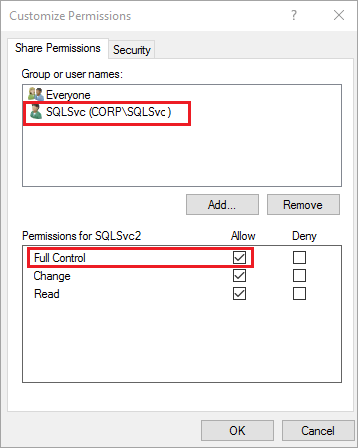
Cliquez sur OK.
Dans la page Autorisations de dossier partagé, sélectionnez Terminer. Sélectionnez Terminer.
Créer une sauvegarde complète de la base de données
Vous devez sauvegarder la nouvelle base de données pour initialiser la chaîne du journal. Si vous ne sauvegardez pas la nouvelle base de données, vous ne pourrez pas l’inclure dans un groupe de disponibilité.
Dans l’Explorateur d’objets, cliquez-droit sur la base de données, pointez sur Tâches, puis sélectionnez Sauvegarder.
Sélectionnez OK pour effectuer une sauvegarde complète à l’emplacement de sauvegarde par défaut.
Créer un groupe de disponibilité
Vous êtes maintenant prêt à créer et à configurer un groupe de disponibilité en effectuant les tâches suivantes :
- Création d’une base de données sur la première instance SQL Server.
- Sauvegarde complète et sauvegarde du journal des transactions de la base de données.
- Restauration des sauvegardes complète et de fichier journal sur la deuxième instance SQL Server avec l’option
NO RECOVERY. - Créez le groupe de disponibilité (MyTestAG) avec validation synchrone, basculement automatique et réplicas secondaires accessibles en lecture.
Créez le groupe de disponibilité
Connectez-vous à votre machine virtuelle SQL Server à l’aide du Bureau à distance et ouvrez SQL Server Management Studio.
Dans l’Explorateur d’objets de SSMS, cliquez avec le bouton droit sur Haute disponibilité Always On, puis sélectionnez Assistant Nouveau groupe de disponibilité.
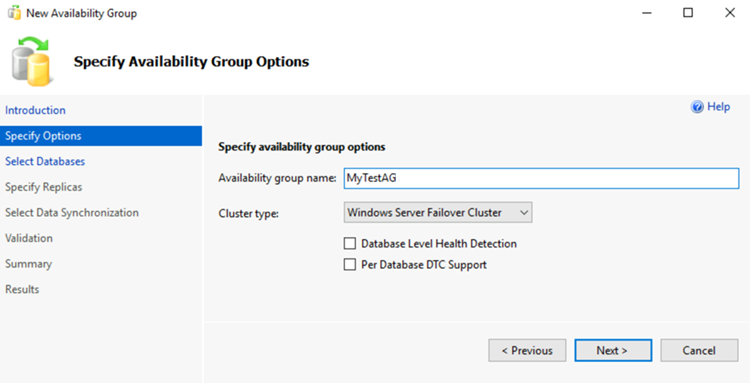
Dans la page Introduction, sélectionnez Suivant. Dans la page Spécifier les options du groupe de disponibilité, entrez le nom du groupe de disponibilité dans la zone Nom du groupe de disponibilité. Par exemple, entrez MyTestAG. Sélectionnez ensuite Suivant.
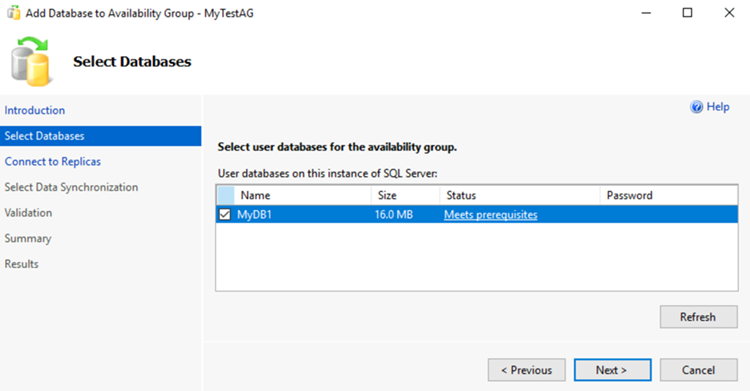
Dans la page Sélectionner des bases de données, sélectionnez votre base de données, puis Suivant.
Notes
La base de données présente les prérequis pour un groupe de disponibilité, car vous avez effectué au moins une sauvegarde complète sur le réplica principal prévu.
Dans la page Spécifier les réplicas, sélectionnez Ajouter un réplica.
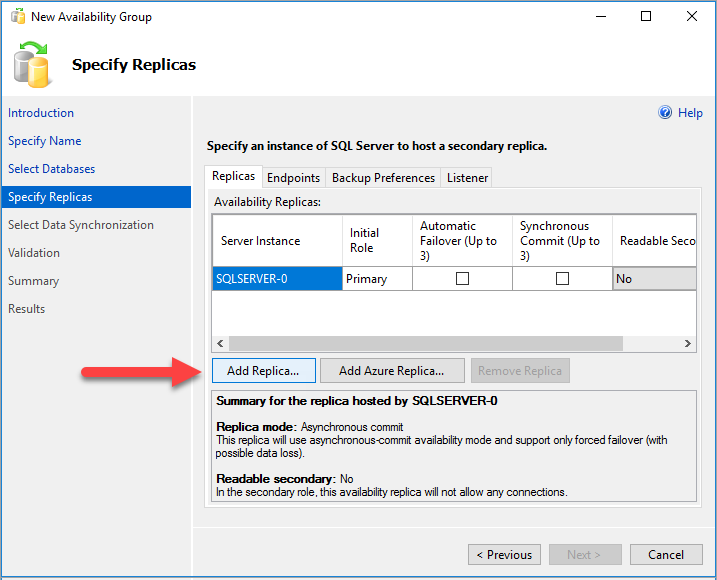
Dans la boîte de dialogue Se connecter au serveur, pour Nom du serveur, entrez le nom de la deuxième instance SQL Server. Sélectionnez Connecter.
De retour dans la page Spécifier les réplicas, vous devez maintenant voir le deuxième serveur sous Réplicas de disponibilité. Configurez les réplicas comme indiqué ci-dessous.
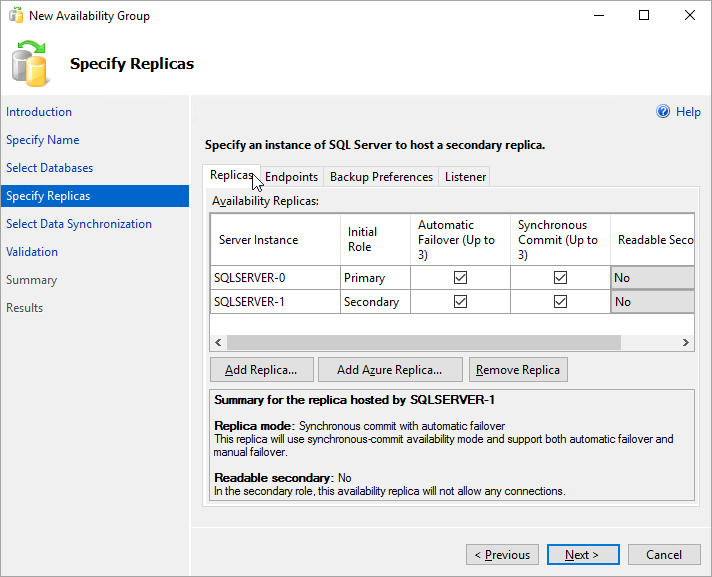
Sélectionnez Points de terminaison afin d’afficher le point de terminaison de mise en miroir de bases de données pour ce groupe de disponibilité. Utilisez le même port que vous avez utilisé lorsque vous avez défini la règle de pare-feu pour les points de terminaison de mise en miroir de base de données.
Dans la page Sélectionner la synchronisation de données initiale, sélectionnez Complète et spécifiez un emplacement réseau partagé. Pour l’emplacement, utilisez le partage de sauvegarde que vous avez créé. Dans l’exemple, il s’agissait de \\<Première instance SQL Server>\Backup\. Sélectionnez Suivant.
Notes
La synchronisation complète effectue une sauvegarde complète de la base de données sur la première instance de SQL Server et la restaure sur la deuxième instance. Pour les bases de données volumineuses, nous ne recommandons pas une synchronisation complète car elle peut prendre beaucoup de temps.
Vous pouvez réduire ce temps en effectuant manuellement une sauvegarde de la base de données et en la restaurant avec
NO RECOVERY. Si la base de données est déjà restaurée avecNO RECOVERYsur la deuxième instance SQL Server avant la configuration du groupe de disponibilité, sélectionnez Joindre uniquement. Si vous souhaitez effectuer la sauvegarde une fois le groupe de disponibilité configuré, sélectionnez Ignorer la synchronisation de données initiale.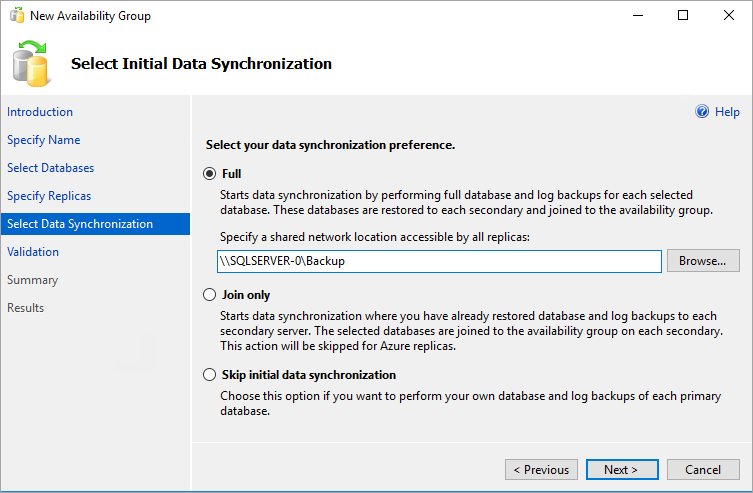
Dans la page Validation, sélectionnez Suivant. Cette page doit ressembler à l’image suivante :
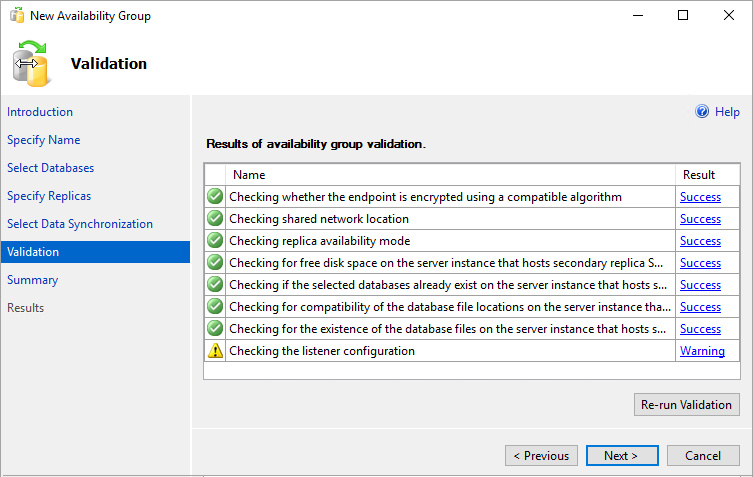
Notes
Un avertissement concernant la configuration de l’écouteur s’affiche parce que vous n’avez pas configuré d’écouteur de groupe de disponibilité. Vous pouvez ignorer cet avertissement car, sur les machines virtuelles, vous créez l’écouteur après la création de l’équilibreur de charge Azure.
Dans la page Résumé, sélectionnez Terminer, puis patientez le temps que l’Assistant configure le nouveau groupe de disponibilité. Dans la page Progression, vous pouvez sélectionner Plus de détails pour afficher la progression détaillée.
Une fois que l’Assistant a terminé la configuration, examinez la page Résultats pour vérifier que le groupe de disponibilité est créé.
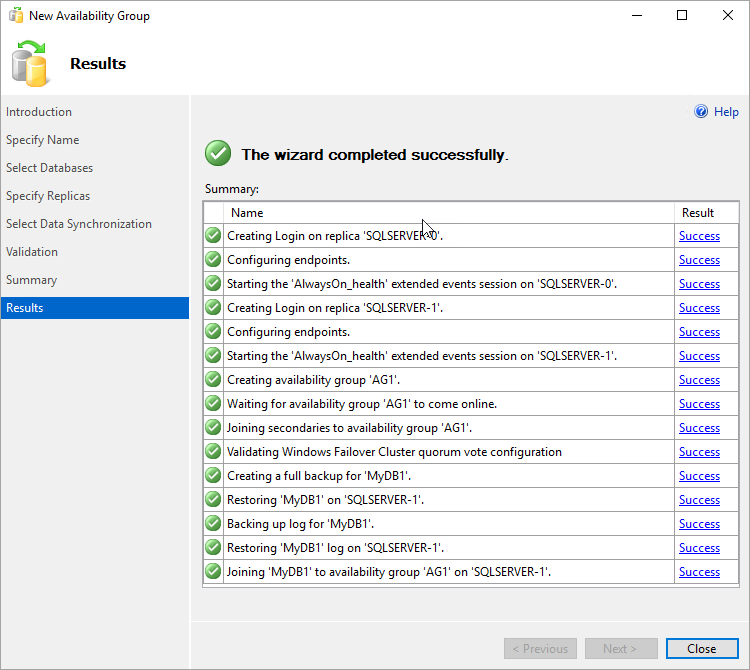
Sélectionnez Fermer pour fermer l’Assistant.

Vérifier le groupe de disponibilité
Dans l’Explorateur d’objets, développez Haute disponibilité Always On, puis Groupes de disponibilité. Vous devez maintenant voir le nouveau groupe de disponibilité dans ce conteneur. Cliquez avec le bouton droit sur le groupe de disponibilité et sélectionnez Afficher le tableau de bord.
Le tableau de bord de votre groupe de disponibilité doit ressembler à celui de la capture d’écran suivante :
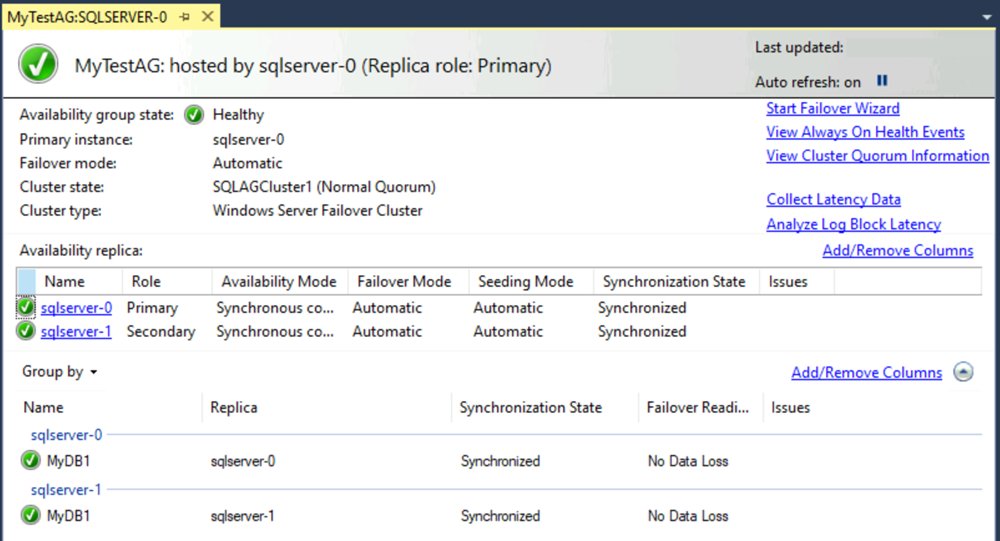
Le tableau de bord présente les répliques, le mode de basculement de chaque réplica et l’état de la synchronisation.
Dans le Gestionnaire du cluster de basculement, sélectionnez votre cluster. Sélectionnez Rôles.
Le nom du groupe de disponibilité que vous avez utilisé est un rôle sur le cluster. Ce groupe de disponibilité n’a pas d’adresse IP pour les connexions clientes, car vous n’avez pas configuré d’écouteur. Vous allez configurer l’écouteur après avoir créé un équilibreur de charge Azure.

Avertissement
N’essayez pas de basculer le groupe de disponibilité à partir du Gestionnaire du cluster de basculement. Toutes les opérations de basculement doivent être effectuées sur le tableau de bord du groupe de disponibilité dans SSMS. Découvrez-en plus sur les restrictions d’utilisation du Gestionnaire du cluster de basculement avec des groupes de disponibilité.


À ce stade, vous avez un groupe de disponibilité avec deux réplicas SQL Server. Vous pouvez déplacer le groupe de disponibilité entre les instances. Vous ne pouvez pas encore vous connecter au groupe de disponibilité, car vous n’avez pas d’écouteur.
Dans les machines virtuelles Azure, l’écouteur requiert un équilibrage de charge. L’étape suivante consiste à créer l’équilibrage de charge dans Azure.
Crée un équilibrage de charge Azure
Notes
Les déploiements de groupes de disponibilité sur plusieurs sous-réseaux ne nécessitent pas d’équilibreur de charge. Dans un environnement à sous-réseau unique, les clients utilisant SQL Server 2019 CU8 et ultérieur sur Windows 2016 et ultérieur peuvent remplacer l’écouteur de nom réseau virtuel (VNN) traditionnel et Azure Load Balancer par un écouteur de nom réseau distribué (DNN). Si vous souhaitez utiliser un DNN, ignorez les étapes du tutoriel qui configurent Azure Load Balancer pour votre groupe de disponibilité.
Sur les machines virtuelles Azure dans un sous-réseau unique, un groupe de disponibilité SQL Server nécessite un équilibreur de charge. Cet équilibreur de charge stocke les adresses IP des écouteurs de groupe de disponibilité et du cluster de basculement Windows Server. Cette section indique comment créer l’équilibrage de charge dans le portail Azure.
Un équilibreur de charge dans Azure peut être standard ou de base. Une équilibreur de charge standard offre davantage de fonctionnalités qu’un équilibreur de charge de base. Pour un groupe de disponibilité, l’équilibreur de charge standard est nécessaire si vous utilisez une zone de disponibilité (à la place d’un groupe à haute disponibilité). Pour plus d’informations sur la différence entre les références SKU, consultez Références SKU Azure Load Balancer.
Important
Le 30 septembre 2025, la référence SKU De base d’Azure Load Balancer sera mise hors service. Pour plus d’informations, consultez l’annonce officielle. Si vous utilisez actuellement l’équilibreur de charge de base, effectuez une mise à niveau vers l’équilibreur de charge standard avant la date de mise hors service. Pour obtenir de l’aide, consultez Mettre à niveau l’équilibreur de charge.
Dans le portail Azure, accédez au groupe de ressources contenant vos machines virtuelles SQL Server et sélectionnez + Ajouter.
Recherchez l’équilibrage de charge. Choisissez l’équilibreur de charge publié par Microsoft.
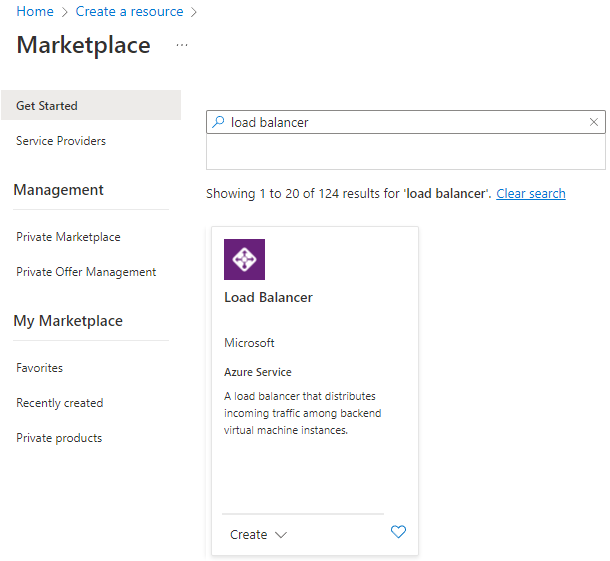
Sélectionnez Create (Créer).
Dans la page Créer un équilibreur de charge, configurez les paramètres suivants pour l’équilibreur de charge :
Paramètre Entrée ou sélection Abonnement Utilisez le même abonnement que la machine virtuelle. Groupe de ressources Utilisez le même groupe de ressources que la machine virtuelle. Nom Utilisez un nom textuel pour l’équilibreur de charge, par exemple sqlLB. Région Utilisez la même région que la machine virtuelle. Référence (SKU) Sélectionnez Standard. Type sélectionnez Interne. La page doit ressembler à ceci :
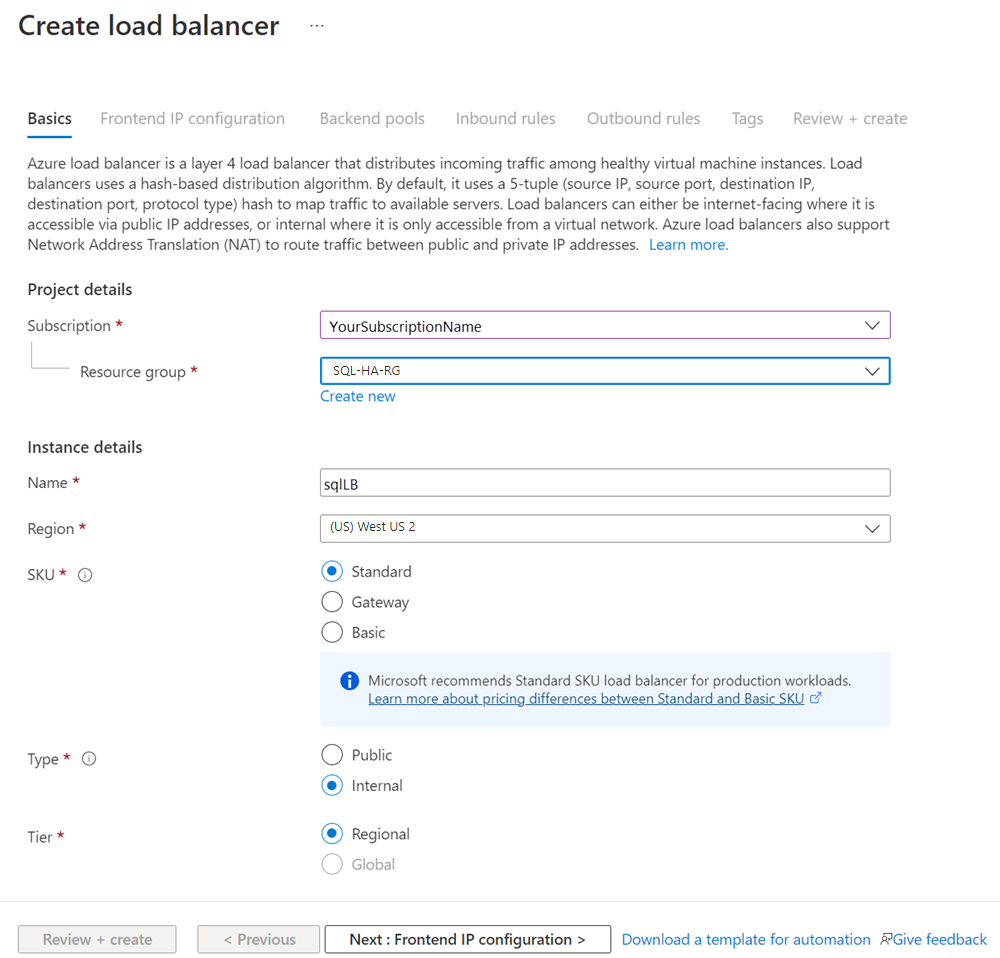
Sélectionner Suivant : Configuration d’adresse IP front-end.
Sélectionnez + Ajouter une configuration IP front-end.
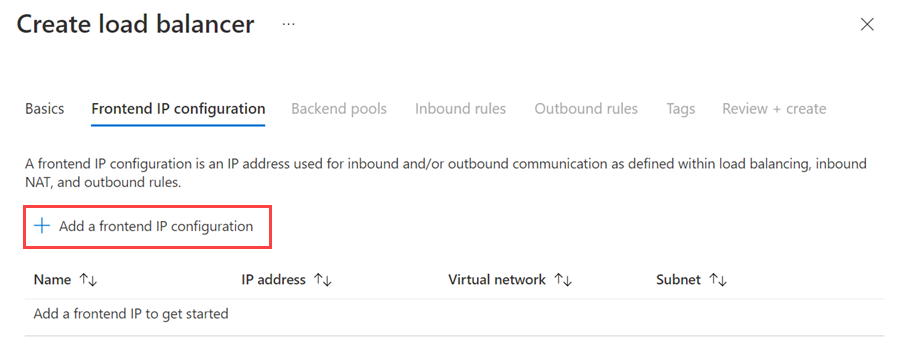
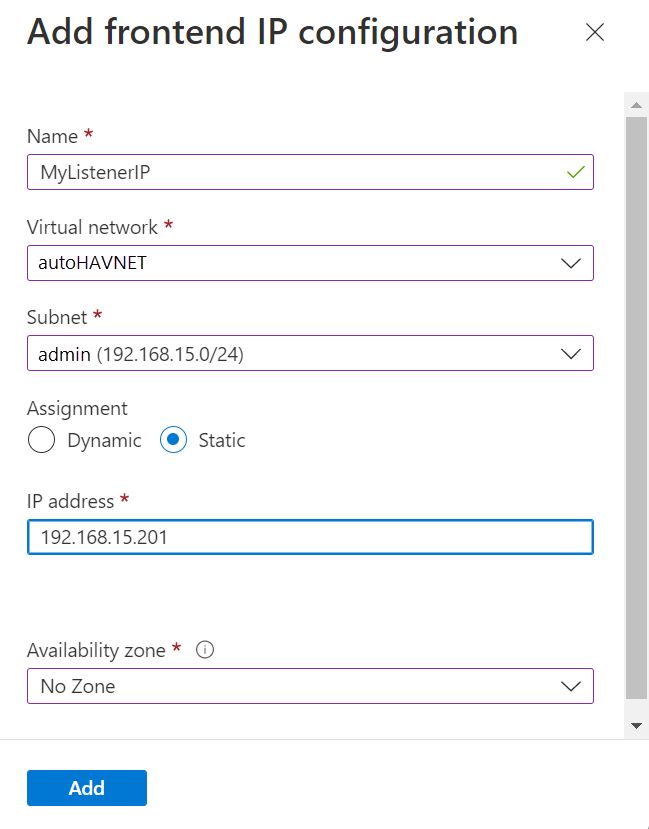
Configurez l’adresse IP front-end avec les valeurs suivantes :
- Nom : entrez un nom qui identifie la configuration IP front-end.
- Réseau virtuel : sélectionnez le même réseau que les machines virtuelles.
- Sous-réseau : sélectionnez le même sous-réseau que les machines virtuelles.
- Affectation : sélectionnez Statique.
- Adresse IP : utilisez une adresse disponible à partir du réseau. Utilisez cette adresse pour l’écouteur de votre groupe de disponibilité. Cette adresse est différente de l’adresse IP de votre cluster.
- Zone de disponibilité : choisissez une zone de disponibilité dans laquelle déployer votre adresse IP (facultatif).
L’image suivante montre la boîte de dialogue Ajouter une configuration d’adresse IP front-end :
Sélectionnez Ajouter.
Choisissez Vérifier + Créer pour valider la configuration. Sélectionnez ensuite Créer pour créer l’équilibreur de charge et l’adresse IP front-end.


Pour configurer l’équilibreur de charge, vous devez créer un pool de back-ends, créer une sonde et définir les règles d’équilibrage de charge.
Ajouter un pool principal pour l’écouteur de groupe de disponibilité
Accédez au groupe de ressources sur le portail Azure. Vous devrez peut-être actualiser l’affichage pour voir l’équilibrage de charge tout juste créé.
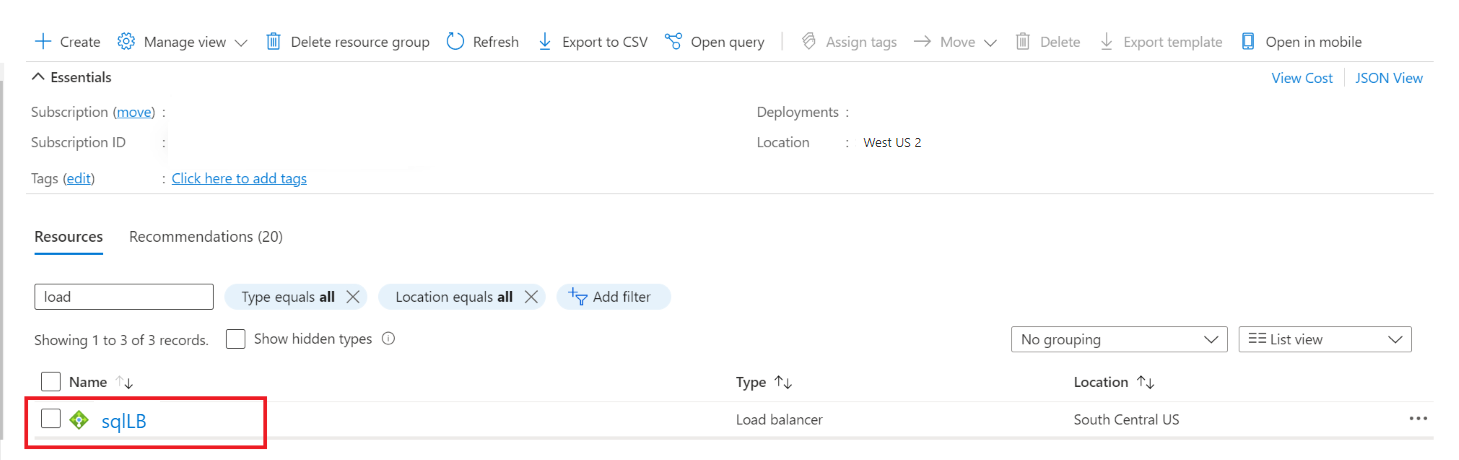
Sélectionnez l’équilibreur de charge, sélectionnez Pools de back-ends, puis sélectionnez + Ajouter.
Pour Nom, indiquez un nom pour le pool de back-ends.
Pour Configuration du pool de back-ends, sélectionnez Carte réseau.
Sélectionnez Ajouter pour associer le pool de back-ends au groupe à haute disponibilité contenant les machines virtuelles.
Sous Machine virtuelle, choisissez les machines virtuelles qui hébergeront les réplicas de groupe de disponibilité. N’incluez pas le serveur témoin de partage de fichiers.
Notes
Si les deux machines virtuelles ne sont pas spécifiées, seules les connexions au réplica principal aboutiront.
Sélectionnez Ajouter pour ajouter les machines virtuelles au pool de back-ends.
Sélectionnez Enregistrer pour créer le pool de back-ends.

Configurer la sonde
Dans le portail Azure, sélectionnez l’équilibreur de charge, sélectionnez Sondes d’intégrité, puis sélectionnez + Ajouter.
Définissez la sonde d’intégrité de l’écouteur comme suit :
Paramètre Description Exemple Nom Texte SQLAlwaysOnEndPointProbe Protocole Choisissez TCP. TCP Port Tout port inutilisé. 59999 Intervalle Intervalle de temps entre les tentatives de la sonde, en secondes. 5 Sélectionnez Ajouter.
Configurer les règles d’équilibrage de charge
Dans le portail Azure, sélectionnez l’équilibreur de charge, sélectionnez Règles d’équilibrage de charge, puis sélectionnez + Ajouter.
Définissez les règles d’équilibrage de charge de l’écouteur comme suit :
Paramètre Description Exemple Nom Texte SQLAlwaysOnEndPointListener Frontend IP address (Adresse IP frontale) Choisissez une adresse. Utilisez l’adresse que vous avez créée lorsque vous avez créé l’équilibrage de charge. Pool back-end Choisir le pool de back-ends Sélectionnez le pool de back-ends qui contient les machines virtuelles ciblées pour l’équilibreur de charge. Protocole Choisissez TCP. TCP Port Utiliser le port pour l'écouteur de groupe de disponibilité 1433 Port principal Ce champ n’est pas utilisé quand une adresse IP flottante est définie pour le retour direct du serveur 1433 Sonde d’intégrité Nom que vous avez spécifié pour la sonde SQLAlwaysOnEndPointProbe Persistance de session Liste déroulante Aucun Délai d’inactivité Délai en minutes de maintien d’une connexion TCP ouverte 4 Adresse IP flottante (retour direct du serveur) Topologie de flux et schéma de mappage d’adresses IP Activé Avertissement
Le retour au serveur direct est configuré lors de la création. Vous ne pouvez pas le changer.
Sélectionnez Enregistrer.
Ajouter l’adresse IP du cluster principal pour le cluster de basculement Windows Server
L’adresse IP du cluster de basculement Windows Server doit également se trouver sur l’équilibreur de charge. Si vous utilisez Windows Server 2019, ignorez ce processus car le cluster crée une valeur Nom de serveur distribué au lieu de la valeur Nom réseau du cluster.
Dans le Portail Azure, accédez au même équilibreur de charge Azure. Sélectionnez Configuration d’adresse IP front-end, puis sélectionnez +Ajouter. Utilisez l’adresse IP que vous avez configurée pour le cluster de basculement Windows Server dans les ressources principales du cluster. Définissez l’adresse IP comme Statique.
Sur l’équilibreur de charge, sélectionnez les Probes d’intégrité, puis cliquez sur +Ajouter.
Définissez la sonde d’intégrité de l’adresse IP du cluster principal pour le cluster de basculement Windows Server comme suit :
Paramètre Description Exemple Nom Texte WSFCEndPointProbe Protocole Choisissez TCP. TCP Port Tout port inutilisé. 58888 Intervalle Intervalle de temps entre les tentatives de la sonde, en secondes. 5 Sélectionnez Ajouter pour définir la sonde d’intégrité.
Sélectionnez Règles d’équilibrage de charge, puis +Ajouter.
Définissez les règles d’équilibrage de charge pour l’adresse IP du cluster principal comme suit :
Paramètre Description Exemple Nom Texte WSFCEndPoint Frontend IP address (Adresse IP frontale) Choisissez une adresse. Utilisez l’adresse que vous avez créée quand vous avez configuré l’adresse IP pour le cluster de basculement Windows Server. Celle-ci diffère de l’adresse IP de l’écouteur. Pool back-end Choisir le pool de back-ends Sélectionnez le pool de back-ends qui contient les machines virtuelles ciblées pour l’équilibreur de charge. Protocole Choisissez TCP. TCP Port Utilisez le port de l’adresse IP du cluster. Il s’agit d’un port disponible qui n’est pas utilisé pour le port de la sonde de l’écouteur. 58888 Port principal Ce champ n’est pas utilisé quand une adresse IP flottante est définie pour le retour direct du serveur 58888 Sonde Nom que vous avez spécifié pour la sonde WSFCEndPointProbe Persistance de session Liste déroulante Aucun Délai d’inactivité Délai en minutes de maintien d’une connexion TCP ouverte 4 Adresse IP flottante (retour direct du serveur) Topologie de flux et schéma de mappage d’adresses IP Activé Avertissement
Le retour au serveur direct est configuré lors de la création. Vous ne pouvez pas le changer.
Sélectionnez OK.
Configurer l’écouteur
La prochaine étape consiste à configurer un écouteur de groupe de disponibilité sur le cluster de basculement.
Notes
Ce tutoriel montre comment créer un seul écouteur avec une adresse IP pour l’équilibreur de charge interne. Pour créer des écouteurs en utilisant une ou plusieurs adresses IP, consultez Configurer un ou plusieurs écouteurs de groupe de disponibilité Always On.
L’écouteur de groupe de disponibilité est une adresse IP et un nom réseau sur lesquels le groupe de disponibilité de SQL Server écoute. Pour créer l’écouteur de groupe de disponibilité :
Récupérez le nom de la ressource réseau du cluster :
a. Utilisez le protocole RDP pour vous connecter à la machine virtuelle Azure qui héberge le réplica principal.
b. Ouvrez le Gestionnaire du cluster de basculement.
c. sélectionnez le nœud Réseaux et notez le nom de réseau du cluster. Utilisez ce nom dans la variable
$ClusterNetworkNamedu script PowerShell. Dans l’image suivante, le nom réseau du cluster est Cluster Network 1 :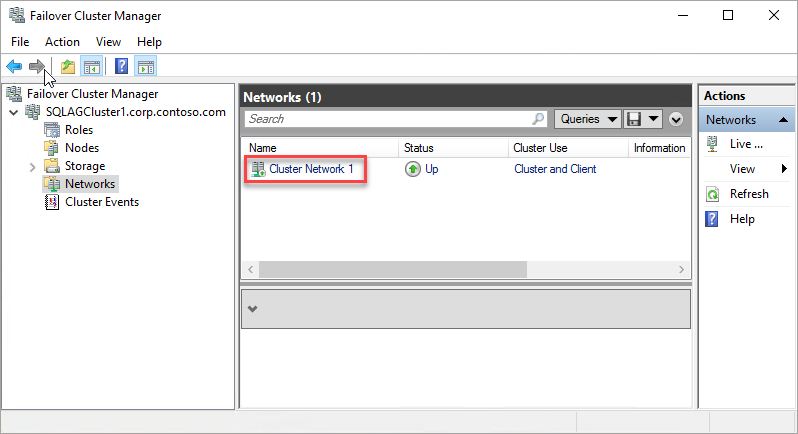
Ajoutez le point d’accès client. Le point d’accès client est le nom réseau que les applications utilisent pour se connecter aux bases de données dans un groupe de disponibilité.
a. Dans le Gestionnaire du cluster de basculement, développez le nom du cluster, puis sélectionnez Rôles.
b. Dans le volet Rôles, cliquez avec le bouton droit sur le nom du groupe de disponibilité, puis sélectionnez Ajouter une ressource>Point d’accès client.
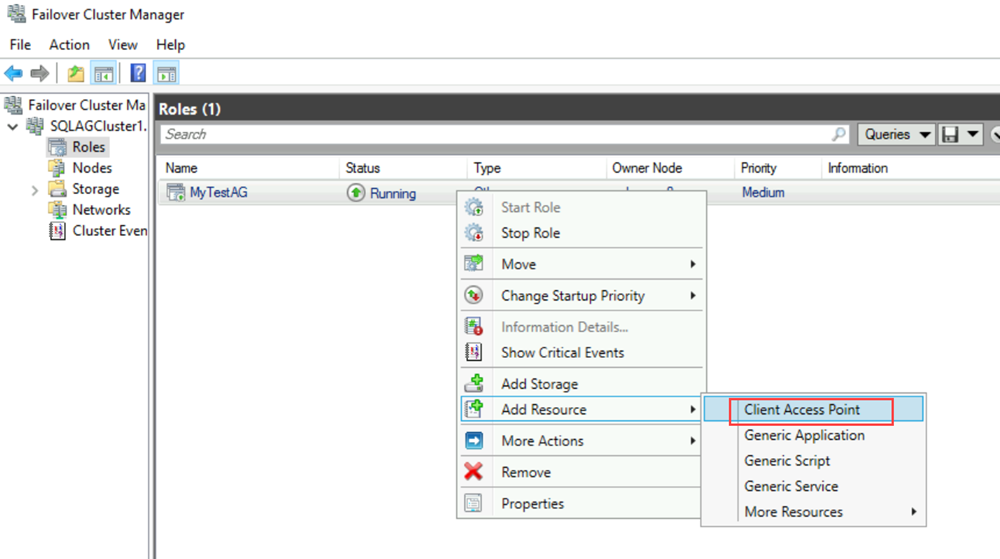
c. Dans la zone Nom, créez un nom pour ce nouvel écouteur. Le nom du nouvel écouteur est le nom réseau que les applications utilisent pour se connecter aux bases de données dans le groupe de disponibilité de SQL Server.
d. Pour terminer la création de l’écouteur, sélectionnez Suivant à deux reprises, puis sélectionnez Terminer. Ne mettez pas l’écouteur ou la ressource en ligne à ce stade.
Mettez le rôle de cluster du groupe de disponibilité hors connexion. Dans le Gestionnaire du cluster de basculement, sous Rôles, cliquez avec le bouton droit sur le rôle, puis sélectionnez Arrêter le rôle.
Configurez la ressource IP du groupe de disponibilité :
a. Sélectionnez l’onglet Ressources, puis développez le point d’accès client que vous avez créé. Le point d’accès client est hors connexion.
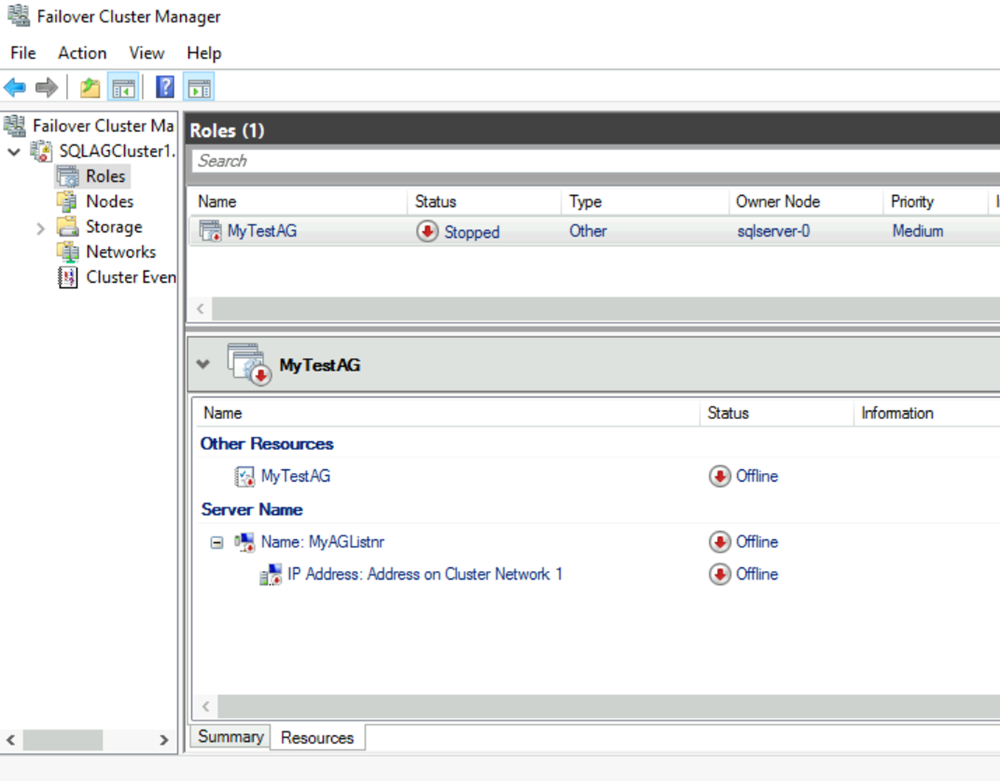
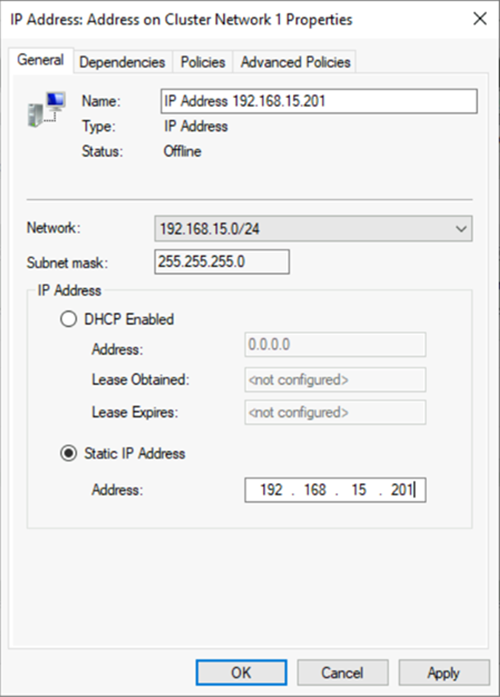
b. Cliquez avec le bouton droit sur la ressource IP, puis sélectionnez Propriétés. Notez le nom de l’adresse IP et utilisez-le dans la variable
$IPResourceNamedans le script PowerShell.c. Sous Adresse IP, sélectionnez Adresse IP statique. Pour l’adresse IP, utilisez l’adresse que vous avez définie pour l’équilibreur de charge sur le portail Azure.
Créez une dépendance entre le groupe de disponibilité SQL Server et le point d’accès client :
a. Dans le Gestionnaire du cluster de basculement, sélectionnez Rôles, puis votre groupe de disponibilité.
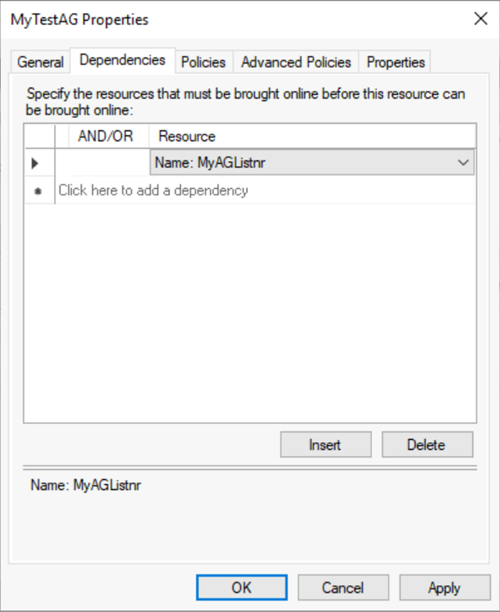
b. Sous l’onglet Ressources, sous Autres ressources, cliquez avec le bouton droit sur la ressource du groupe de disponibilité, puis sélectionnez Propriétés.
c. Sous l’onglet Dépendances, ajoutez le nom du point d’accès client (écouteur).
d. Sélectionnez OK.
Créez une dépendance entre le point d’accès client et l’adresse IP :
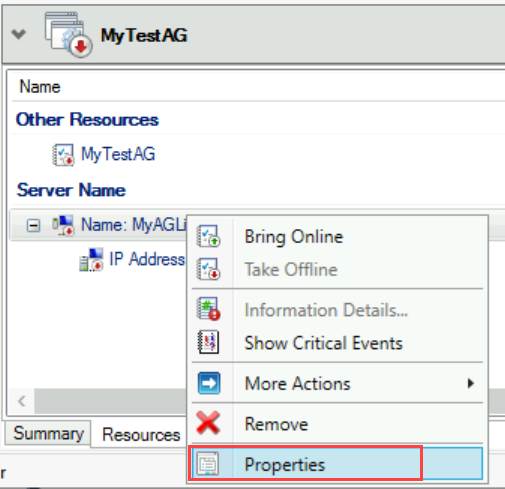
a. Dans le Gestionnaire du cluster de basculement, sélectionnez Rôles, puis votre groupe de disponibilité.
b. Sous l’onglet Ressources, cliquez avec le bouton droit sur le point d’accès client sous Nom du serveur, puis sélectionnez Propriétés.
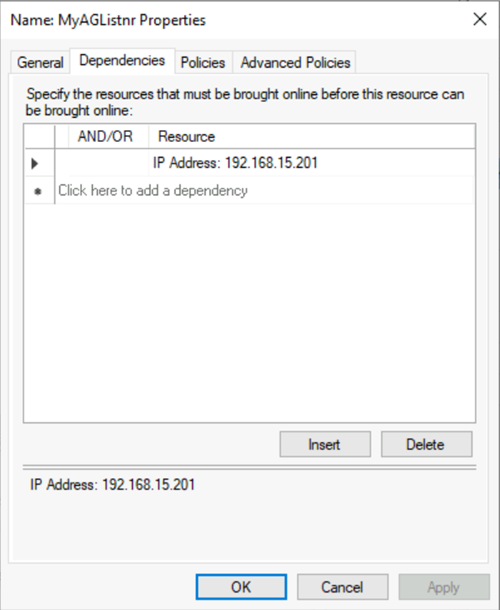
c. Sélectionnez l’onglet Dépendances. Vérifiez que l’adresse IP est une dépendance. Si ce n’est pas le cas, définissez une dépendance sur l’adresse IP. Si plusieurs ressources sont listées, vérifiez que les adresses IP ont des dépendances OR (et non des dépendances AND). Sélectionnez ensuite OK.
Conseil
Vous pouvez vérifier que les dépendances sont correctement configurées. Dans le Gestionnaire du cluster de basculement, accédez à Rôles, cliquez avec le bouton droit sur le groupe de disponibilité, sélectionnez Autres actions, puis Afficher le rapport de dépendance. Lorsque les dépendances sont correctement configurées, le groupe de disponibilité dépend du nom réseau, et le nom réseau dépend de l’adresse IP.
Définissez les paramètres du cluster dans PowerShell :
a. Copiez le script PowerShell suivant sur l’une de vos instances SQL Server. Mettez à jour les variables de votre environnement.
$ClusterNetworkName: pour trouver le nom dans le Gestionnaire du cluster de basculement, sélectionnez Réseaux, cliquez avec le bouton droit sur le réseau, puis sélectionnez Propriétés. Le $ClusterNetworkName se trouve sous Nom sous l’onglet Général.$IPResourceNameest le nom donné à la ressource Adresse IP dans le Gestionnaire du cluster de basculement. Pour le trouver dans le Gestionnaire du cluster de basculement, sélectionnez Rôles, sélectionnez le nom du groupe de disponibilité ou de l’instance de cluster de basculement SQL Server, sélectionnez l’onglet Ressources sous Nom du serveur, cliquez avec le bouton droit sur la ressource Adresse IP, puis sélectionnez Propriétés. La valeur correcte est sous Nom dans l’onglet Général.$ListenerILBIPest l’adresse IP que vous avez créée sur l’équilibreur de charge Azure pour l’écouteur du groupe de disponibilité. $ListenerILBIP se trouve dans le Gestionnaire du cluster de basculement, dans la page de propriétés où se trouve également le nom de ressource de l’écouteur de groupe de disponibilité ou d’instance de cluster de basculement SQL Server.$ListenerProbePortest le port que vous avez configuré sur l’équilibreur de charge Azure pour l’écouteur de groupe de disponibilité (par exemple, 59999). N’importe quel port TCP inutilisé est valide.
$ClusterNetworkName = "<MyClusterNetworkName>" # The cluster network name. Use Get-ClusterNetwork on Windows Server 2012 or later to find the name. $IPResourceName = "<IPResourceName>" # The IP address resource name. $ListenerILBIP = "<n.n.n.n>" # The IP address of the internal load balancer. This is the static IP address for the load balancer that you configured in the Azure portal. [int]$ListenerProbePort = <nnnnn> Import-Module FailoverClusters Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{"Address"="$ListenerILBIP";"ProbePort"=$ListenerProbePort;"SubnetMask"="255.255.255.255";"Network"="$ClusterNetworkName";"EnableDhcp"=0}b. Définissez les paramètres du cluster en exécutant le script PowerShell sur l’un des nœuds du cluster.
Notes
Si vos instances SQL Server se trouvent dans différentes régions, vous devez exécuter le script PowerShell à deux reprises. La première fois, utilisez les valeurs
$ListenerILBIPet$ListenerProbePortde la première région. La seconde fois, utilisez les valeurs$ListenerILBIPet$ListenerProbePortde la seconde région. Le nom réseau du cluster et le nom de ressource IP du cluster sont également différents pour chaque région.Mettez le rôle de cluster du groupe de disponibilité en ligne. Dans le Gestionnaire du cluster de basculement, sous Rôles, cliquez avec le bouton droit sur le rôle, puis sélectionnez Démarrer le rôle.
Si nécessaire, répétez les étapes précédentes pour définir les paramètres du cluster pour l’adresse IP du cluster de basculement Windows Server :
Récupérez le nom de l’adresse IP du cluster de basculement Windows Server. Dans le Gestionnaire du cluster de basculement, sous Principales ressources du cluster, recherchez Nom du serveur.
Cliquez avec le bouton droit sur Adresse IP, puis sélectionnez Propriétés.
Copiez le nom de l’adresse IP à partir de Nom. Cela peut être Adresse IP du cluster.
Définissez les paramètres du cluster dans PowerShell :
a. Copiez le script PowerShell suivant sur l’une de vos instances SQL Server. Mettez à jour les variables de votre environnement.
$ClusterCoreIPest l’adresse IP que vous avez créée sur l’équilibreur de charge Azure pour la ressource de cluster principale du cluster de basculement Windows Server. Cette adresse est différente de l’adresse IP de l’écouteur de groupe de disponibilité.$ClusterProbePortest le port que vous avez configuré sur l’équilibreur de charge Azure pour la sonde d’intégrité du cluster de basculement Windows Server. Ce port est différent de la sonde configurée pour l’écouteur de groupe de disponibilité.
$ClusterNetworkName = "<MyClusterNetworkName>" # The cluster network name. Use Get-ClusterNetwork on Windows Server 2012 or later to find the name. $IPResourceName = "<ClusterIPResourceName>" # The IP address resource name. $ClusterCoreIP = "<n.n.n.n>" # The IP address of the cluster IP resource. This is the static IP address for the load balancer that you configured in the Azure portal. [int]$ClusterProbePort = <nnnnn> # The probe port from WSFCEndPointprobe in the Azure portal. This port must be different from the probe port for the availability group listener. Import-Module FailoverClusters Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{"Address"="$ClusterCoreIP";"ProbePort"=$ClusterProbePort;"SubnetMask"="255.255.255.255";"Network"="$ClusterNetworkName";"EnableDhcp"=0}b. Définissez les paramètres du cluster en exécutant le script PowerShell sur l’un des nœuds du cluster.
Si une ressource SQL est configurée pour utiliser un port compris entre 49152 et 65536 (plage de ports dynamiques par défaut pour TCP/IP), ajoutez une exclusion pour chaque port. Ces ressources peuvent inclure :
- Moteur de base de données SQL Server
- Écouteur de groupe de disponibilité Always On
- Sonde d’intégrité pour l’instance de cluster de basculement
- Point de terminaison de mise en miroir de bases de données
- Ressource IP principale du cluster
L’ajout d’une exclusion empêchera d’autres processus système d’être affectés dynamiquement au même port. Pour ce scénario, configurez les exclusions suivantes sur tous les nœuds de cluster :
netsh int ipv4 add excludedportrange tcp startport=58888 numberofports=1 store=persistentnetsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Il est important de configurer l’exclusion de port quand le port n’est pas utilisé. Sinon, la commande échoue avec un message du type « Le processus ne peut pas accéder au fichier, car il est utilisé par un autre processus ». Pour vérifier que les exclusions sont correctement configurées, utilisez la commande suivante : netsh int ipv4 show excludedportrange tcp.
Avertissement
Le port pour la sonde d’intégrité de l’écouteur de groupe de disponibilité doit être différent du port pour la sonde d’intégrité de l’adresse IP principale du cluster. Dans ces exemples, le port de l’écouteur est 59999 et le port de la sonde d’intégrité de l’adresse IP principale du cluster est 58888. Une règle de pare-feu d’autorisation du trafic entrant doit être définie pour les deux ports.
Définir le port de l’écouteur
Dans SQL Server Management Studio, définissez le port de l’écouteur :
Ouvrez SQL Server Management Studio et connectez-vous au réplica principal.
Accédez à Haute disponibilité Always On>Groupes de disponibilité>Écouteurs de groupe de disponibilité.
Cliquez avec le bouton droit sur le nom de l’écouteur que vous avez créé dans le Gestionnaire du cluster de basculement, puis sélectionnez Propriétés.
Dans la zone Port, spécifiez le numéro de port de l’écouteur de groupe de disponibilité. La valeur par défaut est 1433. Sélectionnez OK.
Vous disposez maintenant d’un groupe de disponibilité pour SQL Server sur les machines virtuelles Azure s’exécutant en mode Resource Manager Azure.
Tester la connexion à l’écouteur
Pour tester la connexion :
Utilisez RDP pour vous connecter à une machine virtuelle SQL Server qui se trouve dans le même réseau virtuel, mais qui ne possède pas le réplica, comme l’autre réplica.
Utilisez l’utilitaire sqlcmd pour tester la connexion. Par exemple, le script suivant établit une connexion sqlcmd avec le réplica principal au moyen de l’écouteur en utilisant l’authentification Windows :
sqlcmd -S <listenerName> -ESi l’écouteur utilise un port autre que le port par défaut (1433), spécifiez le port dans la chaîne de connexion. Par exemple, la commande suivante se connecte à un écouteur sur le port 1435 :
sqlcmd -S <listenerName>,1435 -E
L’utilitaire sqlcmd se connecte automatiquement à l’instance SQL Server qui est le réplica principal actuel du groupe de disponibilité.
Conseil
Vérifiez que le port que vous spécifiez est ouvert sur le pare-feu des deux machines virtuelles SQL Server. Les deux serveurs requièrent une règle de trafic entrant sur le port TCP utilisé. Pour plus d’informations, consultez Ajouter ou modifier des règles de pare-feu.
Contenu connexe
- Ajouter une adresse IP à un équilibreur de charge pour un deuxième groupe de disponibilité
- Configurer un basculement automatique ou manuel
- Cluster de basculement Windows Server avec SQL Server sur des machines virtuelles Azure
- Groupes de disponibilité Always On avec SQL Server sur les machines virtuelles Azure
- Vue d’ensemble des groupes de disponibilité Always On
- Paramètres HADR pour SQL Server sur les machines virtuelles Azure